PAI-Studio: Cinematic Video Background Replacement with Camera-Aware Motion
Pith reviewed 2026-06-28 17:12 UTC · model grok-4.3
The pith
PAI-Studio uses bidirectional attention in a Diffusion Transformer to replace video backgrounds while preserving foreground motion, identity, and lighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
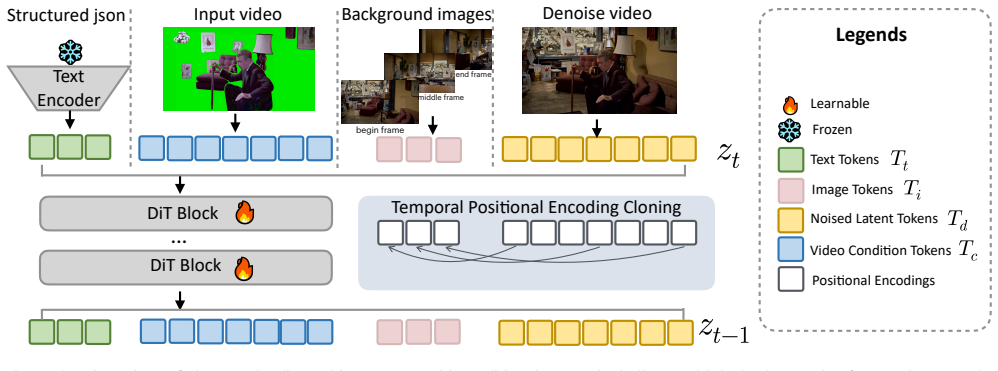
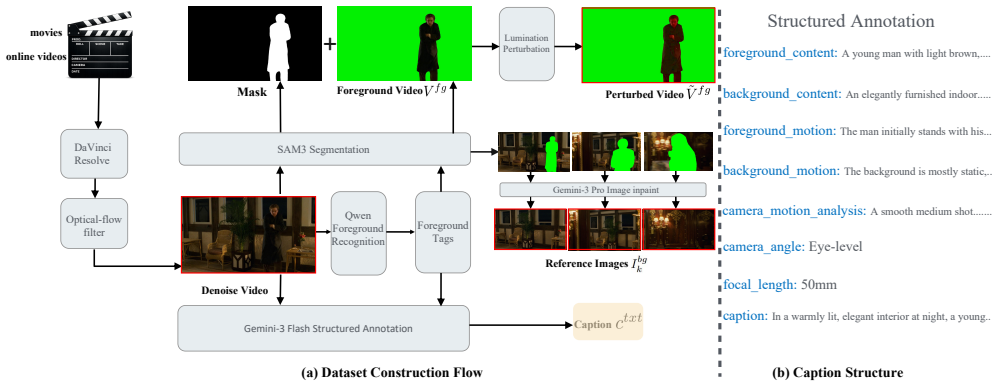
A Diffusion Transformer video backbone reformulated as an in-context conditional generation task via bidirectional attention, trained on a 30K film-derived dataset, produces dynamic backgrounds that align with foreground motion while preserving foreground identity and achieving globally consistent illumination with realistic relighting.
What carries the argument
Bidirectional attention within a Diffusion Transformer video backbone that jointly captures foreground dynamics and background reference information in a unified architecture.
If this is right
- The model produces backgrounds whose motion matches the foreground camera path without separate pose estimation.
- Foreground objects receive relighting that matches the new background's illumination while retaining original appearance details.
- Identity of foreground subjects remains stable across frames and across different reference backgrounds.
- The unified architecture avoids compositing artifacts such as inconsistent boundaries that appear in prior open-source and API systems.
Where Pith is reading between the lines
- The approach may extend to other reference-conditioned video tasks such as object insertion or style transfer if the same bidirectional attention pattern is retained.
- Performance on arbitrary real-world footage could be further improved by adding lightweight camera or lighting adapters on top of the existing backbone.
- The 30K dataset construction process itself offers a template for curating cinematic training data for related synthesis problems.
Load-bearing premise
A single bidirectional-attention Diffusion Transformer trained on the authors' 30K film-derived dataset will generalize to arbitrary real-world camera motion and lighting without additional explicit camera-pose or lighting estimation modules.
What would settle it
Quantitative failure on a held-out test set of real-world videos containing camera trajectories or lighting conditions absent from the 30K training set, measured by drops in motion consistency, relighting fidelity, or identity preservation metrics below commercial baselines.
Figures














read the original abstract
We present PAI-Studio, a new reference-conditioned video synthesis task that addresses a long-standing challenge in cinematic background replacement: generating dynamic backgrounds aligned with foreground motion while preserving foreground identity, matching reference scene appearance, and achieving globally consistent illumination with realistic foreground relighting. Existing open-source systems and commercial APIs cannot simultaneously ensure motion-consistent background generation, high-fidelity foreground relighting and foreground identity preservation, often resulting in static backgrounds, inconsistent boundaries, and noticeable compositing artifacts. To bridge this gap, we build upon a Diffusion Transformer video backbone and reformulate the problem as an in-context conditional generation task. Through bidirectional attention, our model jointly captures foreground dynamics and background reference information within a unified architecture. We further construct a 30K-scale dataset sourced from high-quality films and online videos to support this task. Extensive evaluations demonstrate that our method significantly outperforms existing open-source and commercial API solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PAI-Studio, a reference-conditioned video synthesis method for cinematic background replacement. It builds on a Diffusion Transformer backbone, reformulating the task as in-context conditional generation with bidirectional attention to jointly model foreground dynamics and background references. A 30K-scale dataset sourced from films supports training. The central claim is that the approach significantly outperforms existing open-source and commercial solutions in motion-consistent background generation, high-fidelity foreground relighting, and foreground identity preservation.
Significance. If the empirical claims are substantiated, the work would advance video synthesis for film and media applications by showing that a single bidirectional-attention DiT can implicitly handle camera-aware motion and global illumination without dedicated pose or lighting modules.
major comments (2)
- [Abstract] Abstract: the claim that the method 'significantly outperforms existing open-source and commercial API solutions' is asserted without any quantitative metrics, baselines, ablation studies, or error analysis supplied. This is load-bearing for the central contribution.
- [Method] The central claim rests on the assumption that bidirectional attention in a single DiT, conditioned only on foreground and reference, suffices to capture camera-aware dynamics and global illumination from the 30K film-derived dataset without explicit camera-pose or lighting estimation modules. No tests for out-of-distribution real-world motions or lighting are described, which is load-bearing for the generalization and outperformance assertions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we address each major point directly, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'significantly outperforms existing open-source and commercial API solutions' is asserted without any quantitative metrics, baselines, ablation studies, or error analysis supplied. This is load-bearing for the central contribution.
Authors: The abstract is a concise summary; the full manuscript supplies the requested quantitative metrics (including PSNR/SSIM/LPIPS and user-study scores), multiple baselines, ablations, and error analysis in the Experiments section. We will revise the abstract to include one or two representative quantitative results so the outperformance claim is immediately supported by numbers. revision: partial
-
Referee: [Method] The central claim rests on the assumption that bidirectional attention in a single DiT, conditioned only on foreground and reference, suffices to capture camera-aware dynamics and global illumination from the 30K film-derived dataset without explicit camera-pose or lighting estimation modules. No tests for out-of-distribution real-world motions or lighting are described, which is load-bearing for the generalization and outperformance assertions.
Authors: Our experiments show that bidirectional attention within the single DiT, trained on the diverse 30K film corpus, implicitly learns camera-aware motion and global illumination without auxiliary pose or lighting modules, as evidenced by the reported gains in motion consistency and relighting fidelity. The dataset already spans a wide range of professional camera movements and lighting conditions. We acknowledge that explicit OOD testing on non-cinematic real-world footage is not presented; we will add a limitations paragraph clarifying the intended cinematic scope and the absence of broader OOD claims. revision: partial
Circularity Check
No significant circularity: empirical claims rest on external benchmarks and new dataset
full rationale
The paper introduces a reference-conditioned video synthesis task solved via a Diffusion Transformer backbone reformulated as in-context conditional generation with bidirectional attention, trained on a newly constructed 30K film-derived dataset. Central claims of outperformance in motion-consistent backgrounds, relighting, and identity preservation are supported by evaluations against external open-source systems and commercial APIs. No equations, fitted parameters, self-citations, uniqueness theorems, or ansatzes are described that reduce any prediction or result to the paper's own inputs by construction. The derivation chain is self-contained as an empirical engineering contribution evaluated on independent test cases.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
GeoEdit: Geometry-Aware Object Editing via Dual-Branch Denoising
GeoEdit introduces a Lift-Manipulate-Render-Denoise pipeline with dual-branch denoising and variance-homogeneous injection for 3D-consistent object editing in single photos.
-
LiveEdit: Towards Real-Time Diffusion-Based Streaming Video Editing
LiveEdit distills a bidirectional video foundation model into a unidirectional streaming editor via three-stage training plus mask caching to reach 12.66 FPS with stable edits.
Reference graph
Works this paper leans on
-
[1]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 5
Pith/arXiv arXiv 2025
-
[2]
Text2live: Text-driven layered image and video editing
Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kas- ten, and Tali Dekel. Text2live: Text-driven layered image and video editing. InEuropean conference on computer vi- sion, pages 707–723. Springer, 2022. 3
2022
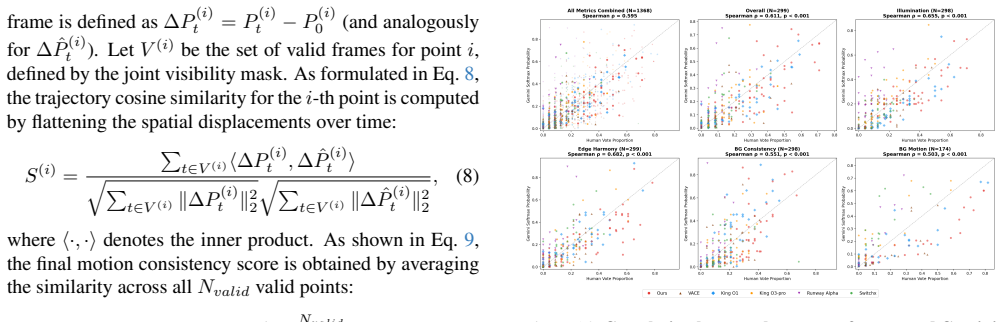
-
[3]
Videopainter: Any- length video inpainting and editing with plug-and-play con- text control
Yuxuan Bian, Zhaoyang Zhang, Xuan Ju, Mingdeng Cao, Liangbin Xie, Ying Shan, and Qiang Xu. Videopainter: Any- length video inpainting and editing with plug-and-play con- text control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–12, 2025. 8
2025
-
[4]
Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22563–22575, 2023. 2, 3
2023
-
[5]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024. 2
2024
-
[6]
Ditctrl: Exploring attention control in multi-modal dif- fusion transformer for tuning-free multi-prompt longer video generation
Minghong Cai, Xiaodong Cun, Xiaoyu Li, Wenze Liu, Zhaoyang Zhang, Yong Zhang, Ying Shan, and Xiangyu Yue. Ditctrl: Exploring attention control in multi-modal dif- fusion transformer for tuning-free multi-prompt longer video generation. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 7763–7772, 2025. 3
2025
-
[7]
Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 5
Pith/arXiv arXiv 2025
-
[8]
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023. 2, 3
Pith/arXiv arXiv 2023
-
[9]
Pengtao Chen, Xianfang Zeng, Maosen Zhao, Peng Ye, Mingzhu Shen, Wei Cheng, Gang Yu, and Tao Chen. Sparse-vdit: Unleashing the power of sparse attention to accelerate video diffusion transformers.arXiv preprint arXiv:2506.03065, 2025. 2
arXiv 2025
-
[10]
Transanimate: Taming layer diffusion to generate rgba video.arXiv preprint arXiv:2503.17934, 2025
Xuewei Chen, Zhimin Chen, and Yiren Song. Transanimate: Taming layer diffusion to generate rgba video.arXiv preprint arXiv:2503.17934, 2025. 3
arXiv 2025
-
[11]
Yinan Chen, Jiangning Zhang, Teng Hu, Yuxiang Zeng, Zhu- cun Xue, Qingdong He, Chengjie Wang, Yong Liu, Xiaobin Hu, and Shuicheng Yan. Ivebench: Modern benchmark suite for instruction-guided video editing assessment.arXiv preprint arXiv:2510.11647, 2025. 7
arXiv 2025
-
[12]
Structure and content-guided video synthesis with diffusion models
Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 7346–7356, 2023. 2, 3
2023
-
[13]
Chenjian Gao, Lihe Ding, Xin Cai, Zhanpeng Huang, Zibin Wang, and Tianfan Xue. Lora-edit: Controllable first-frame- guided video editing via mask-aware lora fine-tuning.arXiv preprint arXiv:2506.10082, 2025. 8
arXiv 2025
-
[14]
Peng Gao, Le Zhuo, Dongyang Liu, Ruoyi Du, Xu Luo, Longtian Qiu, Yuhang Zhang, Chen Lin, Rongjie Huang, Shijie Geng, et al. Lumina-t2x: Transforming text into any modality, resolution, and duration via flow-based large diffu- sion transformers.arXiv preprint arXiv:2405.05945, 2024. 2, 3
arXiv 2024
-
[15]
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion features for consistent video editing.arXiv preprint arXiv:2307.10373, 2023. 3
Pith/arXiv arXiv 2023
-
[16]
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els.arXiv preprint arXiv:2210.02303, 2022. 3
Pith/arXiv arXiv 2022
-
[17]
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022. 3
Pith/arXiv arXiv 2022
-
[18]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3, 2022. 6
2022
-
[19]
Zhihao Hu and Dong Xu. Videocontrolnet: A motion-guided video-to-video translation framework by using diffusion model with controlnet.arXiv preprint arXiv:2307.14073,
-
[20]
Vace: All-in-one video creation and editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 17191–17202, 2025. 6
2025
-
[21]
Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 6013–6022,
-
[22]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2
Pith/arXiv arXiv 2024
-
[23]
Max Ku, Cong Wei, Weiming Ren, Harry Yang, and Wenhu Chen. Anyv2v: A tuning-free framework for any video-to- video editing tasks.arXiv preprint arXiv:2403.14468, 2024. 8
arXiv 2024
-
[24]
Towards an end-to-end framework for flow-guided video inpainting
Zhen Li, Cheng-Ze Lu, Jianhua Qin, Chun-Le Guo, and Ming-Ming Cheng. Towards an end-to-end framework for flow-guided video inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17562–17571, 2022. 3
2022
-
[25]
Real-time high-resolution background matting
Shanchuan Lin, Andrey Ryabtsev, Soumyadip Sengupta, Brian L Curless, Steven M Seitz, and Ira Kemelmacher- Shlizerman. Real-time high-resolution background matting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8762–8771, 2021. 3
2021
-
[26]
Robust high-resolution video matting with tempo- ral guidance
Shanchuan Lin, Linjie Yang, Imran Saleemi, and Soumyadip Sengupta. Robust high-resolution video matting with tempo- ral guidance. InProceedings of the IEEE/CVF Winter Con- ference on Applications of Computer Vision, pages 238–247,
-
[27]
Omnipsd: Layered psd generation with diffusion transformer.arXiv preprint arXiv:2512.09247, 2025
Cheng Liu, Yiren Song, Haofan Wang, and Mike Zheng Shou. Omnipsd: Layered psd generation with diffusion transformer.arXiv preprint arXiv:2512.09247, 2025. 2
arXiv 2025
-
[28]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
Pith/arXiv arXiv 2017
-
[29]
Follow your pose: Pose- guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Xiu Li, and Qifeng Chen. Follow your pose: Pose- guided text-to-video generation using pose-free videos. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 4117–4125, 2024. 3
2024
-
[30]
Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–12, 2024
2024
-
[31]
Follow-your-click: Open-domain regional image animation via motion prompts
Yue Ma, Yingqing He, Hongfa Wang, Andong Wang, Leqi Shen, Chenyang Qi, Jixuan Ying, Chengfei Cai, Zhifeng Li, Heung-Yeung Shum, et al. Follow-your-click: Open-domain regional image animation via motion prompts. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 6018–6026, 2025
2025
-
[32]
Yue Ma, Yulong Liu, Qiyuan Zhu, Ayden Yang, Kunyu Feng, Xinhua Zhang, Zhifeng Li, Sirui Han, Chenyang Qi, and Qifeng Chen. Follow-your-motion: Video motion transfer via efficient spatial-temporal decoupled finetuning.arXiv preprint arXiv:2506.05207, 2025. 3
arXiv 2025
-
[33]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[34]
The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 7
Pith/arXiv arXiv 2017
-
[35]
Fatezero: Fus- ing attentions for zero-shot text-based video editing
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. Fatezero: Fus- ing attentions for zero-shot text-based video editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15932–15942, 2023. 3
2023
-
[36]
High-resolution image synthesis with latent dif- fusion models [internet].arXiv [cs
R Rombach. High-resolution image synthesis with latent dif- fusion models [internet].arXiv [cs. CV]., 2021. 8
2021
-
[37]
Make-a-video: Text-to-video genera- tion without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video genera- tion without text-video data. InInternational Conference on Learning Representations, 2023. 3
2023
-
[38]
Video edit- ing via factorized diffusion distillation
Uriel Singer, Amit Zohar, Yuval Kirstain, Shelly Sheynin, Adam Polyak, Devi Parikh, and Yaniv Taigman. Video edit- ing via factorized diffusion distillation. InEuropean Con- ference on Computer Vision, pages 450–466. Springer, 2024. 3
2024
-
[39]
Quanjian Song, Yiren Song, Kelly Peng, Yuan Gao, and Mike Zheng Shou. Worldwander: Bridging egocentric and exocentric worlds in video generation.arXiv preprint arXiv:2511.22098, 2025. 3
arXiv 2025
-
[40]
Proces- spainter: Learn painting process from sequence data.arXiv preprint arXiv:2406.06062, 2024
Yiren Song, Shijie Huang, Chen Yao, Xiaojun Ye, Hai Ci, Jiaming Liu, Yuxuan Zhang, and Mike Zheng Shou. Proces- spainter: Learn painting process from sequence data.arXiv preprint arXiv:2406.06062, 2024. 3
arXiv 2024
-
[41]
Yiren Song, Danze Chen, and Mike Zheng Shou. Layer- tracer: Cognitive-aligned layered svg synthesis via diffusion transformer.arXiv preprint arXiv:2502.01105, 2025. 3
arXiv 2025
-
[42]
Mitty: Diffusion-based human-to-robot video generation
Yiren Song, Cheng Liu, Weijia Mao, and Mike Zheng Shou. Mitty: Diffusion-based human-to-robot video generation. arXiv preprint arXiv:2512.17253, 2025. 2
arXiv 2025
-
[43]
Yiren Song, Cheng Liu, and Mike Zheng Shou. Makeany- thing: Harnessing diffusion transformers for multi- domain procedural sequence generation.arXiv preprint arXiv:2502.01572, 2025. 3
arXiv 2025
-
[44]
Yiren Song, Cheng Liu, and Mike Zheng Shou. Omniconsis- tency: Learning style-agnostic consistency from paired styl- ization data.arXiv preprint arXiv:2505.18445, 2025. 2
arXiv 2025
-
[45]
Omnihumanoid: Streaming cross- embodiment video generation with paired-free adaptation
Yiren Song, Xiyao Deng, Pei Yang, Yihan Wang, and Mike Zheng Shou. Omnihumanoid: Streaming cross- embodiment video generation with paired-free adaptation. arXiv preprint arXiv:2605.12038, 2026
Pith/arXiv arXiv 2026
-
[46]
Yiren Song, Wangzi Yao, Haofan Wang, and Mike Zheng Shou. Vista: Triplet-supervised video style transfer with dif- fusion transformers.arXiv preprint arXiv:2605.17312, 2026. 2
Pith/arXiv arXiv 2026
-
[47]
Deep video matting via spatio-temporal align- ment and aggregation
Yanan Sun, Guanzhi Wang, Qiao Gu, Chi-Keung Tang, and Yu-Wing Tai. Deep video matting via spatio-temporal align- ment and aggregation. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6975–6984, 2021. 3
2021
-
[48]
Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 4, 6, 3, 12
Pith/arXiv arXiv 2023
-
[49]
Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 3, 15
Pith/arXiv arXiv 2025
-
[50]
Video-to- video synthesis
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. Video-to- video synthesis. InAdvances in Neural Information Pro- cessing Systems, 2018. 3
2018
-
[51]
Videocomposer: Compositional video synthesis with motion controllability.Advances in Neural Information Processing Systems, 36:7594–7611, 2023
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Ji- uniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jin- gren Zhou. Videocomposer: Compositional video synthesis with motion controllability.Advances in Neural Information Processing Systems, 36:7594–7611, 2023. 8
2023
-
[52]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 7
2004
-
[53]
Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7623–7633, 2023. 3
2023
-
[54]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. InEu- ropean Conference on Computer Vision, pages 399–417. Springer, 2024. 3
2024
-
[55]
Motioncanvas: Cinematic shot design with controllable image-to-video generation
Jinbo Xing, Long Mai, Cusuh Ham, Jiahui Huang, Anirud- dha Mahapatra, Chi-Wing Fu, Tien-Tsin Wong, and Feng Liu. Motioncanvas: Cinematic shot design with controllable image-to-video generation. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–11, 2025. 3
2025
-
[56]
Magicanimate: Temporally consistent human im- age animation using diffusion model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human im- age animation using diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1481–1490, 2024. 8
2024
-
[57]
Han Yan, Xibin Song, Yifu Wang, Hongdong Li, Pan Ji, and Chao Ma. Bachvid: Training-free video generation with consistent background and character.arXiv preprint arXiv:2510.21696, 2025. 3
arXiv 2025
-
[58]
Motion-conditioned image animation for video editing.arXiv preprint arXiv:2311.18827, 2023
Wilson Yan, Andrew Brown, Pieter Abbeel, Rohit Girdhar, and Samaneh Azadi. Motion-conditioned image animation for video editing.arXiv preprint arXiv:2311.18827, 2023. 3
arXiv 2023
-
[59]
Rerender a video: Zero-shot text-guided video-to-video translation
Shuai Yang, Yifan Zhou, Ziwei Liu, and Chen Change Loy. Rerender a video: Zero-shot text-guided video-to-video translation. InSIGGRAPH Asia 2023 Conference Papers, pages 1–11, 2023. 3
2023
-
[60]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2
Pith/arXiv arXiv 2024
-
[61]
Transparent image layer diffusion using latent transparency.arXiv preprint arXiv:2402.17113, 2024
Lvmin Zhang and Maneesh Agrawala. Transparent image layer diffusion using latent transparency.arXiv preprint arXiv:2402.17113, 2024. 3
arXiv 2024
-
[62]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 7
2018
-
[63]
Yuxuan Zhang, Yirui Yuan, Yiren Song, Haofan Wang, and Jiaming Liu. Easycontrol: Adding efficient and flexible control for diffusion transformer.arXiv preprint arXiv:2503.07027, 2025. 2
arXiv 2025
-
[64]
Propainter: Improving propagation and transformer for video inpainting
Shangchen Zhou, Chongyi Li, Kelvin CK Chan, and Chen Change Loy. Propainter: Improving propagation and transformer for video inpainting. InProceedings of the IEEE/CVF international conference on computer vision, pages 10477–10486, 2023. 3 PAI-Studio: Cinematic Video Background Replacement with Camera-Aware Motion Supplementary Material The supplementary m...
2023
-
[65]
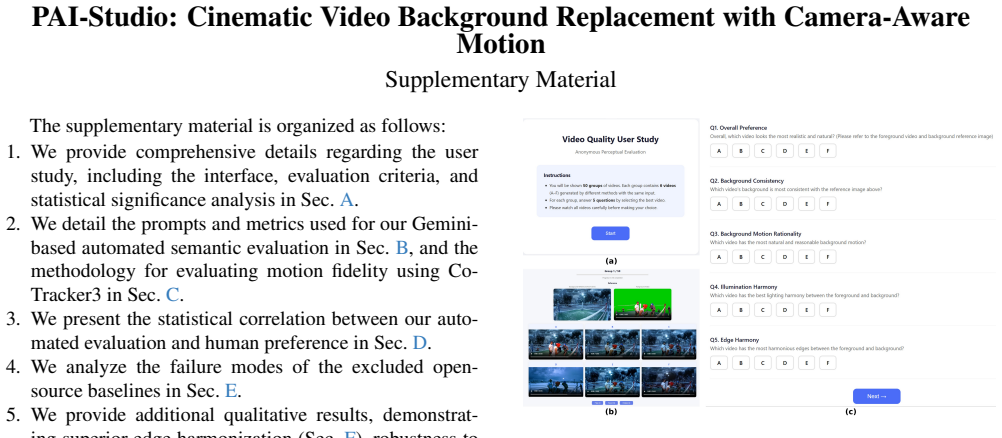
We provide comprehensive details regarding the user study, including the interface, evaluation criteria, and statistical significance analysis in Sec. A
-
[66]
B, and the methodology for evaluating motion fidelity using Co- Tracker3 in Sec
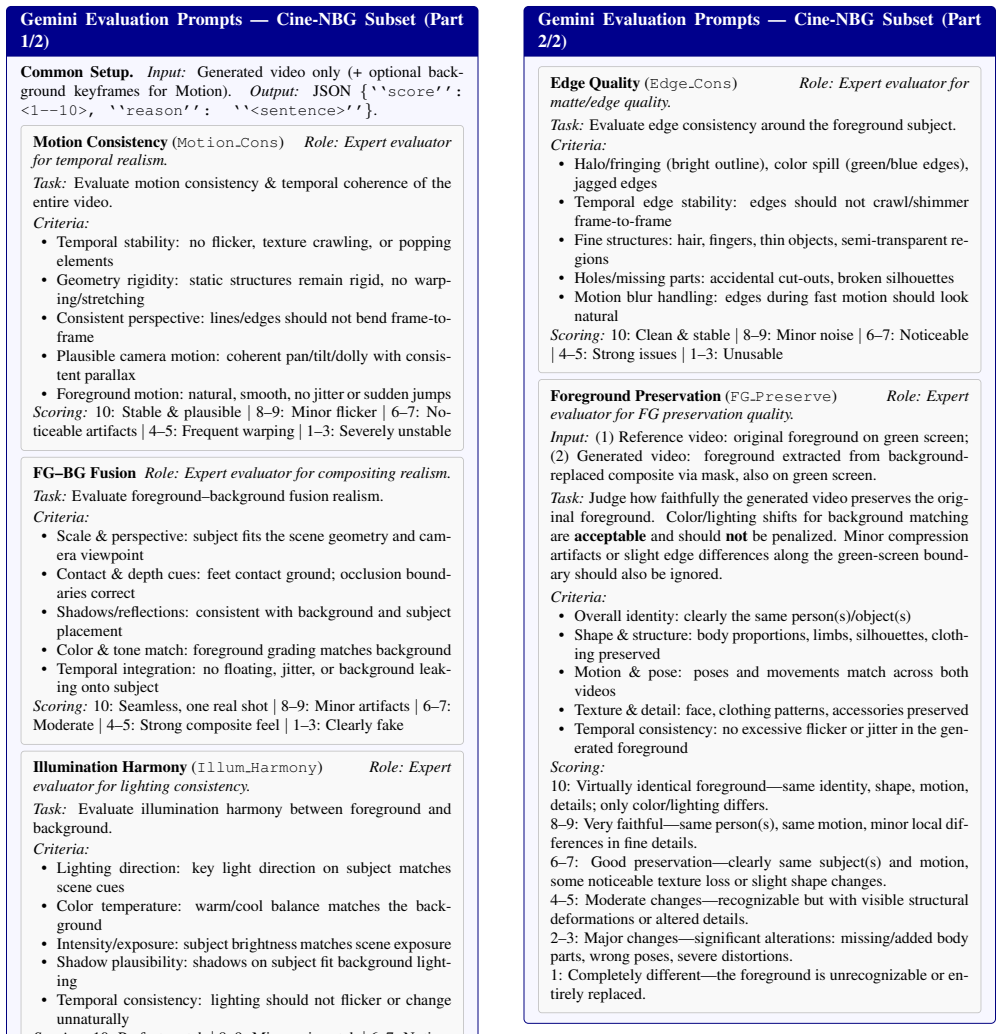
We detail the prompts and metrics used for our Gemini- based automated semantic evaluation in Sec. B, and the methodology for evaluating motion fidelity using Co- Tracker3 in Sec. C
-
[67]
We present the statistical correlation between our auto- mated evaluation and human preference in Sec. D
-
[68]
We analyze the failure modes of the excluded open- source baselines in Sec. E
-
[69]
F), robustness to imperfect masks (Sec
We provide additional qualitative results, demonstrat- ing superior edge harmonization (Sec. F), robustness to imperfect masks (Sec. G), implicit scene-adaptive re- lighting (Sec. H), and the effect of multi-frame control (Sec. J)
-
[70]
We discuss our explorations into efficient conditioning strategies in Sec. K
-
[71]
We provide the prompt templates used for generating structured video annotations in Sec. I
-
[72]
We report the computational cost and resources for train- ing and inference in Sec. L
-
[73]
green spill
We present an analysis of typical failure cases in Sec. M. A. User Study Details The interface and workflow of our user study are illustrated in Fig. 8. We designed a comprehensive evaluation pipeline to compare the perceptual quality of our method against five representative baselines. Experimental Protocol.As shown in the study in- structions (Fig. 8a),...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.