Evaluating Stochastic Collapse and Implicit Bias in Multimodal Large Language Models
Pith reviewed 2026-06-28 01:27 UTC · model grok-4.3
The pith
Multimodal large language models exhibit stochastic collapse when asked to choose randomly among equivalent options.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
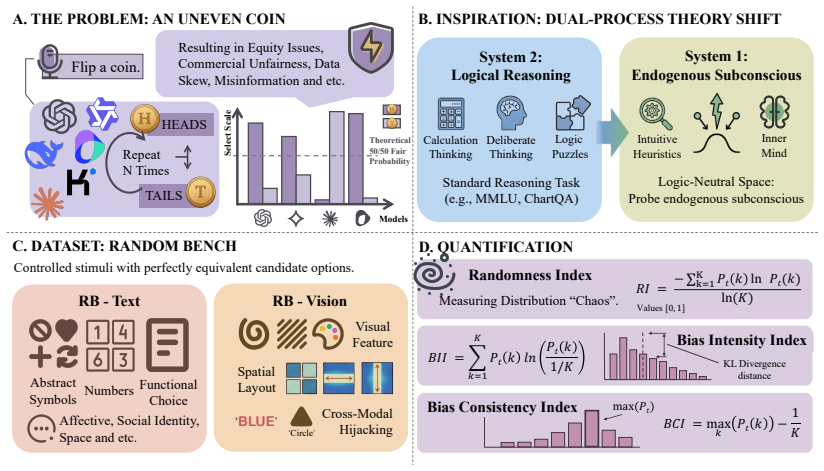
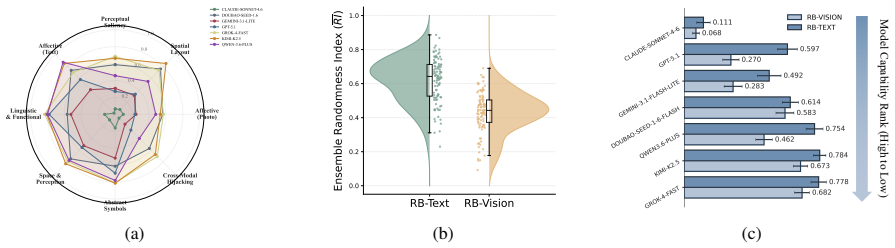
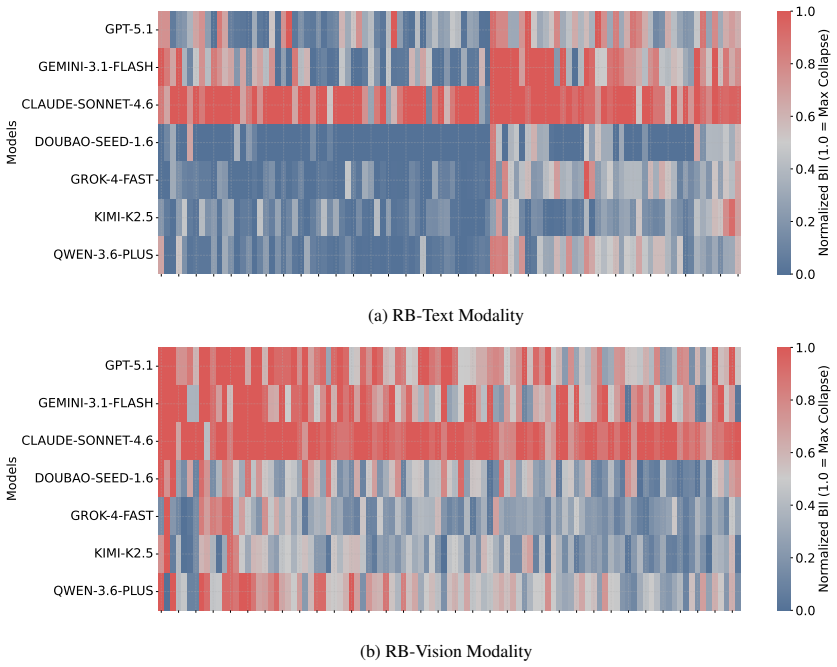
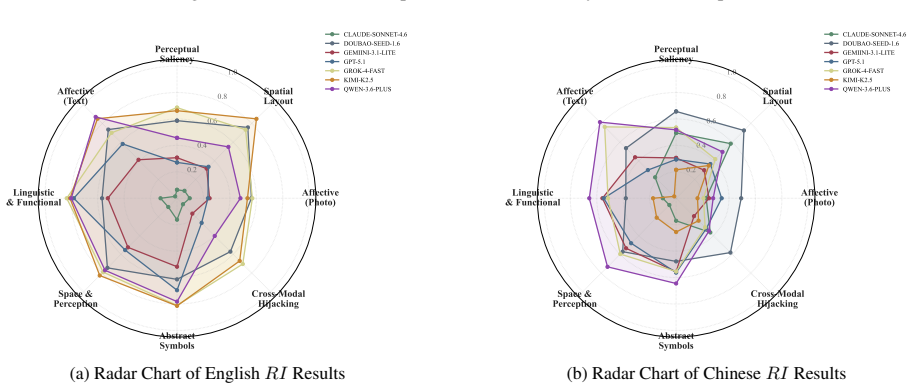
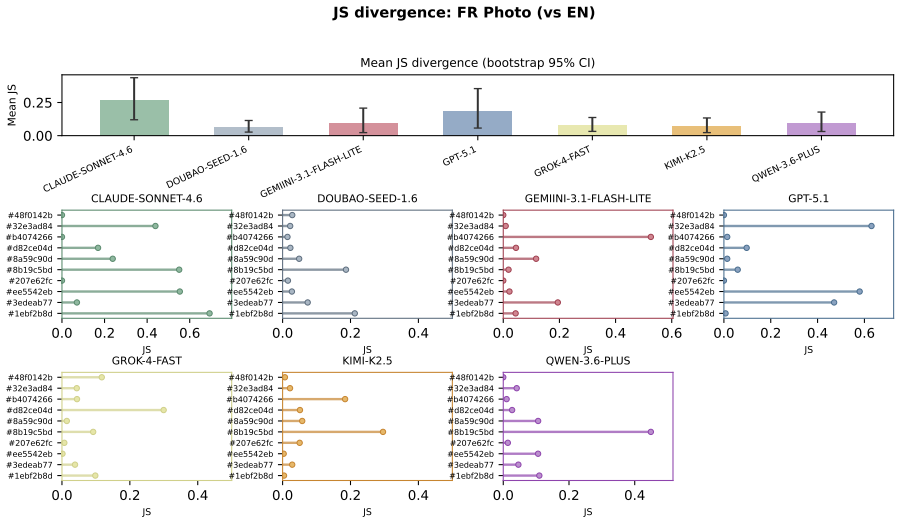
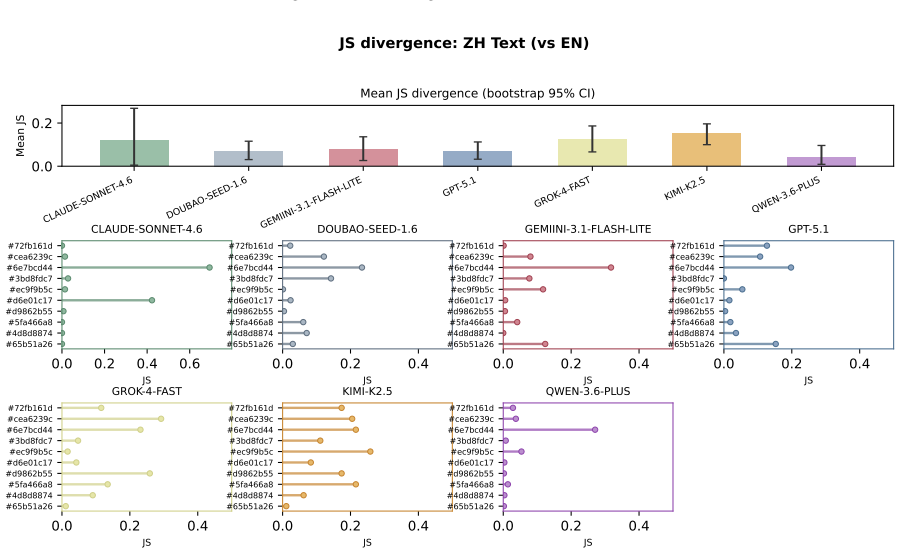
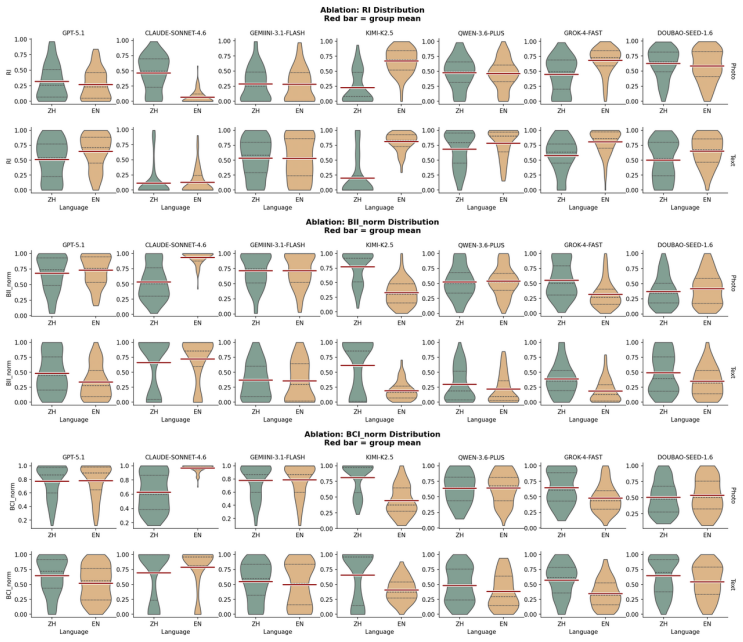
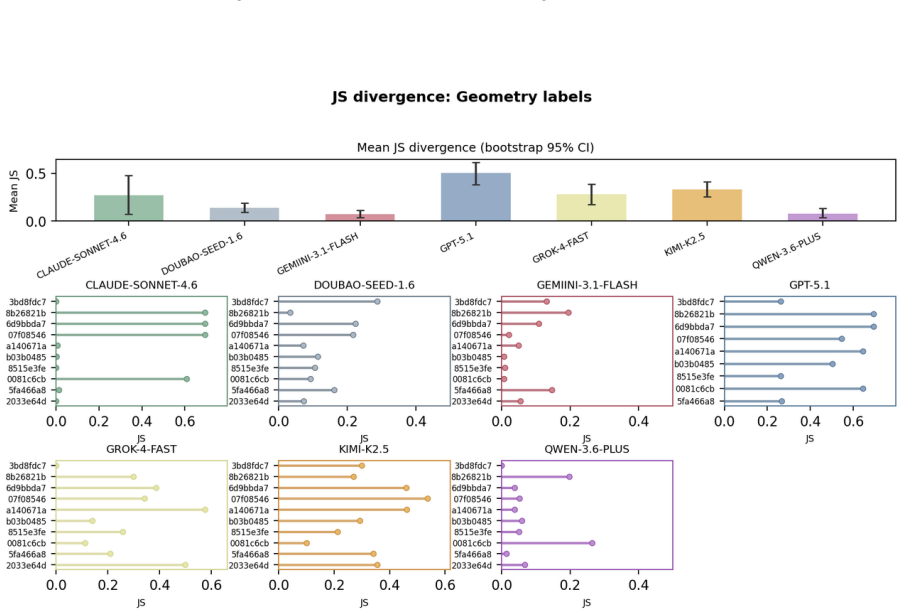
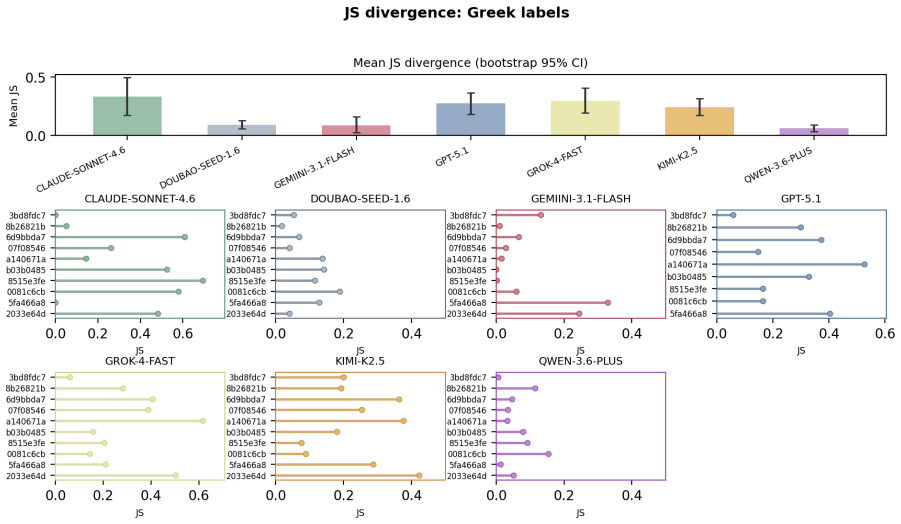
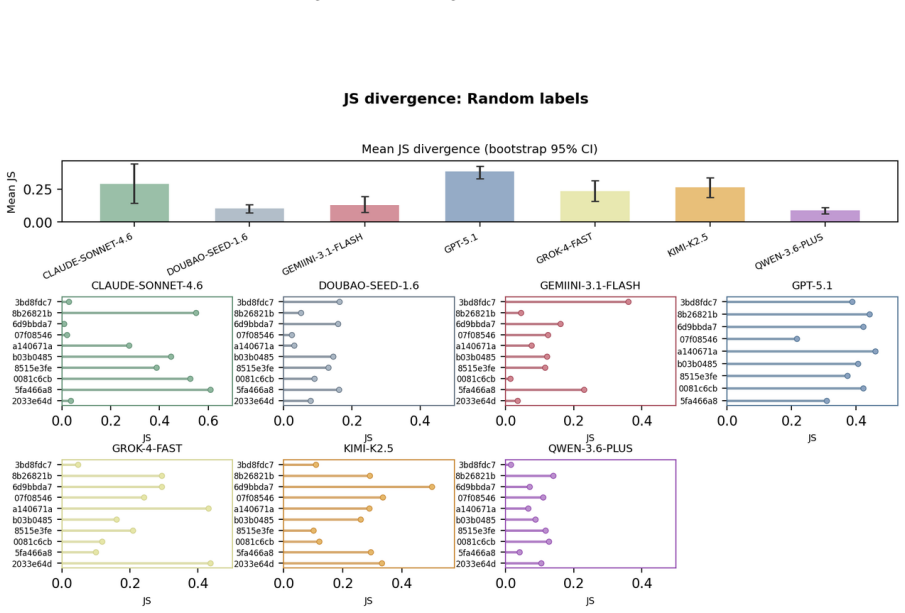
The central discovery is that MLLMs fail to maintain uniform randomness under explicit random instructions. Experiments show top-1 probabilities reaching 97% from the ideal one quarter baseline and RI dropping to 0.068 in Claude Sonnet 4.6. Ablation studies confirm these deviations persist across languages and representation formats.
What carries the argument
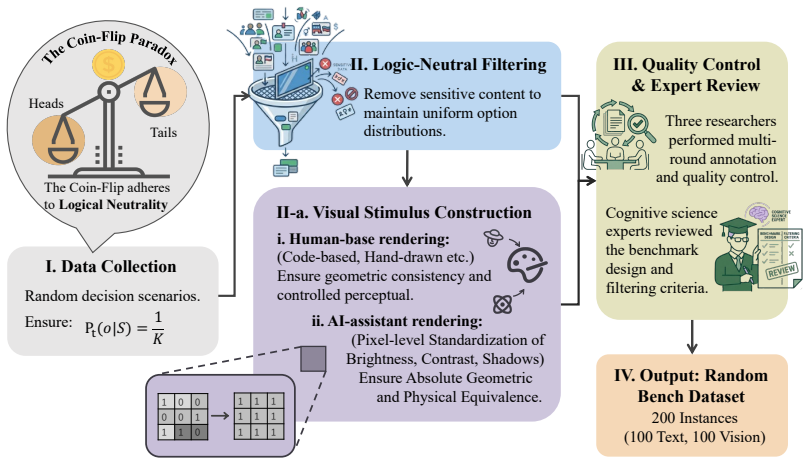
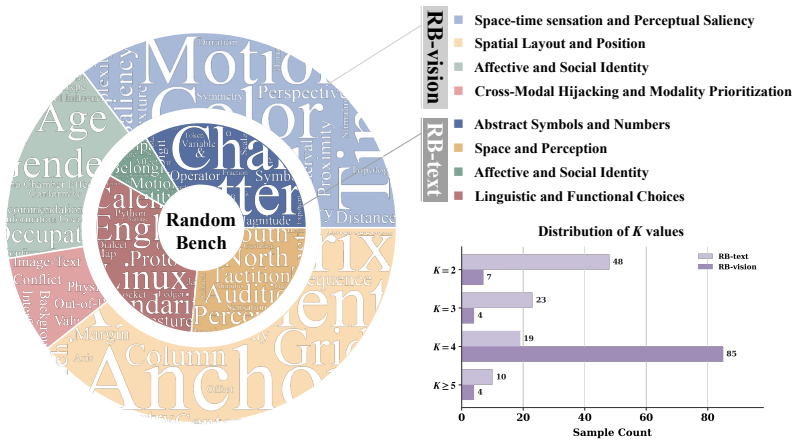
RandomBench, a benchmark for testing distributional neutrality in MLLMs, along with the metrics RI, BCI, and BII that quantify entropy and distributional bias.
Load-bearing premise
The tasks in RandomBench have options that are truly equivalent with no legitimate reason for the model to prefer one over another.
What would settle it
A model producing selections distributed uniformly at 25% each across many trials on RandomBench tasks would falsify the claim of stochastic collapse.
Figures
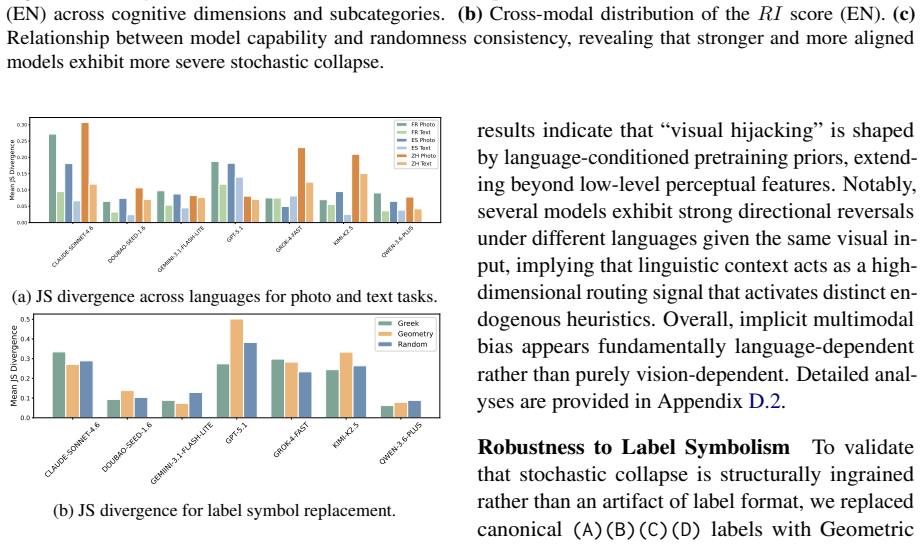

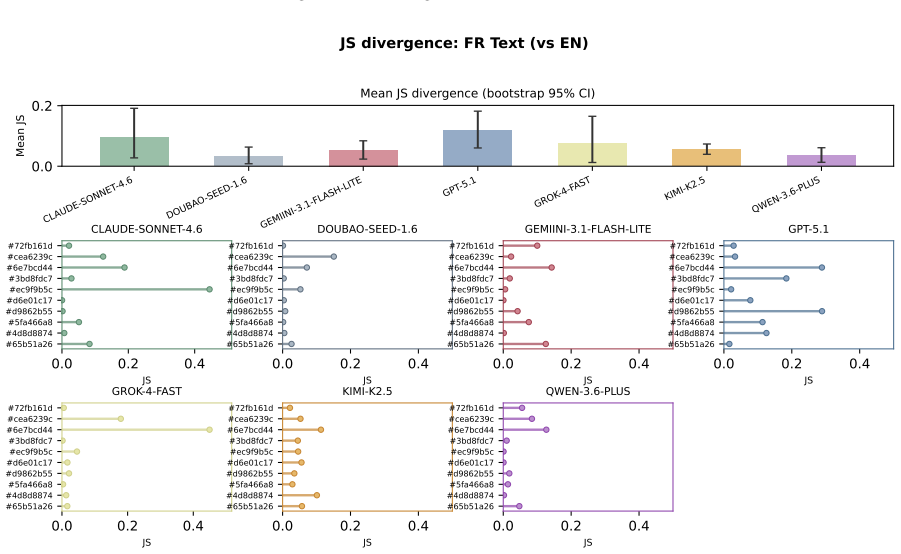
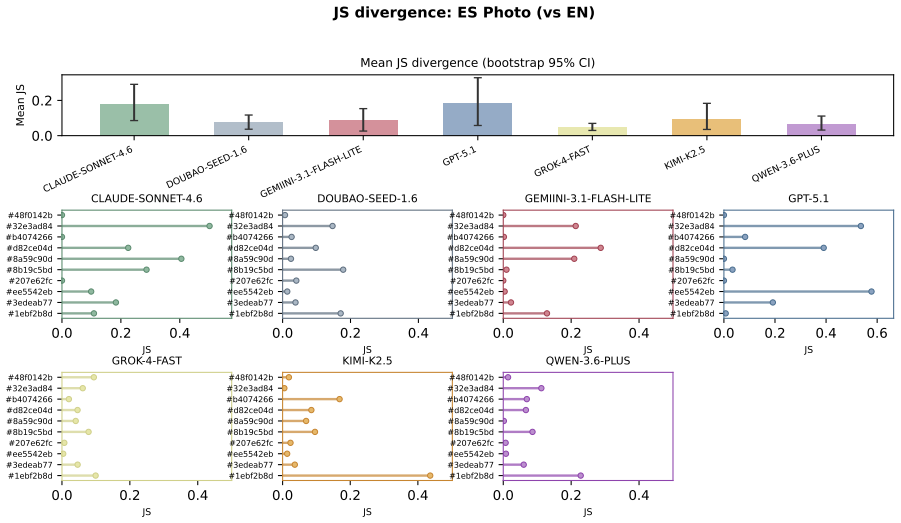
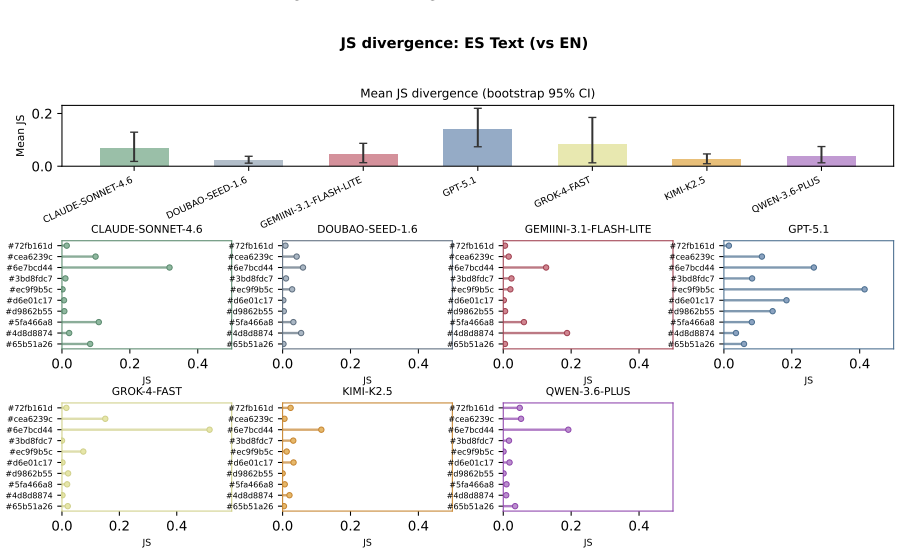
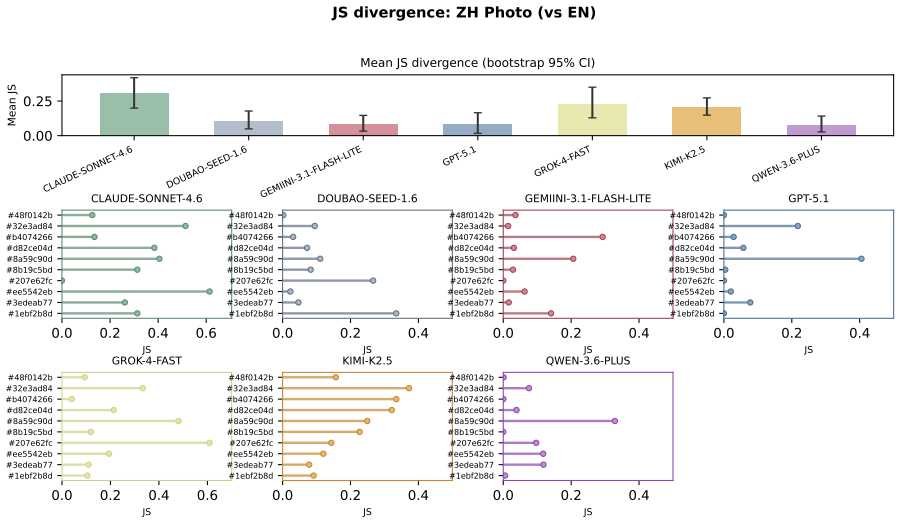
read the original abstract
Current evaluations for Multimodal Large Language Models (MLLMs) overwhelmingly focus on utility-driven objectives, leaving model behavior under logic-neutral scenarios largely underexplored. Stochasticity is essential in scenarios where multiple actions are equally valid, such as recommending travel itineraries or daily schedules where multiple options have similar utility. In such settings, deterministic policies may lead to repetitive behaviors and reduced coverage of valid alternatives. To bridge this gap, we propose RandomBench, a benchmark designed to evaluate whether MLLMs can maintain distributionally neutral behavior when selecting among equivalent options. We further introduce three metrics, including RI, BCI, BII, to quantify entropy and distributional bias. Experiments reveal a pervasive phenomenon termed Stochastic Collapse, where MLLMs fail to maintain uniform randomness under explicit random instructions, with top-1 probabilities reaching 97% from the ideal one quarter baseline and RI dropping to 0.068 in Claude Sonnet 4.6. Extensive ablation studies further demonstrate that these deviations persist across languages and representation formats, highlighting the robustness of distributional collapse in logic-neutral decision settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RandomBench, a benchmark for assessing whether MLLMs maintain distributionally neutral (uniform random) behavior when selecting among options with similar utility under explicit random instructions. It defines three metrics (RI, BCI, BII) to quantify entropy and bias, reports pervasive 'stochastic collapse' with top-1 probabilities reaching 97% (vs. ideal 25% baseline) and RI as low as 0.068 (Claude Sonnet 4.6), and shows the effect persists across languages and input formats via ablation studies.
Significance. If the benchmark options are verifiably equivalent, the work identifies a practically relevant limitation of current MLLMs in logic-neutral decision settings and supplies concrete metrics plus a reusable testbed. The cross-model, cross-language, and cross-format ablations constitute a strength, as does the explicit focus on entropy rather than utility-driven performance.
major comments (1)
- [Abstract and benchmark construction section] Abstract and benchmark construction section: the central claim that observed high top-1 probabilities and low RI constitute 'stochastic collapse' (rather than learned priors) requires that RandomBench options have verifiably identical utility. The manuscript states options have 'similar utility' but supplies no human equivalence ratings, pairwise utility controls, or ablation that rules out frequency/sequence biases acquired during training; without such validation the reported deviations are ambiguous.
minor comments (2)
- [Metrics section] Clarify the exact definition and normalization of RI, BCI, and BII (including any edge-case handling for deterministic outputs) in the metrics section.
- [Experiments section] Add the number of trials per task and per model to the experimental setup so that the reported top-1 probabilities and RI values can be assessed for statistical stability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about verifying option equivalence to support the stochastic collapse claim is substantive, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract and benchmark construction section] Abstract and benchmark construction section: the central claim that observed high top-1 probabilities and low RI constitute 'stochastic collapse' (rather than learned priors) requires that RandomBench options have verifiably identical utility. The manuscript states options have 'similar utility' but supplies no human equivalence ratings, pairwise utility controls, or ablation that rules out frequency/sequence biases acquired during training; without such validation the reported deviations are ambiguous.
Authors: We agree that the manuscript does not supply human equivalence ratings, pairwise utility controls, or a dedicated ablation isolating frequency/sequence biases from training. Options in RandomBench were constructed to be equivalent by design (interchangeable choices under explicit random instructions with no distinguishing utility features), and cross-language/cross-format ablations provide indirect evidence against certain priors. However, these steps do not fully eliminate the ambiguity the referee identifies. We will revise the benchmark construction section to add explicit discussion of this limitation and report a small human study confirming participant-rated equivalence among options. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivation chain or self-referential reductions
full rationale
The paper proposes RandomBench and three metrics (RI, BCI, BII) to measure MLLM behavior under random instructions, then reports experimental results on top-1 probabilities and RI values. No equations, fitted parameters, or derivations are presented that reduce a claimed prediction to its own inputs by construction. The work is a measurement study whose central claims rest on direct observation of model outputs rather than any self-definitional, fitted-input, or self-citation load-bearing step. The assumption that benchmark options have identical utility is a validity concern for interpretation but does not create circularity in any derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Selected tasks present options with identical utility and no model-intrinsic preference ordering.
Forward citations
Cited by 2 Pith papers
-
Contagion Networks: Evaluator Preference Propagation in Multi-Agent LLM Systems
Contagion Networks framework measures evaluator bias propagation in 3-agent LLM systems using the same base model, reporting gamma values of 0.157-0.352 and a 72.4% reduction in contagion when increasing evaluator com...
-
Contagion Networks: Evaluator Preference Propagation in Multi-Agent LLM Systems
Introduces Contagion Networks framework and measures preference propagation in 3-agent LLM setups, finding architectural priors dominate prompts, topology affects spread, and larger committees reduce contagion by ~69%.
Reference graph
Works this paper leans on
-
[1]
, author=
Studies of interference in serial verbal reactions. , author=. Journal of experimental psychology , volume=. 1935 , publisher=
1935
-
[2]
The Role of System 1 and System 2 Semantic Memory Structure in Human and
Abramski, Katherine and Rossetti, Giulio and Stella, Massimo , journal =. The Role of System 1 and System 2 Semantic Memory Structure in Human and
-
[3]
Proceedings of the National Academy of Sciences , volume =
Explicitly unbiased large language models still form biased associations , author =. Proceedings of the National Academy of Sciences , volume =
-
[4]
Advances in Neural Information Processing Systems , volume =
Understanding information storage and transfer in multi-modal large language models , author =. Advances in Neural Information Processing Systems , volume =
-
[5]
Nature Reviews Psychology , volume =
Dual-process theory and decision-making in large language models , author =. Nature Reviews Psychology , volume =
-
[6]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
Quantifying and mitigating unimodal biases in multimodal large language models: A causal perspective , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
2024
-
[7]
Preprints.org , doi =
A Survey on Selection Bias in Large Language Models , author =. Preprints.org , doi =
-
[8]
Huang, Jen-tse and Qin, Jiaxu and Zhang, Jing and others , booktitle =
-
[9]
Li, Yuchen and Fan, Zhen and Chen, Ruizhe and others , booktitle =
-
[10]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Language model probabilities are not calibrated in numeric contexts , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
-
[11]
Advances in Neural Information Processing Systems , volume =
Order-Independence Without Fine Tuning , author =. Advances in Neural Information Processing Systems , volume =
-
[12]
Locating and editing factual associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and editing factual associations in
-
[13]
Sivakumar, Ashwin and Zhang, Allen and Hakim, Zaid and others , booktitle =
-
[14]
Advances in Neural Information Processing Systems , volume =
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author =. Advances in Neural Information Processing Systems , volume =
-
[15]
2026 , pages =
Wang, Sibo and Cao, Xiangkui and Zhang, Jie and Yuan, Zheng and Shan, Shiguang and Chen, Xilin and Gao, Wen , journal =. 2026 , pages =
2026
-
[16]
Wang, Jingyi and Li, Ming and Zhang, Hao and others , journal =
-
[17]
Ye, Wenqian and Liu, Bo and Zheng, Guangtao and others , booktitle =
-
[18]
When Modalities Conflict: How Unimodal Reasoning Uncertainty Governs Preference Dynamics in
Zhang, Zhuoran and Wang, Tengyue and Gong, Xilin and Shi, Yang and Wang, Haotian and Wang, Di and Hu, Lijie , journal =. When Modalities Conflict: How Unimodal Reasoning Uncertainty Governs Preference Dynamics in
-
[19]
Proceedings of the 38th International Conference on Machine Learning , pages =
Calibrate Before Use: Improving Few-shot Performance of Language Models , author =. Proceedings of the 38th International Conference on Machine Learning , pages =
-
[20]
Proceedings of the International Conference on Learning Representations , year =
Large language models are not robust multiple choice selectors , author =. Proceedings of the International Conference on Learning Representations , year =
-
[21]
Mitigating Selection Bias in Large Language Models via Permutation-Aware
Zheng, Jinquan and Yuan, Jia and Yao, Jiacheng and Gu, Chenyang and Zheng, Pujun and He, Guoxiu , booktitle =. Mitigating Selection Bias in Large Language Models via Permutation-Aware. 2026 , note =
2026
-
[22]
2025 , howpublished =
2025
-
[23]
2026 , howpublished =
Claude Sonnet 4.6: Hybrid Reasoning Model , author =. 2026 , howpublished =
2026
-
[24]
2025 , howpublished =
Gemini 3.1 Flash-Lite: Built for Intelligence at Scale , author =. 2025 , howpublished =
2025
-
[26]
2026 , howpublished =
2026
-
[27]
2025 , howpublished =
Grok 4 Fast: Cost-Efficient Reasoning at Scale , author =. 2025 , howpublished =
2025
-
[28]
2025 , howpublished =
Introduction to Techniques Used in. 2025 , howpublished =
2025
-
[29]
2020 , eprint=
StereoSet: Measuring stereotypical bias in pretrained language models , author=. 2020 , eprint=
2020
-
[30]
2024 , eprint=
Measuring Implicit Bias in Explicitly Unbiased Large Language Models , author=. 2024 , eprint=
2024
-
[31]
2025 , eprint=
Modality Bias in LVLMs: Analyzing and Mitigating Object Hallucination via Attention Lens , author=. 2025 , eprint=
2025
-
[32]
2026 , eprint=
Analyzing Reasoning Consistency in Large Multimodal Models under Cross-Modal Conflicts , author=. 2026 , eprint=
2026
-
[33]
2026 , eprint=
When Seeing Overrides Knowing: Disentangling Knowledge Conflicts in Vision-Language Models , author=. 2026 , eprint=
2026
-
[37]
2018 , eprint=
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor , author=. 2018 , eprint=
2018
-
[38]
2025 , eprint=
Agent Lightning: Train ANY AI Agents with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[39]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Governance in Motion: Co-evolution of Constitutions and AI models for Scalable Safety , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[40]
2025 , eprint=
Distributionally Robust Graph Out-of-Distribution Recommendation via Diffusion Model , author=. 2025 , eprint=
2025
-
[41]
2024 , eprint=
Fairness and Diversity in Recommender Systems: A Survey , author=. 2024 , eprint=
2024
-
[43]
Findings of the association for computational linguistics: ACL 2022 , pages=
Chartqa: A benchmark for question answering about charts with visual and logical reasoning , author=. Findings of the association for computational linguistics: ACL 2022 , pages=
2022
-
[44]
Shannon, C. E. , journal=. A mathematical theory of communication , year=
-
[45]
Katherine Abramski, Giulio Rossetti, and Massimo Stella. 2026. The role of system 1 and system 2 semantic memory structure in human and LLM biases. arXiv preprint arXiv:2604.12816
Pith/arXiv arXiv 2026
-
[46]
Alibaba Cloud . 2026. Qwen 3.6 technical blog. https://qwen.ai/blog?id=qwen3.6. Accessed: 2026-05-24
2026
-
[47]
Anthropic . 2026. Claude sonnet 4.6: Hybrid reasoning model. https://www.anthropic.com/claude/sonnet. Accessed: 2026-05-24
2026
- [48]
-
[49]
Griffiths
Xuechunzi Bai, Angelina Wang, Ilia Sucholutsky, and Thomas L. Griffiths. 2025. Explicitly unbiased large language models still form biased associations. Proceedings of the National Academy of Sciences, 122(8):e2416228122
2025
-
[50]
Samyadeep Basu, Michael Grayson, Cecily Morrison, and 1 others. 2024. Understanding information storage and transfer in multi-modal large language models. In Advances in Neural Information Processing Systems, volume 37, pages 7400--7426
2024
-
[51]
Ward, and David P
Oliver Brady, Paul Nulty, Li Zhang, Tomas E. Ward, and David P. McGovern. 2025. Dual-process theory and decision-making in large language models. Nature Reviews Psychology, 4:777--792
2025
-
[52]
ByteDance Seed Team . 2025. Introduction to techniques used in Seed1.6 . https://seed.bytedance.com/en/blog/introduction-to-techniques-used-in-seed1-6. Accessed: 2026-05-24
2025
-
[53]
Meiqi Chen, Yixin Cao, Yan Zhang, and 1 others. 2024. Quantifying and mitigating unimodal biases in multimodal large language models: A causal perspective. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16449--16469
2024
-
[54]
Google DeepMind . 2025. Gemini 3.1 flash-lite: Built for intelligence at scale. https://blog.google/technology/ai/gemini-3-1-flash-lite/. Accessed: 2026-05-24
2025
-
[55]
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. 2018. https://arxiv.org/abs/1801.01290 Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor . Preprint, arXiv:1801.01290
Pith/arXiv arXiv 2018
-
[56]
Guoxiu He, Jinquan Zheng, and Fangqing Han. 2026. https://doi.org/10.20944/preprints202604.2234.v1 A survey on selection bias in large language models . Preprints.org
-
[57]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300
Pith/arXiv arXiv 2020
-
[58]
Chenhao Huang, Ziyu Shen, Yicong Ren, Huiyuan Zheng, Jiazheng Zhang, Mingxu Chai, Ming Zhang, Shihan Dou, Fan Mo, Jie Shi, and 1 others. 2025 a . Governance in motion: Co-evolution of constitutions and ai models for scalable safety. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17198--17221
2025
-
[59]
Jen-tse Huang, Jiaxu Qin, Jing Zhang, and 1 others. 2025 b . VisBias : Measuring explicit and implicit social biases in vision-language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17981--18004
2025
-
[60]
Kimi Team . 2026. https://arxiv.org/abs/2602.02276 Kimi k2.5: Visual agentic intelligence . arXiv preprint arXiv:2602.02276
Pith/arXiv arXiv 2026
-
[61]
Yuchen Li, Zhen Fan, Ruizhe Chen, and 1 others. 2025. FairSteer : Inference time debiasing for LLMs with dynamic activation steering. In Findings of the Association for Computational Linguistics: ACL 2025, pages 11293--11312
2025
-
[62]
Charles Lovering, Michael Krumdick, Viet Dac Lai, Nilesh Reddy, and Greg Durrett. 2025. Language model probabilities are not calibrated in numeric contexts. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29218--29257
2025
-
[63]
Xufang Luo, Yuge Zhang, Zhiyuan He, Zilong Wang, Siyun Zhao, Dongsheng Li, Luna K. Qiu, and Yuqing Yang. 2025. https://arxiv.org/abs/2508.03680 Agent lightning: Train any ai agents with reinforcement learning . Preprint, arXiv:2508.03680
arXiv 2025
-
[64]
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. 2022. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In Findings of the association for computational linguistics: ACL 2022, pages 2263--2279
2022
-
[65]
Reid McIlroy-Young, Katrina Brown, Conlan Olson, Linjun Zhang, and Cynthia Dwork. 2024. Order-independence without fine tuning. In Advances in Neural Information Processing Systems, volume 37, pages 72818--72839
2024
-
[66]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems, volume 35, pages 17359--17372
2022
-
[67]
Moin Nadeem, Anna Bethke, and Siva Reddy. 2020. https://arxiv.org/abs/2004.09456 Stereoset: Measuring stereotypical bias in pretrained language models . Preprint, arXiv:2004.09456
arXiv 2020
-
[68]
OpenAI . 2025. GPT -5.1: Next-generation model for developers. https://openai.com/index/gpt-5-1-for-developers/. Accessed: 2026-05-24
2025
-
[69]
Francesco Ortu, Zhijing Jin, Diego Doimo, and Alberto Cazzaniga. 2026. https://arxiv.org/abs/2507.13868 When seeing overrides knowing: Disentangling knowledge conflicts in vision-language models . Preprint, arXiv:2507.13868
Pith/arXiv arXiv 2026
-
[70]
C. E. Shannon. 1948. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x A mathematical theory of communication . The Bell System Technical Journal, 27(3):379--423
-
[71]
Ashwin Sivakumar, Allen Zhang, Zaid Hakim, and 1 others. 2025. SteerVLM : Robust model control through lightweight activation steering for vision language models. In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23640--23665
2025
-
[72]
J Ridley Stroop. 1935. Studies of interference in serial verbal reactions. Journal of experimental psychology, 18(6):643
1935
-
[73]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. In Advances in Neural Information Processing Systems, volume 36, pages 74952--74965
2023
-
[74]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291
Pith/arXiv arXiv 2023
-
[75]
Jingyi Wang, Ming Li, Hao Zhang, and 1 others. 2026 a . V-FAT : Benchmarking visual fidelity against text-bias. arXiv preprint arXiv:2601.04897
arXiv 2026
-
[76]
Sibo Wang, Xiangkui Cao, Jie Zhang, Zheng Yuan, Shiguang Shan, Xilin Chen, and Wen Gao. 2026 b . https://doi.org/10.1109/TPAMI.2026.3683747 VLBiasBench : A comprehensive benchmark for evaluating bias in large vision-language model . IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1--14
-
[77]
xAI . 2025. Grok 4 fast: Cost-efficient reasoning at scale. https://x.ai/news/grok-4-fast. Accessed: 2026-05-24
2025
-
[78]
Hui Yang, Sifu Yue, and Yunzhong He. 2023. Auto-gpt for online decision making: Benchmarks and additional opinions. arXiv preprint arXiv:2306.02224
arXiv 2023
-
[79]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629
Pith/arXiv arXiv 2022
-
[80]
Wenqian Ye, Bo Liu, Guangtao Zheng, and 1 others. 2024. MM-SpuBench : Towards better understanding of spurious biases in multimodal LLMs . In Advances in Neural Information Processing Systems, volume 37
2024
-
[81]
Zhuoran Zhang, Tengyue Wang, Xilin Gong, Yang Shi, Haotian Wang, Di Wang, and Lijie Hu. 2025. When modalities conflict: How unimodal reasoning uncertainty governs preference dynamics in MLLMs . arXiv preprint arXiv:2511.02243
arXiv 2025
-
[82]
Chu Zhao, Enneng Yang, Yuliang Liang, Jianzhe Zhao, Guibing Guo, and Xingwei Wang. 2025. https://arxiv.org/abs/2501.15555 Distributionally robust graph out-of-distribution recommendation via diffusion model . Preprint, arXiv:2501.15555
arXiv 2025
-
[83]
Yuying Zhao, Yu Wang, Yunchao Liu, Xueqi Cheng, Charu Aggarwal, and Tyler Derr. 2024. https://arxiv.org/abs/2307.04644 Fairness and diversity in recommender systems: A survey . Preprint, arXiv:2307.04644
arXiv 2024
-
[84]
Zihao Zhao, Eric Wallace, Shi Feng, Dan Klein, and Sameer Singh. 2021. Calibrate before use: Improving few-shot performance of language models. In Proceedings of the 38th International Conference on Machine Learning, pages 12697--12706
2021
-
[85]
Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. 2024. Large language models are not robust multiple choice selectors. In Proceedings of the International Conference on Learning Representations
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.