CoRe-Code: Collaborative Reinforcement Learning for Code Generation
Pith reviewed 2026-06-30 11:56 UTC · model grok-4.3
The pith
CoRe-Code uses a Planner-Coder split and GRPO training to improve multi-agent LLM code generation accuracy and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
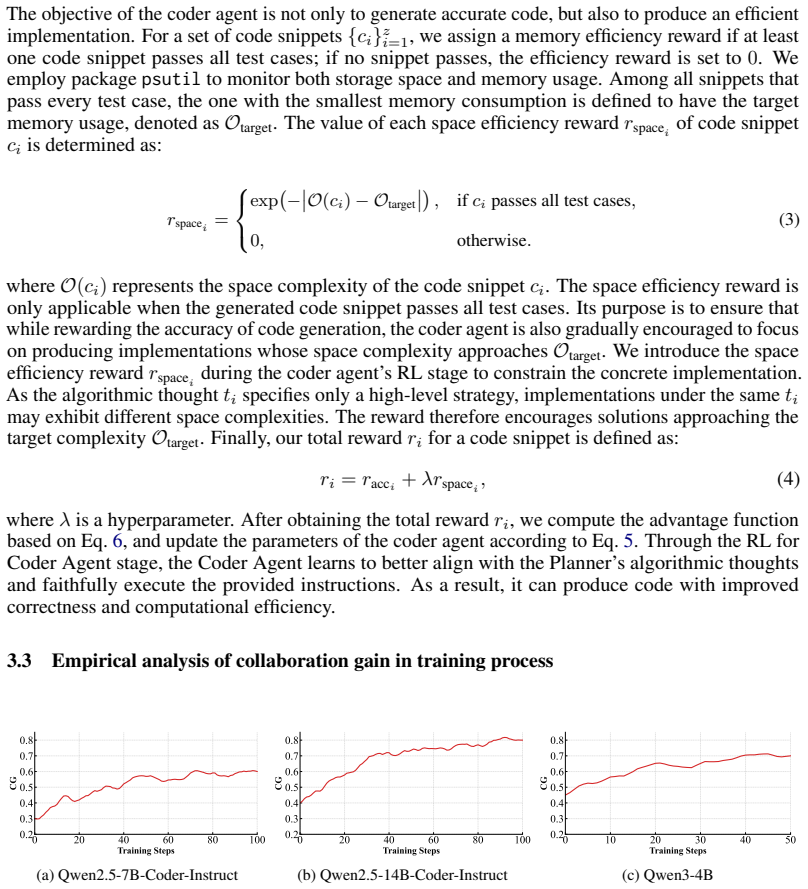
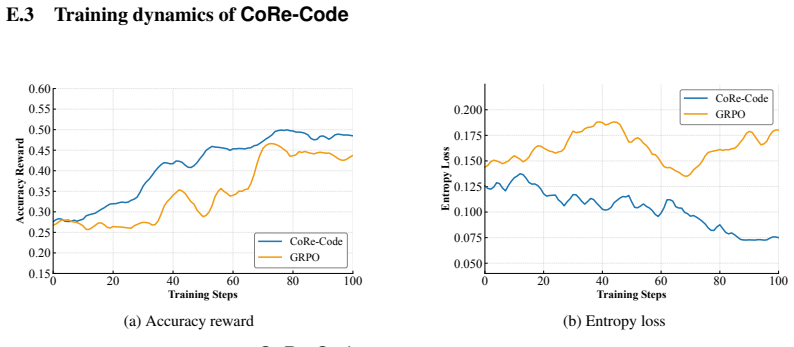
CoRe-Code adopts a Planner-Coder paradigm where the Planner produces high-level plans and the Coder executes them to generate code, then applies a collaboration-aware reinforcement learning stage based on Group Relative Policy Optimization to enhance role specialization and alignment, yielding higher accuracy and better efficiency than prior RL-based and multi-agent code generation methods.
What carries the argument
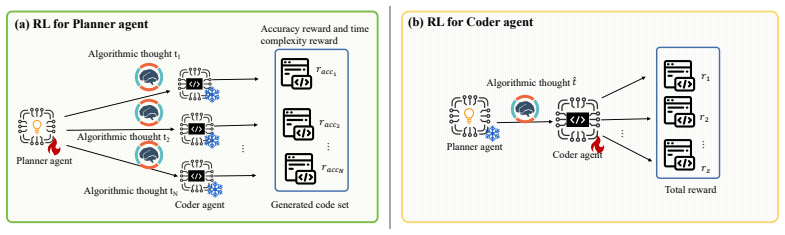
The Planner-Coder paradigm combined with collaboration-aware reinforcement learning via Group Relative Policy Optimization (GRPO) to improve inter-agent coordination and role specialization.
If this is right
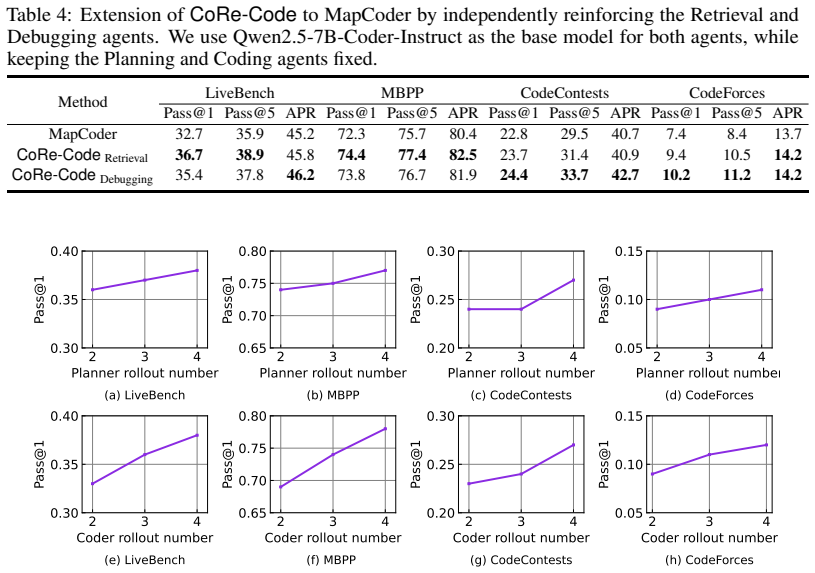
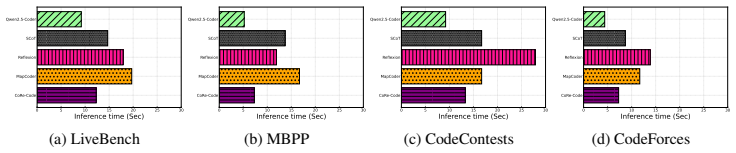
- Consistent accuracy gains on code generation benchmarks of varying difficulty when using three different base models.
- Lower execution time and memory consumption relative to existing RL and multi-agent baselines.
- The same training stage can be attached to other multi-agent setups such as retrieval and debugging agents.
Where Pith is reading between the lines
- The same planning-execution split and group optimization might reduce coordination failures in agent teams that solve non-code tasks such as theorem proving.
- If GRPO remains stable when more than two roles are added, it could reduce the engineering cost of building larger multi-agent systems.
- Testing the framework on safety-critical code domains would show whether the reported efficiency gains also lower error rates that matter in practice.
Load-bearing premise
That introducing a simple Planner-Coder division and training it with GRPO is enough to create stronger role specialization and coordination than existing multi-agent code methods.
What would settle it
Reproducing the benchmark experiments and finding that CoRe-Code shows no accuracy improvement or higher execution time and memory use than the strongest baseline methods.
Figures
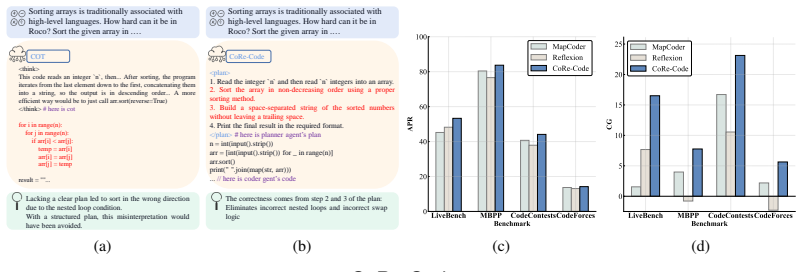

read the original abstract
Large language models (LLMs) have achieved strong performance in code generation, but most methods rely on autoregressive decoding without global planning, often leading to locally coherent yet globally suboptimal solutions (e.g., failing test cases or inefficient complexity). While recent approaches such as Chain-of-Thought (CoT) and multi-agent systems (MAS) introduce planning, their limited role specialization and coordination hinder performance on complex tasks. To address the challenges of coordination and specialization in multi-agent code generation, we propose Collaborative Reinforcement Code (CoRe-Code), a framework for role specialized LLM agents that enhances inter-agent coordination to generate more accurate and efficient code. CoRe-Code adopts a simple Planner-Coder paradigm, where the Planner produces high-level plans and the Coder executes them to generate code. We further introduce a collaboration-aware reinforcement learning stage based on Group Relative Policy Optimization (GRPO) to enhance role specialization and alignment. Experiments show that CoRe-Code outperforms a wide range of existing RL-based and multi-agent methods. In addition, we demonstrate that CoRe-Code can generalize to other multi-agent frameworks (e.g., Retrieval and Debugging agents), highlighting its flexibility and scalability. We evaluate CoRe-Code on multiple benchmarks of varying difficulty using three base models. Compared to existing baselines, the results show consistent improvements in accuracy, while also achieving higher efficiency in terms of execution time and memory usage, demonstrating the effectiveness and practicality of CoRe-Code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoRe-Code, a multi-agent framework for LLM-based code generation that adopts a Planner-Coder paradigm and introduces collaboration-aware reinforcement learning via Group Relative Policy Optimization (GRPO) to improve role specialization, inter-agent coordination, and global optimality. It claims consistent outperformance over RL-based and multi-agent baselines on multiple code-generation benchmarks of varying difficulty (using three base models), plus gains in accuracy, execution time, and memory usage, and generalization to other agent frameworks such as retrieval and debugging agents.
Significance. If the empirical claims are substantiated by properly reported experiments, the work could offer a practical route to addressing coordination failures in multi-agent code generation. The absence of any quantitative results, baseline specifications, or protocol details in the provided text, however, leaves the significance unassessable.
major comments (3)
- [Abstract] Abstract: the central claim that 'Experiments show that CoRe-Code outperforms a wide range of existing RL-based and multi-agent methods' and delivers 'consistent improvements in accuracy' is unsupported by any numerical results, baseline names, metrics, error bars, or statistical tests. This is load-bearing for the entire contribution.
- [Abstract] Abstract: no experimental protocol, benchmark names, base-model sizes, training details for GRPO, or measurement procedures for execution time and memory are supplied, preventing evaluation of the efficiency and practicality claims.
- [Abstract] Abstract (proposed framework paragraph): the assertion that the Planner-Coder paradigm plus GRPO 'enhance role specialization and alignment' is presented without any ablation, coordination metric, or comparison showing that these components are responsible for the reported gains.
minor comments (1)
- [Abstract] Abstract: 'GRPO' is introduced without expansion or citation on first use.
Simulated Author's Rebuttal
Thank you for your review. We agree with the points raised regarding the abstract and will make revisions to include more specific details from the full manuscript to substantiate the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'Experiments show that CoRe-Code outperforms a wide range of existing RL-based and multi-agent methods' and delivers 'consistent improvements in accuracy' is unsupported by any numerical results, baseline names, metrics, error bars, or statistical tests. This is load-bearing for the entire contribution.
Authors: We accept this criticism. While the full paper contains the quantitative results, baselines, metrics, and statistical analyses in the experimental evaluation, the abstract does not. We will revise the abstract to include key numerical results, specific baseline names, and mention of error bars or significance where applicable. revision: yes
-
Referee: [Abstract] Abstract: no experimental protocol, benchmark names, base-model sizes, training details for GRPO, or measurement procedures for execution time and memory are supplied, preventing evaluation of the efficiency and practicality claims.
Authors: We agree that these details are missing from the abstract. The manuscript specifies the benchmarks, base models (three different LLMs), GRPO training procedure, and measurement methods for efficiency metrics in the main text. We will incorporate concise mentions of these into the revised abstract. revision: yes
-
Referee: [Abstract] Abstract (proposed framework paragraph): the assertion that the Planner-Coder paradigm plus GRPO 'enhance role specialization and alignment' is presented without any ablation, coordination metric, or comparison showing that these components are responsible for the reported gains.
Authors: The full manuscript includes ablations and metrics for role specialization and coordination to support this. We will update the abstract to reference these supporting experiments or adjust the wording to reflect the evidence provided in the paper. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript presents CoRe-Code as an empirical framework (Planner-Coder paradigm plus GRPO collaboration-aware RL) whose central claims are performance improvements on code-generation benchmarks. No equations, derivations, fitted parameters, or first-principles results appear in the provided text. All statements reduce to experimental comparisons rather than any self-definitional, fitted-input, or self-citation chain that collapses to the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
DAIN: Dynamic Agent-Based Interaction Network for Efficient and Collaborative Multimodal Reasoning
DAIN reframes multimodal fusion as dynamic agent collaboration with sparse activation, claiming SOTA results including 2.6% accuracy gain on ADNI across five benchmarks.
Reference graph
Works this paper leans on
-
[1]
Initialize an empty result container (conceptually a list of characters or substrings)
-
[2]
Branch: 19
Traverse the input string from the first to the last character. Branch: 19
-
[3]
Else, append the character itself unchanged
For each character: If the character is a space (‘’ ’‘), append ‘’%20’‘ to the result. Else, append the character itself unchanged. Loop:
-
[4]
Final Step:
A loop is required to process each character in the input string sequentially until the end is reached. Final Step:
-
[5]
Combine all elements in the result container into a single string
-
[6]
%20") else: result.append(char) return
Return this new string. </plan> defreplaceSpaces(s): result = [] forcharins: ifchar == ’␣’: result.append("%20") else: result.append(char) return"".join(result) 20 CoRe-Code(Sample 2) Q: Write a function to get a lucid number smaller than or equal to n. <plan> Input: - n (an integer): The upper bound for searching lucid numbers, where n >= 1. Output: The ...
-
[7]
Examples: 1, 2, 3, 5, 7, 6, 10, 14, 15, 21, 28, etc
Define Lucid Number: A lucid number is a positive integer whose prime factors are only 2, 3, 5, or 7. Examples: 1, 2, 3, 5, 7, 6, 10, 14, 15, 21, 28, etc
-
[8]
Sequence (Step-by-Step Process):
-
[9]
Start with the base set {1}, since 1 is trivially lucid
-
[10]
Generate new lucid numbers by multiplying existing ones by 2, 3, 5, or 7
-
[11]
Continue generating until values exceed n
-
[12]
Store all generated lucid numbers in a data structure (e.g., list or heap)
-
[13]
Select the maximum lucid number that is <= n
-
[14]
If n itself is lucid -> directly return n
Branch (Conditions): If n < 1 -> no lucid number exists, return 0 or handle as invalid input. If n itself is lucid -> directly return n. Otherwise, search among generated lucid numbers for the largest <= n
-
[15]
Continue until no new lucid numbers can be generated under the bound
Loop (Repetition): Use a loop or priority-based expansion to multiply numbers repeatedly until exceeding n. Continue until no new lucid numbers can be generated under the bound. </plan> deflargest_lucid_number(n): ifn < 1: return0 primes = [2, 3, 5, 7] lucid = {1} queue = [1] whilequeue: current = queue.pop() forpinprimes: new_val = current * p ifnew_val ...
-
[16]
Output is a single integer, representing the number of valid paths modulo or exact (depending on constraints)
Input-Output Structure Input defines a stacked structure of L layers, each with N cities, connected in a complete bipartite way to the next layer with uniform costs per destination. Output is a single integer, representing the number of valid paths modulo or exact (depending on constraints)
-
[17]
Solving Logic Sequence:
-
[18]
Model path costs as sequences of choices across L transitions (from entry to exit)
-
[19]
Since costs depend only on the chosen city in each layer, the total cost is the sum of L chosen city costs (one from each layer)
-
[20]
Limitations
The number of paths equals the number of such sequences, which is $N^L$. But we only count sequences whose total cost % M == 0. Branch: For each possible remainder modulo M, decide whether adding a new city’s cost keeps us on a path toward divisibility. Use a dynamic programming (DP) state: ‘dp[layer][r] = number of ways to reach remainder r after process...
-
[21]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.