Is the Last Layer Sufficient for Uncertainty Quantification?
Pith reviewed 2026-06-28 21:31 UTC · model grok-4.3
The pith
Last-layer linearization matches full-network performance for epistemic uncertainty quantification but with substantially lower computational cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
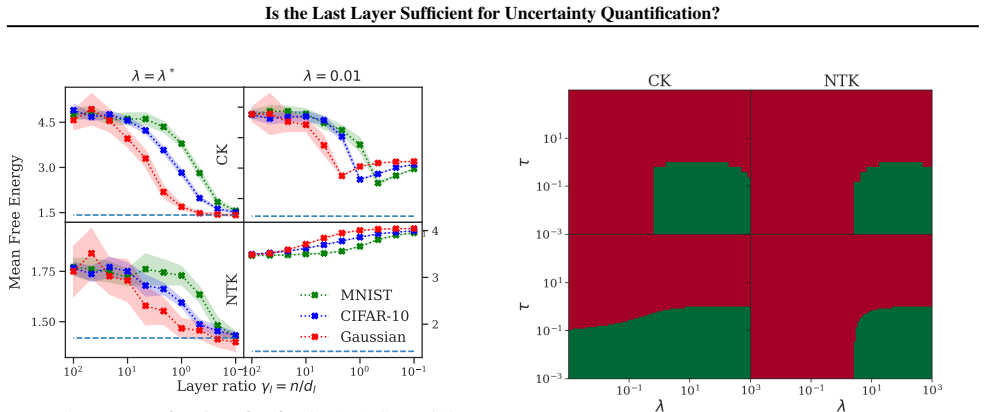
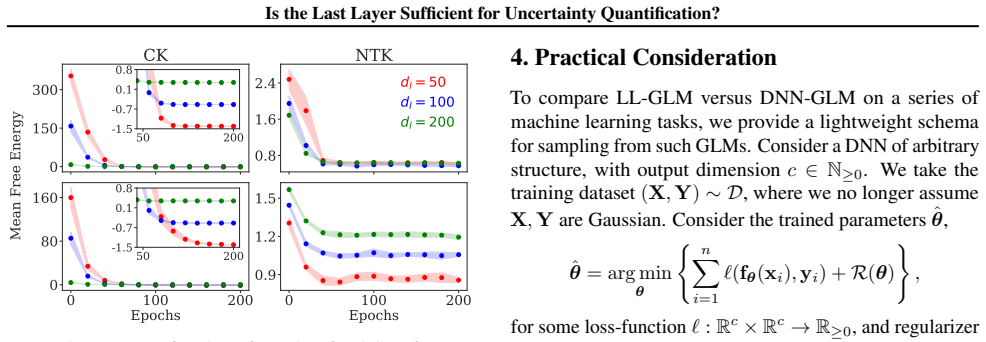
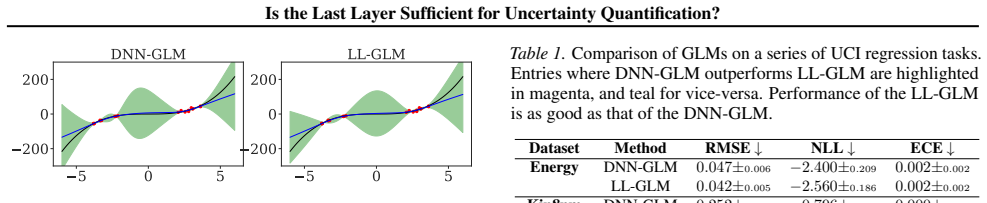
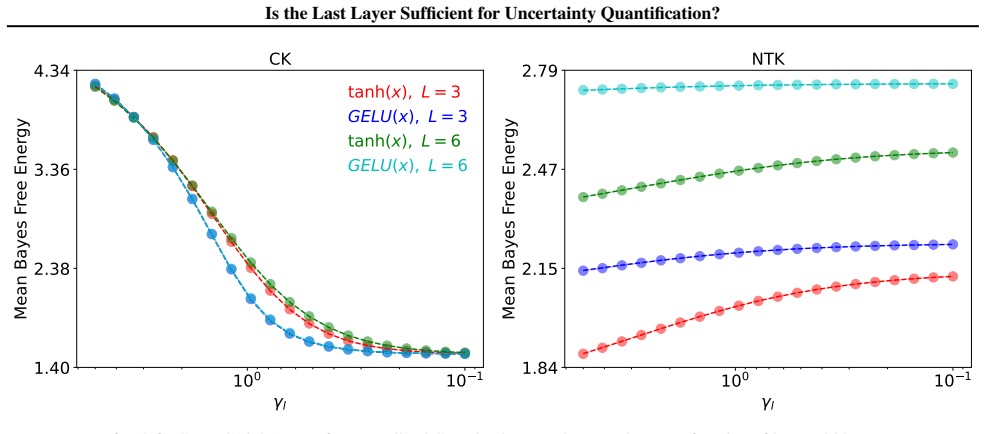
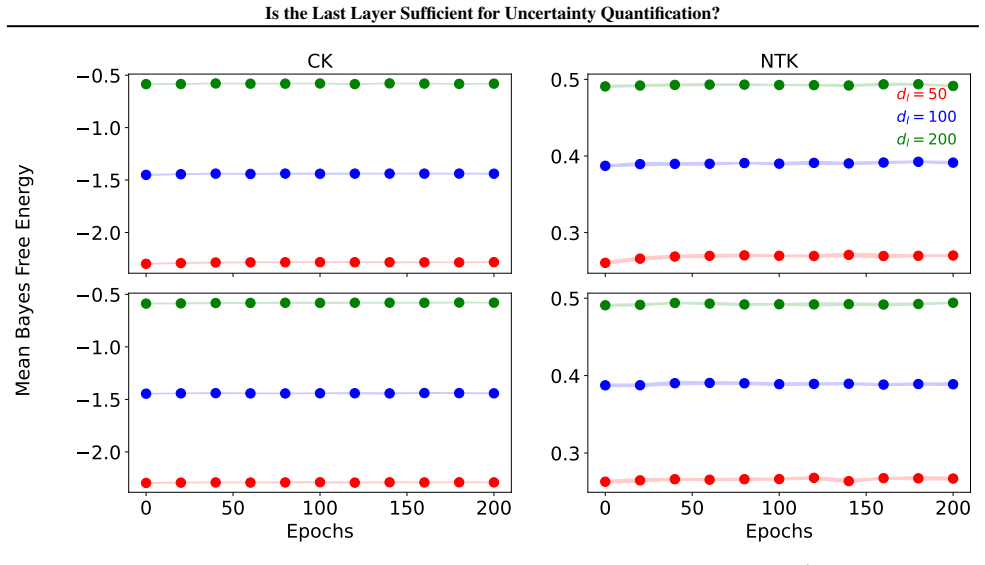
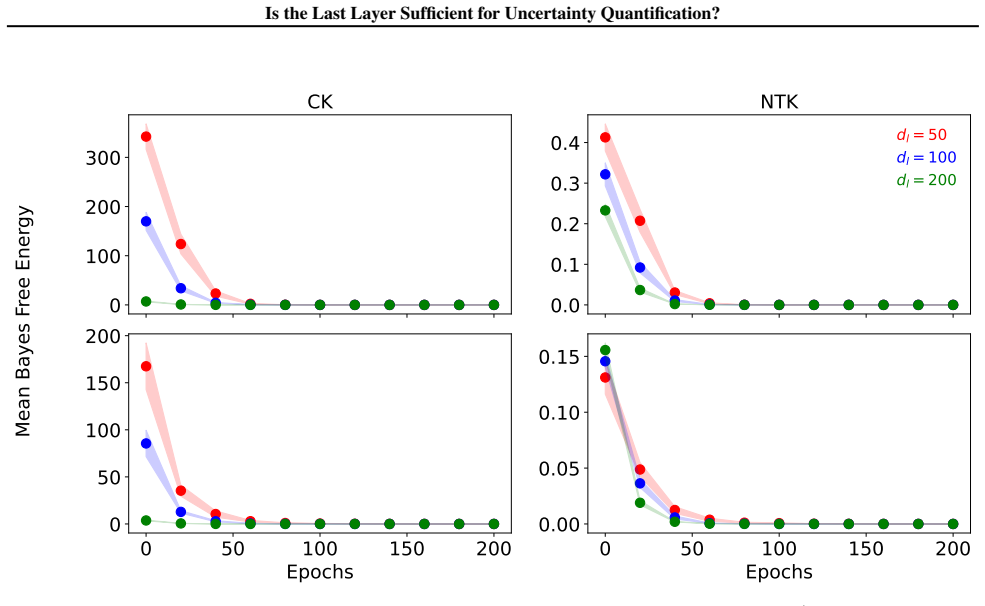
By comparing Bayesian generalized linear models obtained from full-network linearization versus last-layer linearization of DNNs, using both random matrix theory for theoretical comparison and empirical evaluation across modern tasks, the analysis concludes that a last-layer approximation yields comparable UQ performance while offering substantially improved computational efficiency.
What carries the argument
Last-layer linearization of a DNN to produce a Bayesian generalized linear model whose predictive posterior supplies the epistemic uncertainty estimate.
If this is right
- Last-layer linearization can be substituted for full linearization without degrading UQ quality in the tested regimes.
- The reduced computational burden makes Bayesian UQ practical for larger or deeper networks.
- Resources previously spent on full-network posterior approximations can be reallocated to model capacity or data scale.
- Existing full-linearization pipelines may be simplified to last-layer versions while preserving performance.
Where Pith is reading between the lines
- Uncertainty behavior in these networks may be dominated by the final layer's parameter posterior rather than earlier layers.
- Targeted last-layer methods could be designed from the start to further reduce overhead beyond current approximations.
- The same sufficiency pattern might appear in other post-training analyses such as gradient-based attributions.
- Deployment settings with strict latency constraints can adopt last-layer UQ with reduced risk of performance loss.
Load-bearing premise
The random matrix theory analysis assumes that the linearization approximations and network scaling regimes used in the theoretical comparison accurately capture the behavior of practical DNNs on real data distributions.
What would settle it
An experiment on a standard benchmark where full-network linearization produces statistically significantly better-calibrated uncertainty estimates or superior out-of-distribution detection than last-layer linearization would refute the claim of comparability.
Figures
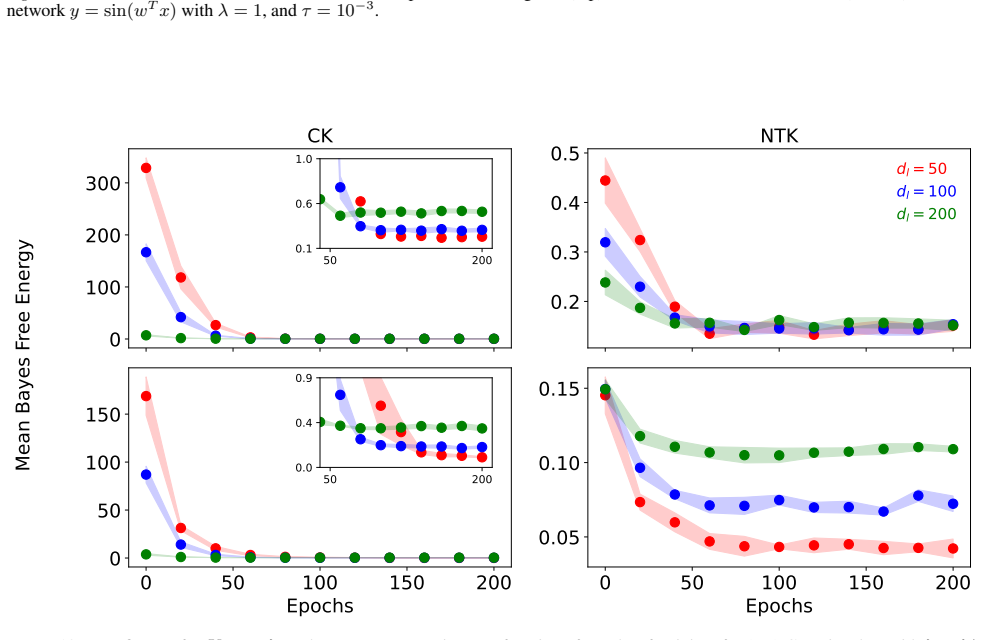
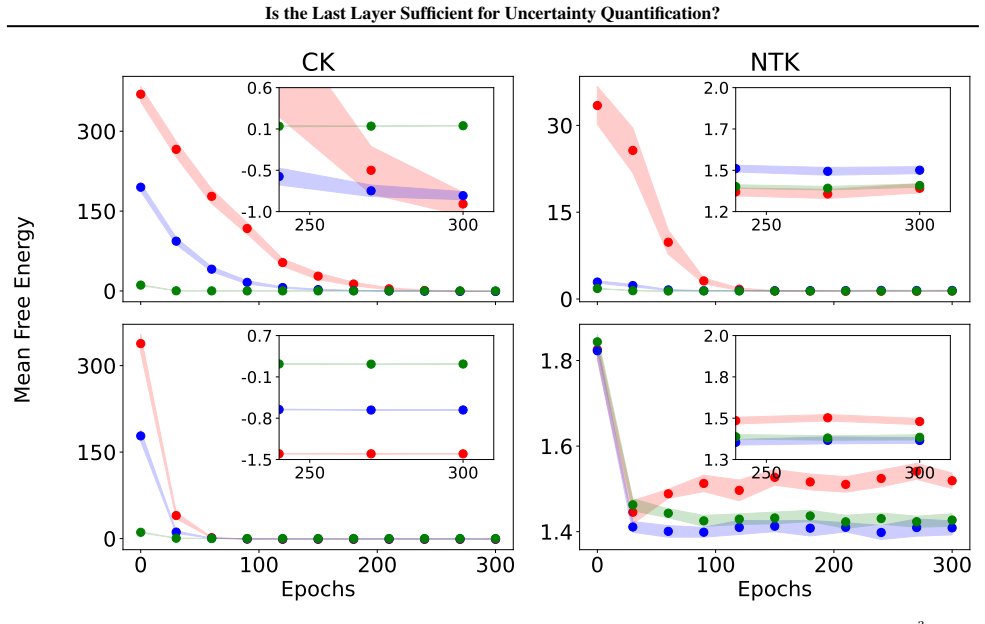
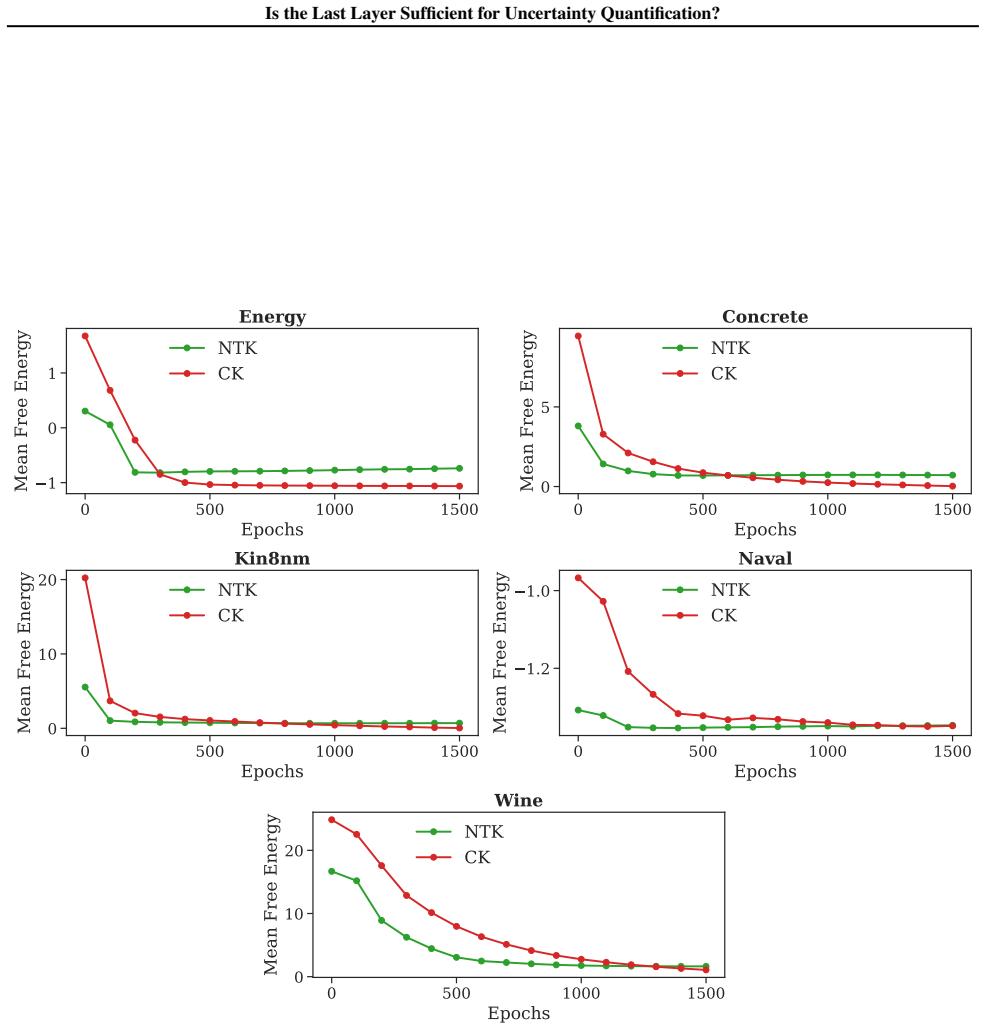
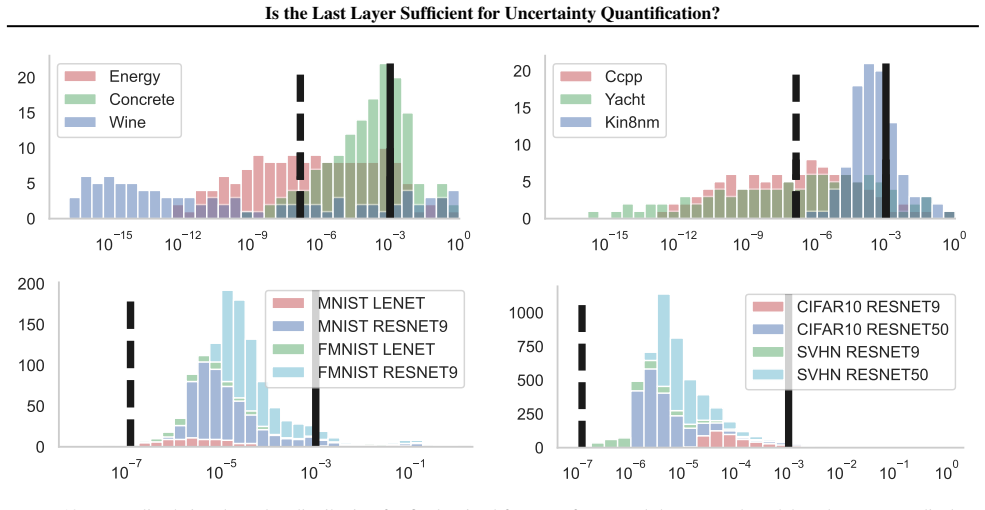
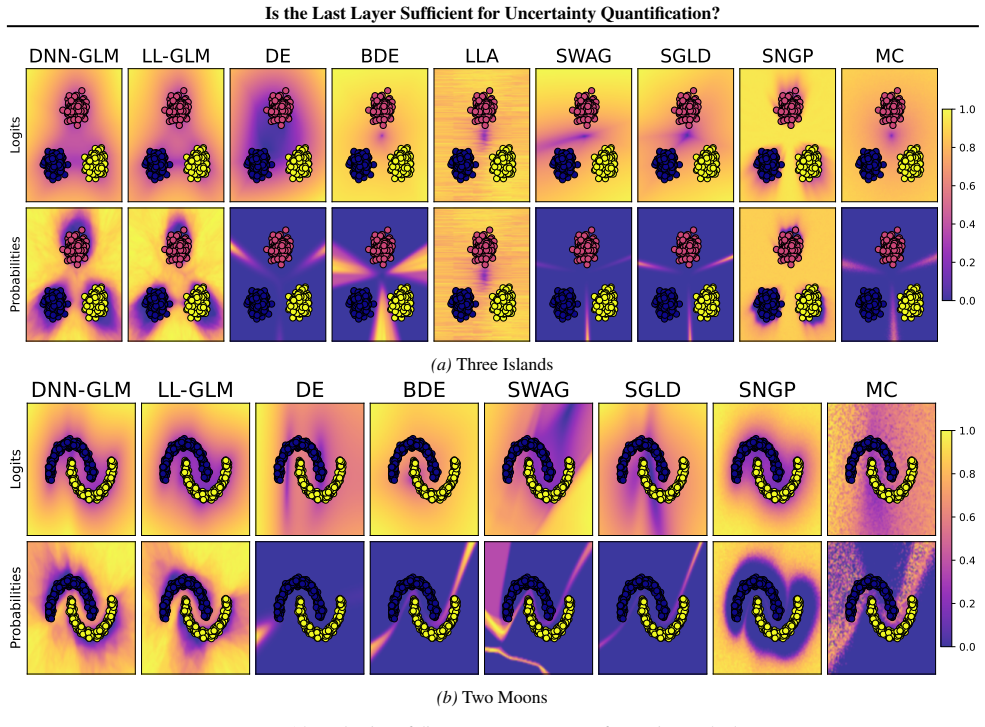
read the original abstract
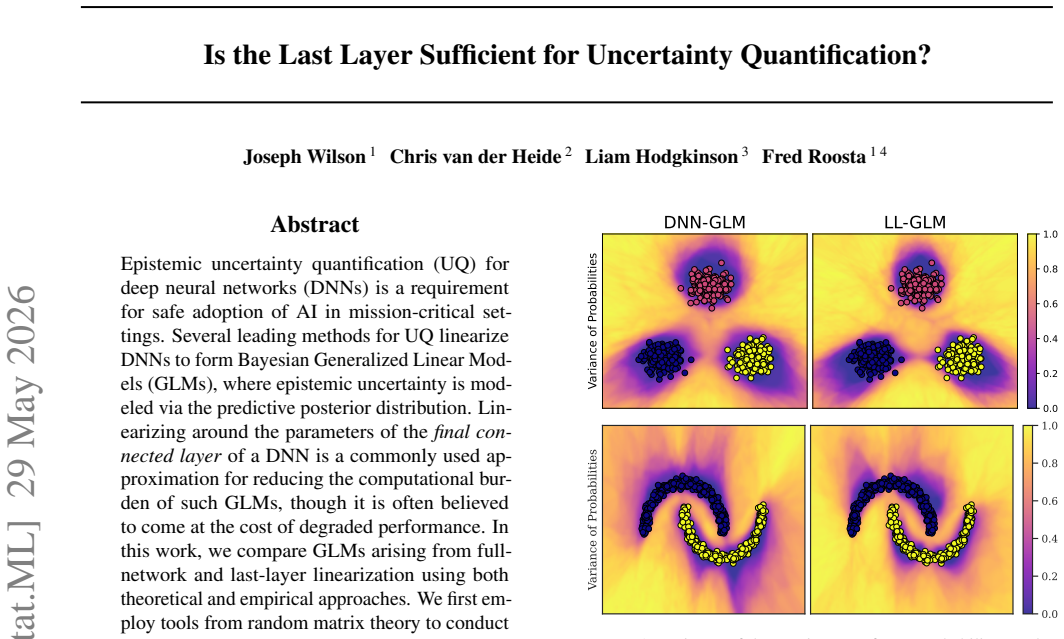
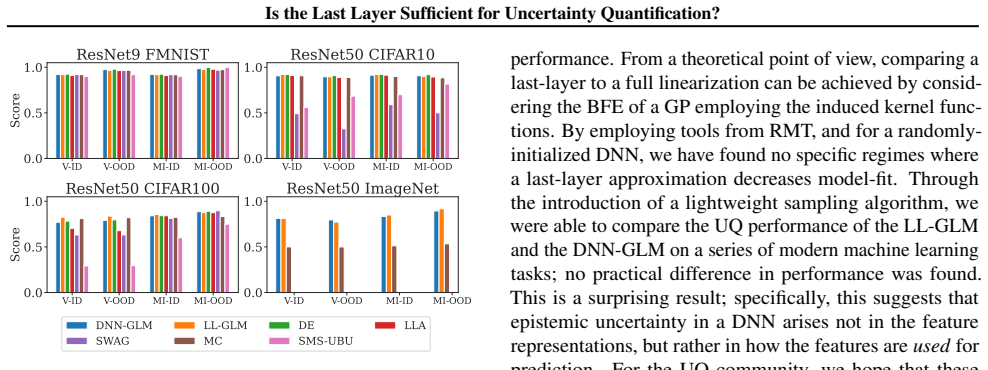
Epistemic uncertainty quantification (UQ) for deep neural networks (DNNs) is a requirement for safe adoption of AI in mission-critical settings. Several leading methods for UQ linearize DNNs to form Bayesian Generalized Linear Models (GLMs), where epistemic uncertainty is modeled via the predictive posterior distribution. Linearizing around the parameters of the final connected layer of a DNN is a commonly used approximation for reducing the computational burden of such GLMs, though it is often believed to come at the cost of degraded performance. In this work, we compare GLMs arising from full-network and last-layer linearization using both theoretical and empirical approaches. We first employ tools from random matrix theory to conduct a theoretical comparison; this analysis reveals no meaningful improvement in the UQ capabilities of full linearization. Coupled with a large-scale empirical evaluation across a range of modern machine learning tasks, we arrive at the following conclusion: a last-layer approximation yields comparable UQ performance while offering substantially improved computational efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that epistemic UQ via Bayesian GLMs obtained by DNN linearization can use a last-layer approximation without meaningful loss in performance relative to full-network linearization. This is supported by a random-matrix-theory comparison showing no improvement from full linearization, together with large-scale empirical results across modern ML tasks, leading to the conclusion that last-layer linearization is sufficient while being substantially more computationally efficient.
Significance. If the central claim holds, the result would justify a widely applicable computational shortcut for UQ in DNNs, reducing the cost of posterior inference while preserving predictive uncertainty quality; this would be a practically useful finding for safety-critical applications.
major comments (2)
- [RMT analysis section] § on RMT analysis (theoretical comparison): the conclusion that full-network linearization yields 'no meaningful improvement' rests on specific modeling choices for the linearization point, width/depth scaling, and random-matrix approximations to the Hessian/feature covariances; these regimes' fidelity to finite-width networks on real non-Gaussian data is not verified, which directly undermines the theoretical half of the central claim.
- [Empirical evaluation] Empirical evaluation section: the abstract and available text provide no derivation details, error bars, dataset descriptions, or quantitative metrics (e.g., specific UQ scores or statistical tests), so the claim of 'comparable UQ performance' cannot be assessed for robustness or effect size from the presented material.
minor comments (2)
- Clarify the precise definition of 'comparable' (e.g., within what tolerance on which metric) in both the theoretical and empirical parts.
- Ensure all notation for the GLM posterior and linearization is introduced with explicit equations before the RMT comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the scope and presentation of our results. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [RMT analysis section] § on RMT analysis (theoretical comparison): the conclusion that full-network linearization yields 'no meaningful improvement' rests on specific modeling choices for the linearization point, width/depth scaling, and random-matrix approximations to the Hessian/feature covariances; these regimes' fidelity to finite-width networks on real non-Gaussian data is not verified, which directly undermines the theoretical half of the central claim.
Authors: The RMT analysis is conducted under standard asymptotic regimes (infinite width and depth) with explicitly stated modeling choices for the linearization point and covariance approximations; these are common in the literature for obtaining closed-form insights into DNN Hessians and feature maps. The analysis shows that, within these regimes, full-network linearization does not yield meaningful improvement over last-layer. We agree that direct verification of the RMT approximations against finite-width real-data Hessians would be valuable additional evidence, but the manuscript's large-scale empirical evaluation on non-Gaussian real-world tasks provides complementary validation of the practical conclusion. In revision we will add an explicit limitations paragraph discussing the asymptotic assumptions and their relation to the empirical results. revision: partial
-
Referee: [Empirical evaluation] Empirical evaluation section: the abstract and available text provide no derivation details, error bars, dataset descriptions, or quantitative metrics (e.g., specific UQ scores or statistical tests), so the claim of 'comparable UQ performance' cannot be assessed for robustness or effect size from the presented material.
Authors: The full manuscript contains a dedicated empirical section that specifies all datasets, the exact UQ metrics (negative log-likelihood, expected calibration error, Brier score), error bars obtained from multiple independent runs with different random seeds, and direct comparisons between last-layer and full-network linearization. The abstract is intentionally concise. To improve accessibility we will add a summary table of key quantitative results and explicit cross-references in the revision. revision: yes
Circularity Check
No circularity: RMT analysis and empirics are independent of the target claim
full rationale
The derivation chain consists of an external random-matrix-theory comparison (under explicitly stated linearization and scaling assumptions) followed by a separate large-scale empirical evaluation. Neither component reduces to a self-definition, a fitted parameter renamed as a prediction, or a load-bearing self-citation chain; the RMT step is presented as an independent theoretical tool rather than an ansatz or uniqueness result imported from the authors' prior work. The conclusion that last-layer linearization suffices therefore rests on two non-circular inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
ElemeNet: Multiscale Molecular Machine Learning with Uncertainty Quantification Across the Periodic Table
ElemeNet is a unified ML software package for molecular property prediction across elements 1-100 with built-in uncertainty quantification and competitive benchmarks on diverse chemistry datasets.
Reference graph
Works this paper leans on
-
[1]
Daxberger, E., Kristiadi, A., Immer, A., Eschenhagen, R., Bauer, M., and Hennig, P
URL https://openreview.net/forum? id=ruGY8v10mK. Daxberger, E., Kristiadi, A., Immer, A., Eschenhagen, R., Bauer, M., and Hennig, P. Laplace redux-effortless bayesian deep learning.Advances in neural information processing systems, 34:20089–20103, 2021. de Jong, I. P., Sburlea, A. I., and Valdenegro-Toro, M. Un- certainty quantification in machine learnin...
arXiv 2021
-
[2]
PMLR, 2019. Fan, Z. and Wang, Z. Spectra of the conjugate kernel and neural tangent kernel for linear-width neural networks. Advances in Neural Information Processing Systems, 33: 7710–7721, 2020. 10 Is the Last Layer Sufficient for Uncertainty Quantification? Feng, R., Zheng, K., Huang, Y ., Zhao, D., Jordan, M., and Zha, Z.-J. Rank diminishing in deep n...
Pith/arXiv arXiv 2019
-
[3]
11 Is the Last Layer Sufficient for Uncertainty Quantification? Krivoruchko, K
PMLR, 2020. 11 Is the Last Layer Sufficient for Uncertainty Quantification? Krivoruchko, K. and Gribov, A. Evaluation of empirical bayesian kriging.Spatial Statistics, 32:100368, 2019. Lakshminarayanan, B., Pritzel, A., and Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles.Advances in Neural Information Processing Sys...
2020
-
[4]
Nemani, V ., Biggio, L., Huan, X., Hu, Z., Fink, O., Tran, A., Wang, Y ., Zhang, X., and Hu, C
Springer Science & Business Media, 2012. Nemani, V ., Biggio, L., Huan, X., Hu, Z., Fink, O., Tran, A., Wang, Y ., Zhang, X., and Hu, C. Uncertainty quan- tification in machine learning for engineering design and health prognostics: A tutorial.Mechanical Systems and Signal Processing, 205:110796, 2023. Ortega, L. A., Rodriguez Santana, S., and Hern ´andez...
-
[5]
Snoek, J., Rippel, O., Swersky, K., Kiros, R., Satish, N., Sundaram, N., Patwary, M., Prabhat, M., and Adams, R
URL https://www.auai.org/uai2018/ proceedings/papers/207.pdf. Snoek, J., Rippel, O., Swersky, K., Kiros, R., Satish, N., Sundaram, N., Patwary, M., Prabhat, M., and Adams, R. Scalable bayesian optimization using deep neural net- works. InInternational conference on machine learning, pp. 2171–2180. PMLR, 2015. Tulino, A. M., Verd´u, S., et al. Random matri...
2015
-
[6]
cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper
URL https://proceedings.neurips. cc/paper_files/paper/2017/file/ 3f5ee243547dee91fbd053c1c4a845aa-Paper. pdf. V ovk, V ., Gammerman, A., and Shafer, G.Algorithmic Learning in a Random World, volume 29. Springer, 2005. Wang, Z., Engel, A., Sarwate, A. D., Dumitriu, I., and Chiang, T. Spectral evolution and invariance in linear- width neural networks.Advanc...
2017
-
[7]
For a Bayesian method, we generally have a mean predictor µ:R d →R c and a covariance function Σ :R d →R c×c, that output in the softmax space
Firstly, we use the variance of the maximum softmax prediction as our uncertainty score. For a Bayesian method, we generally have a mean predictor µ:R d →R c and a covariance function Σ :R d →R c×c, that output in the softmax space. For the variance of the maximum softmax prediction for a given test point x⋆, we first find ˆc=argmaxk µ(x∗)k, where µ(x⋆)k ...
-
[8]
Secondly, we compute the AUCROC score for two settings: on an in-distribution test set, where we seek to detect 35 Is the Last Layer Sufficient for Uncertainty Quantification? correctly predicted versus incorrectly predicted points (V ARROC-ID), and using an OOD test set, where we seek to detect correctly predicted versus OOD points (V ARROC-OOD). Note th...
2024
-
[9]
We take 40 posterior samples, and discard the first10as a burn-in
component of SMS-UBU, we take the pre-trained DNN, run SWA (using Adam with weight decay equal to that for our original DNN training) for 5 epochs, and then run SMS-UBU from the averaged parameters. We take 40 posterior samples, and discard the first10as a burn-in. GPT-2 The trained GPT-2 weights were taken fromHuggingFace; a classification head was then ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.