Beyond the Black Box: Interpretability of Agentic AI Tool Use
Pith reviewed 2026-06-30 22:57 UTC · model grok-4.3
The pith
A mechanistic interpretability toolkit built on sparse autoencoders and linear probes can read pre-action model states to predict whether an AI agent needs a tool and how risky the action is.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
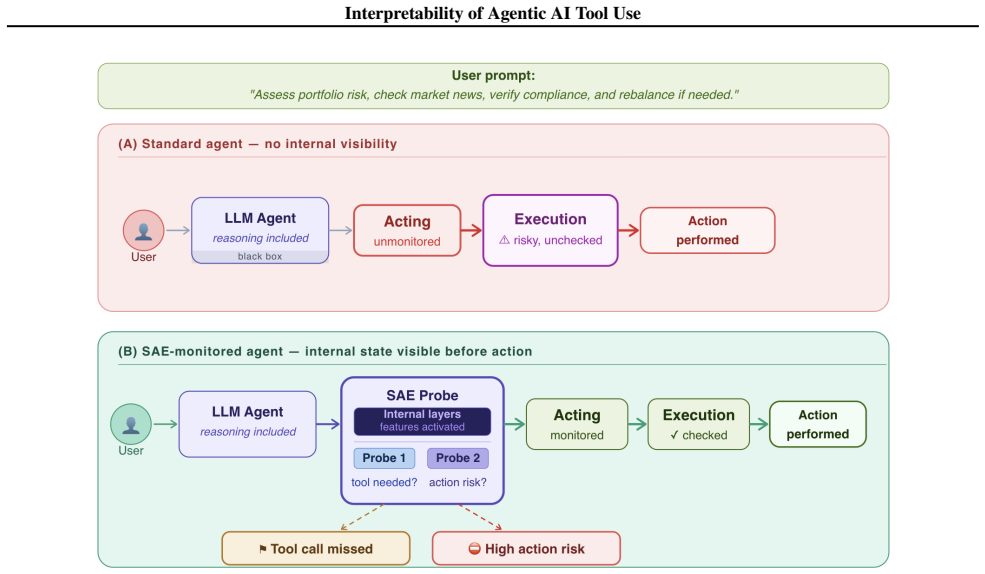
The paper claims that sparse autoencoders can decompose pre-action activations into sparse internal features from which linear probes can infer both the need for a tool call and the risk level of the next action, that these signals are concentrated in identifiable layers and features, and that ablating the features alters the model's tool-use behavior in the expected direction.
What carries the argument
Sparse Autoencoders (SAEs) that decompose activations into sparse internal features, combined with linear probes that classify signals for tool need and risk from those features.
If this is right
- The toolkit locates specific layers and features most associated with tool decisions across the tested models.
- Feature ablation provides a direct test of whether those features are functionally necessary for the observed tool-use behavior.
- Pre-action inference supplies visibility into potential failures before they affect later steps in long-horizon agent runs.
- The approach adds an internal monitoring layer that complements rather than replaces external evaluation methods.
Where Pith is reading between the lines
- The same workflow could be applied at inference time to flag high-risk tool calls before they execute.
- Extending the probes to additional agent behaviors such as planning or memory retrieval might reveal shared internal mechanisms.
- Combining the internal signals with external logs could create hybrid monitoring systems that catch both early signals and downstream effects.
Load-bearing premise
That the sparse features derived from pre-action activations contain linearly readable signals about tool need and risk that can be isolated through ablation without confounding effects from other model behaviors.
What would settle it
If ablating the features identified by the probes produces no measurable change in the model's actual tool-calling frequency or risk profile on the same trajectories used for probe training.
Figures
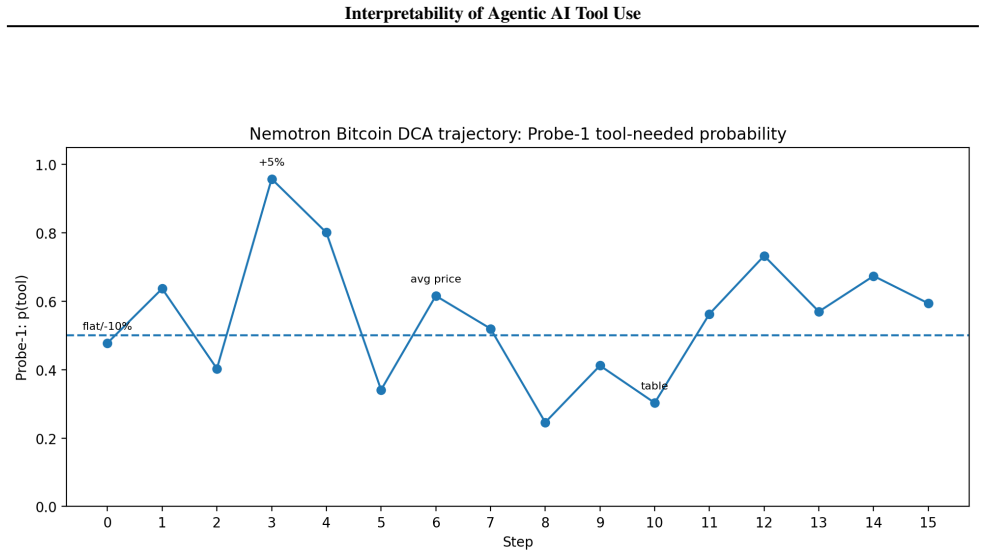
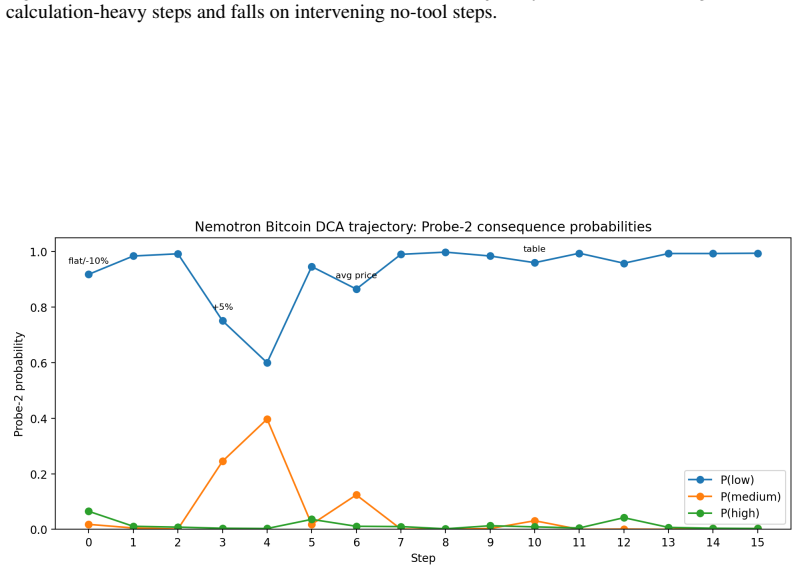
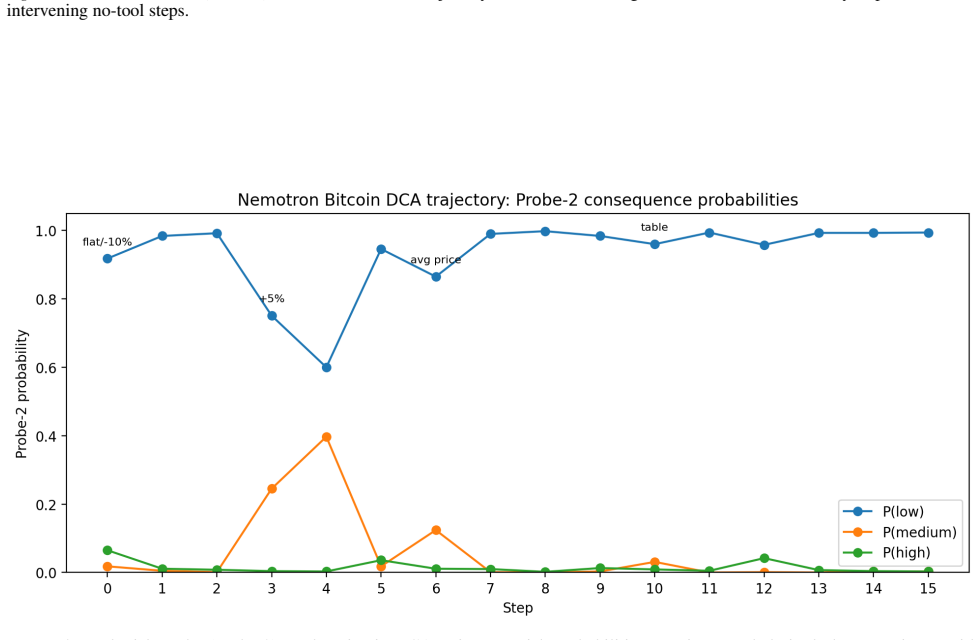
read the original abstract
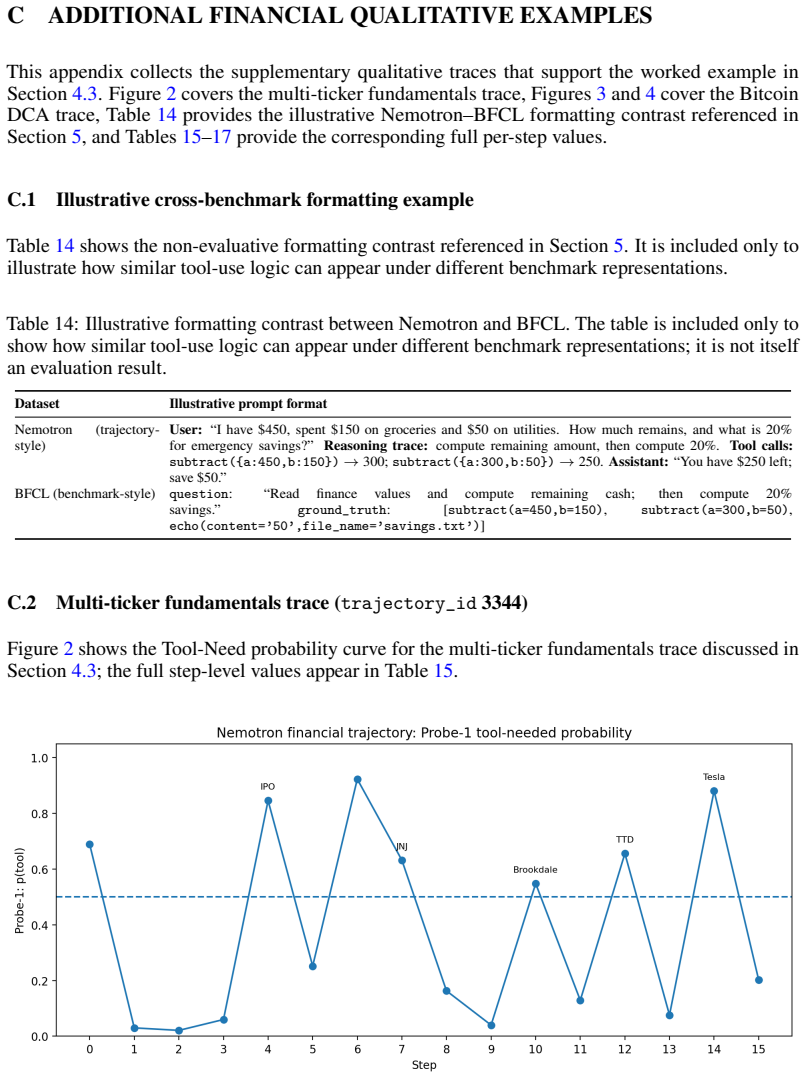
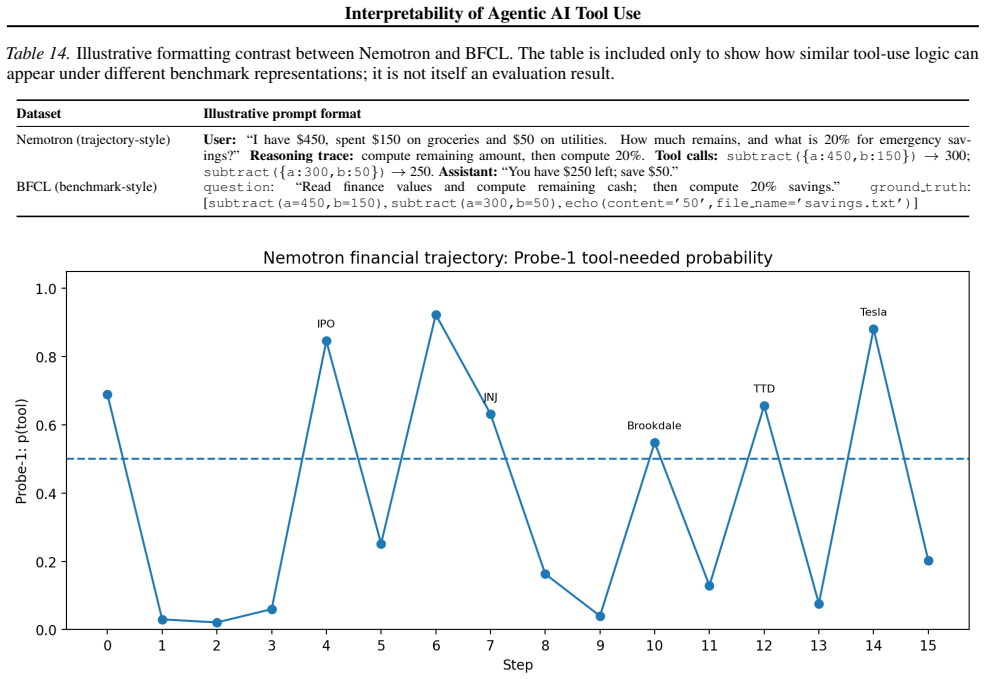
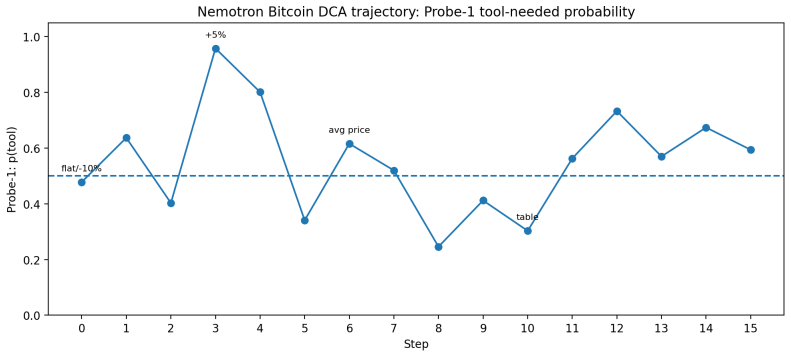
AI agents are promising for high-stakes enterprise workflows, but dependable deployment remains limited because tool-use failures are difficult to diagnose and control. Agents may skip required tool calls, invoke tools unnecessarily, or take actions whose consequence becomes visible only after execution. Existing observability methods are external: prompts reveal correlations, evaluations score outputs, and logs arrive only after the model has already acted. In long-horizon settings, these failures are costly because an early tool mistake can alter the rest of the trajectory, increase token consumption, and create downstream safety and security risk. We introduce a mechanistic-interpretability toolkit built on Sparse Autoencoders (SAEs), which decompose activations into sparse internal features, and linear probes, lightweight classifiers that read signals from those features. The framework reads model states before each action and infers whether a tool is needed and how risky the next tool action is. It identifies the model layers and features most associated with tool decisions and tests their functional importance through feature ablation. We train the probes on multi-step trajectories from the NVIDIA Nemotron function-calling dataset and apply the same workflow to GPT-OSS 20B and Gemma 3 27B models. The goal is not to replace external evaluation, but to add a missing layer: visibility into what the model signaled internally before action. This helps surface deeper causes of agent failure, especially in long-horizon runs where an early mistake can impact subsequent agent behavior. More broadly, the paper shows how mechanistic interpretability can support internal observability for monitoring tool calls and risk in agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a mechanistic-interpretability toolkit for AI agents using Sparse Autoencoders (SAEs) to decompose activations into sparse internal features and linear probes to read signals from pre-action model states. The framework infers tool need and risk for the next action, identifies associated layers and features, and tests functional importance via feature ablation. It is trained on multi-step trajectories from the NVIDIA Nemotron function-calling dataset and applied to GPT-OSS 20B and Gemma 3 27B models, with the goal of adding internal visibility into tool-use decisions to diagnose failures in long-horizon agent workflows beyond external evaluations.
Significance. If the empirical claims hold, the work would provide a useful internal observability layer for agentic tool use, extending SAE-based interpretability to diagnose pre-action decisions in high-stakes settings. The multi-model application and focus on risk inference represent a timely direction for mechanistic interpretability in agents. However, the manuscript as presented contains no reported metrics or outcomes, so its current contribution is limited to a methodological proposal.
major comments (2)
- [Abstract] Abstract: The abstract states that the framework 'infers whether a tool is needed and how risky the next tool action is' and 'tests their functional importance through feature ablation,' but reports no accuracy metrics for the probes, no ablation results (e.g., change in tool-calling behavior), and no validation outcomes. This absence makes it impossible to evaluate whether SAE features from pre-action activations contain the claimed linearly readable signals or whether ablation isolates tool-specific importance without confounds.
- [Abstract] Methods/Results (as described in abstract): The central claim requires that linear probes on SAE features can accurately infer tool need/risk and that ablation demonstrates functional importance. No experiments, baselines, controls (e.g., ablation on non-tool features or random features), or performance numbers are provided to support this, leaving the weakest assumption untested.
minor comments (1)
- [Abstract] Abstract: The model name 'GPT-OSS 20B' is nonstandard; clarify the exact model variant or citation to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the manuscript as presented is a methodological proposal and that the abstract language implies empirical outcomes (accuracy metrics, ablation results) that are not supported by reported numbers or experiments. We will revise the abstract, claims, and framing to accurately reflect the contribution as a proposed toolkit and workflow without overstating untested results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states that the framework 'infers whether a tool is needed and how risky the next tool action is' and 'tests their functional importance through feature ablation,' but reports no accuracy metrics for the probes, no ablation results (e.g., change in tool-calling behavior), and no validation outcomes. This absence makes it impossible to evaluate whether SAE features from pre-action activations contain the claimed linearly readable signals or whether ablation isolates tool-specific importance without confounds.
Authors: We agree the abstract phrasing is misleading. The manuscript introduces the SAE + probe toolkit and describes its intended use on pre-action activations from the Nemotron trajectories applied to the two models, but contains no quantitative probe accuracies, ablation deltas, or controls. In revision we will rewrite the abstract to state that the framework is designed to read pre-action states for tool-need and risk signals and outlines a method for feature ablation, while explicitly noting that empirical validation metrics are not reported here. We will add a limitations paragraph on the absence of these numbers. revision: yes
-
Referee: [Abstract] Methods/Results (as described in abstract): The central claim requires that linear probes on SAE features can accurately infer tool need/risk and that ablation demonstrates functional importance. No experiments, baselines, controls (e.g., ablation on non-tool features or random features), or performance numbers are provided to support this, leaving the weakest assumption untested.
Authors: The observation is accurate: the provided manuscript text describes the training procedure and model application but supplies no probe performance numbers, ablation outcomes, or control experiments. Because the central claims rest on untested assumptions, we will revise the abstract and introduction to remove any implication that the probes or ablations have been shown to work, and instead present the work as a methodological proposal whose empirical validation remains future work. revision: yes
Circularity Check
No circularity; empirical toolkit application is self-contained
full rationale
The paper describes training SAEs and linear probes on the Nemotron function-calling dataset trajectories, then applying the resulting probes and ablations to GPT-OSS 20B and Gemma 3 27B. No equations, uniqueness theorems, or first-principles derivations are presented that reduce to fitted inputs by construction. No self-citation chains are invoked to justify core claims. The method is a direct empirical pipeline (decompose activations, train probes on labeled trajectories, ablate features) whose validity rests on external data and standard SAE/probe techniques rather than internal redefinition or renaming. This matches the default expectation of no circularity for an applied interpretability study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders decompose model activations into sparse, interpretable features relevant to specific behaviors such as tool decisions.
Forward citations
Cited by 1 Pith paper
-
Looking Is Not Picking: An Attention-Segment Account of Tool-Selection Failures in LLM Agents
Attention analysis shows that LLM tool selection failures occur at the readout/decision stage, not because the model fails to attend to the correct tool definition.
Reference graph
Works this paper leans on
-
[1]
Alain, G., & Bengio, Y . (2017). Understanding Intermedi- ate Layers Using Linear Classifier Probes.arXiv preprint arXiv:1610.01644. https://arxiv.org/abs/1610.01644 Bricken, T., et al. (2023). Towards Monosemanticity: Decompos- ing Language Models with Dictionary Learning.Transformer Cir- cuits Thread. https://transformer-circuits.pub/2023/monosemantic- ...
Pith/arXiv arXiv 2017
-
[2]
https://arxiv.org/abs/2302.04761 Tatsat, H., & Shater, A. (2025). Beyond the Black Box: Inter- pretability of LLMs in Finance.arXiv preprint arXiv:2505.24650. https://arxiv.org/abs/2505.24650 Wang, J., et al. (2025). HammerBench: Fine-Grained Function- Calling Evaluation in Real Mobile Device Scenarios.arXiv preprint arXiv:2412.16516. https://arxiv.org/ab...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.