Learning Emotion-discriminative Representations for Zero-Shot Cross-lingual Speech Emotion Recognition
Pith reviewed 2026-06-27 23:36 UTC · model grok-4.3
The pith
Supervised contrastive learning plus speaker adversarial learning produces emotion-discriminative representations that improve zero-shot cross-lingual speech emotion recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
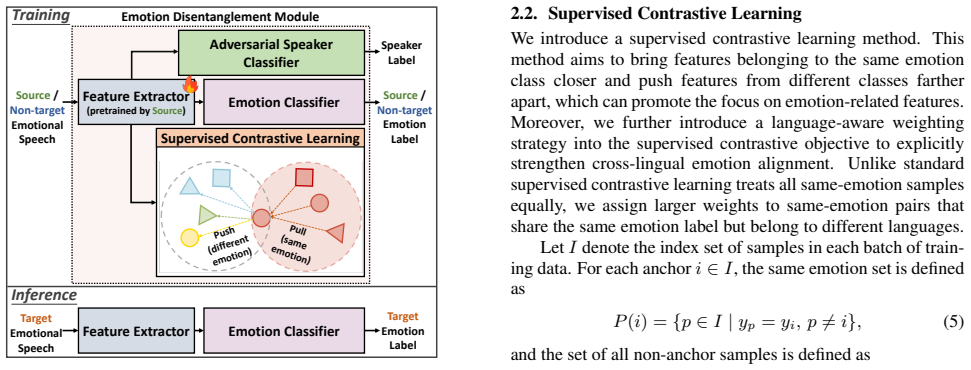
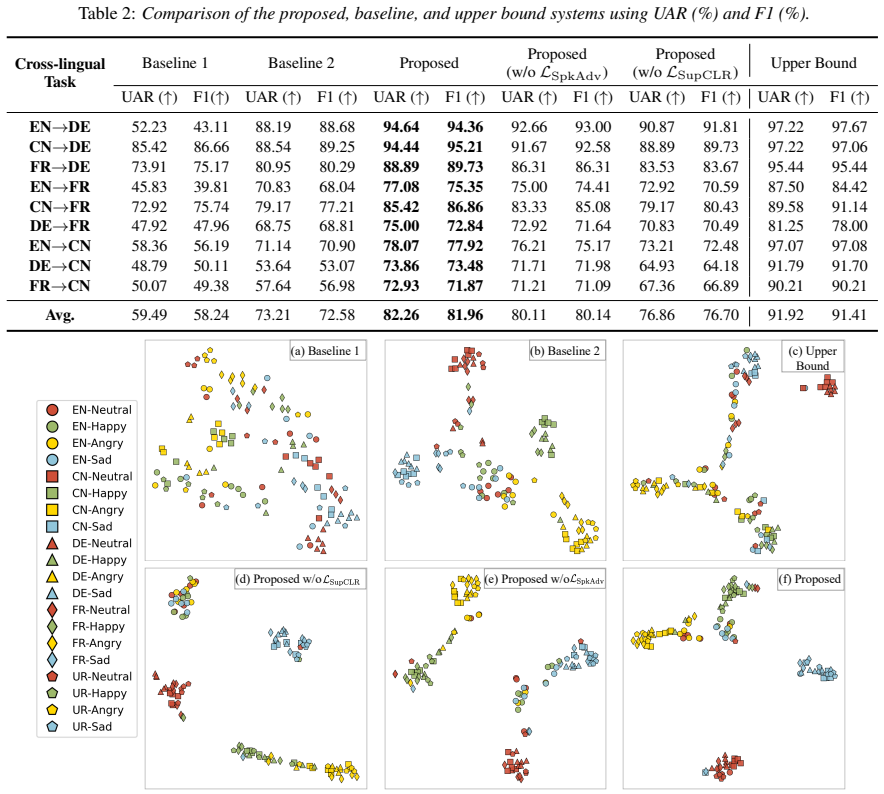
The central claim is that jointly applying supervised contrastive learning to align emotion classes across languages and speaker adversarial learning to suppress speaker-related information yields representations that remain discriminative for emotions yet generalize to target languages with no emotion annotations, and that this combination measurably outperforms conventional training strategies under zero-shot cross-lingual evaluation.
What carries the argument
The joint objective of supervised contrastive loss for emotion alignment and adversarial loss for speaker invariance, applied during training on source-language data only.
If this is right
- Models trained this way require no emotion labels in the target language yet still recognize emotions at higher accuracy than models trained without the two losses.
- Speaker-invariant features reduce the impact of speaker variation when the test language differs from the training language.
- Cross-lingual emotion alignment becomes possible through contrastive pairing of same-emotion utterances from different languages.
- The method can be applied on top of any existing speech encoder without changing its architecture.
Where Pith is reading between the lines
- The same combination of losses could be tried on other paralinguistic tasks such as speaker verification or language identification where domain shift is an issue.
- Performance might improve further if the contrastive pairs were augmented with synthetic cross-lingual translations of utterances.
- If the adversarial component is too strong it could erase useful prosodic cues that carry emotion; a tunable balance between the two losses would be worth measuring.
Load-bearing premise
That the contrastive term will succeed in aligning emotion clusters across languages and the adversarial term will remove speaker cues that otherwise hurt transfer, even without any target-language emotion labels.
What would settle it
A replication experiment on the same language pairs that shows no accuracy gain, or a drop, when the two losses are added compared with plain supervised training.
Figures
read the original abstract
Zero-shot cross-lingual speech emotion recognition (SER) remains challenging due to distribution mismatches across languages and the lack of emotion annotations in target language. Under such conditions, models trained solely on source-language data frequently suffer from degraded generalization when evaluated on unseen target languages. To address this limitation, we propose an emotion-discriminative representation learning method that integrates supervised contrastive learning and speaker adversarial learning. The contrastive learning promotes cross-lingual emotion alignment, while speaker adversarial learning suppresses speaker-related cues to encourage speaker-invariant representations. Experimental results under a zero-shot cross-lingual SER setting demonstrate that the proposed method significantly improves SER performance over conventional training strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an emotion-discriminative representation learning method for zero-shot cross-lingual speech emotion recognition that combines supervised contrastive learning (to align emotion representations across languages) with speaker adversarial learning (to produce speaker-invariant features). It evaluates the approach under a standard zero-shot protocol (source-only training, target-only evaluation) and claims consistent performance gains over conventional strategies across multiple language pairs.
Significance. If the empirical gains are reproducible, the work provides a practical way to mitigate language and speaker mismatches in SER without target-language annotations. Credit is due for employing standard dataset splits and reporting improvements that are consistent rather than isolated to a single pair.
minor comments (1)
- [Abstract] Abstract: the claim of 'significant improvement' is stated without any numerical results, baselines, or dataset identifiers, which is a presentation issue that makes the central empirical claim harder to assess at first reading.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The report contains no specific major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical ML method (supervised contrastive loss + speaker-adversarial training) evaluated on standard source-only training / target-only zero-shot splits across language pairs. No equations, derivations, or parameter-fitting steps appear in the abstract or method description that reduce a claimed prediction to its own inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing justification. The result is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speech Emotion Recognition (SER) has received increasing at- tention in affective computing over the past two decades [1] owing to its potential applications in healthcare [2, 3], educa- tion [4, 5], and robotics [6, 7]. SER aims to identify human emotional states by extracting emotional features from speech. Research on SER systems has shown...
Pith/arXiv arXiv 2026
-
[2]
Note thatDtarget is not used during training
Methodology LetD source denote the labeled emotional speech data of the source language,D non-target the union of labeled emotional speech data from auxiliary non-target languages, andD target the emotional speech data in the target language. Note thatDtarget is not used during training. The overall training data is defined as D=D source ∪ Dnon-target.(1)...
-
[3]
#Samples
Experimental Evaluations 3.1. Datasets and Evaluation Metrics For clarity, we useEN,CN,DE,FR,URto denote English, Mandarin, German, French, and Urdu, respectively. We design nine zero-shot cross-lingual settings. In each setting, one lan- guage is selected as the source and another as the target, while the rest serve as non-target languages. The configura...
-
[4]
Exten- sive experiments under nine zero-shot cross-lingual settings demonstrate that the proposed systems significantly outperform baseline systems
Conclusion In this paper, we propose an emotion-discriminative represen- tation learning method that effectively integrates supervised contrastive learning and speaker adversarial learning. Exten- sive experiments under nine zero-shot cross-lingual settings demonstrate that the proposed systems significantly outperform baseline systems. Visualization evid...
-
[5]
THERS Make New Standards Program for the Next Generation Researchers
Acknowledgments This work was partly supported by JST CREST Grant Number JPMJCR22D1 and JSPS KAKENHI Grant Number 26H02530, Japan. In addition, this work was also financially supported by JST SPRING, Grant Number JPMJSP2125. The author would like to take this opportunity to thank the “THERS Make New Standards Program for the Next Generation Researchers.”
-
[6]
Generative AI Use Disclosure Generative AI tools were used for grammar correction
-
[7]
Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends,
B. W. Schuller, “Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends,”Communications of the ACM, vol. 61, no. 5, pp. 90–99, 2018
2018
-
[8]
Emotion recognition us- ing speech and neural structured learning to facilitate edge in- telligence,
M. Z. Uddin and E. G. Nilsson, “Emotion recognition us- ing speech and neural structured learning to facilitate edge in- telligence,”Engineering Applications of Artificial Intelligence, vol. 94, p. 103775, 2020
2020
-
[9]
Cloud-assisted speech and face recognition framework for health monitoring,
M. S. Hossain and G. Muhammad, “Cloud-assisted speech and face recognition framework for health monitoring,”Mobile Net- works and Applications, vol. 20, pp. 391–399, 2015
2015
-
[10]
Speech emotion recognition in e- learning system based on affective computing,
W. Li, Y . Zhang, and Y . Fu, “Speech emotion recognition in e- learning system based on affective computing,” inICNC, vol. 5, 2007, pp. 809–813
2007
-
[11]
Emotional recognition from the speech signal for a virtual education agent,
A. Tickle, S. Raghu, and M. Elshaw, “Emotional recognition from the speech signal for a virtual education agent,” inJournal of Physics: Conference Series, vol. 450, no. 1, 2013, p. 012053
2013
-
[12]
Towards speech emotion recognition applied to social robots,
A. Gamboa, I. Dongo, A. Aguilera, and R. Begazo, “Towards speech emotion recognition applied to social robots,” inCLEI, 2024, pp. 1–10
2024
-
[13]
Speech emotion recognition in real static and dynamic human-robot interaction scenarios,
N. Gr ´ageda, C. Busso, E. Alvarado, R. Garc ´ıa, R. Mahu, F. Huenupan, and N. B. Yoma, “Speech emotion recognition in real static and dynamic human-robot interaction scenarios,”Com- puter Speech and Language, vol. 89, p. 101666, 2025
2025
-
[14]
Two- stage framework for robust speech emotion recognition using tar- get speaker extraction in human speech noise conditions,
J. Mi, X. Shi, D. Ma, J. He, T. Fujimura, and T. Toda, “Two- stage framework for robust speech emotion recognition using tar- get speaker extraction in human speech noise conditions,” inAP- SIPA ASC, 2024, pp. 1–6
2024
-
[15]
Exploring wav2vec 2.0 fine tuning for improved speech emotion recognition,
L. W. Chen and A. Rudnicky, “Exploring wav2vec 2.0 fine tuning for improved speech emotion recognition,” inICASSP, 2023, pp. 1–5
2023
-
[16]
Robust speech emotion recognition under human speech noise,
J. Mi, X. Shi, D. Ma, J. He, T. Fujimura, and T. Toda, “Robust speech emotion recognition under human speech noise,”Com- puter Speech and Language, vol. 100, p. 101987, 2026
2026
-
[17]
Cross corpus speech emotion classification-an effective transfer learning tech- nique,
S. Latif, R. Rana, S. Younis, J. Qadir, and J. Epps, “Cross corpus speech emotion classification-an effective transfer learning tech- nique,”arXiv preprint arXiv:1801.06353, 2018
arXiv 2018
-
[18]
Cross-lingual and multilingual speech emotion recognition on English and French,
M. Neumann and N. g. Thang Vu, “Cross-lingual and multilingual speech emotion recognition on English and French,” inICASSP, 2018, pp. 5769–5773
2018
-
[19]
Cross-corpus speech emotion recognition based on few-shot learning and domain adaptation,
Y . Ahn, S. J. Lee, and J. W. Shin, “Cross-corpus speech emotion recognition based on few-shot learning and domain adaptation,” IEEE Signal Processing Letters, vol. 28, pp. 1190–1194, 2021
2021
-
[20]
Cross-lingual speech emotion recognition: Humans vs. self- supervised models,
Z. Han, T. Geng, H. Feng, J. Yuan, K. Richmond, and Y . Li, “Cross-lingual speech emotion recognition: Humans vs. self- supervised models,” inICASSP, 2025, pp. 1–5
2025
-
[21]
wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech repre- sentations,”Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[22]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[23]
Unsupervised adversarial domain adaptation for cross-lingual speech emotion recognition,
S. Latif, J. Qadir, and M. Bilal, “Unsupervised adversarial domain adaptation for cross-lingual speech emotion recognition,” inACII, 2019, pp. 732–737
2019
-
[24]
Generative adver- sarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adver- sarial nets,”Advances in neural information processing systems, vol. 27, 2014
2014
-
[25]
Unsu- pervised cross-lingual speech emotion recognition using domain adversarial neural network,
X. Cai, Z. Wu, K. Zhong, B. Su, D. Dai, and H. Meng, “Unsu- pervised cross-lingual speech emotion recognition using domain adversarial neural network,” inISCSLP, 2021, pp. 1–5
2021
-
[26]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. March, and V . Lempitsky, “Domain-adversarial training of neural networks,”Journal of machine learning re- search, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[27]
A layer-anchoring strategy for enhancing cross-lingual speech emotion recognition,
S. G. Upadhyay, C. Busso, and C.-C. Lee, “A layer-anchoring strategy for enhancing cross-lingual speech emotion recognition,” inInterspeech, 2024, pp. 4693–4697
2024
-
[28]
D. Tang, P. Kuppens, L. Geurts, and T. van Waterschoot, “End- to-end transfer learning for speaker-independent cross-language and cross-corpus speech emotion recognition,”arXiv preprint arXiv:2311.13678, 2023
arXiv 2023
-
[29]
MELD: A multimodal multi-party dataset for emo- tion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “MELD: A multimodal multi-party dataset for emo- tion recognition in conversations,” inACL, 2019, pp. 527–536
2019
-
[30]
Emotional voice conver- sion: Theory, databases and ESD,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Emotional voice conver- sion: Theory, databases and ESD,”Speech Communication, vol. 137, pp. 1–18, 2022
2022
-
[31]
A database of German emotional speech,
F. Burkhardt, A. Paeschke, M. Rolfes, W. F. Sendlmeier, and B. Weiss, “A database of German emotional speech,” inInter- speech, 2005, pp. 1517–1520
2005
-
[32]
A Canadian French emo- tional speech dataset,
P. Gournay, O. Lahaie, and R. Lefebvre, “A Canadian French emo- tional speech dataset,” inACM MMSys, 2018, pp. 399–402
2018
-
[33]
Cross lingual speech emotion recognition: Urdu vs. western languages,
S. Latif, A. Qayyum, M. Usman, and J. Qadir, “Cross lingual speech emotion recognition: Urdu vs. western languages,” inFIT, 2018, pp. 88–93
2018
-
[34]
A study on multimodal fusion and layer adapter in emotion recognition,
X. Shi, Y . Gao, J. He, J. Mi, X. Li, and T. Toda, “A study on multimodal fusion and layer adapter in emotion recognition,” in APSIPA ASC, 2024, pp. 1–6
2024
-
[35]
LoRA: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “LoRA: Low-rank adaptation of large language models.”ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[36]
Parameter-efficient transfer learning for NLP,
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. De Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly, “Parameter-efficient transfer learning for NLP,” inInternational conference on machine learning. PMLR, 2019, pp. 2790–2799
2019
-
[37]
Parame- ter efficient finetuning for speech emotion recognition and domain adaptation,
N. Lashkarashvili, W. Wu, G. Sun, and P. C. Woodland, “Parame- ter efficient finetuning for speech emotion recognition and domain adaptation,” inICASSP, 2024, pp. 10 986–10 990
2024
-
[38]
Visualizing data using t-SNE
L. Van der Maaten and G. Hinton, “Visualizing data using t-SNE.” Journal of machine learning research, vol. 9, no. 11, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.