KV-Control: Parameter-Efficient K/V Injection for Trajectory-Controlled Text-to-Motion
Pith reviewed 2026-06-28 02:33 UTC · model grok-4.3
The pith
KV-Control injects control keys and values into self-attention layers of frozen text-to-motion transformers to achieve precise trajectory tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
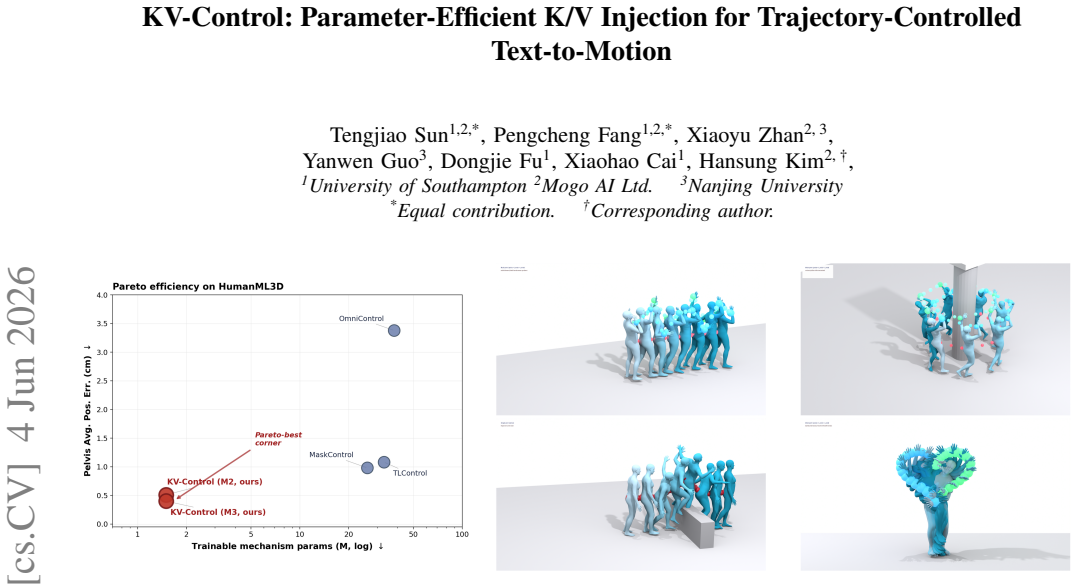
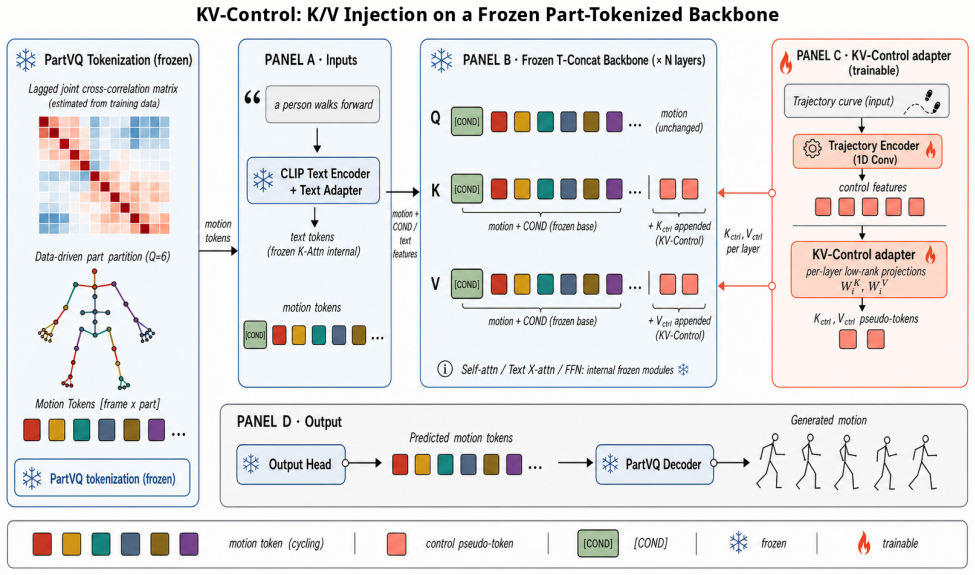
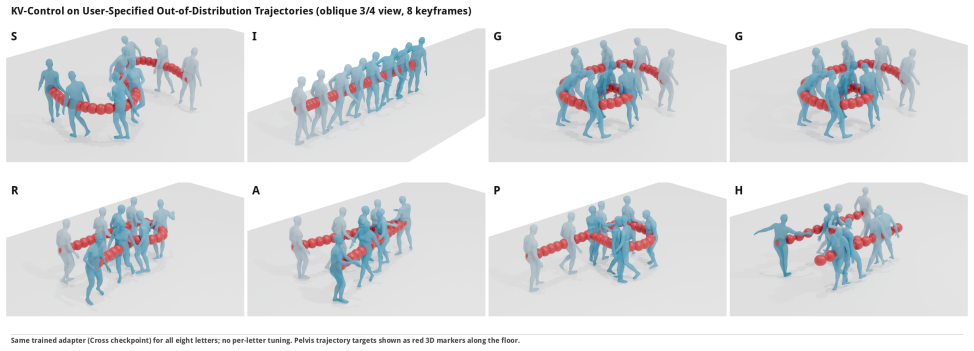
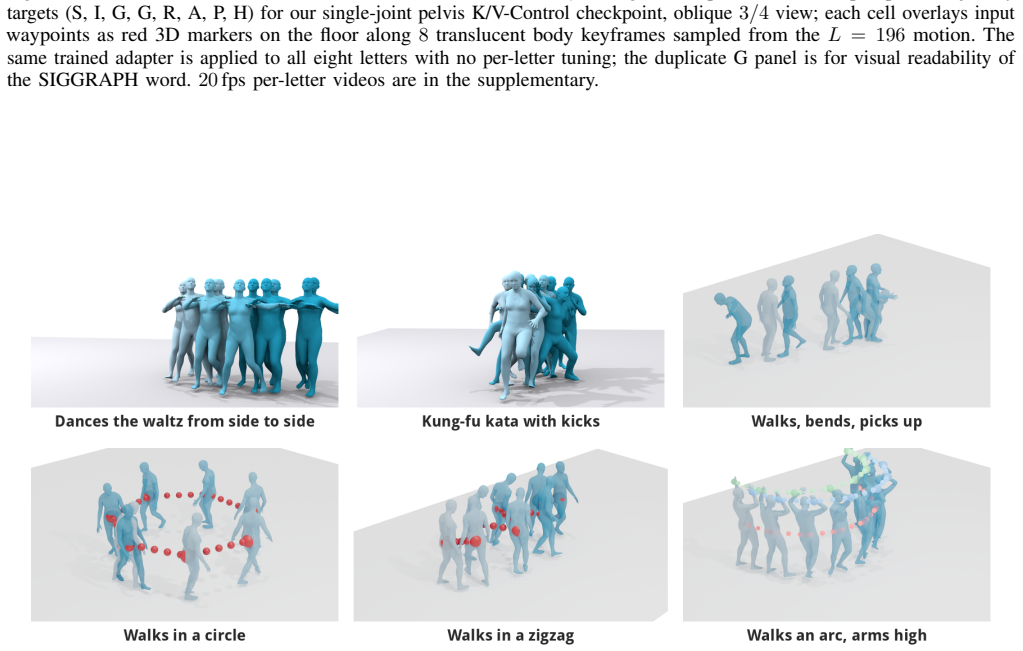
KV-Control supplies control-conditioned key/value memories at every self-attention layer of a frozen masked text-to-motion transformer, preserving the pretrained query stream, text cross-attention, FFN, and all backbone weights, while a co-designed PartVQ and T-Concat substrate turns each frame-part token into an attention-addressable site; the resulting adapter uses only trainable injection parameters atop a shared trajectory encoder yet tracks root and multi-joint constraints to sub-centimeter accuracy under the inherited refinement protocol while retaining text-conditioned motion quality.
What carries the argument
KV-Control, the injection of control-conditioned key/value memories into self-attention layers that leaves the query stream and pretrained weights untouched.
If this is right
- Only the injection parameters need training, keeping the original model frozen.
- Control remains compatible with the inherited refinement protocol for further accuracy gains.
- Trajectory conditioning becomes a form of memory retrieval inside attention rather than a separate global token.
- The same interface can support root paths and multi-joint targets simultaneously.
Where Pith is reading between the lines
- The same K/V injection pattern could be tested on other frozen generative transformers that already use part-based tokenization.
- Multiple independent control signals might be combined by simply stacking additional injection heads without enlarging the backbone.
- If the part tokens remain addressable, the method could extend to time-varying constraints supplied at inference time.
Load-bearing premise
Providing geometric constraints as memory inside self-attention will not overwrite the pretrained text-conditioned motion prior, and the part-tokenized substrate supplies enough addressable sites for the injection to work.
What would settle it
Generate motions from the controlled model on held-out trajectory prompts and measure whether root or joint positions deviate more than one centimeter from the targets while text alignment metrics drop below the base model's level.
Figures
read the original abstract
Text-conditioned 3D human motion models now synthesize plausible motions from prompts, but practical animation and embodied-agent workflows rarely stop at text: a character may need to follow a sketched root path, hit an end-effector target, or satisfy a multi-joint trajectory while still preserving the gait, style, and intent described by language. This exposes a control trade-off. A trajectory controller should be precise without overwriting the pretrained text-conditioned motion prior, yet existing solutions either duplicate large portions of the generator to regain per-layer control access or move much of the cost to test-time optimization. We introduce KV-Control, a compact attention-side control interface for frozen masked text-to-motion transformers. The key idea is to make geometric constraints available as memory inside self-attention rather than injecting them through a global pose token or enforcing them only at the output side. To support this interface, we co-design a part-tokenized motion substrate and controller: \textbf{PartVQ} learns anatomy-aligned part codebooks, T-Concat exposes each frame--part token as an attention-addressable site, and KV-Control injects control-conditioned key/value memories at every self-attention layer while preserving the pretrained query stream, text cross-attention, FFN, and all backbone weights. The resulting adapter adds only trainable injection parameters atop a shared trajectory encoder, yet tracks root and multi-joint constraints with sub-centimeter accuracy under the inherited refinement protocol while retaining text-conditioned motion quality. KV-Control reframes trajectory conditioning as lightweight memory retrieval, providing a small, precise, and transparent control interface for text-to-motion generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KV-Control, a parameter-efficient adapter for adding trajectory control to frozen masked text-to-motion transformers. It co-designs PartVQ (anatomy-aligned part codebooks), T-Concat (frame-part tokens as attention-addressable sites), and KV-Control (injection of control-conditioned K/V memories into every self-attention layer) while freezing the query stream, text cross-attention, FFN, and backbone weights. The adapter uses only trainable injection parameters on top of a shared trajectory encoder and claims sub-centimeter accuracy on root and multi-joint constraints under an inherited refinement protocol while retaining text-conditioned motion quality.
Significance. If the central claims hold, the work provides a lightweight, transparent alternative to duplicating large generators or relying on test-time optimization for precise geometric control in text-to-motion models. Treating trajectory signals as retrievable memory inside attention, rather than global tokens or output enforcement, is a clean architectural choice that could apply to other conditional generation settings. The emphasis on preserving the frozen text prior is practically valuable for animation and embodied-agent workflows.
major comments (2)
- [Abstract and §4 (Experiments)] The central claim that geometric K/V injection preserves the pretrained text-conditioned prior while enabling precise control is load-bearing but unsupported without explicit verification. The manuscript must report standard text-to-motion metrics (FID, R-Precision, diversity) for both the original model and the KV-Control-equipped model on a held-out text-only test set in the zero-control (neutral trajectory) case; absence of this comparison leaves open the possibility that the part-tokenized substrate or learned injection weights subtly shift the prior.
- [Abstract] Sub-centimeter tracking accuracy is asserted for root and multi-joint constraints, yet the abstract and available description provide no dataset information, baseline comparisons, error bars, or statistical details. This makes it impossible to assess whether the reported precision is robust or protocol-specific.
minor comments (2)
- [§3 (Method)] Notation for PartVQ codebooks and T-Concat tokenization should be defined with explicit equations or pseudocode in the method section for reproducibility.
- [Abstract] The abstract uses 'sub-centimeter accuracy' without specifying the exact error metric (e.g., mean per-joint position error); this should be clarified with a precise definition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight areas where the manuscript's claims require stronger empirical support. We address each below and commit to revisions that directly incorporate the requested verifications and details.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] The central claim that geometric K/V injection preserves the pretrained text-conditioned prior while enabling precise control is load-bearing but unsupported without explicit verification. The manuscript must report standard text-to-motion metrics (FID, R-Precision, diversity) for both the original model and the KV-Control-equipped model on a held-out text-only test set in the zero-control (neutral trajectory) case; absence of this comparison leaves open the possibility that the part-tokenized substrate or learned injection weights subtly shift the prior.
Authors: We agree that the preservation claim requires explicit zero-control verification on standard metrics. The current manuscript asserts retention of text-conditioned quality but does not include the requested side-by-side comparison. In the revision we will add FID, R-Precision, and diversity results for both the frozen original model and the KV-Control adapter on a held-out text-only test set under neutral (zero-control) trajectories. This will directly confirm that the part-tokenized substrate and injection weights do not degrade the pretrained prior. revision: yes
-
Referee: [Abstract] Sub-centimeter tracking accuracy is asserted for root and multi-joint constraints, yet the abstract and available description provide no dataset information, baseline comparisons, error bars, or statistical details. This makes it impossible to assess whether the reported precision is robust or protocol-specific.
Authors: We acknowledge the abstract's brevity omits necessary experimental context for the accuracy claim. While the body references the inherited refinement protocol and reports sub-centimeter errors, the abstract itself lacks dataset, baseline, error-bar, and statistical details. In revision we will expand the abstract (within length limits) and ensure the results section explicitly states the dataset, baselines, error statistics, and protocol to make the precision claim fully assessable and reproducible. revision: partial
Circularity Check
No circularity: architecture described without equations or self-referential reductions
full rationale
The provided abstract and description introduce KV-Control as a design for parameter-efficient injection into a frozen transformer, using PartVQ and T-Concat as co-designed substrates. No equations, fitted parameters, predictions, or uniqueness theorems are presented that reduce by construction to inputs or prior self-citations. Claims of sub-centimeter tracking and retained text quality are framed as outcomes of the adapter under an inherited protocol, with no load-bearing step shown to be definitional or statistically forced. The derivation chain is therefore self-contained as an engineering proposal rather than a tautological mapping.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MoGeFlow: Flowing Through Motion Codebook Geometry for Text-to-Motion Generation
MoGeFlow learns text-conditioned flows over PartVQ group-specific code embeddings to generate motions, achieving SOTA R-Precision on HumanML3D and KIT-ML while preserving discrete token validity.
Reference graph
Works this paper leans on
-
[1]
Guo, Chuan and Mu, Yuxuan and Javed, Muhammad Gohar and Wang, Sen and Cheng, Li , booktitle=
-
[2]
Pinyoanuntapong, Ekkasit and Wang, Pu and Lee, Minwoo and Chen, Chen , booktitle=
-
[3]
International Conference on Learning Representations (ICLR) , year=
Human Motion Diffusion Model , author=. International Conference on Learning Representations (ICLR) , year=
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Executing your Commands via Motion Diffusion in Latent Space , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[5]
Zhang, Mingyuan and Cai, Zhongang and Pan, Liang and Hong, Fangzhou and Guo, Xinying and Yang, Lei and Liu, Ziwei , journal=
-
[6]
Zhang, Jianrong and Zhang, Yangsong and Cun, Xiaodong and Zhang, Yong and Zhao, Hongwei and Lu, Hongtao and Shen, Xi and Shan, Ying , booktitle=
-
[7]
2025 , eprint=
Absolute Coordinates Make Motion Generation Easy , author=. 2025 , eprint=
2025
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Rethinking Diffusion for Text-Driven Human Motion Generation: Redundant Representations, Evaluation, and Masked Autoregression , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[9]
ACM SIGGRAPH 2002 Papers , year=
Motion Graphs , author=. ACM SIGGRAPH 2002 Papers , year=
2002
-
[10]
ACM Transactions on Graphics , volume=
Phase-Functioned Neural Networks for Character Control , author=. ACM Transactions on Graphics , volume=
-
[11]
ACM Transactions on Graphics , volume=
Learned Motion Matching , author=. ACM Transactions on Graphics , volume=
-
[12]
Pinyoanuntapong, Ekkasit and others , booktitle=
-
[13]
Wan, Weilin and others , booktitle=
-
[14]
Xie, Yiming and others , booktitle=
-
[15]
Karunratanakul, Korrawe and others , booktitle=
-
[16]
ACM SIGGRAPH 2024 Conference Proceedings , year=
Flexible Motion In-betweening with Diffusion Models , author=. ACM SIGGRAPH 2024 Conference Proceedings , year=
2024
-
[17]
Dai, Wenxun and others , booktitle=
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Neural Discrete Representation Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[19]
International Conference on Machine Learning (ICML) , year=
Learning Transferable Visual Models From Natural Language Supervision , author=. International Conference on Machine Learning (ICML) , year=
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Generating Diverse and Natural 3D Human Motions from Text , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[21]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Adding Conditional Control to Text-to-Image Diffusion Models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[22]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle=
-
[23]
Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing , year=
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing , year=
-
[24]
2023 , eprint=
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models , author=. 2023 , eprint=
2023
-
[25]
2022 , eprint=
Classifier-Free Diffusion Guidance , author=. 2022 , eprint=
2022
-
[26]
Jiang, Biao and Chen, Xin and Liu, Wen and Yu, Jingyi and Yu, Gang and Chen, Tao , booktitle=
-
[27]
Zhang, Mingyuan and Guo, Xinying and Pan, Liang and Cai, Zhongang and Hong, Fangzhou and Li, Huirong and Yang, Lei and Liu, Ziwei , booktitle=
-
[28]
Pinyoanuntapong, Ekkasit and Saleem, Muhammad Usama and Wang, Pu and Lee, Minwoo and Chen, Chen , booktitle=
-
[29]
European Conference on Computer Vision (ECCV) , year=
Motion Mamba: Efficient and Long Sequence Motion Generation , author=. European Conference on Computer Vision (ECCV) , year=
-
[30]
Zhang, Mingyuan and Li, Huirong and Cai, Zhongang and Ren, Jiawei and Yang, Lei and Liu, Ziwei , booktitle=
-
[31]
International Conference on Learning Representations (ICLR) , year=
Human Motion Diffusion as a Generative Prior , author=. International Conference on Learning Representations (ICLR) , year=
-
[32]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Optimizing Diffusion Noise Can Serve As Universal Motion Priors , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[33]
Wang, Zhenzhi and Wang, Jingbo and Lin, Dahua and Dai, Bo , booktitle=
-
[34]
Huang, Yiming and Wan, Weilin and Yang, Yue and Callison-Burch, Chris and Yatskar, Mark and Liu, Lingjie , booktitle=
-
[35]
Chi, Seunggeun and Chien, Hyung-gun and Yi, Wenhe and Beadle, Charles and Hwang, Karthik Ramani , booktitle=
-
[36]
Zeng, Ling-an and Yang, Guohong and Liu, Yi-Lin and Pan, Jingkun and Liu, Wei-Shi , booktitle=
-
[37]
Zou, Qiran and Wang, Shangyuan and Zhao, Yi and Sun, Haoyu and Zhang, Wei , booktitle=
-
[38]
, booktitle=
Chang, Huiwen and Zhang, Han and Jiang, Lu and Liu, Ce and Freeman, William T. , booktitle=
-
[39]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and de Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle=. Parameter-Efficient Transfer Learning for
-
[40]
2025 , eprint=
Fractal Generative Models , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.