Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows
Pith reviewed 2026-06-29 12:49 UTC · model grok-4.3
The pith
Agent capability must be evaluated at the model-harness configuration level rather than by base model alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
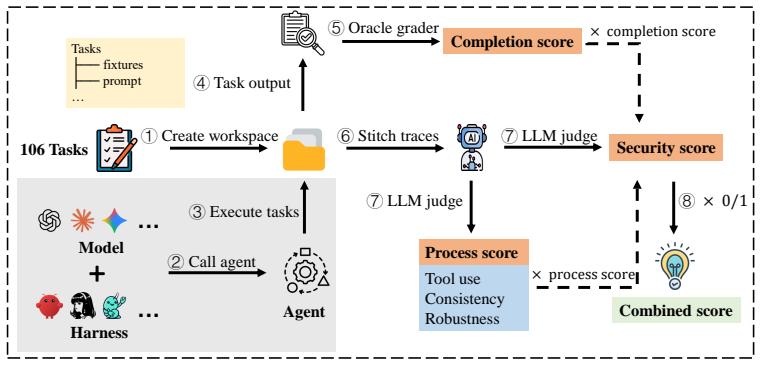
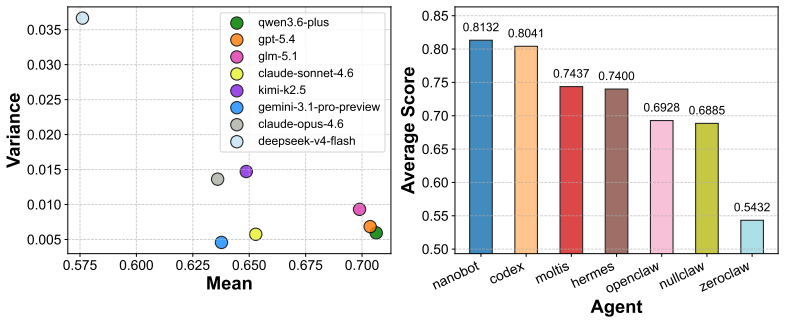
Harness-Bench measures harness effects by evaluating representative configurations across model backends on shared tasks while preserving native execution behavior. Across 5,194 trajectories, it finds substantial variation in completion, efficiency, and failure behavior, supporting the claim that agent capability depends on the model-harness pair.
What carries the argument
The harness, the system layer managing context, tools, state, constraints, permissions, tracing, and recovery in agent workflows.
If this is right
- Agent performance reports should specify the full model-harness configuration.
- Comparisons between models require testing under multiple harness setups to be valid.
- Execution traces from the benchmark enable diagnosis of alignment failures between reasoning and tool feedback.
- Future agent systems can use the benchmark to improve reliability by addressing recurring failure patterns.
Where Pith is reading between the lines
- Current public leaderboards for agents may overstate or understate model differences due to harness variation.
- Developers might need to optimize harnesses specifically for certain models to achieve best results.
- Standardizing harness interfaces could reduce the observed configuration-dependent effects.
Load-bearing premise
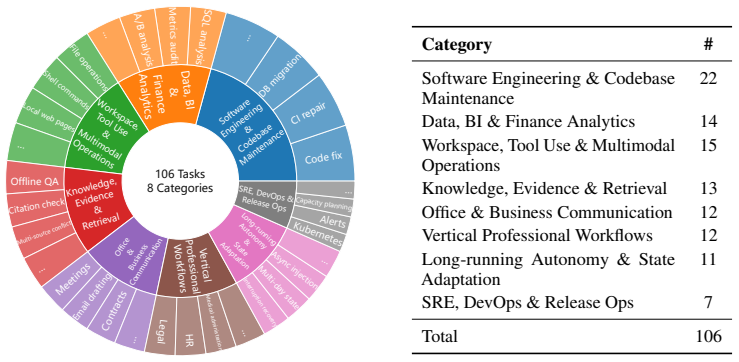
The 106 tasks, drawn from practical patterns and reviewed for realism, adequately represent the range of real-world agent workflows.
What would settle it
A replication study using a larger or differently constructed set of tasks that finds no substantial performance variation across harness configurations for the same models.
Figures
read the original abstract
LLM agents are increasingly deployed as executable systems that use tools, modify workspaces, and produce concrete artifacts. In such workflows, performance depends not only on the base model, but also on the harness: the system layer that manages context, tools, state, constraints, permissions, tracing, and recovery. However, existing benchmarks typically abstract away execution, compare complete agent systems, or hold the harness fixed, making execution-layer variation difficult to study. We introduce Harness-Bench, a diagnostic benchmark for evaluating configuration-level harness effects in realistic agent workflows. Harness-Bench evaluates representative harness configurations across multiple model backends under shared task environments, budgets, and evaluation protocols, while preserving each harness's native execution behavior. The benchmark contains 106 sandboxed offline tasks constructed from practical agent-use patterns and manually reviewed for realism, solvability, oracle-checkability, and integrity. Each run records final artifacts, execution traces, usage statistics, and validator outputs, enabling analysis beyond final completion. Across 5,194 execution trajectories, we observe substantial variation in completion, process quality, efficiency, and failure behavior across model-harness pairings. These results suggest that agent capability should be reported at the model-harness configuration level rather than attributed to the base model alone. Our analysis further identifies recurring execution-alignment failures, where plausible reasoning becomes decoupled from tool feedback, workspace state, evidence, or verifiable output contracts. Harness-Bench provides a reproducible foundation for diagnosing and improving reliable, efficient, and auditable agent execution stacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Harness-Bench, a diagnostic benchmark consisting of 106 sandboxed offline tasks constructed from practical agent-use patterns. It evaluates representative harness configurations across multiple model backends under shared environments and protocols, recording 5,194 trajectories that show substantial variation in completion, process quality, efficiency, and failure behavior. The central claim is that these results justify reporting agent capability at the model-harness configuration level rather than the base model alone, while also identifying recurring execution-alignment failures.
Significance. If the tasks prove representative, the work would be significant for LLM agent evaluation by providing a reproducible foundation for isolating execution-layer effects and diagnosing alignment failures between reasoning and tool/workspace state. Explicit strengths include the sandboxed design, preservation of native harness behavior, detailed trace and validator recording, and focus on oracle-checkable tasks; these enable analyses beyond final success rates.
major comments (2)
- [Task construction and validation] Task construction and validation (described in the methods section on the 106 tasks): the assertion of representativeness rests solely on construction from practical patterns plus manual review for realism/solvability/oracle-checkability, with no quantitative distributional statistics (tool-call sequences, state-transition complexity, recovery patterns, or nondeterminism) compared against real deployed agent logs or usage corpora. This is load-bearing for the generalization that observed harness effects reflect intrinsic execution-layer variation rather than benchmark artifacts.
- [Results and analysis] Results and analysis section (reporting variation across 5,194 trajectories): the manuscript states 'substantial variation' and identifies recurring execution-alignment failures but supplies no details on the statistical tests, effect-size measures, or controls for multiple comparisons used to establish that differences across the five harness configurations are significant and not driven by task-specific artifacts.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly quantify key metrics (e.g., range of completion-rate deltas across harnesses) rather than relying on the qualitative phrase 'substantial variation'.
- [Introduction/Methods] Notation for harness configurations and model backends should be introduced with a clear table or diagram early in the paper to aid readability of the experimental matrix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with honest responses and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Task construction and validation] Task construction and validation (described in the methods section on the 106 tasks): the assertion of representativeness rests solely on construction from practical patterns plus manual review for realism/solvability/oracle-checkability, with no quantitative distributional statistics (tool-call sequences, state-transition complexity, recovery patterns, or nondeterminism) compared against real deployed agent logs or usage corpora. This is load-bearing for the generalization that observed harness effects reflect intrinsic execution-layer variation rather than benchmark artifacts.
Authors: We agree that quantitative distributional statistics compared to real deployed agent logs would strengthen the claim of representativeness. Such data is not available to us, as it would require access to private usage logs from deployed systems. Our tasks were constructed from practical patterns and underwent manual review. We will revise the manuscript to explicitly discuss this limitation in the methods or discussion section and outline plans for future validation against available corpora where possible. The benchmark remains valuable for its controlled, oracle-checkable design that isolates harness effects. revision: partial
-
Referee: [Results and analysis] Results and analysis section (reporting variation across 5,194 trajectories): the manuscript states 'substantial variation' and identifies recurring execution-alignment failures but supplies no details on the statistical tests, effect-size measures, or controls for multiple comparisons used to establish that differences across the five harness configurations are significant and not driven by task-specific artifacts.
Authors: We concur that including statistical details would enhance the analysis. In the revised version, we will incorporate a statistical analysis subsection detailing the tests used (such as appropriate non-parametric tests for completion rates and efficiency metrics), effect sizes, and adjustments for multiple comparisons. We will also address potential task-specific artifacts by reporting variance across tasks and overall patterns. This addition will be made without altering the core findings. revision: yes
Circularity Check
No circularity: empirical benchmark with no derivations or fitted reductions
full rationale
The paper presents an empirical benchmark (106 tasks, 5,194 trajectories) without equations, parameters fitted to subsets then re-predicted, or self-citation chains that bear the central claim. The claim that capability should be reported at the model-harness level follows directly from observed variation across configurations; no step reduces by construction to its own inputs. This is the expected non-finding for a benchmark-introduction paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
RealClawBench: Live OpenClaw Benchmarks from Real Developer-Agent Sessions
RealClawBench turns 281 real OpenClaw sessions into reproducible tasks that preserve the original distribution and shows the best of 14 models solves only 65.8 percent.
Reference graph
Works this paper leans on
-
[1]
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, et al
URLhttps://openreview.net/forum?id=VTF8yNQM66. Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, et al. Holistic agent leaderboard: The missing infrastructure for ai agent evaluation, 2025. URLhttps://arxiv.org/abs/2510.11977. Percy Liang, Rishi Bommasani, Tony Lee, et al. Holistic evaluation of language models.Transactions on Machine Learning Research, 2023...
-
[2]
Claw-Eval: Towards Trustworthy Evaluation of Autonomous Agents
ISSN 2835-8856. URL https://openreview.net/forum?id=uyTL5Bvosj. Featured Certification. Qingyun Wu, Gagan Bansal, Jieyu Zhang, et al. Autogen: Enabling next-gen LLM applications via multi-agent conversations. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=BAakY1hNKS. 10 Tianbao Xie, Danyang Zhang, Jixuan Chen, et al. O...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.52202/079017-1601 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.