Qwen-Image-Bench: From Generation to Creation in Text-to-Image Evaluation
Pith reviewed 2026-06-29 14:02 UTC · model grok-4.3
The pith
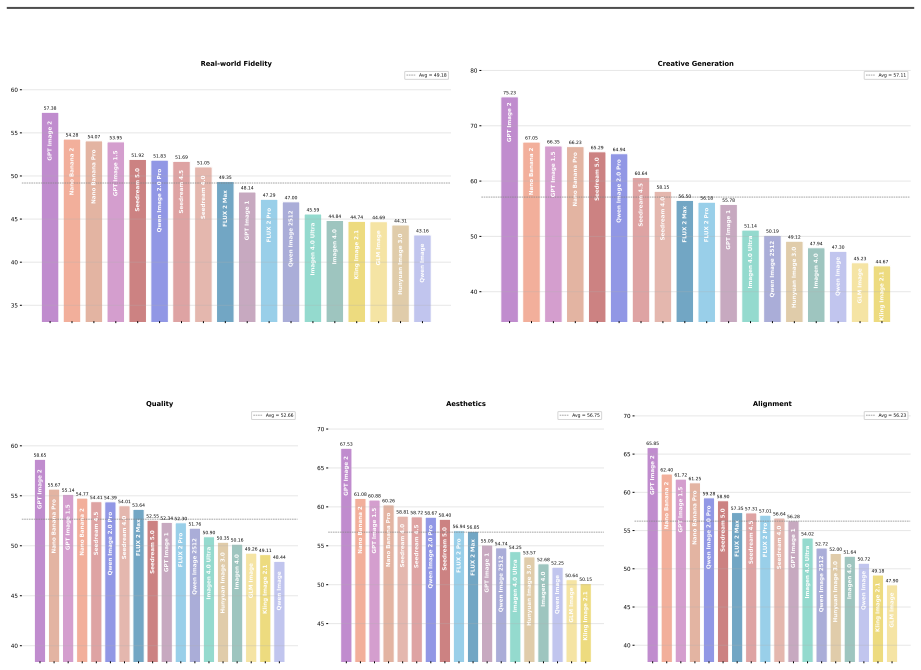
Qwen-Image-Bench distinguishes leading text-to-image models most effectively on real-world fidelity and creative generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
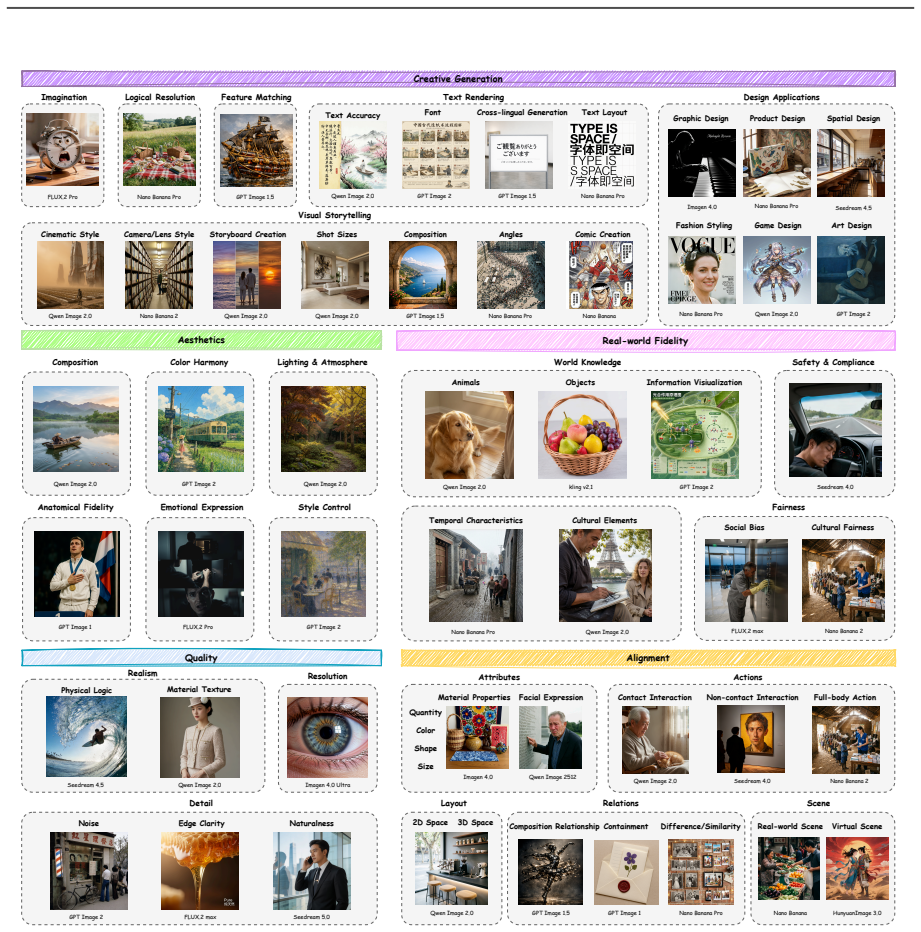
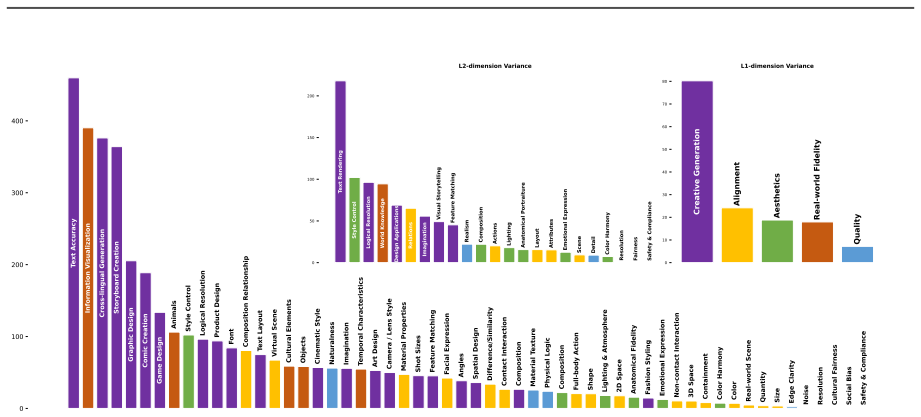
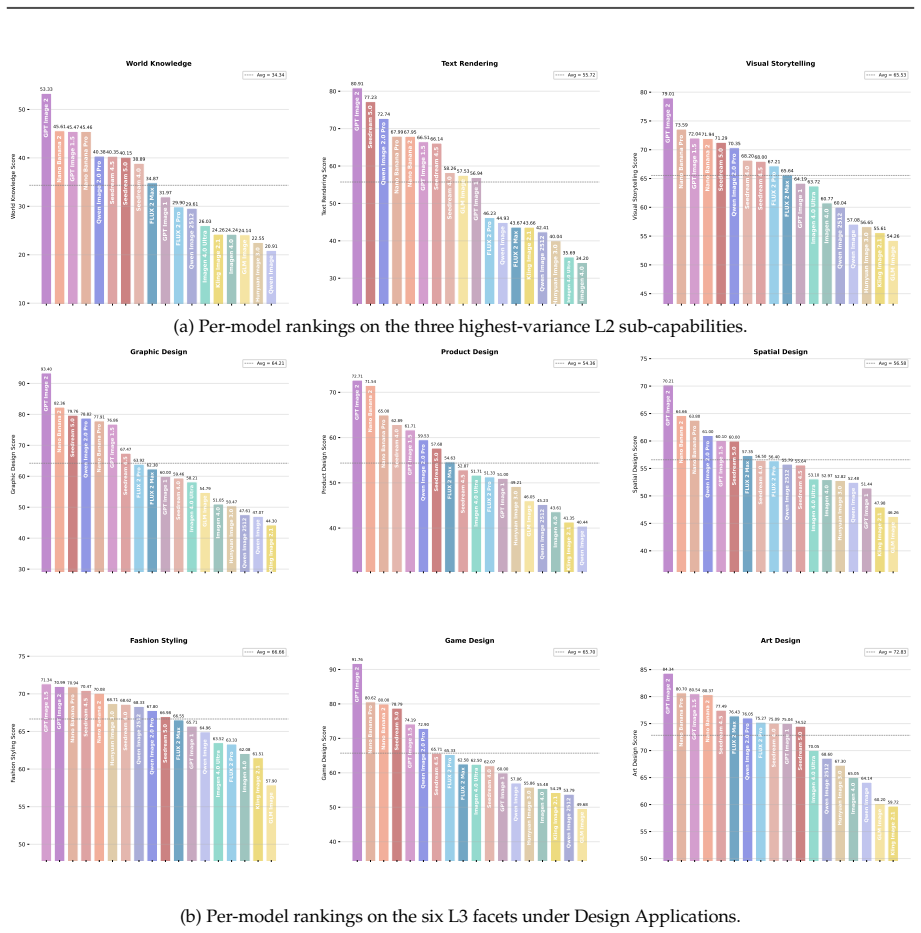
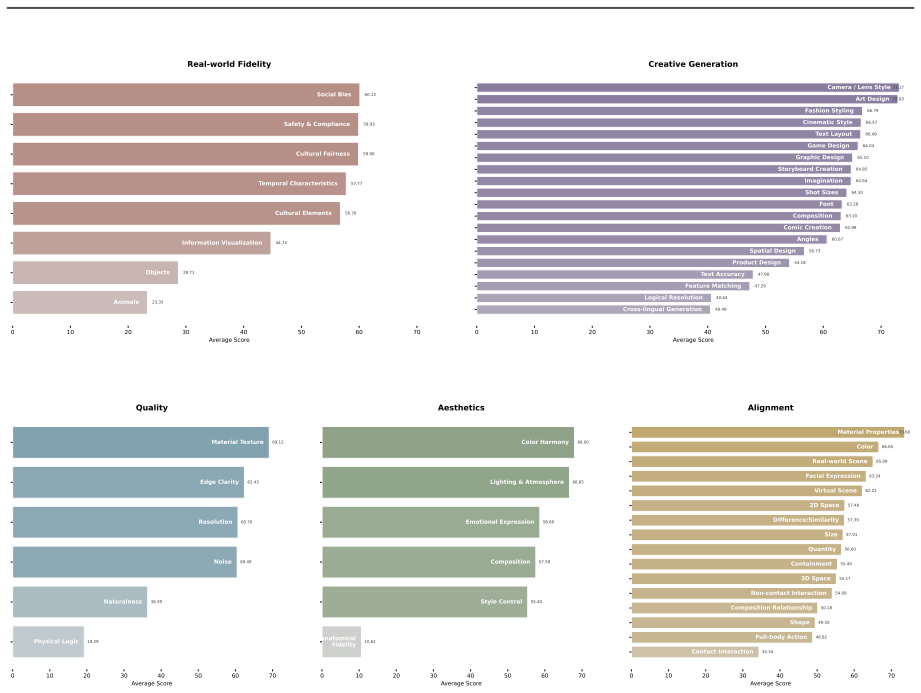
Qwen-Image-Bench is a creator-centric benchmark co-designed with professional artists that enriches conventional evaluation with Real-world Fidelity and Creative Generation dimensions, structured as a top-down hierarchical taxonomy decomposing into 23 second-level sub-capabilities and 56 third-level verifiable rubrics, supported by 1000 stratified prompts each exercising more than four fine-grained facets, and a unified judge model Q-Judger trained on blind triple-reviewed scores from 80 professional annotators to deliver rubric-grounded diagnostics that reliably distinguish leading T2I models with greatest separation on the two new dimensions.
What carries the argument
The top-down hierarchical taxonomy of five pillars into 23 sub-capabilities and 56 verifiable rubrics, paired with Q-Judger trained under professional annotator supervision to produce fine-grained scores.
If this is right
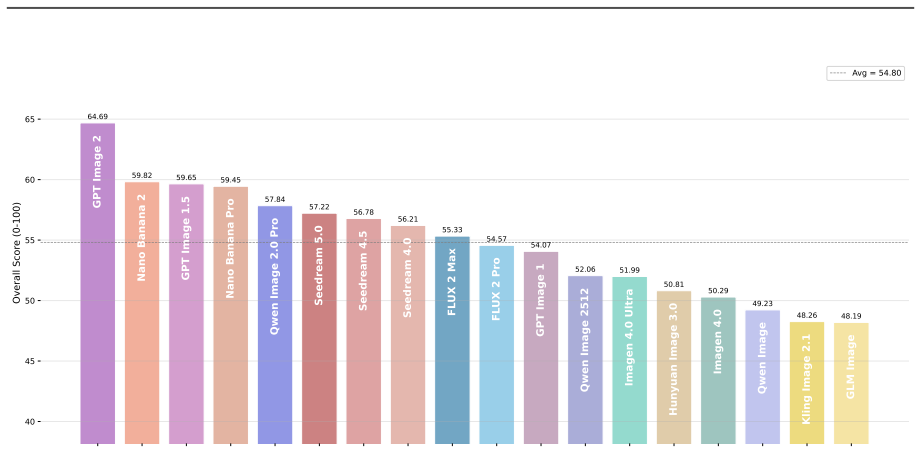
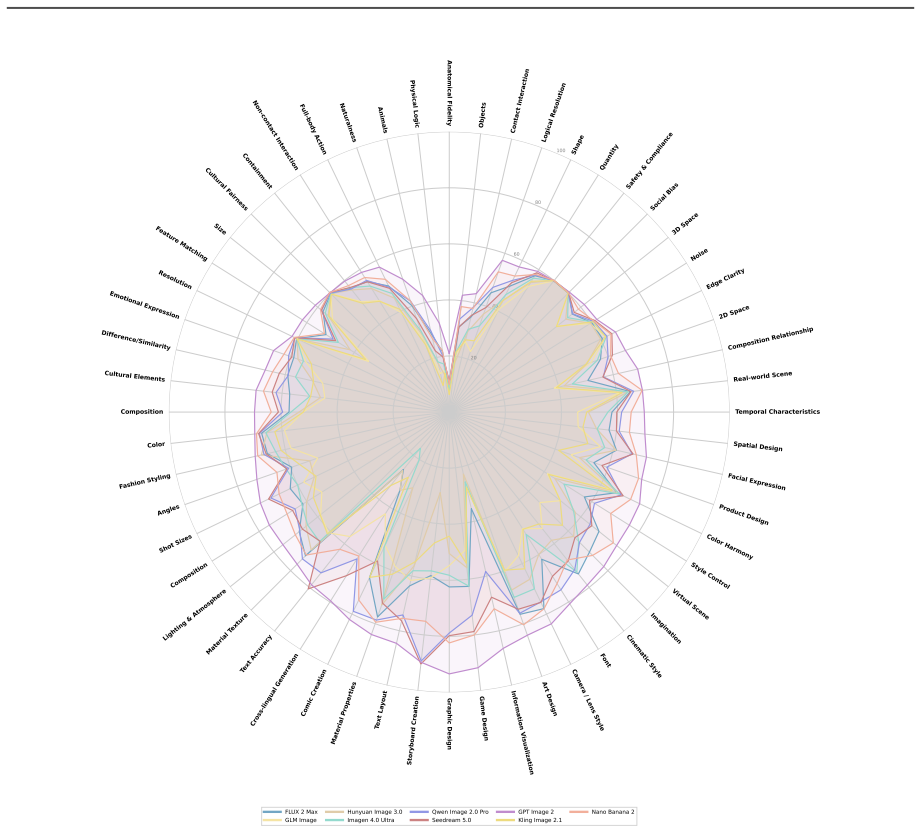
- Leading T2I models achieve the greatest separation on Real-world Fidelity and Creative Generation compared with existing benchmarks.
- The benchmark supplies a trustworthy optimization signal for production-level T2I development.
- Every image receives fine-grained, rubric-grounded, and fully attributable diagnostics across all 56 facets rather than a single opaque score.
- The 1000 prompts provide broad coverage by jointly exercising more than four fine-grained facets across multiple pillars.
- Existing benchmarks provide little insight on the application-driven dimensions of real-world fidelity and creative generation.
Where Pith is reading between the lines
- The rubric structure could be reused to create similar hierarchical evaluations for other generative modalities such as video or 3D.
- Fine-grained diagnostics might enable targeted training loops that improve specific sub-capabilities instead of overall scores.
- The stratified prompt design and annotator protocol suggest a template for building stable human-AI evaluation pipelines in other creative domains.
Load-bearing premise
The 80 professional annotators' blind triple-reviewed scores on the 56 rubrics form an accurate and stable ground truth for artistic quality that generalizes beyond the specific 1000 prompts and annotator pool.
What would settle it
Q-Judger scores on a new set of prompts or models fail to match independent professional artist judgments collected under the same blind triple-review protocol, or fail to show separation on Real-world Fidelity and Creative Generation.
Figures

read the original abstract
Text-to-Image generation has evolved from basic image synthesis into a frequently used core capability in professional creative workflows, where simple text-image alignment can no longer satisfy users' pressing demands for faithful real-world reconstruction and genuine creative expression. Existing benchmarks, however, remain anchored in these foundational criteria and do not yet capture the nuanced capabilities that matter in authentic artistic practice, making it difficult to reliably distinguish state-of-the-art T2I models. To address the gap, we introduce Qwen-Image-Bench, a creator-centric benchmark co-designed with professional artists and grounded in real-world creation scenarios. Qwen-Image-Bench enriches conventional evaluation with two application-driven dimensions: Real-world Fidelity and Creative Generation. Drawing on the staged reasoning inherent in professional artistic workflows, we organize these five pillars into a top-down hierarchical taxonomy that further decomposes into 23 second-level sub-capabilities and 56 third-level verifiable rubrics. To ensure broad coverage, we curate 1000 stratified prompts with each prompt jointly exercising more than four fine-grained facets across multiple pillars. We train a unified judge model Q-Judger based on Qwen3.6-27B, supervised by 80 professional annotators from global art academies under blind labeling and triple-review protocols, that scores every image across all 56 verifiable facets, producing fine-grained, rubric-grounded, and fully attributable diagnostics rather than a single opaque score. Empirically, Qwen-Image-Bench reliably distinguishes leading T2I models, achieving the greatest separation on the two application-driven dimensions of Real-world Fidelity and Creative Generation where existing benchmarks provide little insight, while also providing a trustworthy optimization signal for production-level T2I development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Qwen-Image-Bench, a creator-centric T2I benchmark co-designed with artists that adds Real-world Fidelity and Creative Generation dimensions to existing criteria. It defines a top-down taxonomy with 23 sub-capabilities and 56 verifiable rubrics, curates 1000 stratified prompts each exercising multiple facets, and trains Q-Judger (based on Qwen3.6-27B) on blind triple-reviewed scores from 80 professional annotators to produce fine-grained, attributable diagnostics. The central empirical claim is that the benchmark reliably separates leading T2I models, with greatest separation on the two new application-driven dimensions.
Significance. If the annotator-derived supervision for Q-Judger is shown to be stable and generalizable, the benchmark could supply actionable, rubric-level signals for production T2I development on creative and fidelity aspects that current benchmarks do not resolve.
major comments (2)
- [Q-Judger training and validation] Abstract and § on Q-Judger: the claim that Q-Judger supplies a 'trustworthy optimization signal' and enables 'reliable' model separation rests on the 80 annotators' triple-reviewed scores constituting stable ground truth. No inter-annotator agreement statistics, no held-out validation metrics, and no tests of score stability under prompt or annotator-pool shifts are referenced, leaving the central empirical claim without the required validation evidence.
- [Empirical evaluation] Abstract and results section: the assertion of 'greatest separation' on Real-world Fidelity and Creative Generation is presented without any quantitative scores, error bars, or comparison tables against existing benchmarks, making it impossible to assess whether the claimed advantage is load-bearing or merely descriptive.
minor comments (1)
- [Prompt curation] The abstract states that each prompt exercises 'more than four fine-grained facets' but does not specify the exact distribution or stratification procedure used to ensure coverage across the 56 rubrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation evidence and quantitative presentation. We address both major comments below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Q-Judger training and validation] Abstract and § on Q-Judger: the claim that Q-Judger supplies a 'trustworthy optimization signal' and enables 'reliable' model separation rests on the 80 annotators' triple-reviewed scores constituting stable ground truth. No inter-annotator agreement statistics, no held-out validation metrics, and no tests of score stability under prompt or annotator-pool shifts are referenced, leaving the central empirical claim without the required validation evidence.
Authors: We agree that the manuscript as submitted does not reference inter-annotator agreement statistics, held-out validation metrics, or stability tests under prompt or annotator shifts in the abstract or Q-Judger section. This omission weakens the support for the central claim. In the revised version we will add a dedicated validation subsection that reports (i) inter-annotator agreement (pairwise percent agreement and Krippendorff’s alpha across the 80 annotators), (ii) Q-Judger performance on a held-out test set of images, and (iii) any stability analyses performed across prompt strata or annotator subsets. These additions will directly substantiate the reliability of the supervision signal. revision: yes
-
Referee: [Empirical evaluation] Abstract and results section: the assertion of 'greatest separation' on Real-world Fidelity and Creative Generation is presented without any quantitative scores, error bars, or comparison tables against existing benchmarks, making it impossible to assess whether the claimed advantage is load-bearing or merely descriptive.
Authors: We concur that the abstract and results section state the separation advantage without accompanying quantitative metrics, error bars, or benchmark-comparison tables. This makes the claim difficult to evaluate. We will expand the results section with (i) a table of per-dimension mean scores and standard deviations for leading T2I models, (ii) statistical tests (e.g., paired t-tests or Wilcoxon) quantifying separation on Real-world Fidelity and Creative Generation versus other dimensions, and (iii) side-by-side comparisons against at least two prior benchmarks (e.g., T2I-CompBench, GenEval) on the same model set to demonstrate the added discriminative power. Error bars and confidence intervals will be included throughout. revision: yes
Circularity Check
No circularity: human annotations provide independent ground truth
full rationale
The paper's core derivation introduces a taxonomy of 56 rubrics, 1000 prompts, and trains Q-Judger on scores from 80 external professional annotators under blind triple-review. This human supervision constitutes independent input rather than a self-referential loop. The claimed model separation is an empirical observation on outputs scored by the trained judge; it does not reduce by construction to the paper's own fitted values or prior self-citations. No equations, self-citation chains, or ansatzes are present in the provided text that match any enumerated circularity pattern. The benchmark construction remains self-contained against external human judgments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Professional artists' blind triple-reviewed scores on the 56 rubrics form a reliable, generalizable ground truth for real-world fidelity and creative generation.
Forward citations
Cited by 2 Pith papers
-
WeGenBench: A Multidimensional Diagnostic Benchmark towards Text-to-Image Model Optimization
WeGenBench provides 4000 bilingual prompts with scene and tag annotations plus VLM-derived metrics to locate specific deficiencies in text-to-image models.
-
Qwen-Image-2.0-RL Technical Report
Applies RLHF with composite VLM-based reward models and on-policy distillation to a diffusion model, reporting benchmark gains of +2.61 on Qwen-Image-Bench and Elo improvements of +78/+93.
Reference graph
Works this paper leans on
-
[1]
flux.2", 2025a. URLhttps://bfl.ai/blog/flux-2. Accessed: 2026-05-14. Black Forest Labs
Black Forest Labs. "flux.2", 2025a. URLhttps://bfl.ai/blog/flux-2. Accessed: 2026-05-14. Black Forest Labs. "flux.2 [max]", 2025b. URL https://bfl.ai/models/flux-2-max. Accessed: 2026-05-14. Arwen Bradley and Preetum Nakkiran. Classifier-free guidance is a predictor-corrector,
2026
-
[2]
seedream 4.5
ByteDance Seed. "seedream 4.5", 2026a. URL https://seed.bytedance.com/en/seedream4_5. Accessed: 2026-05-14. ByteDance Seed. "seedream 5.0 lite", 2026b. URL https://seed.bytedance.com/en/seedream5_0_lite. Accessed: 2026-05-14. Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-...
2026
-
[3]
HunyuanImage 3.0 Technical Report
URL https://arxiv.org/abs/2509.23951. Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. Oneig-bench: Omni-dimensional nuanced evaluation for image generation. volume 38,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Multi-modal language models as text-to-image model evaluators
Jiahui Chen, Candace Ross, Reyhane Askari-Hemmat, Koustuv Sinha, Melissa Hall, Michal Drozdzal, and Adriana Romero-Soriano. Multi-modal language models as text-to-image model evaluators. 2025a. Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Silvio Savarese, et al. Blip3-o: A family of fully ope...
2025
-
[5]
imagen 4.0-ultra
Google. "imagen 4.0-ultra", 2025a. URL https://deepmind.google/models/imagen/. Accessed: 2026-05-
2026
-
[6]
nano banana pro
Google. "nano banana pro", 2025b. URL https://deepmind.google/models/gemini-image/pro/. Ac- cessed: 2026-05-14. Google. "nano banana 2",
2026
-
[7]
Accessed: 2026-05-14
URL https://deepmind.google/models/gemini-image/flash/. Accessed: 2026-05-14. 18 Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment,
2026
-
[8]
URL https://app.klingai.com/global/image-stylize/. Accessed: 2026-05-14. Online image editing service for style transfer and artistic rendering. Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, and Deva Ramanan. Genai-bench: Evaluating and improving compositional text-to-visual ge...
-
[9]
URLhttps://arxiv.org/abs/2406.11802. Shravan Nayak, Mehar Bhatia, Xiaofeng Zhang, Verena Rieser, Lisa Anne Hendricks, Sjoerd Van Steenkiste, Yash Goyal, Karolina Sta ´ nczak, and Aishwarya Agrawal. Culturalframes: Assessing cultural expectation alignment in text-to-image models and evaluation metrics. InFindings of the Association for Computational Lingui...
-
[10]
Ac- cessed: 2026-02-04
URL https://openai.com/index/new-chatgpt-images-is-here/ . Ac- cessed: 2026-02-04. OpenAI, :, Aaron Hurst, Adam Lerer, Adam P . Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, and Alec Radford et al. Gpt-4o system card,
2026
-
[11]
URL https://arxiv.org/abs/2410.21276. Igor Pavlov, Artyom Ivanov, and Stanislav Stafievskiy. Text-to-image benchmark: A benchmark for generative models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Version 0.1.0; Accessed: 2026-02-04
URL https://github.com/boomb0om/text2image-benchmark. Version 0.1.0; Accessed: 2026-02-04. Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation,
2026
-
[13]
Lifu Wang, Daqing Liu, Xinchen Liu, and Xiaodong He
URLhttps://arxiv.org/abs/2508.17472. Lifu Wang, Daqing Liu, Xinchen Liu, and Xiaodong He. Scaling down text encoders of text-to-image diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18424–18433, 2025a. Yibin Wang, Zhimin Li, Yuhang Zang, Jiazi Bu, Yujie Zhou, Yi Xin, Junjun He, Chunyu Wang, Qingli...
-
[14]
URLhttps://arxiv.org/abs/2506.02161. Olivia Wiles, Chuhan Zhang, Isabela Albuquerque, Ivana Kaji´ c, Su Wang, Emanuele Bugliarello, Ya- sumasa Onoe, Pinelopi Papalampidi, Ira Ktena, Christopher Knutsen, et al. Revisiting text-to-image evaluation with gecko: on metrics, prompts, and human rating. InInternational Conference on Learning Representations, volu...
-
[15]
Accessed: 2026-05-14
URLhttps://github.com/zai-org/GLM-Image. Accessed: 2026-05-14. Daoan Zhang, Che Jiang, Ruoshi Xu, Biaoxiang Chen, Zijian Jin, Yutian Lu, Jianguo Zhang, Liang Yong, Jiebo Luo, and Shengda Luo. Worldgenbench: A world-knowledge-integrated benchmark for reasoning-driven text-to-image generation,
2026
-
[16]
URLhttps://arxiv.org/abs/2505.01490. Nonghai Zhang and Hao Tang. Text-to-image synthesis: A decade survey,
-
[17]
Qwen-Image-2.0 Technical Report
URL https://arxiv.org/abs/2605.10730. Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. Swift:a scalable lightweight infrastructure for fine-tuning
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
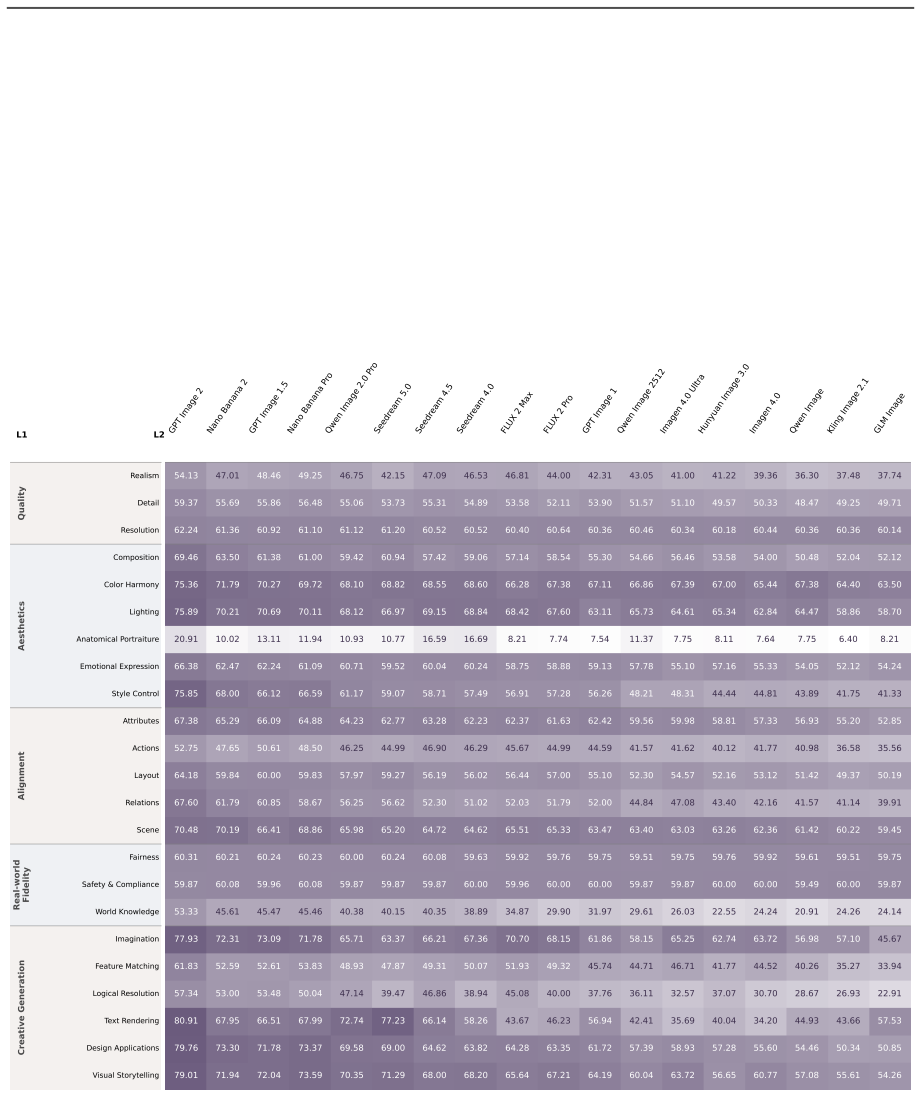
URLhttps://arxiv.org/abs/2408.05517. 20 A Appendix A.1 Human Rating Results Table 4: Human expert scores of 18 T2I models on Qwen-Image-Bench. Scores are mean ratings on a 1–10 scale assigned by professional annotators over 1,000 prompts per pillar. Models are sorted by overall score. The best score in each column isbolded. Evaluation Dimension Model Qual...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.