A Geometric Account of Activation Steering through Angle-Norm Decomposition
Pith reviewed 2026-06-28 00:48 UTC · model grok-4.3
The pith
Steering in language models mainly changes angular alignment with concepts while norm affects stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
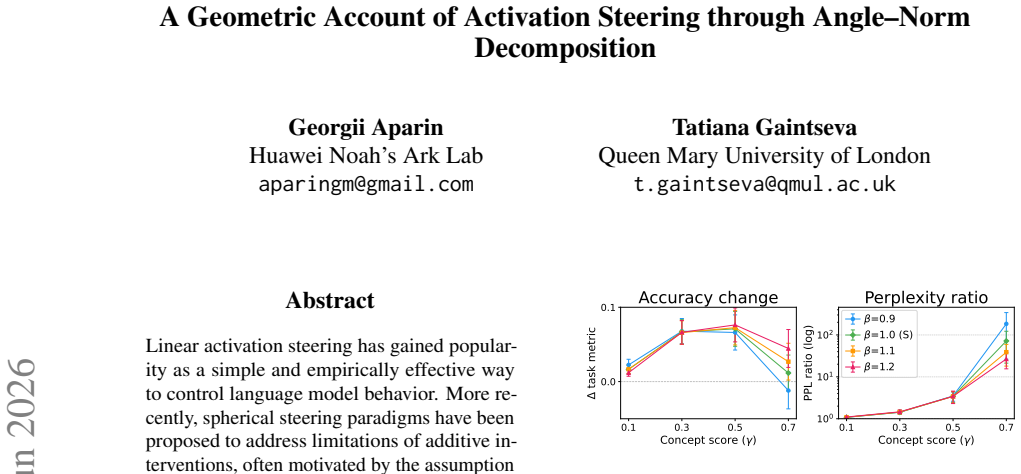
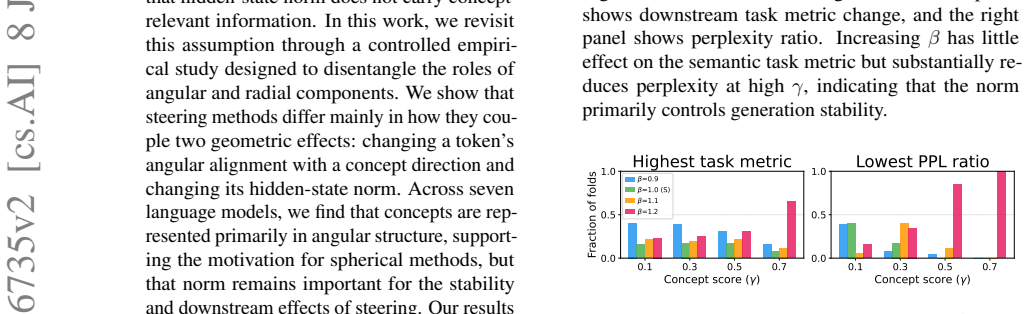
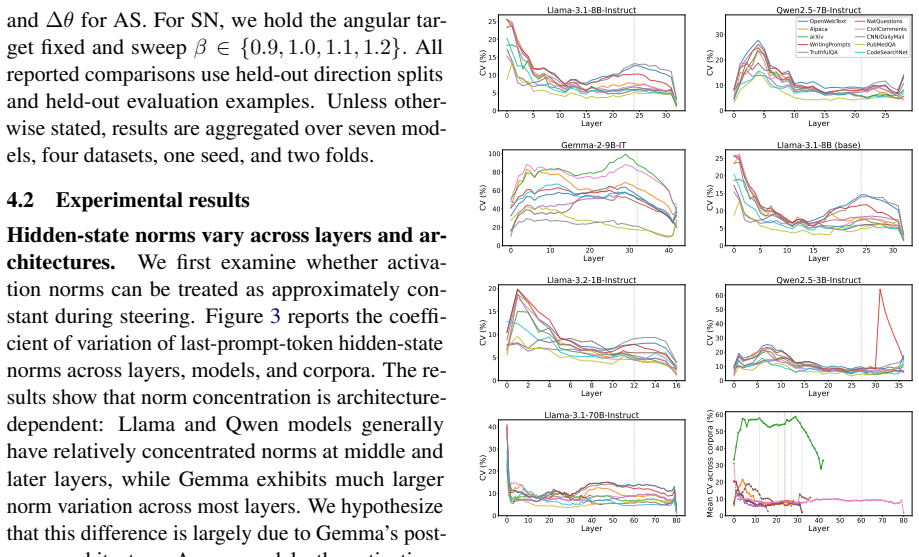
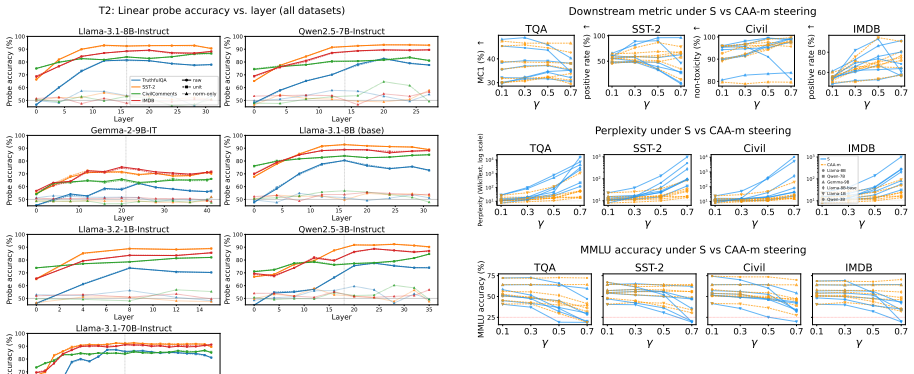
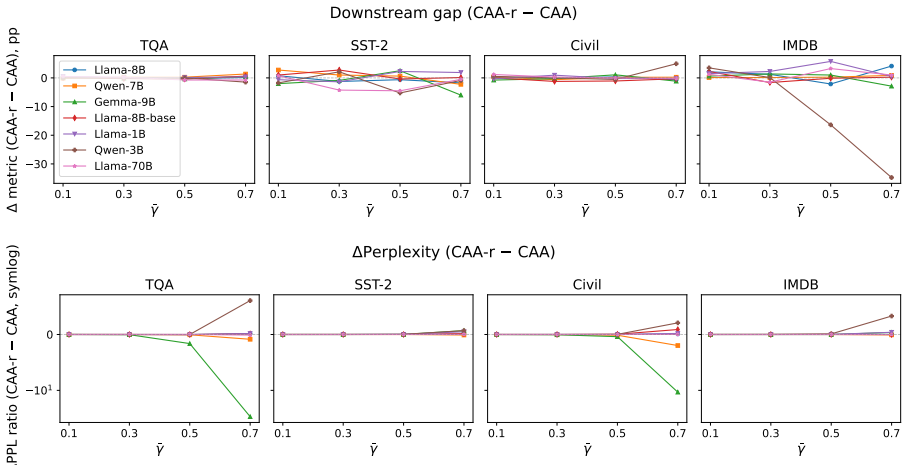
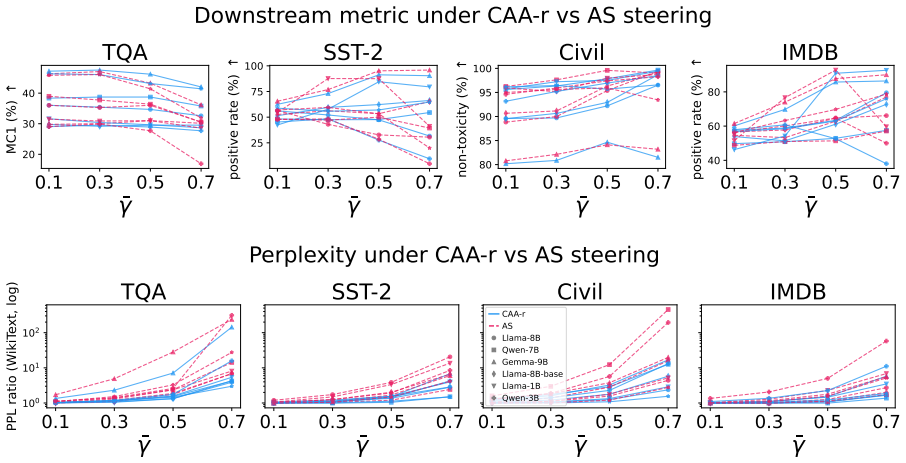
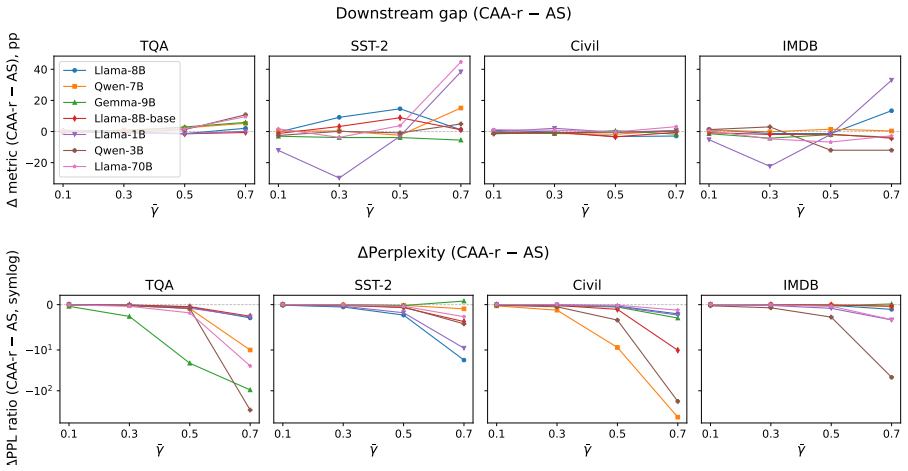
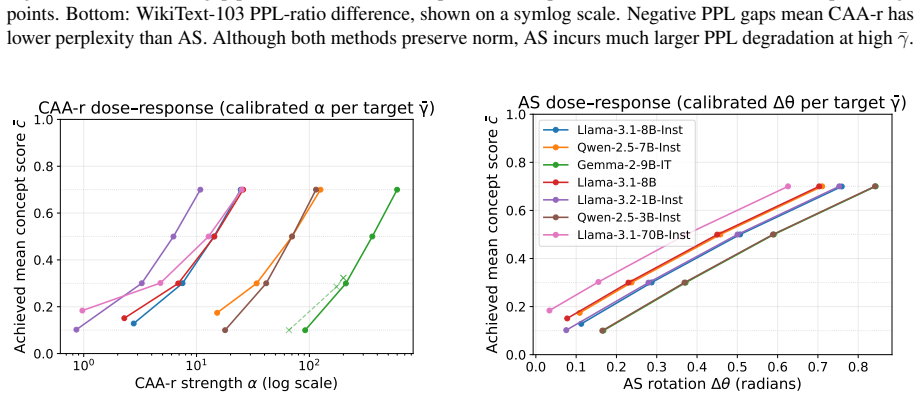
Steering methods differ mainly in how they couple two geometric effects: changing a token's angular alignment with a concept direction and changing its hidden-state norm. Across seven language models, concepts are represented primarily in angular structure, supporting the motivation for spherical methods, but that norm remains important for the stability and downstream effects of steering. Results explain why interventions with similar concept-level effects can behave differently and suggest parameterizing steering by interpretable angular and radial components rather than a single additive coefficient.
What carries the argument
Angle-norm decomposition of hidden states, separating angular alignment from vector magnitude to analyze how each contributes to steering outcomes.
If this is right
- Interventions with matched concept effects can still differ in stability because of how they alter norm.
- Steering should be designed with separate angular and radial parameters for clearer control.
- Linear methods entangle angle and norm through one coefficient, producing side effects not seen in norm-preserving approaches.
- Spherical methods gain from preserving norm but must still account for its downstream role.
Where Pith is reading between the lines
- Independent tuning of angle for concept strength and norm for output quality could yield more reliable edits.
- The same decomposition may apply to interventions in vision or multimodal models.
- Extending the analysis to generation length or multi-step reasoning tasks would test whether norm effects grow with output complexity.
Load-bearing premise
The controlled empirical study successfully separates angular and radial components without interference from model architecture or intervention details.
What would settle it
A test in which norm is held fixed while angle is varied shows that differences between linear and spherical steering disappear or that concept effects fail to appear.
Figures
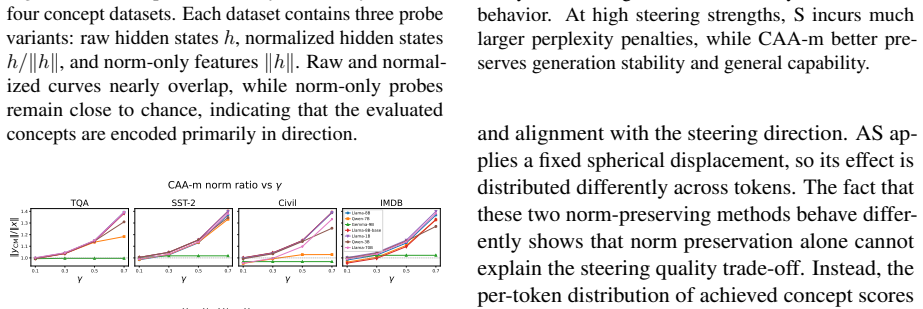
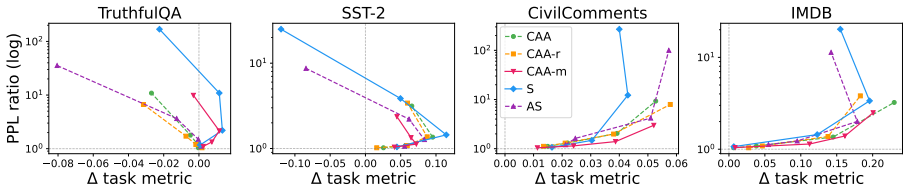
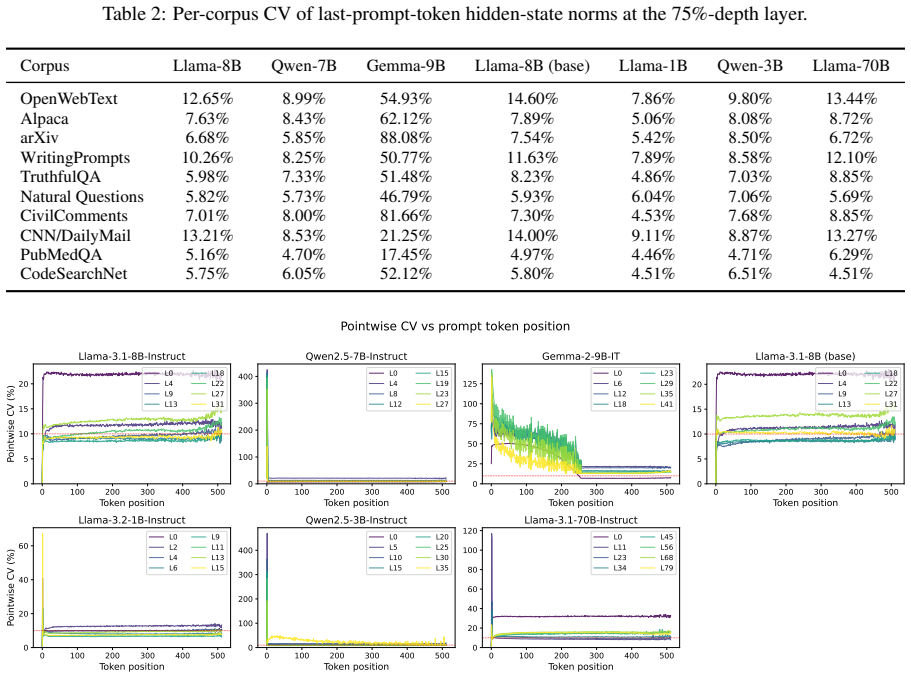
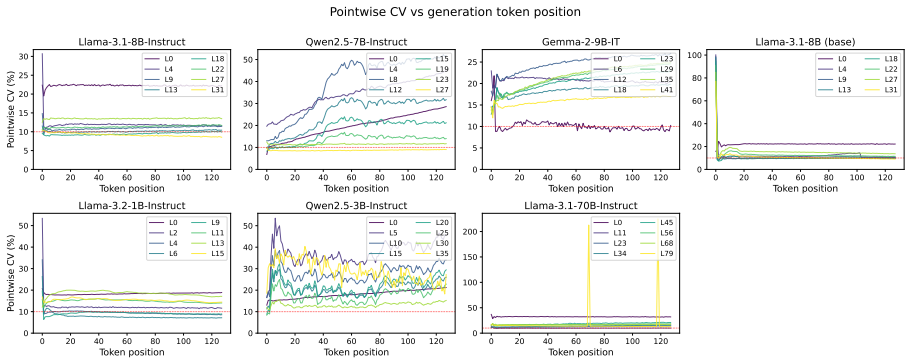
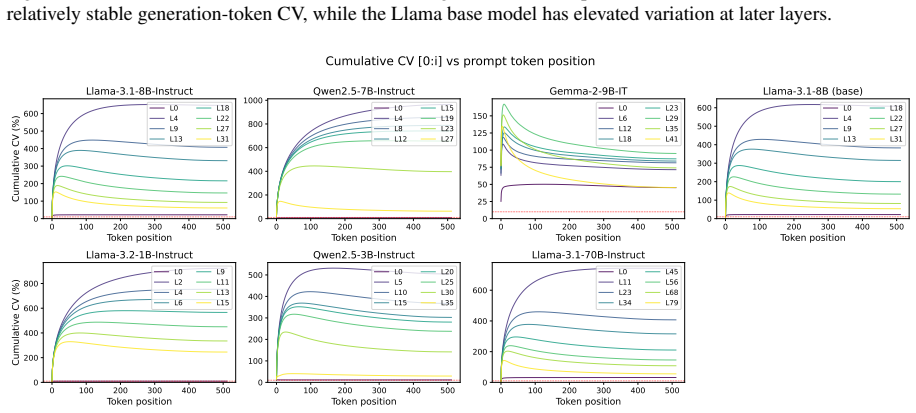
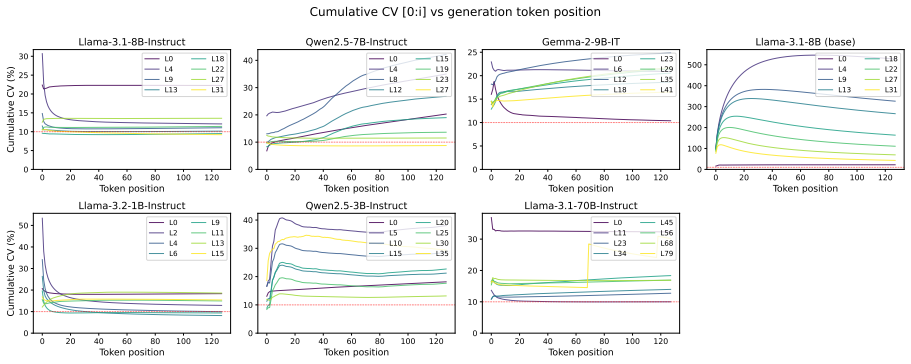
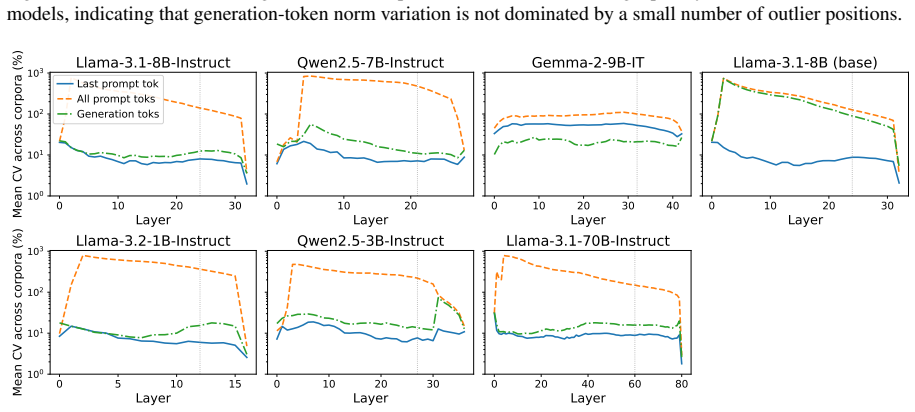
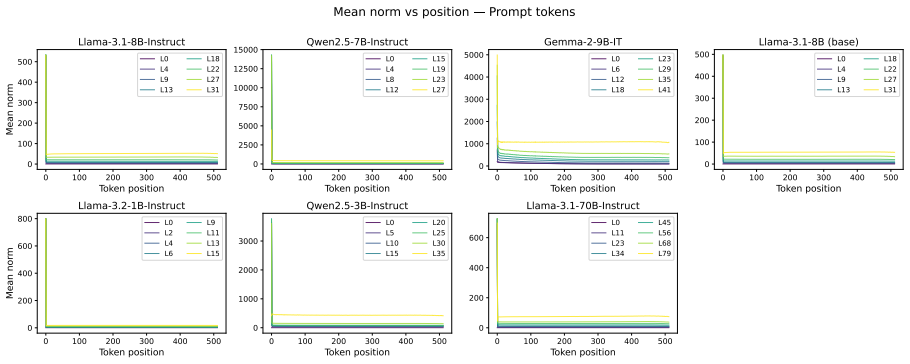
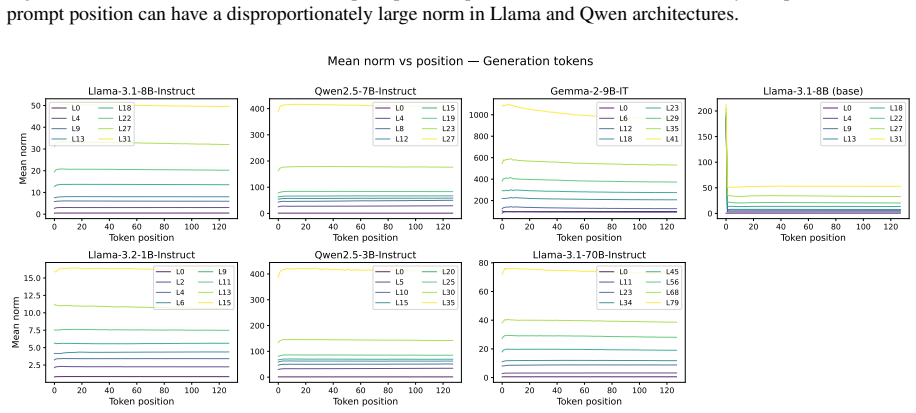
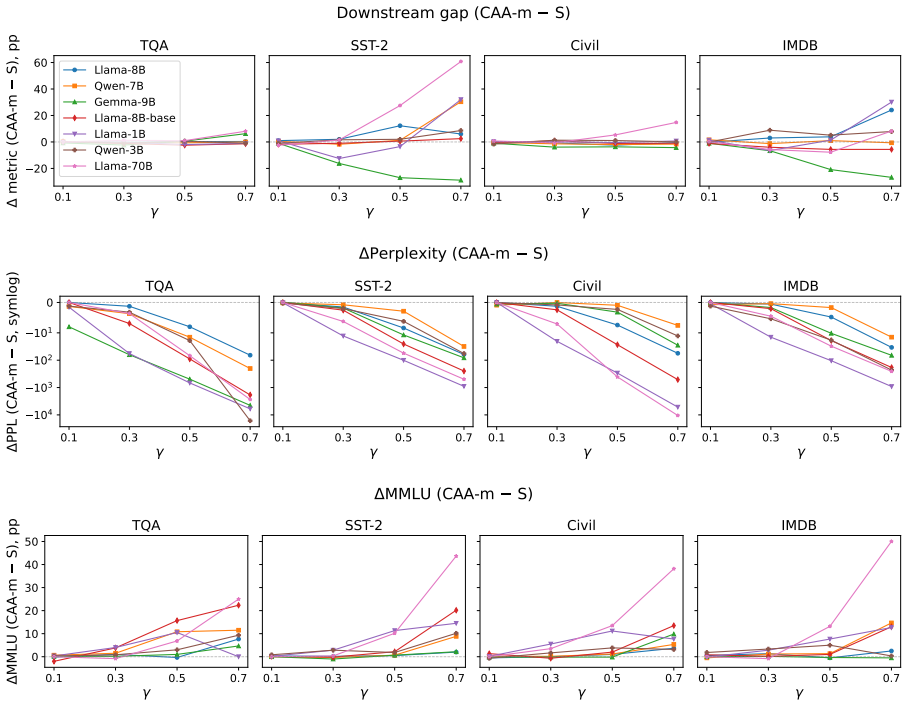
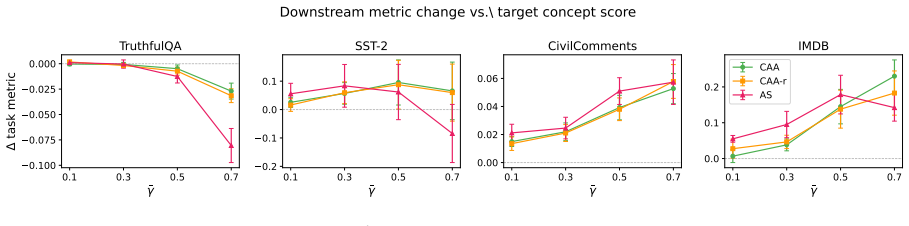
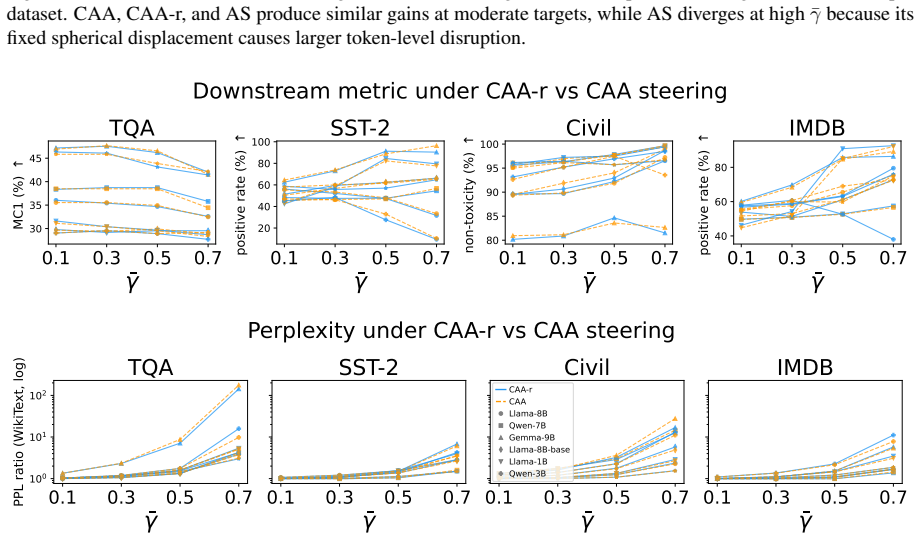
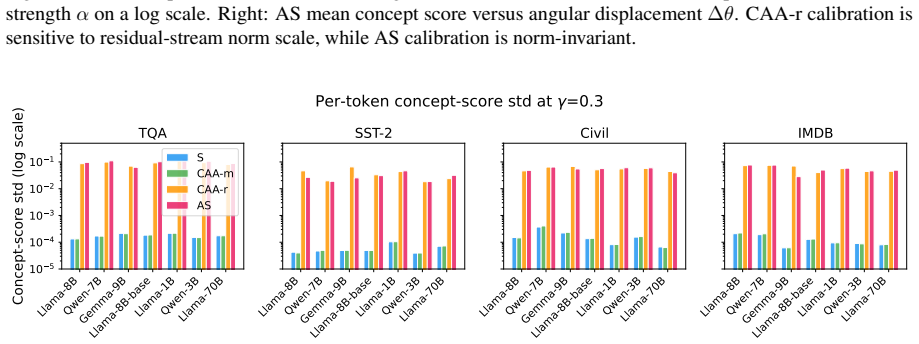
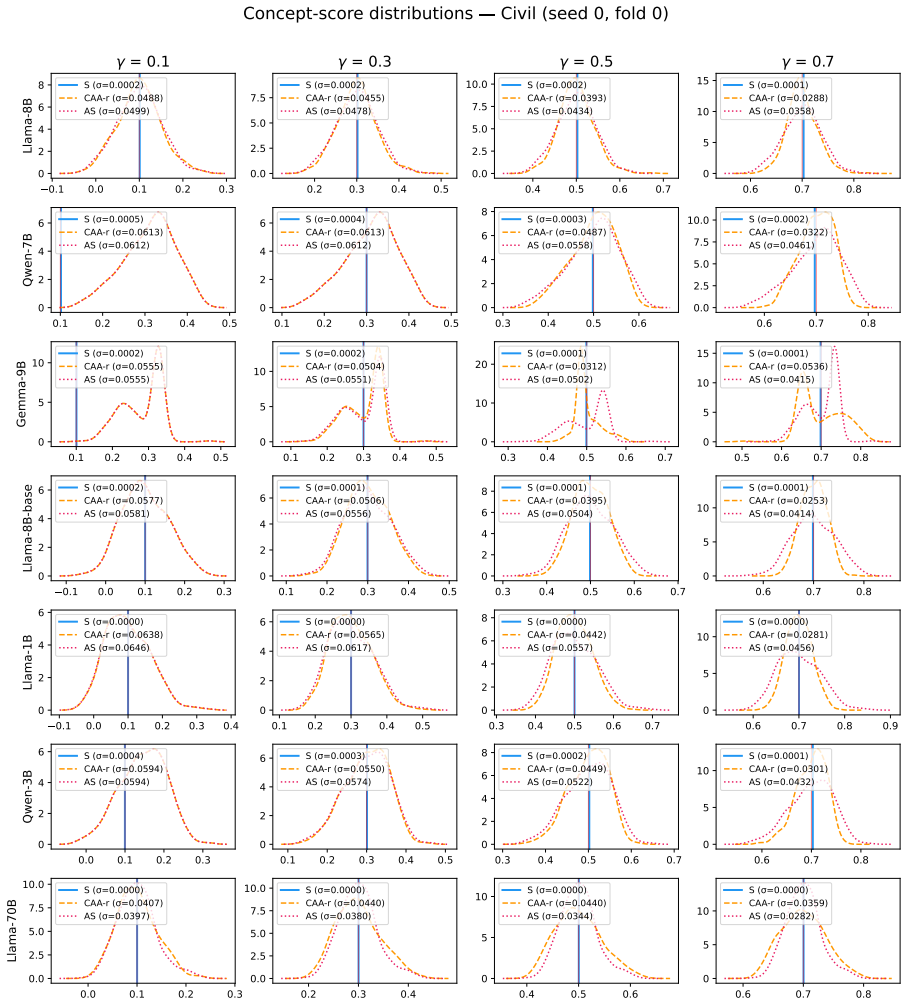
read the original abstract
Linear activation steering has gained popularity as a simple and empirically effective way to control language model behavior. More recently, spherical steering paradigms have been proposed to address limitations of additive interventions, often motivated by the assumption that hidden-state norm does not carry concept-relevant information. In this work, we revisit this assumption through a controlled empirical study designed to disentangle the roles of angular and radial components. We show that steering methods differ mainly in how they couple two geometric effects: changing a token's angular alignment with a concept direction and changing its hidden-state norm. Across seven language models, we find that concepts are represented primarily in angular structure, supporting the motivation for spherical methods, but that norm remains important for the stability and downstream effects of steering. Our results explain why interventions with similar concept-level effects can behave differently, and suggest that activation steering should be parameterized by interpretable angular and radial components of the intervention, rather than by a single additive coefficient that entangles these two effects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that linear activation steering can be decomposed into angular alignment and norm changes in hidden states. Through a controlled study across seven language models, it finds that concepts are represented primarily in angular structure (supporting spherical steering), while norm affects stability and downstream effects. It concludes that steering should be parameterized by interpretable angular and radial components rather than a single additive coefficient, as methods differ mainly in how they couple these geometric effects.
Significance. If the empirical disentanglement holds without confounding, the work provides a useful geometric lens on why additive vs. spherical steering methods produce different stability and behavioral outcomes. The multi-model scope and focus on interpretable parameterization are strengths that could inform more principled intervention design. The result is incremental but directly addresses a practical assumption in the activation steering literature.
major comments (2)
- [§4] §4 (Experimental Setup) and the abstract: The central claim that the seven-model study 'disentangles' angular and radial components rests on the assertion that steering methods 'differ mainly in how they couple two geometric effects.' However, no details are provided on per-model intervention scaling, projection, or normalization handling. Different models have distinct hidden-state distributions and layer norms; without explicit controls or reporting of these factors, the observed norm effects on stability could be implementation artifacts rather than pure geometric signals, directly undermining the disentanglement claim.
- [§5.1] §5.1 (Results on angular vs. norm importance): The finding that 'norm remains important for the stability and downstream effects of steering' is load-bearing for the recommendation to parameterize by angle and radius. Yet the manuscript supplies no statistical methods, controls for layer choice, or ablation on scaling coefficients, making it impossible to evaluate whether the angular-primary representation result is robust or confounded by model architecture.
minor comments (2)
- [Abstract] The abstract states findings from a 'controlled empirical study' but the provided text contains no experimental details, controls, or data summaries; this should be expanded even in the abstract for clarity.
- Notation for angle-norm decomposition (e.g., any equations defining the decomposition) should be introduced earlier and used consistently when discussing coupling of effects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the experimental reporting and robustness of our claims. We address each major comment below and will make revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup) and the abstract: The central claim that the seven-model study 'disentangles' angular and radial components rests on the assertion that steering methods 'differ mainly in how they couple two geometric effects.' However, no details are provided on per-model intervention scaling, projection, or normalization handling. Different models have distinct hidden-state distributions and layer norms; without explicit controls or reporting of these factors, the observed norm effects on stability could be implementation artifacts rather than pure geometric signals, directly undermining the disentanglement claim.
Authors: We agree that explicit documentation of per-model intervention parameters is required to substantiate the disentanglement. Although the study applied consistent protocols, the manuscript did not report scaling coefficients, projection steps, or normalization handling in sufficient detail. In the revised version we will expand §4 with a new subsection listing the exact scaling factors, projection methods, and normalization procedures used for each of the seven models, including any layer-norm adjustments. This addition will allow verification that the reported norm effects reflect geometric properties rather than implementation artifacts. revision: yes
-
Referee: [§5.1] §5.1 (Results on angular vs. norm importance): The finding that 'norm remains important for the stability and downstream effects of steering' is load-bearing for the recommendation to parameterize by angle and radius. Yet the manuscript supplies no statistical methods, controls for layer choice, or ablation on scaling coefficients, making it impossible to evaluate whether the angular-primary representation result is robust or confounded by model architecture.
Authors: We acknowledge that the current presentation of §5.1 lacks the statistical and ablation details needed to assess robustness. The experiments did vary layers and scaling, yet these were not formally reported or tested. We will revise §5.1 to include (i) statistical significance tests across multiple runs, (ii) explicit justification and controls for layer selection, and (iii) ablations that systematically vary scaling coefficients while holding angular components fixed. These changes will provide quantitative support for the claim that angular structure primarily encodes concepts while norm influences stability. revision: yes
Circularity Check
No circularity; empirical observations on angle-norm effects
full rationale
The paper reports results from a controlled empirical study across seven models, measuring how steering methods affect angular alignment versus norm in hidden states. No load-bearing derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims are direct observations of geometric effects rather than reductions to prior inputs by construction. This matches the default case of a self-contained empirical report.
Axiom & Free-Parameter Ledger
free parameters (1)
- steering intervention coefficients
Forward citations
Cited by 1 Pith paper
-
GEMS: Geometric Constraints Enable Multi-Semantic Superposition in LLMs
GEMS enables multi-semantic superposition in LLMs via norm-preserving superposition, attention injection, and real-time orthogonalization, maintaining high performance on GSM8K and Wikitext-2.
Reference graph
Works this paper leans on
-
[1]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander , booktitle =. Steering. 2024 , month = aug, address =. doi:10.18653/v1/2024.acl-long.828 , url =
-
[2]
Panickssery, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander Matt , year =. Steering. 2312.06681 , archivePrefix =
-
[3]
2023 , eprint =
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author =. 2023 , eprint =
2023
-
[4]
2023 , eprint =
Activation Addition: Steering Language Models Without Optimization , author =. 2023 , eprint =
2023
-
[5]
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
-
[6]
Proceedings of the 41st International Conference on Machine Learning , pages =
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
2024
-
[7]
2025 , eprint =
Angular Steering: Behavior Control via Rotation in Activation Space , author =. 2025 , eprint =
2025
-
[8]
2026 , eprint =
Spherical Steering: Geometry-Aware Activation Rotation for Language Models , author =. 2026 , eprint =
2026
-
[9]
2026 , eprint =
Selective Steering: Norm-Preserving Control Through Discriminative Layer Selection , author =. 2026 , eprint =
2026
-
[10]
2026 , eprint =
Activation Steering for Aligned Open-ended Generation without Sacrificing Coherence , author =. 2026 , eprint =
2026
-
[11]
2024 , eprint =
Improving Instruction-Following in Language Models through Activation Steering , author =. 2024 , eprint =
2024
-
[12]
Extracting Latent Steering Vectors from Pretrained Language Models
Extracting Latent Steering Vectors from Pretrained Language Models , author =. Findings of the Association for Computational Linguistics: ACL 2022 , pages =. 2022 , address =. doi:10.18653/v1/2022.findings-acl.48 , url =
-
[13]
International Conference on Learning Representations , year =
Efficient Streaming Language Models with Attention Sinks , author =. International Conference on Learning Representations , year =
-
[14]
TruthfulQA: Measuring how models mimic human false- hoods
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2022 , publisher =. doi:10.18653/v1/2022.acl-long.229 , url =
-
[15]
Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages =
Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank , author =. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing , pages =. 2013 , publisher =
2013
-
[16]
arXiv preprint arXiv:1903.04561 , year =
Nuanced Metrics for Measuring Unintended Bias with Real Data for Text Classification , author =. arXiv preprint arXiv:1903.04561 , year =
Pith/arXiv arXiv 1903
-
[17]
Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =
Learning Word Vectors for Sentiment Analysis , author =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , pages =. 2011 , publisher =
2011
-
[18]
International Conference on Learning Representations , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations , year =
-
[19]
arXiv preprint arXiv:1609.07843 , year =
Pointer Sentinel Mixture Models , author =. arXiv preprint arXiv:1609.07843 , year =
-
[20]
Transactions of the Association for Computational Linguistics , volume =
Natural Questions: A Benchmark for Question Answering Research , author =. Transactions of the Association for Computational Linguistics , volume =. 2019 , doi =
2019
-
[21]
Advances in Neural Information Processing Systems , volume =
Teaching Machines to Read and Comprehend , author =. Advances in Neural Information Processing Systems , volume =. 2015 , url =
2015
-
[22]
Get To The Point: Summarization with Pointer-Generator Networks , author =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2017 , publisher =. doi:10.18653/v1/P17-1099 , url =
-
[23]
2019 , howpublished =
OpenWebText Corpus , author =. 2019 , howpublished =
2019
-
[24]
2023 , howpublished =
Alpaca: A Strong, Replicable Instruction-Following Model , author =. 2023 , howpublished =
2023
-
[25]
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages =. 2018 , publisher =. doi:10.18653/v1/N18-2097 , url =
-
[26]
Hierarchical Neural Story Generation , author =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2018 , publisher =. doi:10.18653/v1/P18-1082 , url =
-
[27]
URLhttps://doi.org/10.18653/v1/D19-1259
PubMedQA: A Dataset for Biomedical Research Question Answering , author =. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing , pages =. 2019 , publisher =. doi:10.18653/v1/D19-1259 , url =
-
[28]
arXiv preprint arXiv:1909.09436 , year =
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search , author =. arXiv preprint arXiv:1909.09436 , year =
Pith/arXiv arXiv 1909
-
[29]
Refusal in Language Models Is Mediated by a Single Direction , booktitle =
Andy Arditi and Oscar Obeso and Aaquib Syed and Daniel Paleka and Nina Panickssery and Wes Gurnee and Neel Nanda , editor =. Refusal in Language Models Is Mediated by a Single Direction , booktitle =. 2024 , url =
2024
-
[30]
arXiv preprint arXiv:2407.21783 , year =
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
-
[31]
arXiv preprint arXiv:2412.15115 , year =
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
-
[32]
arXiv preprint arXiv:2408.00118 , year =
Gemma 2: Improving Open Language Models at a Practical Size , author =. arXiv preprint arXiv:2408.00118 , year =
-
[33]
2024 , howpublished =
Llama 3.1 Community License Agreement , author =. 2024 , howpublished =
2024
-
[34]
2024 , howpublished =
Llama 3.2 Community License Agreement , author =. 2024 , howpublished =
2024
-
[35]
2024 , howpublished =
Qwen2.5 Model Release and Licensing , author =. 2024 , howpublished =
2024
-
[36]
2024 , howpublished =
Qwen Research License Agreement , author =. 2024 , howpublished =
2024
-
[37]
2026 , howpublished =
Gemma Terms of Use , author =. 2026 , howpublished =
2026
-
[38]
2024 , howpublished =
TruthfulQA Dataset Card , author =. 2024 , howpublished =
2024
-
[39]
2024 , howpublished =
Stanford Sentiment Treebank v2 (SST2) Dataset , author =. 2024 , howpublished =
2024
-
[40]
2023 , howpublished =
Binary Stanford Sentiment Treebank 2 (SST-2) , author =. 2023 , howpublished =
2023
-
[41]
2024 , howpublished =
Civil Comments Dataset Card , author =. 2024 , howpublished =
2024
-
[42]
2011 , howpublished =
Large Movie Review Dataset , author =. 2011 , howpublished =
2011
-
[43]
2024 , howpublished =
WikiText Dataset Card , author =. 2024 , howpublished =
2024
-
[44]
2024 , howpublished =
MMLU Dataset Card , author =. 2024 , howpublished =
2024
-
[45]
2019 , howpublished =
OpenWebText Corpus Download Page , author =. 2019 , howpublished =
2019
-
[46]
2023 , howpublished =
Stanford Alpaca Repository , author =. 2023 , howpublished =
2023
-
[47]
2024 , howpublished =
Scientific Papers Dataset Card , author =. 2024 , howpublished =
2024
-
[48]
2024 , howpublished =
WritingPrompts Dataset Card , author =. 2024 , howpublished =
2024
-
[49]
2019 , howpublished =
Natural Questions Download Page , author =. 2019 , howpublished =
2019
-
[50]
2024 , howpublished =
CNN/DailyMail Dataset Card , author =. 2024 , howpublished =
2024
-
[51]
2019 , howpublished =
PubMedQA Repository , author =. 2019 , howpublished =
2019
-
[52]
2019 , howpublished =
CodeSearchNet Repository , author =. 2019 , howpublished =
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.