Normalized Relevance Measure as a Unifying Framework to Explain Neural Network Latent Structures
Pith reviewed 2026-06-28 19:30 UTC · model grok-4.3
The pith
The normalized relevance measure framework defines neuron importance as a signed measure that unifies prior explanation methods for neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
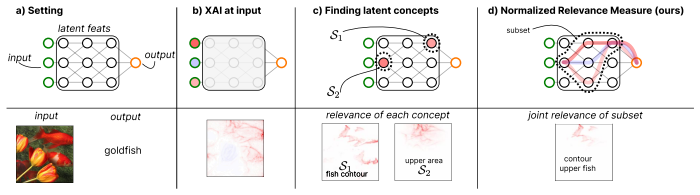
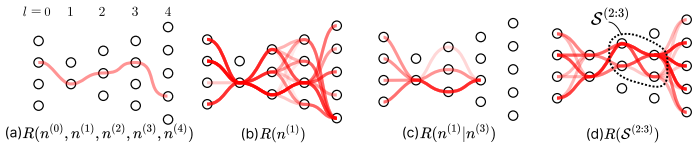
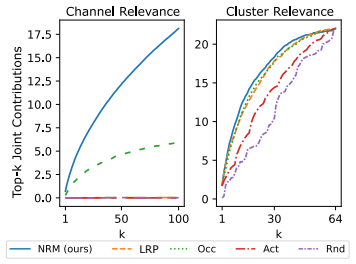
The normalized relevance measure (NRM) framework attributes relevance to arbitrary sets of neurons across layers of arbitrary architectures by defining relevance explicitly as a normalized signed measure constructed using marginalization and conditioning operations based on additive and multiplicative laws in direct analogy to probability measures. The normalization property guarantees comparability across layers, and the framework subsumes existing propagation-based explanation algorithms by identifying the underlying quantity being computed.
What carries the argument
The normalized relevance measure (NRM), a signed measure on neuron sets that is constructed via marginalization and conditioning and then normalized to enable cross-layer comparison.
If this is right
- Existing propagation-based methods compute specific cases of the same relevance quantity under different marginalization choices.
- Relevance scores become directly comparable between early and late layers because of the normalization step.
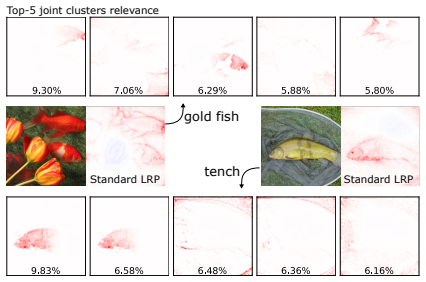
- Joint relevance analysis across multiple layers can trace how information flows through internal representations in models such as VGG16.
Where Pith is reading between the lines
- The same marginalization and conditioning construction might be applied to recurrent or transformer architectures to produce cross-layer relevance maps.
- Choosing different conditioning operations within the NRM definition could generate families of new explanation techniques beyond those already known.
- The framework's emphasis on sets of neurons rather than single units suggests a route to explanations that respect group structure in the latent space.
Load-bearing premise
Relevance of arbitrary neuron sets can be rigorously defined as a normalized signed measure built from marginalization and conditioning operations in the same way probability measures are built.
What would settle it
A calculation on a trained network where the NRM values for neuron sets in one layer cannot be meaningfully compared in scale to those in another layer would show the normalization property fails to hold.
Figures

read the original abstract
To understand how a neural network (NN) functions and makes predictions, it has become increasingly clear that analyzing only the input domain is insufficient -- one must also examine its internal inference mechanisms to capture the complete picture. To explain the internal inference mechanisms of such models, it is essential to analyze the importance of latent representations for a given task. In this paper, we propose the \emph{normalized relevance measure} (NRM) framework -- a novel general explanation procedure that attributes relevance to \emph{arbitrary sets of neurons across layers of arbitrary architectures}. In the NRM framework, relevance of selected neurons is explicitly defined as a normalized signed measure, constructed using simple operations -- marginalization and conditioning based on additive and multiplicative laws -- in analogy to the probability measures. The normalization property further guarantees comparability across layers. The NRM framework subsumes existing propagation-based explanation algorithms by explicitly identifying the underlying quantity being computed. We demonstrate the utility of the framework in computer vision applications, where joint relevance analysis across multiple layers reveals key information flows in VGG16 networks. Overall, the NRM framework provides a general, mathematically grounded approach to understanding how modern NNs propagate information, offering a versatile and broadly applicable foundation for explainable artificial intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
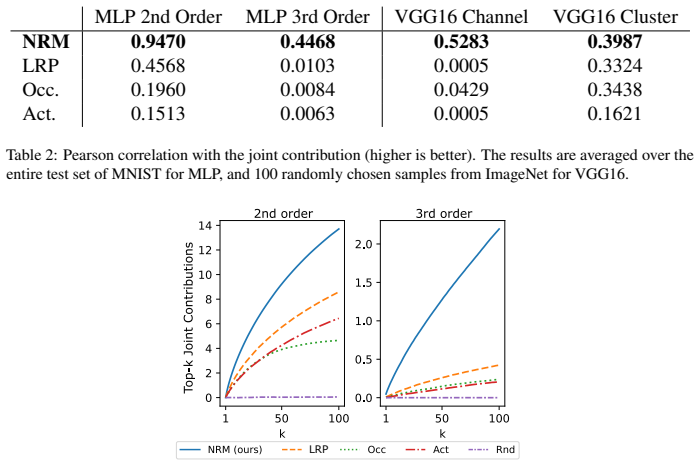
Summary. The paper proposes the normalized relevance measure (NRM) framework, which defines relevance of arbitrary sets of neurons across layers of arbitrary neural network architectures as a normalized signed measure constructed via marginalization and conditioning operations (additive and multiplicative laws) in direct analogy to probability measures. The normalization is claimed to enable cross-layer comparability. The central claim is that NRM subsumes existing propagation-based explanation methods (e.g., LRP, DeepLIFT) by explicitly identifying the underlying quantity each computes. Utility is illustrated via joint relevance analysis across layers in VGG16 for computer vision tasks.
Significance. If the subsumption claim is established via explicit mappings, NRM would offer a mathematically grounded unifying lens for propagation-based explanations, with the signed-measure normalization providing a concrete mechanism for cross-layer and cross-architecture comparison. The probability-measure analogy supplies a clear axiomatic structure that could facilitate further theoretical development in XAI.
major comments (1)
- [Abstract, §3] Abstract and §3 (NRM definition): the central subsumption claim—that NRM subsumes LRP, DeepLIFT, etc., 'by explicitly identifying the underlying quantity being computed'—requires a concrete mapping showing that each standard rule set computes exactly the normalized signed measure under the paper's marginalization/conditioning operations. No such derivation, table, or proposition appears; without it the unification remains an asserted analogy rather than a demonstrated equivalence, which is load-bearing for the paper's primary contribution.
minor comments (2)
- [§2] Notation for the signed measure (e.g., how the normalization constant is defined when the measure can be negative) should be stated explicitly in the main text rather than left to supplementary material.
- [§4] The VGG16 experiments would benefit from a quantitative baseline comparison (e.g., against layer-wise relevance propagation alone) rather than purely qualitative information-flow visualizations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The point raised about strengthening the subsumption claim is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (NRM definition): the central subsumption claim—that NRM subsumes LRP, DeepLIFT, etc., 'by explicitly identifying the underlying quantity being computed'—requires a concrete mapping showing that each standard rule set computes exactly the normalized signed measure under the paper's marginalization/conditioning operations. No such derivation, table, or proposition appears; without it the unification remains an asserted analogy rather than a demonstrated equivalence, which is load-bearing for the paper's primary contribution.
Authors: We agree that the subsumption claim would be substantially strengthened by explicit derivations. Although the NRM definition in §3 is constructed precisely so that common propagation rules emerge as special cases of the marginalization and conditioning operations (with the normalization ensuring the signed-measure property), the current manuscript presents this at the level of the general framework rather than case-by-case mappings. In the revised version we will add a new proposition in §3 together with a summary table that derives the exact equivalence for the standard LRP rules (including the z-rule and αβ-rule) and the DeepLIFT rules, showing the specific marginalization/conditioning steps that recover each method as an instance of the normalized relevance measure. This addition will make the unification demonstrative rather than asserted. revision: yes
Circularity Check
No circularity: NRM definition and subsumption claim remain independent of inputs
full rationale
The abstract defines NRM explicitly via marginalization/conditioning operations producing a normalized signed measure, then asserts subsumption via identification of existing algorithms as computing that same quantity. No equations, self-citations, or fitted parameters are shown that would reduce the central claim to a tautology or prior author result by construction. The derivation chain is therefore self-contained against external benchmarks; the unification is presented as an explicit mapping rather than a renaming or self-referential fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Relevance of neuron sets can be defined as a normalized signed measure using marginalization and conditioning based on additive and multiplicative laws in analogy to probability measures.
Forward citations
Cited by 1 Pith paper
-
Explaining Temporal Graph Neural Networks via Feature-induced Information Flow
A new attribution method for ETGNNs extends NRM with modular decomposition to analyze entire event-induced information flow and outperforms prior explainers on synthetic epidemic/social and real political event data.
Reference graph
Works this paper leans on
-
[1]
Achtibat, M
R. Achtibat, M. Dreyer, I. Eisenbraun, S. Bosse, T. Wiegand, W. Samek, and S. Lapuschkin. From attribution maps to human-understandable explanations through concept relevance propagation.Nat. Mac. Intell., 5(9):1006–1019, 2023
2023
-
[2]
Achtibat, S
R. Achtibat, S. M. V . Hatefi, M. Dreyer, A. Jain, T. Wiegand, S. Lapuschkin, and W. Samek. Attnlrp: Attention-aware layer-wise relevance propagation for transformers. InICML, pages 135–168. PMLR/OpenReview.net, 2024
2024
-
[3]
Ancona, E
M. Ancona, E. Ceolini, C. Öztireli, and M. Gross. Towards better understanding of gradient-based attribution methods for deep neural networks. InICLR (Poster). OpenReview.net, 2018. 23
2018
-
[4]
Arras, J
L. Arras, J. A. Arjona-Medina, M. Widrich, G. Montavon, M. Gillhofer, K.-R. Müller, S. Hochreiter, and W. Samek. Explaining and interpreting LSTMs. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, volume 11700, pages 211–238. Springer, 2019
2019
-
[5]
S. Bach, A. Binder, G. Montavon, F. Klauschen, K.-R. Müller, and W. Samek. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PloS one, 10(7):e0130140, 2015
2015
-
[6]
C. M. Bishop.Pattern Recognition and Machine Learning (Information Science and Statistics), pages 402–411. Springer-Verlag, Berlin, Heidelberg, 2006
2006
-
[7]
F. Bley, S. Lapuschkin, W. Samek, and G. Montavon. Explaining predictive uncertainty by exposing second-order effects.Pattern Recognition, 160:111171, 2025
2025
-
[8]
Blücher, J
S. Blücher, J. Vielhaben, and N. Strodthoff. Preddiff: Explanations and interactions from conditional expectations.Artif. Intell., 312:103774, 2022
2022
-
[9]
Chormai, J
P. Chormai, J. Herrmann, K.-R. Müller, and G. Montavon. Disentangled expla- nations of neural network predictions by finding relevant subspaces.IEEE Trans. Pattern Anal. Mach. Intell., 46(11):7283–7299, 2024
2024
-
[10]
Conmy, A
A. Conmy, A. N. Mavor-Parker, A. Lynch, S. Heimersheim, and A. Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability. InNeurIPS, 2023
2023
-
[11]
T. Cui, P. Marttinen, and S. Kaski. Learning global pairwise interactions with bayesian neural networks. InECAI, Frontiers in Artificial Intelligence and Appli- cations, pages 1087–1094. IOS Press, 2020
2020
-
[12]
Dhamdhere, M
K. Dhamdhere, M. Sundararajan, and Q. Yan. How important is a neuron. In International Conference on Learning Representations, 2019
2019
-
[13]
Eberle, J
O. Eberle, J. Büttner, F. Kräutli, K.-R. Müller, M. Valleriani, and G. Montavon. Building and interpreting deep similarity models.IEEE Trans. Pattern Anal. Mach. Intell., 44(3):1149–1161, 2022
2022
-
[14]
Elhage, N
N. Elhage, N. Nanda, C. Olsson, T. Henighan, N. Joseph, B. Mann, A. Askell, Y . Bai, A. Chen, T. Conerly, N. DasSarma, D. Drain, D. Ganguli, Z. Hatfield- Dodds, D. Hernandez, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah. A mathematical framework for transformer circuits.Transformer Circu...
2021
-
[15]
Erhan, A
D. Erhan, A. Courville, and P. Vincent. Visualizing higher-layer features of a deep network.Technical Report, Univeristé de Montréal, 01 2009
2009
-
[16]
Ghorbani and J
A. Ghorbani and J. Zou. Neuron shapley: discovering the responsible neurons. In Proceedings of the 34th International Conference on Neural Information Process- ing Systems, Red Hook, NY , USA, 2020. Curran Associates Inc. 24
2020
-
[17]
Gunning, M
D. Gunning, M. Stefik, J. Choi, T. Miller, S. Stumpf, and G.-Z. Yang. Xai—explainable artificial intelligence.Science Robotics, 4(37), 2019
2019
-
[18]
J. C. Harsanyi. 17. a bargaining model for the cooperative n-person game. In Contributions to the Theory of Games, Volume IV, pages 325–356. Princeton University Press, Princeton, 1959
1959
-
[19]
Holzinger, A
A. Holzinger, A. Saranti, C. Molnar, P. Biecek, and W. Samek. Explainable AI methods - A brief overview. InxxAI@ICML, pages 13–38. Springer, 2020
2020
-
[20]
J. D. Janizek, P. Sturmfels, and S.-I. Lee. Explaining explanations: axiomatic feature interactions for deep networks.J. Mach. Learn. Res., 22(1), Jan. 2021
2021
-
[21]
Kauffmann, J
J. Kauffmann, J. Dippel, L. Ruff, W. Samek, K.-R. Müller, and G. Montavon. Explainable ai reveals clever hans effects in unsupervised learning models.Nature Machine Intelligence, 7(3):412–422, 2025
2025
-
[22]
J. R. Kauffmann, M. Esders, L. Ruff, G. Montavon, W. Samek, and K.-R. Müller. From clustering to cluster explanations via neural networks.IEEE Trans. Neural Networks Learn. Syst., 35(2):1926–1940, 2024
1926
-
[23]
Lapuschkin, S
S. Lapuschkin, S. Wäldchen, A. Binder, G. Montavon, W. Samek, and K.-R. Müller. Unmasking clever hans predictors and assessing what machines really learn.Nature communications, 10(1):1096, 2019
2019
-
[24]
S. Lloyd. Least squares quantization in PCM.IEEE Trans. Inf. Theory, 28(2): 129–137, 1982
1982
-
[25]
S. M. Lundberg and S.-I. Lee. A unified approach to interpreting model predictions. InNeurIPS, volume 30, page 4768–4777. Curran Associates, Inc., 2017
2017
-
[26]
S. M. Lundberg, G. Erion, H. Chen, A. DeGrave, J. M. Prutkin, B. Nair, R. Katz, J. Himmelfarb, N. Bansal, and S.-I. Lee. From local explanations to global understanding with explainable ai for trees.Nature Machine Intelligence, 2(1): 56–67, 2020
2020
-
[27]
Montavon, S
G. Montavon, S. Lapuschkin, A. Binder, W. Samek, and K.-R. Müller. Explain- ing nonlinear classification decisions with deep taylor decomposition.Pattern Recognit., 65:211–222, 2017
2017
-
[28]
Montavon, W
G. Montavon, W. Samek, and K.-R. Müller. Methods for interpreting and under- standing deep neural networks.Digit. Signal Process., 73:1–15, 2018
2018
-
[29]
C. Olah, A. Satyanarayan, I. Johnson, S. Carter, L. Schubert, K. Ye, and A. Mord- vintsev. The building blocks of interpretability.Distill, 2018
2018
- [30]
-
[31]
why should I trust you?
M. T. Ribeiro, S. Singh, and C. Guestrin. "why should I trust you?": Explaining the predictions of any classifier. InKDD, pages 1135–1144. ACM, 2016
2016
-
[32]
G. C. Rota. On the foundations of combinatorial theory i. theory of möbius functions.Zeitschrift für Wahrscheinlichkeitstheorie und Verwandte Gebiete, 2(4): 340–368, Jan 1964
1964
-
[33]
Samek, G
W. Samek, G. Montavon, A. Vedaldi, L. K. Hansen, and K.-R. Müller, editors. Explainable AI: Interpreting, Explaining and Visualizing Deep Learning, volume 11700 ofLecture Notes in Computer Science. Springer, 2019
2019
-
[34]
Samek, G
W. Samek, G. Montavon, S. Lapuschkin, C. J. Anders, and K.-R. Müller. Explain- ing deep neural networks and beyond: A review of methods and applications.Proc. IEEE, 109(3):247–278, 2021
2021
-
[35]
Schnake, O
T. Schnake, O. Eberle, J. Lederer, S. Nakajima, K. T. Schütt, K.-R. Müller, and G. Montavon. Higher-order explanations of graph neural networks via relevant walks.IEEE Trans. Pattern Anal. Mach. Intell., 44(11):7581–7596, 2022
2022
-
[36]
Schnake, F
T. Schnake, F. R. Jafari, J. Lederer, P. Xiong, S. Nakajima, S. Gugler, G. Mon- tavon, and K.-R. Müller. Towards symbolic XAI - explanation through human understandable logical relationships between features.Inf. Fusion, 118:102923, 2025
2025
-
[37]
Strumbelj and I
E. Strumbelj and I. Kononenko. An efficient explanation of individual classifi- cations using game theory.J. Mach. Learn. Res., 11:1–18, Mar. 2010. ISSN 1532-4435
2010
-
[38]
Sundararajan, A
M. Sundararajan, A. Taly, and Q. Yan. Axiomatic attribution for deep networks. InICML- Volume 70, page 3319–3328. JMLR.org, 2017
2017
-
[39]
Tsang, D
M. Tsang, D. Cheng, and Y . Liu. Detecting statistical interactions from neural network weights. InICLR, 2018
2018
-
[40]
Xiong, T
P. Xiong, T. Schnake, G. Montavon, K.-R. Müller, and S. Nakajima. Efficient computation of higher-order subgraph attribution via message passing. InICML, pages 24478–24495. PMLR, 2022
2022
-
[41]
Xiong, T
P. Xiong, T. Schnake, M. Gastegger, G. Montavon, K.-R. Müller, and S. Nakajima. Relevant walk search for explaining graph neural networks. InICML, pages 38301–38324. PMLR, 2023
2023
-
[42]
Z. Ying, D. Bourgeois, J. You, M. Zitnik, and J. Leskovec. Gnnexplainer: Generat- ing explanations for graph neural networks. InNeurIPS 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 9240–9251, 2019
2019
-
[43]
H. Yuan, H. Yu, J. Wang, K. Li, and S. Ji. On explainability of graph neural networks via subgraph explorations. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event, volume 139, pages 12241–12252. PMLR, 2021. 26
2021
-
[44]
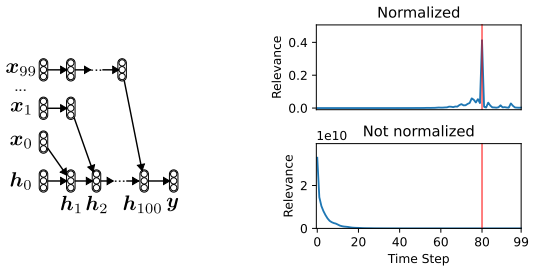
B. Zhou, Y . Sun, D. Bau, and A. Torralba. Interpretable basis decomposition for visual explanation. InECCV (8), Lecture Notes in Computer Science, pages 122–138. Springer, 2018. 27 Appendix A. Generalization to Arbitrary Architectures In Section 3, we described the NRM framework for a proper FFNNs—a FFNN with no skip connection and no intermediate input ...
2018
-
[45]
For a target output neuron n(L), i.e., the target class in classification, identify concept neurons, i.e., relevant intermediate neurons {n(l)} in some layer l∈ {1, . . . ,L−1}
-
[46]
This process is called Relevance Maximization (RelMax)
For each concept neuron n(l), find input samples that maximize the concept relevance. This process is called Relevance Maximization (RelMax)
-
[47]
This algorithm is called CRP
With respect to each concept neuron n(l) and an output neuron n(L), compute the input relevances. This algorithm is called CRP. The concept relevance (ConRel) computed in Step 1 corresponds to the joint relevance ConReln(l),n(L) =R(n (l),n (L)).(F.3) The quantity (F.3) is also the objective function to be maximized with respect to the input samplex∈ Xin S...
-
[48]
If the given network is not proper FFNN, convert it into a proper FFNN, following the procedure in Appendix A
-
[49]
Feed the input sample, and then compute the unnormalized relevance propa- gation matrices {eT(l)}L l=1 and output relevance er(L), from which the consecutive conditional relevance (17) and the output relevance (18) are computed
-
[50]
Choose a set of neurons S(L) to which we attribute, and the target neuron n(l) to be explained for l>max(L) (typically l=L)
-
[51]
Compute the relevance R(S(L),n (l)) or R(S(L)|n(l)) by the sum-product message passing algorithm (Theorem 1)
-
[52]
With this procedure, one can analyze the decision-making mechanism of any type of NN with arbitrarily high-order explanation
If we search for most relevance information flow, iterate Step 4 for different set S(L) of neurons. With this procedure, one can analyze the decision-making mechanism of any type of NN with arbitrarily high-order explanation. 38 Appendix I. Evaluation Methods This appendix provides details of our evaluation metrics. Appendix I.1. Joint contribution The jo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.