ChartArena: Benchmarking Chart Parsing across Languages, Scenarios, and Formats
Pith reviewed 2026-06-28 17:20 UTC · model grok-4.3
The pith
ChartArena benchmark reveals that current chart parsing models struggle most with diagrammatic structures and hand-drawn images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
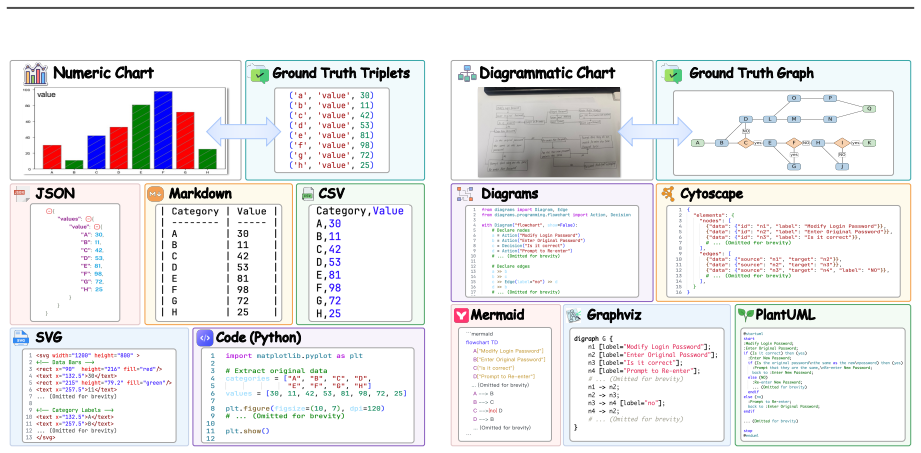
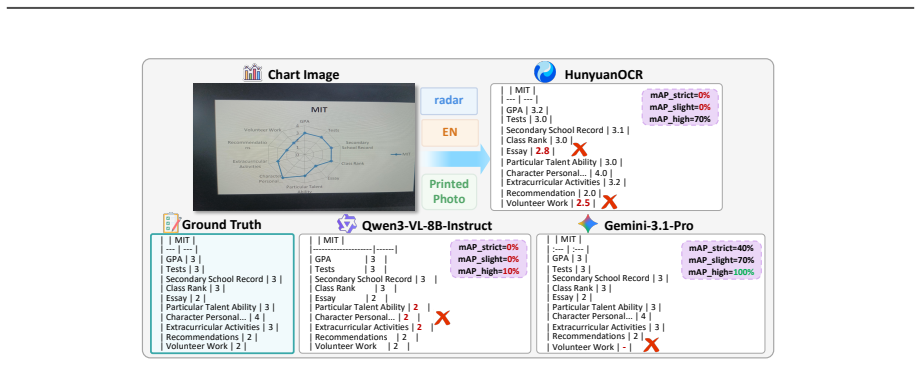
ChartArena provides a unified benchmark for chart parsing that covers numeric and diagrammatic structures across digital, printed, and hand-drawn images in two languages. Its evaluation protocol maps diverse model outputs into normalized triple and directed graph views scored by structure-aware metrics. Tests of 26 leading MLLMs show frontier proprietary models such as Gemini 3.1 Pro lead overall yet the strongest open-source systems close the gap rapidly, document parsing models perform adequately on numeric charts but drop sharply on diagrammatic ones, and expert chart parsers remain confined to narrow families, with radar charts and hand-drawn scenarios remaining especially difficult for
What carries the argument
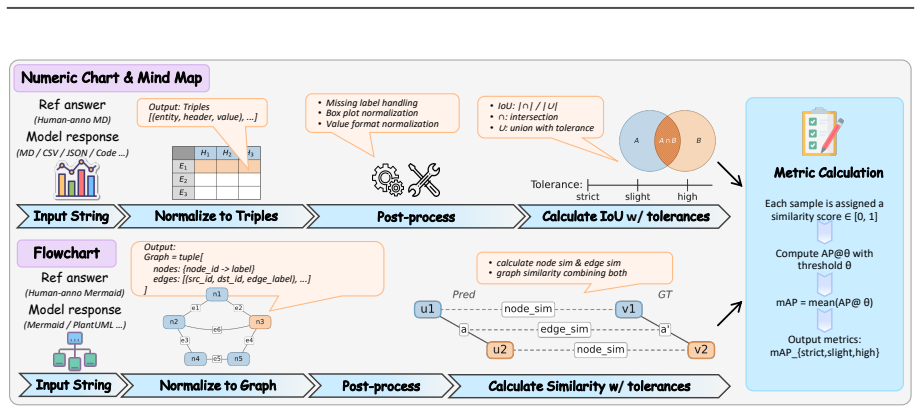
The format-agnostic evaluation protocol that converts heterogeneous model outputs into a normalized triple view and a directed graph view for structure-aware metric scoring.
If this is right
- Document parsing models require targeted extensions to handle flowcharts, mind maps, and similar diagrammatic forms.
- Training or adaptation pipelines must incorporate hand-drawn and printed photo variations to improve robustness.
- Radar charts need dedicated modeling attention because they remain difficult even for leading systems.
- Open-source models can be expected to match proprietary performance on chart parsing within a short development cycle.
- A single unified benchmark enables direct comparison of models that previously used incompatible output formats.
Where Pith is reading between the lines
- The separation between numeric and diagrammatic performance suggests that future architectures may benefit from modular designs that route different chart families to specialized sub-modules.
- The benchmark's coverage of printed and hand-drawn photos could serve as a template for evaluating other visual information extraction tasks that encounter real-world capture noise.
- If the format-agnostic mapping proves stable, similar canonical views might simplify evaluation for additional structured visual outputs such as tables or infographics.
Load-bearing premise
The human-agent collaborative annotation pipeline with multi-stage human verification produces reliable ground-truth labels across all chart types and scenarios.
What would settle it
A re-annotation of a random sample of ChartArena instances by independent annotators that produces substantially different structure labels and reverses the reported performance ordering among model classes.
Figures

read the original abstract
Charts are a primary medium for conveying quantitative and relational information, yet systematically evaluating chart parsing models remains difficult. Existing benchmarks focus on narrow chart types and leave diagrammatic structures such as flowcharts and mind maps largely unaddressed, while models produce outputs in incompatible formats, and datasets rarely include the printed or hand-drawn images encountered in practice. To address these issues, we introduce ChartArena, a comprehensive bilingual benchmark covering eight chart families spanning both numeric charts and diagrammatic structures, each evaluated across three visual scenarios: digital renderings, printed photos, and hand-drawn photos. The dataset is built via a human-agent collaborative annotation pipeline with multi-stage human verification to ensure annotation reliability. To enable fair cross-model comparison, we further design a format-agnostic evaluation protocol that maps heterogeneous outputs into two canonical semantic spaces, a normalized triple view and a directed graph view, and scores them with structure-aware metrics. Through extensive evaluation of 26 leading MLLMs, we observe three consistent findings: (i) frontier proprietary models such as Gemini 3.1 Pro lead overall, yet the strongest open-source systems are rapidly closing the gap; (ii) document parsing models handle numeric charts reasonably but fall sharply behind on diagrammatic structures; and (iii) expert chart parsers remain limited to narrow chart families. Across all models, radar charts and hand-drawn scenarios stay especially challenging. These findings show that ChartArena exposes clear capability gaps and provides a unified foundation for future progress. ChartArena is publicly available at https://github.com/pspdada/ChartArena.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChartArena, a bilingual benchmark for chart parsing covering eight chart families (numeric and diagrammatic structures) across digital, printed, and hand-drawn scenarios. It employs a human-agent collaborative annotation pipeline with multi-stage verification, proposes a format-agnostic evaluation protocol mapping outputs to triple and directed graph views, and evaluates 26 MLLMs, reporting that proprietary models like Gemini 3.1 Pro lead, open-source models are closing the gap, document parsers struggle with diagrammatic charts, and expert parsers are limited, with radar charts and hand-drawn scenarios being particularly challenging.
Significance. If the ground-truth annotations are reliable, ChartArena provides a valuable unified benchmark that addresses limitations in existing chart parsing evaluations by including diagrammatic structures and real-world visual scenarios. The format-agnostic evaluation protocol and public release of the dataset and code are notable strengths that could facilitate future research in multimodal large language models for chart understanding.
major comments (2)
- [Dataset construction] The human-agent collaborative annotation pipeline with multi-stage human verification (described in the dataset construction section) is load-bearing for all reported findings, yet the manuscript supplies no inter-annotator agreement statistics, no error rates broken down by chart family or scenario (especially hand-drawn and diagrammatic), and no description of how relational disagreements were resolved. Without these, the performance gaps between document parsers and other models on diagrammatic structures cannot be confidently attributed to model capability rather than label quality.
- [Experiments and results] The three headline findings in the abstract and experiments section are presented without statistical significance tests, confidence intervals, or per-scenario variance estimates across the 26 models. For example, the claim that document parsing models 'fall sharply behind' on diagrammatic structures lacks effect-size quantification, weakening the robustness of the cross-model and cross-scenario comparisons.
minor comments (2)
- [Abstract] The abstract states the benchmark is bilingual but does not name the languages; this detail should appear in the first paragraph of the introduction or dataset section for immediate clarity.
- [Evaluation protocol] A concrete worked example (e.g., a small flowchart mapped to both the normalized triple view and directed graph view with the resulting metric scores) would help readers understand the format-agnostic protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of ChartArena's contributions. We address each major comment below.
read point-by-point responses
-
Referee: [Dataset construction] The human-agent collaborative annotation pipeline with multi-stage human verification (described in the dataset construction section) is load-bearing for all reported findings, yet the manuscript supplies no inter-annotator agreement statistics, no error rates broken down by chart family or scenario (especially hand-drawn and diagrammatic), and no description of how relational disagreements were resolved. Without these, the performance gaps between document parsers and other models on diagrammatic structures cannot be confidently attributed to model capability rather than label quality.
Authors: We agree that additional details on annotation quality would strengthen the manuscript. In the revised version, we will report inter-annotator agreement statistics (e.g., percentage agreement and Cohen's kappa) on a sampled subset, with breakdowns by chart family and scenario. We will also expand the dataset construction section to describe the process for resolving relational disagreements during multi-stage verification. revision: yes
-
Referee: [Experiments and results] The three headline findings in the abstract and experiments section are presented without statistical significance tests, confidence intervals, or per-scenario variance estimates across the 26 models. For example, the claim that document parsing models 'fall sharply behind' on diagrammatic structures lacks effect-size quantification, weakening the robustness of the cross-model and cross-scenario comparisons.
Authors: We concur that statistical tests and variance estimates would improve the presentation of results. The revised manuscript will include statistical significance testing (with multiple-comparison corrections) and confidence intervals or standard errors for the primary metrics. We will also add per-scenario variance estimates and effect-size information to support the cross-model comparisons. revision: yes
Circularity Check
No significant circularity in benchmark construction and evaluation paper
full rationale
This is a benchmark paper that constructs a dataset via human-agent annotation and evaluates 26 MLLMs using a format-agnostic protocol. No mathematical derivations, fitted parameters, predictions, or uniqueness theorems are present. The central claims rest on empirical results from the new benchmark rather than reducing to self-citations or input definitions by construction. The annotation pipeline is presented as a methodological choice without any self-referential derivation. This is the most common honest finding for dataset and evaluation papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Chart content can be reliably represented as normalized triples or directed graphs without loss of key quantitative and relational information.
invented entities (1)
-
ChartArena dataset and evaluation protocol
no independent evidence
Forward citations
Cited by 1 Pith paper
-
StrucTab: A Structured Optimization Framework for Table Parsing
StrucTab achieves SOTA table parsing performance by unifying structural subtasks through sequential reasoning and using decomposed RL rewards in Uni-TabRL, plus a new TableVerse-5K benchmark.
Reference graph
Works this paper leans on
-
[1]
ChartX and ChartVLM: A versatile benchmark and foundation model for complicated chart reasoning.IEEE Transactions on Image Processing, 2025
Renqiu Xia, Hancheng Ye, Xiangchao Yan, Qi Liu, Hongbin Zhou, Zijun Chen, Botian Shi, Junchi Yan, and Bo Zhang. ChartX and ChartVLM: A versatile benchmark and foundation model for complicated chart reasoning.IEEE Transactions on Image Processing, 2025
2025
-
[2]
OneChart: Purify the chart structural extraction via one auxiliary token
Jinyue Chen, Lingyu Kong, Haoran Wei, Chenglong Liu, Zheng Ge, Liang Zhao, Jianjian Sun, Chunrui Han, and Xiangyu Zhang. OneChart: Purify the chart structural extraction via one auxiliary token. InProceedings of the 32nd ACM International Conference on Multimedia, 2024
2024
-
[3]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL, 2022
2022
-
[4]
Chart question answering from real-world analytical narratives
Maeve Hutchinson, Radu Jianu, Aidan Slingsby, Jo Wood, and Pranava Swaroop Madhyastha. Chart question answering from real-world analytical narratives. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop), 2025
2025
-
[5]
ChartSense: Interactive data extraction from chart images
Daekyoung Jung, Wonjae Kim, Hyunjoo Song, Jeong-in Hwang, Bongshin Lee, Bohyoung Kim, and Jinwook Seo. ChartSense: Interactive data extraction from chart images. InProceedings of the CHI Conference on Human Factors in Computing Systems, 2017
2017
-
[6]
ReVision: Automated classification, analysis and redesign of chart images
Manolis Savva, Nicholas Kong, Arti Chhajta, Li Fei-Fei, Maneesh Agrawala, and Jeffrey Heer. ReVision: Automated classification, analysis and redesign of chart images. InProceedings of the 24th annual ACM symposium on User interface software and technology, 2011
2011
-
[7]
Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, et al. Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[8]
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, et al. PaddleOCR-VL: Boosting multilingual document parsing via a 0.9B ultra-compact vision-language model.arXiv preprint arXiv:2510.14528, 2025
arXiv 2025
-
[9]
HunyuanOCR Technical Report.arXiv preprint arXiv:2511.19575, 2025
Hunyuan Vision Team, Pengyuan Lyu, Xingyu Wan, Gengluo Li, Shangpin Peng, Weinong Wang, Liang Wu, Huawen Shen, Yu Zhou, Canhui Tang, et al. HunyuanOCR Technical Report.arXiv preprint arXiv:2511.19575, 2025
arXiv 2025
-
[10]
Divide Rows and Conquer Cells: Towards structure recognition for large tables
Huawen Shen, Xiang Gao, Jin Wei, Liang Qiao, Yu Zhou, Qiang Li, and Zhanzhan Cheng. Divide Rows and Conquer Cells: Towards structure recognition for large tables. InProceedings of the International Joint Conferences on Artificial Intelligence, pages 1369–1377, 2023
2023
-
[11]
Global Table Extractor (GTE): A framework for joint table identification and cell structure recognition using visual context
Xinyi Zheng, Doug Burdick, Lucian Popa, Peter Zhong, and Nancy Xin Ru Wang. Global Table Extractor (GTE): A framework for joint table identification and cell structure recognition using visual context. InProceedings of the IEEE Winter Conference on Applications of Computer Vision, 2021
2021
-
[12]
Image-Based Table Recognition: Data, model, and evaluation
Xu Zhong, Elaheh ShafieiBavani, and Antonio Jimeno Yepes. Image-Based Table Recognition: Data, model, and evaluation. InProceedings of the European Conference on Computer Vision, 2020
2020
-
[13]
CC-OCR: A comprehensive and challenging OCR benchmark for evaluating large multimodal models in literacy
Zhibo Yang, Jun Tang, Zhaohai Li, Pengfei Wang, Jianqiang Wan, Humen Zhong, Xuejing Liu, Mingkun Yang, Peng Wang, Shuai Bai, et al. CC-OCR: A comprehensive and challenging OCR benchmark for evaluating large multimodal models in literacy. InProceedings of the IEEE International Conference on Computer Vision, 2025
2025
-
[14]
Image Over Text: Transforming formula recognition evaluation with Character Detection Matching
Bin Wang, Fan Wu, Linke Ouyang, Zhuangcheng Gu, Rui Zhang, Renqiu Xia, Botian Shi, Bo Zhang, and Conghui He. Image Over Text: Transforming formula recognition evaluation with Character Detection Matching. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[15]
Syntax-Aware Network for Handwritten Mathematical Expression Recognition
Ye Yuan, Xiao Liu, Wondimu Dikubab, Hui Liu, Zhilong Ji, Zhongqin Wu, and Xiang Bai. Syntax-Aware Network for Handwritten Mathematical Expression Recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[16]
Bin Wang, Zhuangcheng Gu, Guang Liang, Chao Xu, Bo Zhang, Botian Shi, and Conghui He. UniMERNet: A universal network for real-world mathematical expression recognition.arXiv preprint arXiv:2404.15254, 2024
arXiv 2024
-
[17]
An-Lan Wang, Jingqun Tang, Lei Liao, Hao Feng, Qi Liu, Xiang Fei, Jinghui Lu, Han Wang, Hao Liu, Yuliang Liu, et al. WildDoc: How far are we from achieving comprehensive and robust document understanding in the wild? InProceedings of the Conference on Empirical Methods in Natural Language Processing, pages 23002–23012, 2025
2025
-
[18]
Gengluo Li, Pengyuan Lyu, Chengquan Zhang, Huawen Shen, Liang Wu, Xingyu Wan, Gangyan Zeng, Han Hu, Can Ma, and Yu Zhou. Towards real-world document parsing via realistic scene synthesis and document-aware training.arXiv preprint arXiv:2603.23885, 2026
Pith/arXiv arXiv 2026
-
[19]
Parsing table structures in the wild
Rujiao Long, Wen Wang, Nan Xue, Feiyu Gao, Zhibo Yang, Yongpan Wang, and Gui-Song Xia. Parsing table structures in the wild. InProceedings of the IEEE International Conference on Computer Vision, 2021
2021
-
[20]
RealCQA: Scientific chart question answering as a test-bed for first-order logic
Saleem Ahmed, Bhavin Jawade, Shubham Pandey, Srirangaraj Setlur, and Venu Govindaraju. RealCQA: Scientific chart question answering as a test-bed for first-order logic. InProceedings of the International Conference on Document Analysis and Recognition, 2023. 8
2023
-
[21]
EvoChart: A benchmark and a self-training approach towards real-world chart understanding
Muye Huang, Han Lai, Xinyu Zhang, Wenjun Wu, Jie Ma, Lingling Zhang, and Jun Liu. EvoChart: A benchmark and a self-training approach towards real-world chart understanding. InProceedings of the AAAI Conference on Artificial Intelligence, 2025
2025
-
[22]
Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, et al. Qwen3-VL Technical Report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[23]
Cheng Cui, Ting Sun, Suyin Liang, Tingquan Gao, Zelun Zhang, Jiaxuan Liu, Xueqing Wang, Changda Zhou, Hongen Liu, Manhui Lin, et al. PaddleOCR-VL-1.5: Towards a multi-task 0.9B VLM for robust in-the-wild document parsing.arXiv preprint arXiv:2601.21957, 2026
Pith/arXiv arXiv 2026
-
[24]
TinyChart: Efficient chart understanding with visual token merging and program-of-thoughts learning
Liang Zhang, Anwen Hu, Haiyang Xu, Ming Yan, Yichen Xu, Qin Jin, Ji Zhang, and Fei Huang. TinyChart: Efficient chart understanding with visual token merging and program-of-thoughts learning. InProceedings of the 2024 conference on empirical methods in natural language processing, 2024
2024
-
[25]
ChartAssisstant: A universal chart multimodal language model via chart-to-table pre-training and multitask instruction tuning
Fanqing Meng, Wenqi Shao, Quanfeng Lu, Peng Gao, Kaipeng Zhang, Yu Qiao, and Ping Luo. ChartAssisstant: A universal chart multimodal language model via chart-to-table pre-training and multitask instruction tuning. InFindings of the Association for Computational Linguistics: ACL, 2024
2024
-
[26]
Multimodal OCR: Parse anything from documents.arXiv preprint arXiv:2603.13032, 2026
Handong Zheng, Yumeng Li, Kaile Zhang, Liang Xin, Guangwei Zhao, Hao Liu, Jiayu Chen, Jie Lou, Jiyu Qiu, Qi Fu, et al. Multimodal OCR: Parse anything from documents.arXiv preprint arXiv:2603.13032, 2026
arXiv 2026
-
[27]
Lei Chen, Xuanle Zhao, Zhixiong Zeng, Jing Huang, Liming Zheng, Yufeng Zhong, and Lin Ma. Breaking the SFT plateau: Multimodal structured reinforcement learning for Chart-to-Code generation.arXiv preprint arXiv:2508.13587, 2025
arXiv 2025
-
[28]
Yang Chen, Yufan Shen, Wenxuan Huang, Sheng Zhou, Qunshu Lin, Xinyu Cai, Zhi Yu, Jiajun Bu, Botian Shi, and Yu Qiao. Learning Only with Images: Visual reinforcement learning with reasoning, rendering, and visual feedback.arXiv preprint arXiv:2507.20766, 2025
arXiv 2025
-
[29]
ChartCoder: Advancing multimodal large language model for Chart-to-Code generation
Xuanle Zhao, Xianzhen Luo, Qi Shi, Chi Chen, Shuo Wang, Zhiyuan Liu, and Maosong Sun. ChartCoder: Advancing multimodal large language model for Chart-to-Code generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025
2025
-
[30]
ChartMoE: Mixture of diversely aligned expert connector for chart understanding
Zhengzhuo Xu, Bowen Qu, Yiyan Qi, Sinan Du, Chengjin Xu, Chun Yuan, and Jian Guo. ChartMoE: Mixture of diversely aligned expert connector for chart understanding. InProceedings of the International Conference on Learning Representations, 2025
2025
-
[31]
Making multimodal LLMs reliable chart data extractors: A benchmark and training framework
Yuchen He, Peizhi Ying, Liqi Cheng, Kuilin Peng, Yuan Tian, Dazhen Deng, and Yingcai Wu. Making multimodal LLMs reliable chart data extractors: A benchmark and training framework. InProceedings of the CHI Conference on Human Factors in Computing Systems, 2026
2026
-
[32]
Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Jiaqi Wang, and Dahua Lin. Visual Self-Refine: A pixel-guided paradigm for accurate chart parsing.arXiv preprint arXiv:2602.16455, 2026
arXiv 2026
-
[33]
PlotQA: Reasoning over scientific plots
Nitesh Methani, Pritha Ganguly, Mitesh M Khapra, and Pratyush Kumar. PlotQA: Reasoning over scientific plots. In Proceedings of the ieee winter conference on applications of computer vision, 2020
2020
-
[34]
MMC: Advancing multimodal chart understanding with large-scale instruction tuning
Fuxiao Liu, Xiaoyang Wang, Wenlin Yao, Jianshu Chen, Kaiqiang Song, Sangwoo Cho, Yaser Yacoob, and Dong Yu. MMC: Advancing multimodal chart understanding with large-scale instruction tuning. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024
2024
-
[35]
Hierarchically recognizing vector graphics and a new chart-based vector graphics dataset.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Shuguang Dou, Xinyang Jiang, Lu Liu, Lu Ying, Caihua Shan, Yifei Shen, Xuanyi Dong, Yun Wang, Dongsheng Li, and Cairong Zhao. Hierarchically recognizing vector graphics and a new chart-based vector graphics dataset.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[36]
ParseBench: A document parsing benchmark for AI agents.arXiv preprint arXiv:2604.08538, 2026
Boyang Zhang, Sebastián G Acosta, Preston Carlson, Sacha Bron, Pierre-Loïc Doulcet, and Simon Suo. ParseBench: A document parsing benchmark for AI agents.arXiv preprint arXiv:2604.08538, 2026
Pith/arXiv arXiv 2026
-
[37]
CCpdf: Building a high quality corpus for visually rich documents from web crawl data
Michał Turski, Tomasz Stanisławek, Karol Kaczmarek, Paweł Dyda, and Filip Grali ´nski. CCpdf: Building a high quality corpus for visually rich documents from web crawl data. InInternational Conference on Document Analysis and Recognition, 2023
2023
-
[38]
Renqiu Xia, Bo Zhang, Haoyang Peng, Hancheng Ye, Xiangchao Yan, Peng Ye, Botian Shi, Yu Qiao, and Junchi Yan. StructChart: On the schema, metric, and augmentation for visual chart understanding.arXiv preprint arXiv:2309.11268, 2023
arXiv 2023
-
[39]
GPT-4 Technical Report.arXiv preprint arXiv:2303.08774, 2023
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[40]
OpenAI GPT-5 System Card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. OpenAI GPT-5 System Card.arXiv preprint arXiv:2601.03267, 2025. 9
Pith/arXiv arXiv 2025
-
[41]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
Pith/arXiv arXiv 2025
-
[42]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https://qwen.ai/blog?id= qwen3.5
2026
-
[43]
V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiale Zhu, Jiali Chen, J...
Pith/arXiv arXiv 2025
-
[44]
Seed1.8 model card: Towards generalized real-world agency, 2025
Bytedance Seed. Seed1.8 model card: Towards generalized real-world agency, 2025. URL https://github.com/ ByteDance-Seed/Seed-1.8/blob/main/Seed-1.8-Modelcard.pdf
2025
-
[45]
Seed2.0 model card: Towards intelligence frontier for real-world complexity, February 2026
ByteDance Seed Team. Seed2.0 model card: Towards intelligence frontier for real-world complexity, February 2026. URL https://github.com/ByteDance-Seed/Seed2.0. Model Card
2026
-
[46]
Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
Pith/arXiv arXiv 2026
-
[47]
Xiaomi MiMo-V2-Omni: See, hear, act in the agentic era
Xiaomi Corporation. Xiaomi MiMo-V2-Omni: See, hear, act in the agentic era. https://mimo.xiaomi.com/ mimo-v2-omni, 2026
2026
-
[48]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[49]
Gemini 3.1 Pro: A smarter model for your most complex tasks
Google. Gemini 3.1 Pro: A smarter model for your most complex tasks. https://blog.google/ innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/, 2026
2026
-
[50]
Binary codes capable of correcting deletions, insertions, and reversals
Vladimir I Levenshtein et al. Binary codes capable of correcting deletions, insertions, and reversals. InSoviet physics doklady, 1966
1966
-
[51]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InProceedings of Advances in Neural Information Processing Systems, 2020
2020
-
[52]
Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
Pith/arXiv arXiv 2023
-
[53]
Llama 3 model card
AI@Meta. Llama 3 model card. https://github.com/meta-llama/llama3/blob/main/MODEL_CARD. md, 2024
2024
-
[54]
Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115, 2024
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 Technical Report.arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[55]
Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[56]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[57]
The Claude 3 model family: Opus, Sonnet, Haiku, 2024
Anthropic. The Claude 3 model family: Opus, Sonnet, Haiku, 2024. URL https://www-cdn.anthropic.com/ de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
2024
-
[58]
DeepSeek-V3 Technical Report.arXiv preprint arXiv:2412.19437, 2024
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. DeepSeek-V3 Technical Report.arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[59]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[60]
Direct Preference Optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization: Your language model is secretly a reward model. InProceedings of Advances in Neural Information Processing Systems, 2023. 10
2023
-
[61]
SimPO: Simple preference optimization with a reference-free reward
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference-free reward. In Proceedings of Advances in Neural Information Processing Systems, 2024
2024
-
[62]
Shangpin Peng, Weinong Wang, Zhuotao Tian, Senqiao Yang, Xing Wu, Haotian Xu, Chengquan Zhang, Takashi Isobe, Baotian Hu, and Min Zhang. Uni-DPO: A unified paradigm for dynamic preference optimization of LLMs.arXiv preprint arXiv:2506.10054, 2025
Pith/arXiv arXiv 2025
-
[63]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Proceedings of Advances in Neural Information Processing Systems, 2022
2022
-
[64]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, 2021
2021
-
[65]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InProceedings of the International Conference on Machine Learning, 2023
2023
-
[66]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InProceedings of Advances in Neural Information Processing Systems, 2023
2023
-
[67]
InstructBLIP: Towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. InstructBLIP: Towards general-purpose vision-language models with instruction tuning. InProceedings of Advances in Neural Information Processing Systems, 2023
2023
-
[68]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[69]
Yucheng Han, Chi Zhang, Xin Chen, Xu Yang, Zhibin Wang, Gang Yu, Bin Fu, and Hanwang Zhang. ChartLlama: A multimodal LLM for chart understanding and generation.arXiv preprint arXiv:2311.16483, 2023
arXiv 2023
-
[70]
Gengluo Li, Shangpin Peng, Xingyu Wan, Chengquan Zhang, Hao Feng, Xin Xu, Pian Wu, Bang Li, Zengmao Ding, Yongge Liu, et al. Chronicles-OCR: A cross-temporal perception benchmark for the evolutionary trajectory of chinese characters.arXiv preprint arXiv:2605.11960, 2026
Pith/arXiv arXiv 2026
-
[71]
Per image
Yongxin Shi, Chongyu Liu, Dezhi Peng, Cheng Jian, Jiarong Huang, and Lianwen Jin. M5HisDoc: A large-scale multi-style chinese historical document analysis benchmark. InProceedings of the Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. 11 ChartArena: Benchmarking Chart Parsing across Languages, Scenar...
2023
-
[72]
Focus only on the chart itself and ignore unrelated elements such as decorations, backgrounds, logos, and watermarks
-
[73]
category-unit
If both category labels and numerical units are present (e.g., axis labels), merge them into the table header using the format “category-unit”
-
[74]
Preserve all category labels exactly as they appear in the chart without translation or rewriting
-
[75]
Mind Map Parsing Prompt Please parse the chart content in the image and extract the data into a structured Markdownmulti-level unordered list format
Preserve the original semantics and numerical precision of all values. Mind Map Parsing Prompt Please parse the chart content in the image and extract the data into a structured Markdownmulti-level unordered list format. Requirements:
-
[76]
Use unordered lists beginning with ‘-’, where each node text is represented as a list item
-
[77]
Determine the hierarchy according to the connection relationships between nodes, where parent nodes correspond to higher-level list items and child nodes correspond to nested list items
-
[78]
Flowchart Parsing Prompt Please carefully analyze the followingflowchartimage and fully transcribe it into Mermaid flowchart code
Fully extract all text contained in each node or box while preserving the original language and punctuation. Flowchart Parsing Prompt Please carefully analyze the followingflowchartimage and fully transcribe it into Mermaid flowchart code. Requirements:
-
[79]
Use Mermaid flowchart or graph syntax (preferably flowchart TD or flowchart LR according to the actual direction of the diagram)
-
[80]
Strictly preserve all node text, including the original language and punctuation, without translation, rewriting, or simplification
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.