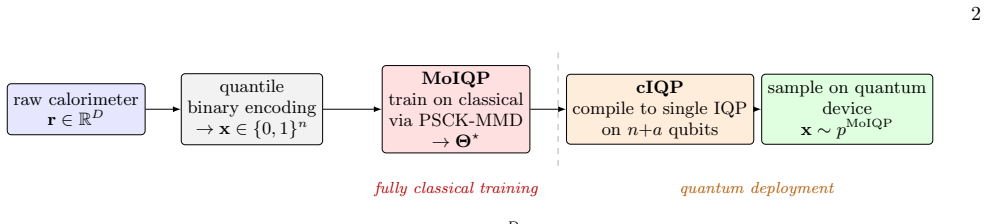
An IQP Born Machine for Calorimeter Image Generation at 64 Qubits with Compiled-IQP Deployment
Pith reviewed 2026-06-29 16:32 UTC · model grok-4.3
The pith
A 64-qubit IQP Born machine trained on calorimeter showers compiles to a single deployable circuit that matches the original marginals within 0.591 times Monte Carlo noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The three-part pipeline of MoIQP architecture, PSCK kernel, and exact deferred-measurement compilation into cIQP produces calorimeter-image marginals whose MAE rho lies between the encoding-fidelity floor and the classical baseline, with the compiled circuit reproducing the MoIQP marginal to 0.591 times the Monte Carlo noise floor across five random seeds at L equals 8.
What carries the argument
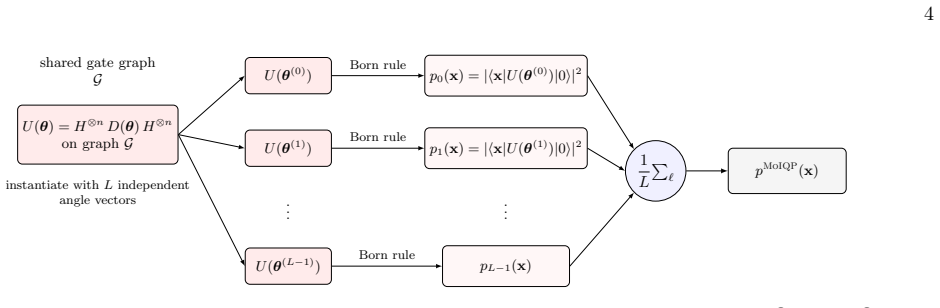
The Mixture-of-IQP (MoIQP) model whose Walsh-diagonal MMD squared loss is minimized by Van den Nest Fourier Monte Carlo and then compiled by deferred measurement into a single cIQP circuit on n plus log2 L qubits.
If this is right
- The trained model can be run on existing quantum hardware without further classical post-processing.
- The same compilation step applies to any IQP Born machine whose mixing weights are discrete.
- Classical training cost remains polynomial in the number of Fourier features even at 64 qubits.
- The Pearson-Stabilized kernel biases the optimizer toward accurate two-point correlations in the shower images.
- Held-out test performance stays within one standard deviation of training performance, indicating limited overfitting.
Where Pith is reading between the lines
- If the same pipeline scales to larger L without an exponential rise in required Fourier samples, it could become a practical method for quantum-assisted simulation of particle detectors.
- The approach separates the training phase (classical, data-driven) from the inference phase (quantum, sampling-hard), which may matter for workflows that need many independent samples after one training run.
- Because the compilation is exact, any future improvement in IQP circuit fidelity directly improves the final generative quality without retraining.
Load-bearing premise
Minimizing the Walsh-diagonal MMD squared loss under the Pearson-Stabilized Correlation Kernel produces a minimum whose generated images match the true calorimeter shower statistics.
What would settle it
Sampling the compiled cIQP circuit on quantum hardware and finding that its marginals deviate from the classically trained MoIQP marginals by more than the reported 0.591 factor times Monte Carlo noise would falsify the claim that the compilation preserves the learned distribution.
Figures




read the original abstract
We train an instantaneous quantum polynomial-time (IQP) Born machine on real high-energy-physics calorimeter shower images at 64 qubits and compile the trained model into a single sampling-hard IQP circuit for quantum deployment. The pipeline has three components. The first is a Mixture-of-IQP (MoIQP) architecture, whose Walsh-diagonal MMD$^2$ loss is classically trainable by Van den Nest Fourier Monte Carlo. The second is the Pearson-Stabilized Correlation Kernel (PSCK), a positive-definite MMD kernel that biases descent toward correlation-sensitive directions through a data-evaluated Jacobian of the empirical Pearson matrix. The third is an exact deferred-measurement compilation of MoIQP into a single IQP circuit on n + $log_2 L$ qubits (cIQP). Across five seeds at L = 8, 1500 epochs, the model reaches $\mathrm{MAE}_{\rho}$ = $0.069 \pm 0.008$ against a 0.052 encoding-fidelity floor on the training split and $0.071 \pm 0.008$ on a held-out test split, versus a Liu-Wang baseline at $\mathrm{MAE}_{\rho}$ = 0.100. The compiled cIQP reproduces the MoIQP marginal to $0.591 \pm 0.012$ times the Monte Carlo noise floor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an IQP Born machine based on a Mixture-of-IQP (MoIQP) architecture for generating 64-qubit calorimeter shower images from high-energy physics data. The training uses a Walsh-diagonal MMD² loss that is classically trainable via Van den Nest Fourier Monte Carlo, augmented by the Pearson-Stabilized Correlation Kernel (PSCK). An exact deferred-measurement compilation produces a single IQP circuit (cIQP) for deployment. Empirical results across five seeds at L=8 after 1500 epochs report MAE_ρ = 0.069 ± 0.008 on both training and held-out test splits (against an encoding-fidelity floor of 0.052), outperforming the Liu-Wang baseline at 0.100, with the cIQP reproducing the MoIQP marginal to 0.591 ± 0.012 times the Monte Carlo noise floor.
Significance. If the central claims hold, this work provides a concrete demonstration of classically trainable quantum generative models at 64 qubits with direct quantum hardware deployment via compilation. The explicit reporting of seed-averaged metrics with error bars, comparison to an encoding-fidelity floor, and reproduction factor relative to Monte Carlo noise are strengths that make the empirical results more falsifiable and reproducible. This could have implications for quantum machine learning applications in particle physics simulations.
minor comments (2)
- [Abstract] The three pipeline components are listed but the full manuscript should provide explicit equations for the PSCK Jacobian and the deferred-measurement compilation to allow independent verification.
- The Liu-Wang baseline is referenced without a citation; adding the reference would improve context.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our work, the positive assessment of its significance, and the recommendation for minor revision. No specific major comments appear in the provided referee report, so we have no individual points requiring point-by-point rebuttal or revision at this stage. We remain available to address any additional feedback or minor clarifications the editor or referee may wish to raise.
Circularity Check
No significant circularity detected
full rationale
The paper defines the MoIQP architecture, Walsh-diagonal MMD² loss (classically trainable via Van den Nest Fourier Monte Carlo), PSCK kernel, and exact deferred-measurement compilation to cIQP as distinct components. It then reports empirical outcomes: MAE_ρ = 0.069 ± 0.008 (train) and 0.071 ± 0.008 (test) after 1500 epochs at L=8 across five seeds, versus Liu-Wang baseline 0.100 and 0.052 encoding-fidelity floor, plus cIQP reproduction factor 0.591 ± 0.012× MC noise. These quantities are measured post-training on held-out data and compared to external baselines; no claimed prediction reduces by construction to fitted parameters, no self-citation chain justifies a uniqueness theorem, and the loss/kernel minimum is not asserted to be identical to the reported MAE_ρ by definition. The derivation chain remains self-contained against the stated empirical benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Qudit extension of parameterized IQP circuits: A generative quantum machine learning approach to integer data
Qudit extension of parameterized IQP circuits proposed for generative modeling of integer data, with loss function and covariance matrix, validated on electron shower energy deposits in CLIC electromagnetic calorimeter.
Reference graph
Works this paper leans on
-
[1]
We run five independent user-seeds,{42,43,44,45,46}, each of which controls the graph, the parameter initialization, and the Monte Carlo stream
Configuration All runs useB= 8 (n= 64 qubits),L= 8MoIQP components, an Erd˝ os–R´ enyi gate graph at average de- gree 6.0 (graph seed = user-seed + 1, so the graph itself varies seed to seed with|G|in the range 256 to 287), 1500 Adam epochs, learning rate 0.02 with cosine restarts ev- ery 100 epochs, Monte Carlo batch sizeM= 4096 per forward pass,PSCKmixi...
-
[2]
5 plots MAE ρ as a function of epoch across the sweep
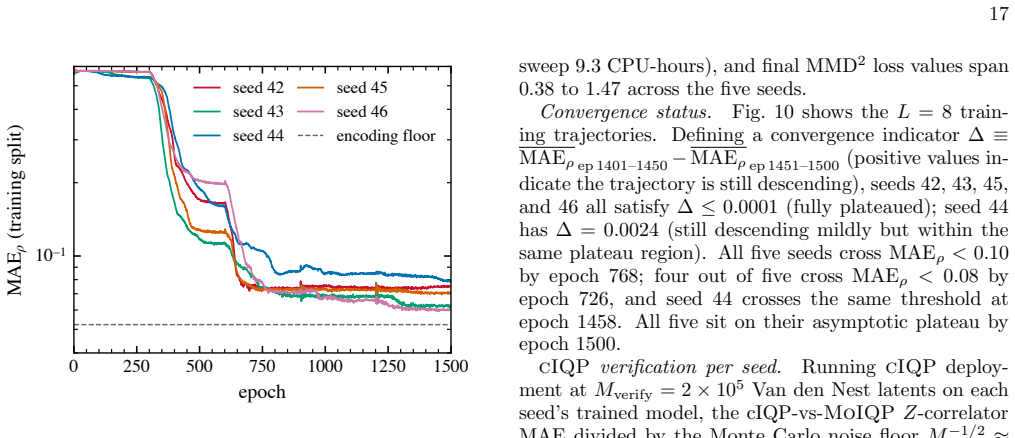
Convergence Fig. 5 plots MAE ρ as a function of epoch across the sweep. All five seeds descend past MAEρ = 0.08 between epoch 659 and epoch 1458 and sit on their respective asymptotic plateaus by epoch 1500 (see convergence indi- cator in Appendix D). The seed-wise min–max envelope is tight at late times; the ratio of maximum to minimum MAEρ across the fi...
-
[3]
The mean MAEρ = 0.069±0.008 is 0.017 above the encoding-fidelity floor MAEenc, train ρ = 0.052
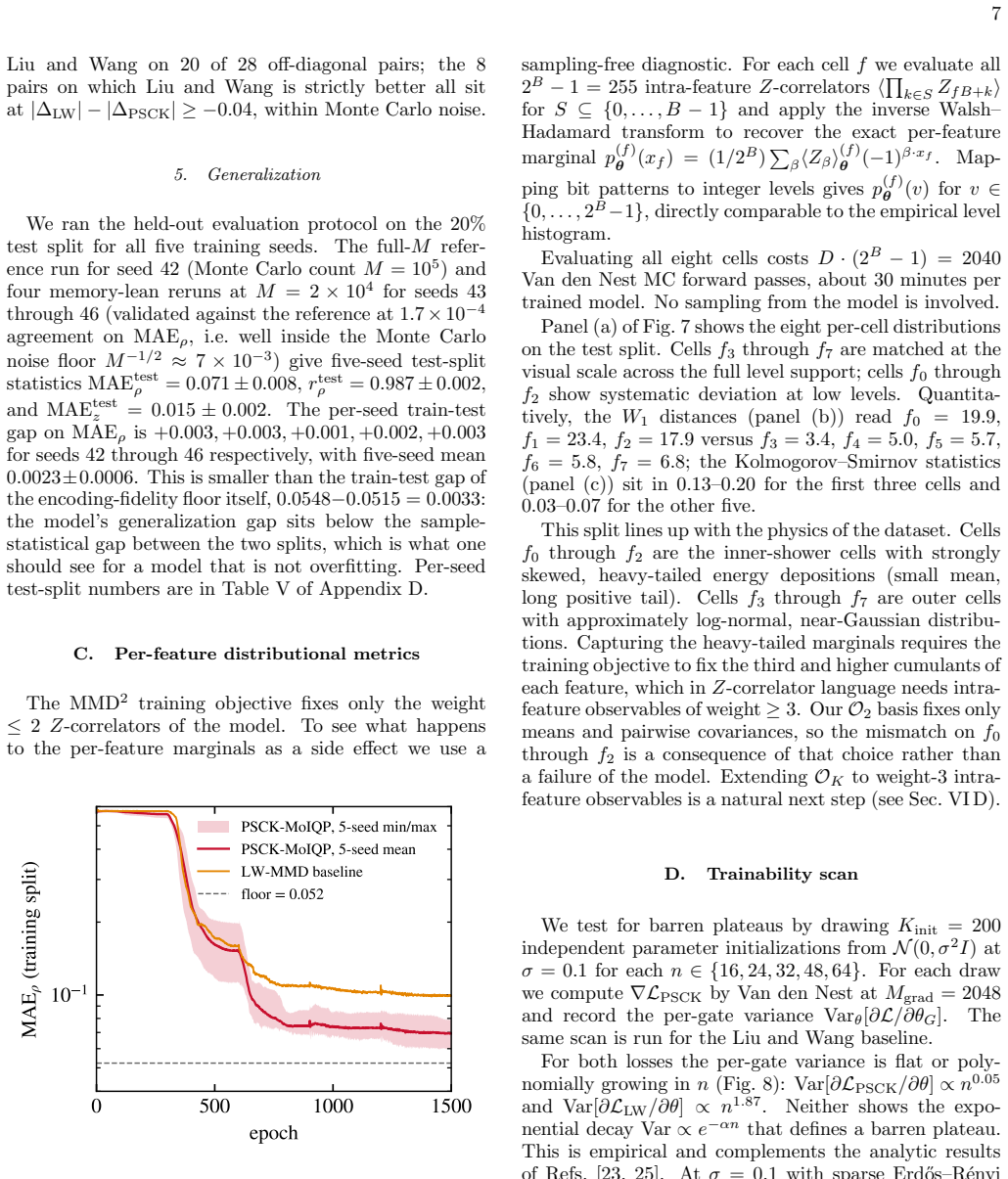
Main result Table I summarizes the five-seed sweep; per-seed num- bers are in Appendix D. The mean MAEρ = 0.069±0.008 is 0.017 above the encoding-fidelity floor MAEenc, train ρ = 0.052. The weight-2Z-correlator mean absolute error is MAEz = 0.011±0.002, near the Monte Carlo noise floor atM= 4096. All five seeds achieve MAE ρ <0.08 and converge (convergenc...
-
[4]
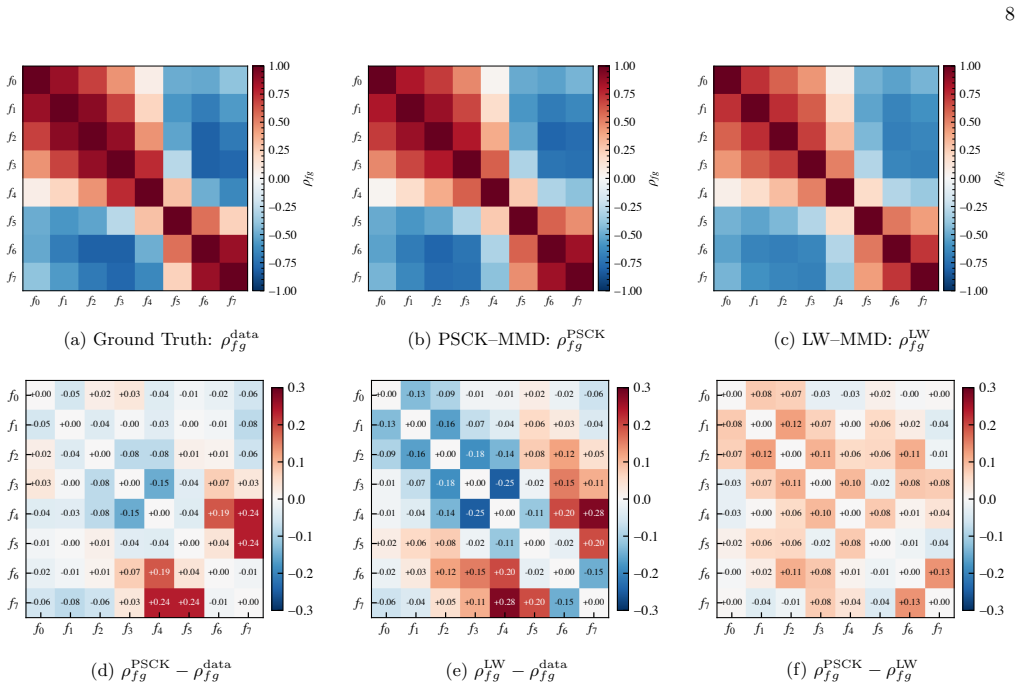
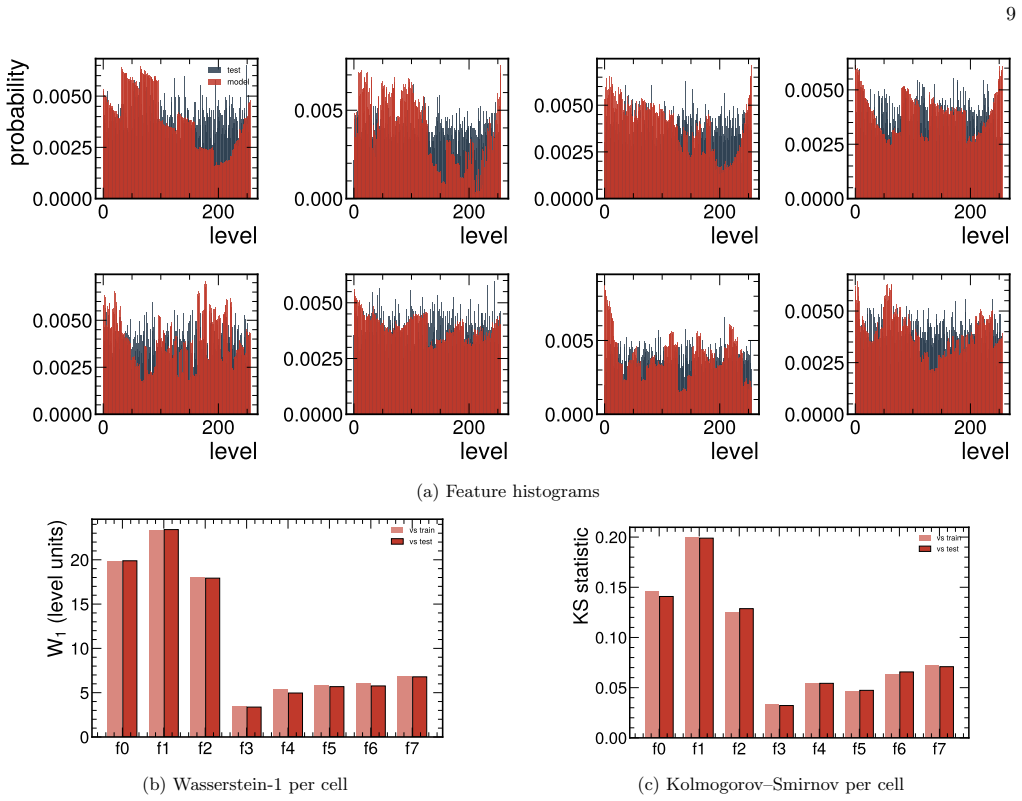
Pairwise correlation reconstruction The top row of Fig. 6 shows the recovered Pearson cor- relation matrixρ f g ofPSCK-MoIQP(middle) and the Liu and Wang baseline (right) against the training-split data (left).PSCKrecovers the full amplitude range of the data,|ρ| ∈[−0.85,+0.85], at the best seed (r ρ = 0.990, MAE ρ = 0.060), and averagesr ρ = 0.988±0.002 ...
-
[5]
Generalization We ran the held-out evaluation protocol on the 20% test split for all five training seeds. The full-Mrefer- ence run for seed 42 (Monte Carlo countM= 10 5) and four memory-lean reruns atM= 2×10 4 for seeds 43 through 46 (validated against the reference at 1.7×10 −4 agreement on MAE ρ, i.e. well inside the Monte Carlo noise floorM −1/2 ≈7×10...
2040
-
[6]
This work lives inside the framework of Refs
Train-on-classical, deploy-on-quantum framework. This work lives inside the framework of Refs. [21, 22], which showed that MMD 2 for IQP Born machines de- composes as a classically tractable Pauli-Zmixture and proposed the train-on-classical / deploy-on-quantum workflow. What we add is thePSCKkernel, the MoIQParchitecture, thecIQPcompilation, the IQP- 10 ...
-
[7]
Ball´ o-Gimbernat et al
Shallow-IQP graph generators. Ball´ o-Gimbernat et al. [24] ran shallow-IQP genera- tive models for Erd˝ os–R´ enyi and bipartite graph dis- tributions on real superconducting hardware at up to 153 qubits, with Liu and Wang heat-kernel MMD train- ing. Our contributions are complementary to theirs: a correlation-aligned kernel (PSCK), a mixture archi- tect...
-
[8]
HEP quantum-circuit Born machines. Refs. [10–12] train QCBMs and qGANs on HEP data at 8 to 12 qubits, with 2 or 3 features, on generic varia- tional architectures rather than IQP. This work extends the qubit count and feature dimensionality by about an order of magnitude, which is possible because the IQP MMD objective is classically trainable to begin wi...
-
[9]
the controlled-IQP unitary as a product of ancilla- indexed Pauli-Zrotations
-
[10]
the inverse-WHT relation between base angles and compiled angles
-
[11]
the deferred-measurement equivalence toMoIQP through a Walsh-sum identity on the ancilla out- come
-
[12]
All four parts are cross-checked numerically, which ver- ifies bit-level agreement betweencIQPandMoIQP marginals up to Monte Carlo noise
the gate-count and hardness analysis. All four parts are cross-checked numerically, which ver- ifies bit-level agreement betweencIQPandMoIQP marginals up to Monte Carlo noise. Notation and setup. Let the base gate graph beG={G 1, . . . , G|G|}with eachG j ⊆ {0, . . . , n−1}a subset of data qubits of weight |Gj| ∈ {1,2}. Denote the single-IQP unitary on pa...
-
[13]
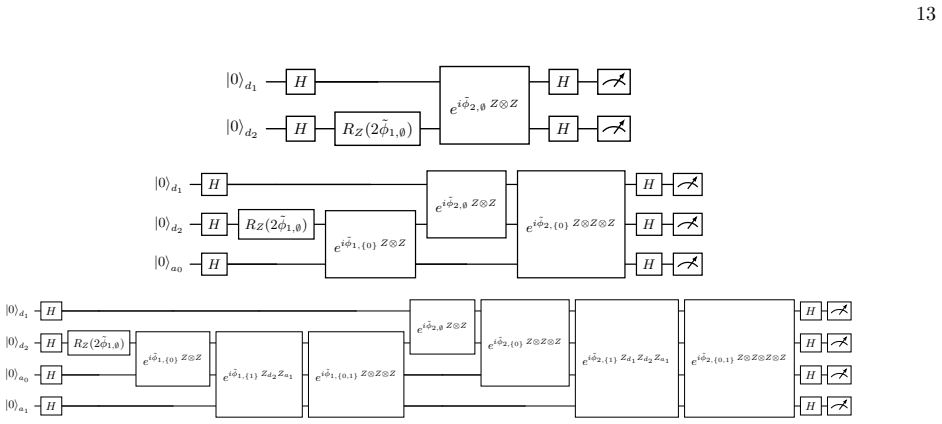
The cIQP unitary as a product ofZ⊗Zrotations Construct the compiled diagonal unitary onn+a qubits as DcIQP = |G|Y j=1 Y S⊆{0,...,a−1} ei ˜ϕj,S ZGj ⊗Zanc S ,(A3) with compiled angles{ ˜ϕj,S}to be determined. Every factor is a diagonal exponential of a Pauli-Zstring and all such strings commute, so the product is order inde- pendent andD cIQP is diagonal in...
-
[14]
Ancilla-conditional equivalence Fix an ancilla basis state|ℓ⟩ ∈C 2a and consider DcIQP(I ⊗n ⊗ |ℓ⟩⟨ℓ|). SinceZ anc S |ℓ⟩= (−1) ℓ·S|ℓ⟩, DcIQP · |ϕ⟩data ⊗ |ℓ⟩ = Y j,S ei ˜ϕj,S (−1)ℓ·S ZGj |ϕ⟩data ⊗ |ℓ⟩ = Y j eiΦ j(ℓ)Z Gj |ϕ⟩data ⊗ |ℓ⟩, (A5) 12 with the effective data-register angle Φj(ℓ) = X S⊆{0,...,a−1} (−1)ℓ·S ˜ϕj,S.(A6) Pick ˜ϕj,S so that Φ...
-
[15]
The leadingH ⊗(n+a) pre- pares|+⟩ ⊗n ⊗ |+⟩ ⊗a =|+⟩ ⊗n ⊗ 1√ L P ℓ |ℓ⟩
Deferred-measurement equivalence ApplyU cIQP to|0⟩ ⊗(n+a). The leadingH ⊗(n+a) pre- pares|+⟩ ⊗n ⊗ |+⟩ ⊗a =|+⟩ ⊗n ⊗ 1√ L P ℓ |ℓ⟩. Applying DcIQP and using Eq. (A5), DcIQP|+⟩⊗(n+a) = 1√ L L−1X ℓ=0 D(θ(ℓ))|+⟩⊗n ⊗ |ℓ⟩.(A12) The trailingH ⊗(n+a) =H ⊗n ⊗H ⊗a then gives U cIQP|0⟩⊗(n+a) = 1√ L L−1X ℓ=0 U(θ (ℓ))|0⟩⊗n ⊗H ⊗a|ℓ⟩. (A13) Measuring alln+aqubits in the c...
-
[16]
(A3) the compiled diagonal contains one Z⊗Z-phase rotation per (j, S) pair
Gate count and gate weights From Eq. (A3) the compiled diagonal contains one Z⊗Z-phase rotation per (j, S) pair. Ignoring accidental zero-angle prunings, the number of compiled gates is |GcIQP|=|G| ·L,(A16) i.e. each base gate expands intoLcompiled gates, one per ancilla subsetS. For the headlinen= 64,L= 8 configuration this gives|G cIQP|in the range 2048...
2048
-
[17]
The generative-modeling deployment only ever uses the marginal of Eq
Sampling hardness We distinguish two sampling tasks: the joint (n+a)- qubit distribution and the data-onlyn-qubit marginal. The generative-modeling deployment only ever uses the marginal of Eq. (A15). The joint is not operationally relevant. For thejoint,U cIQP is IQP-form onn+aqubits by construction. The original Bremner–Jozsa–Shepherd [18] argument was ...
-
[18]
Numerical verification Two independent numerical routines cover this con- struction and are provided with the code companion of this paper. One runs exact wavefunction simula- tion at smalln(≤4) and verifies machine-precision agreement between thecIQPdata-register marginal and the directMoIQPdistribution, with measured error maxx |Pr cIQP(x)−p MoIQP(x)|<5...
-
[19]
Setup and bit-level expectations.Featuref∈ {0,
Derivations a. Setup and bit-level expectations.Featuref∈ {0, . . . , D−1}is encoded asBbitsb f,0, . . . , bf,B−1 ∈ {0,1}on qubitsf B, f B+ 1, . . . , f B+B−1, with recon- struction Sf = B−1X k=0 wk bf,k , w k = 2 B−1−k (B1) so thatW≡ P k wk = 2 B −1. The single-qubit ex- pectationz 1;f,k ≡ ⟨Z f B+k⟩and two-qubit expectation z2;(f k),(gl) ≡ ⟨Z f B+k ZgB+l...
-
[20]
Because Jis evaluated at the data, it is built once at the start of training and reused for every gradient step
Complexity The full (P×K) Jacobian withP=D(D−1)/2 andK=DB+D B 2 + D 2 B2 =|O 2|is computed in O(P B2 +D 2B2) time via the formulas above. Because Jis evaluated at the data, it is built once at the start of training and reused for every gradient step. AtD= 8, B= 8 this is 28×2080 = 5.8×10 4 Jacobian entries and the build time is a few milliseconds, negligi...
2080
-
[21]
Numerical verification The verification code runs a central-difference finite- difference verification of the full Jacobian against the training data routine atD= 8,B= 2,K= 136, with rel- ative error 5.08×10−11, at the noise floor of symmetric fi- nite differences with stepε= 10 −5 in double precision. A second companion code implements the closed-form fo...
-
[22]
Scan protocol For eachn∈ {16,24,32,48,64}(feature countsD= 8 and bit countsB∈ {2,3,4,6,8}) we perform the follow- ing routine:
-
[23]
draw a fresh Erd˝ os–R´ enyi gate graphGn at average degree 6 with graph seed 43
-
[24]
sampleK init = 200 independent parameter vectors θ(k) ∼ N(0, σ 2I) atσ= 0.1
-
[25]
for each initialization, evaluate the full loss gradient ∇LviaM grad = 2048 Van den Nest latents
2048
-
[26]
All reported statistics useK init = 200 inits pern, for bothPSCK(η= 5) and the Liu and Wang baseline
record the per-gate gradient component variance, the gradient-norm-squared∥∇L∥ 2, and the loss valueL(θ (k)). All reported statistics useK init = 200 inits pern, for bothPSCK(η= 5) and the Liu and Wang baseline. The total sample size underlying the per-gate-variance columns of Table II isK init · |Gn|, from 12 800 atn= 16 to 55 200 atn= 64. n|G| pgvPSCK s...
-
[27]
The fit parameters, PSCK:b= +0.055±0.255, R 2 = 0.015 LW :b= +1.874±0.049, R 2 = 0.998
Polynomial fits We fit each pgv(n) curve in Table II by OLS on the log– log axes, log pgv = logA+blogn. The fit parameters, PSCK:b= +0.055±0.255, R 2 = 0.015 LW :b= +1.874±0.049, R 2 = 0.998. (C1) ThePSCKslope is indistinguishable from zero at this scan resolution (|b|/s.e.= 0.22). The per-gate variance is consistent with constant behavior acrossn∈ {16, ....
-
[28]
Fitting this hypothesis to the same data givesc PSCK = 7×10 −4 (indistinguishable from zero;R 2 = 0.003) andc LW =−5.2×10 −2 (nega- tive, i.e
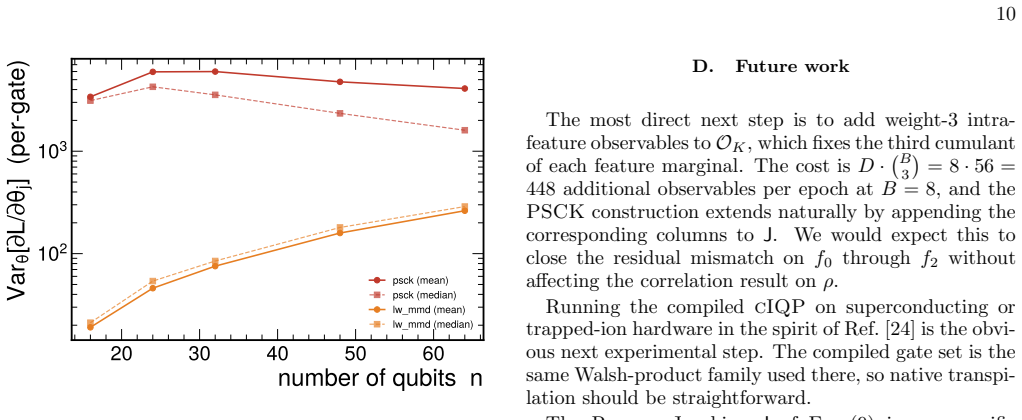
Ruling out exponential decay A barren plateau is canonically an exponential decay Var∝a e −cn withc >0. Fitting this hypothesis to the same data givesc PSCK = 7×10 −4 (indistinguishable from zero;R 2 = 0.003) andc LW =−5.2×10 −2 (nega- tive, i.e. growth, which is just polynomial scaling re-fit). Comparison by residual sum-of-squares shows that for LW the ...
-
[29]
Log–log fits give∥∇L PSCK∥2 ∝n 1.14±0.20 and LPSCK ∝n 0.88±0.13 forPSCK, and∥∇L LW∥2 ∝ n2.95±0.01 and LLW ∝n 1.80±0.02 for Liu and Wang
Gradient-norm and loss-value scaling Table III lists the total gradient norm squared∥∇L∥ 2 and the mean loss value Lacross the sameK init = 200 inits. Log–log fits give∥∇L PSCK∥2 ∝n 1.14±0.20 and LPSCK ∝n 0.88±0.13 forPSCK, and∥∇L LW∥2 ∝ n2.95±0.01 and LLW ∝n 1.80±0.02 for Liu and Wang. n ∥∇LPSCK∥2 LPSCK ∥∇LL W∥2 LL W 16 2.17×10 5 4.22×10 2 1.22×10 3 3.28...
-
[30]
Absolute versus relative gradient strength Table II shows aPSCK-over-LW gradient advantage ranging from 178×atn= 16 down to 15.6×atn= 64 in absolute terms. As a statement about trainability this is misleading:PSCKand Liu and Wang have different loss scales (Table III, columns 3 and 5), and Adam-type optimizers rescale step sizes by running second-moment e...
-
[31]
no exponential de- cay
Limitations Three explicit limitations of the scan. First, single graph realization pern. Eachnuses one ER graph at graph-seed 43, so graph-to-graph fluctuations at fixed (n,⟨k⟩) are not sampled. The residual variance in the PSCKpgv fit (R 2 = 0.015) is plausibly dominated by that source. A multi-graph extension would tighten the empirical slope bound onP...
2048
-
[32]
CaloChallenge 2022: A com- munity challenge for fast calorimeter simulation,
C. Krauseet al., “CaloChallenge 2022: A com- munity challenge for fast calorimeter simulation,” arXiv:2410.21611 (2024)
-
[33]
AtlFast3: The next generation of fast simulation in ATLAS,
ATLAS Collaboration, “AtlFast3: The next generation of fast simulation in ATLAS,” Comput. Softw. Big Sci. 6, 7 (2022)
2022
-
[34]
CaloGAN: Simulating 3D high-energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks,
M. Paganini, L. de Oliveira, B. Nachman, “CaloGAN: Simulating 3D high-energy particle showers in multilayer electromagnetic calorimeters with generative adversarial networks,” Phys. Rev. D97, 014021 (2018)
2018
-
[36]
Fast and accurate simulations of calorimeter showers with normalizing flows,
C. Krause, D. Shih, “Fast and accurate simulations of calorimeter showers with normalizing flows,” Phys. Rev. D107, 113003 (2023)
2023
-
[37]
Induc- tive simulation of calorimeter showers with normalizing flows,
M.R. Buckley, I. Pang, D. Shih, C. Krause, “Induc- tive simulation of calorimeter showers with normalizing flows,” Phys. Rev. D109, 033006 (2024)
2024
-
[38]
AllShowers: One model for all calorimeter showers,
T. Busset al., “AllShowers: One model for all calorimeter showers,” arXiv:2601.11716 (2026)
-
[39]
CaloScore v2: Single-shot calorimeter shower simulation with diffusion models,
V. Mikuni, B. Nachman, “CaloScore v2: Single-shot calorimeter shower simulation with diffusion models,” JINST19, P02001 (2024)
2024
-
[40]
CaloDREAM: Detector response emulation via atten- tive flow matching,
L. Favaro, A. Ore, S. Palacios Schweitzer, T. Plehn, “CaloDREAM: Detector response emulation via atten- tive flow matching,” SciPost Phys.18, 088 (2025)
2025
-
[41]
Unsupervised quantum cir- cuit learning in high-energy physics,
A. Delgado, K.E. Hamilton, “Unsupervised quantum cir- cuit learning in high-energy physics,” Phys. Rev. D106, 096006 (2022)
2022
-
[42]
Condi- tional Born machine for Monte Carlo event generation,
O. Kiss, M. Grossi, E. Kajomovitz, S. Vallecorsa, “Condi- tional Born machine for Monte Carlo event generation,” Phys. Rev. A106, 022612 (2022)
2022
-
[43]
Full quantum generative adver- sarial networks for high-energy physics simulations,
S.Y. Changet al., “Full quantum generative adver- sarial networks for high-energy physics simulations,” arXiv:2305.07284 (2023)
-
[44]
CaloQVAE: Simulating high-energy particle-calorimeter interactions using hybrid quantum- classical generative models,
S. Hoqueet al., “CaloQVAE: Simulating high-energy particle-calorimeter interactions using hybrid quantum- classical generative models,” Eur. Phys. J. C84, 1 (2024)
2024
-
[45]
The Born supremacy: Quantum advantage and training of an Ising Born machine,
B. Coyle, D. Mills, V. Danos, E. Kashefi, “The Born supremacy: Quantum advantage and training of an Ising Born machine,” npj Quantum Inf.6, 60 (2020). 18 training split (final epoch) held-out test split seed MAE ρ rρ MAEz MAEρ rρ MAEz gap 42 0.0749 0.9879 0.0099 0.0772 0.9870 0.0137 +0.0030 43 0.0624 0.9898 0.0098 0.0646 0.9889 0.0138 +0.0026 44 0.0790 0....
2020
-
[46]
Barren plateaus in quantum neu- ral network training landscapes,
J.R. McCleanet al., “Barren plateaus in quantum neu- ral network training landscapes,” Nat. Commun.9, 4812 (2018)
2018
-
[47]
Cost function dependent barren plateaus in shallow parametrized quantum circuits,
M. Cerezoet al., “Cost function dependent barren plateaus in shallow parametrized quantum circuits,” Nat. Commun.12, 1791 (2021)
2021
-
[48]
Temporally unstructured quantum computation,
D. Shepherd, M.J. Bremner, “Temporally unstructured quantum computation,” Proc. R. Soc. A465, 1413 (2009)
2009
-
[49]
Classical simu- lation of commuting quantum computations implies col- lapse of the polynomial hierarchy,
M.J. Bremner, R. Jozsa, D.J. Shepherd, “Classical simu- lation of commuting quantum computations implies col- lapse of the polynomial hierarchy,” Proc. R. Soc. A467, 459 (2011)
2011
-
[50]
Average- case complexity versus approximate simulation of com- muting quantum computations,
M.J. Bremner, A. Montanaro, D.J. Shepherd, “Average- case complexity versus approximate simulation of com- muting quantum computations,” Phys. Rev. Lett.117, 080501 (2016)
2016
-
[51]
Simulating quantum computers with probabilistic methods
M. Van den Nest, “Simulating quantum computers with probabilistic methods,” arXiv:0911.1624 (2010)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[52]
Trainability barriers and opportu- nities in quantum generative modeling,
M.S. Rudolphet al., “Trainability barriers and opportu- nities in quantum generative modeling,” npj Quantum Inf.10, 116 (2024)
2024
-
[53]
E. Recio-Armengol, S. Ahmed, J. Bowles, “Train on classical, deploy on quantum: Scaling genera- tive quantum machine learning to a thousand qubits,” arXiv:2503.02934 (2025)
-
[54]
IQP Born machines under data-dependent and agnostic initialization strategies,
S. Lerch, J. Bowles, R. Puig, E. Recio-Armengol, Z. Holmes, S. Thanasilp, “IQP Born machines under data-dependent and agnostic initialization strategies,” arXiv:2603.14576 (2026)
-
[55]
Shallow IQP circuits and graph generation,
O. Ball´ o-Gimbernatet al., “Shallow IQP circuits and graph generation,” arXiv:2511.05267 (2025); Phys. Rev. A (in press)
-
[56]
Characterizing trainability of instan- taneous quantum polynomial circuit Born machines,
S. Hakkakuet al., “Characterizing trainability of instan- taneous quantum polynomial circuit Born machines,” arXiv:2602.11042 (2026)
-
[57]
Differentiable learning of quantum cir- cuit Born machines,
J. Liu, L. Wang, “Differentiable learning of quantum cir- cuit Born machines,” Phys. Rev. A98, 062324 (2018)
2018
-
[58]
Improved separation between quantum and classical computers for sampling and functional tasks,
S. C. Marshall, S. Aaronson, V. Dunjko, “Improved separation between quantum and classical computers for sampling and functional tasks,” arXiv:2410.20935 (2024); in40th Computational Complexity Conference (CCC 2025), LIPIcs Vol. 339, pp. 5:1–5:14, Schloss Dagstuhl, Leibniz-Zentrum f¨ ur Informatik (2025), doi:10.4230/LIPIcs.CCC.2025.5
-
[59]
S. Monaco, J. Slim, K. Borras, D. Kr¨ ucker, “clic (v1.0.0),” Zenodo (2025), doi:10.5281/zenodo.16027525. Downsampled from the CLIC single-particle electron- shower dataset in the Ele FixedAngle format; code at github.com/desyqml/clic
-
[60]
IQPopt: Fast optimization of instantaneous quantum polynomial circuits in JAX
E. Recio-Armengol and J. Bowles, “IQPopt: Fast opti- mization of instantaneous quantum polynomial circuits in JAX,” arXiv:2501.04776 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.