Forward-Free Diffusion Language Models
Pith reviewed 2026-06-27 19:21 UTC · model grok-4.3
The pith
Diffusion language models can generate text by recursively refining their own drafts without any hand-designed forward corruption process.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
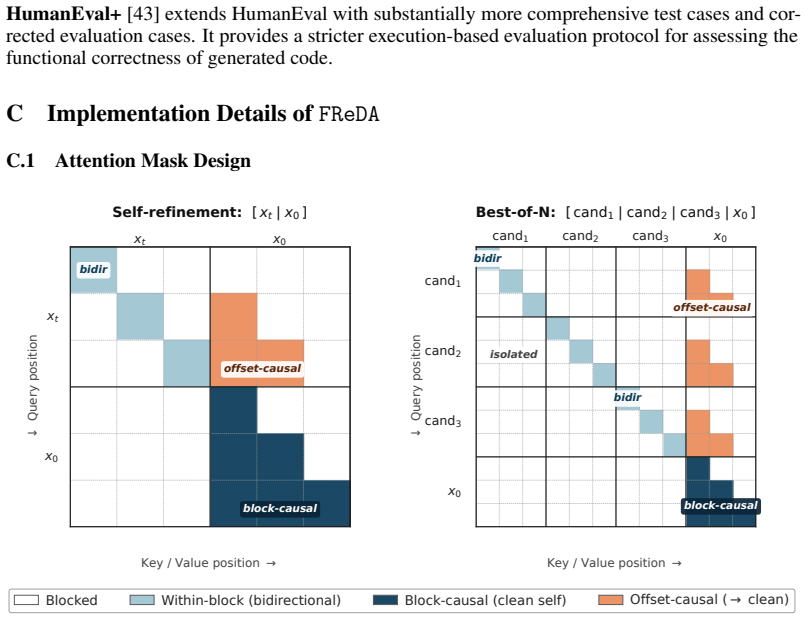
FReDA eliminates the need for a hand-designed forward process by formulating diffusion language modeling as recursive distribution refinement, in which model-generated drafts serve as implicit intermediate states and the learned refinement model progressively moves the draft distribution toward the target distribution through either direct self-refinement or best-of-N selection among parallel candidates.
What carries the argument
Recursive distribution refinement that treats model-generated drafts as implicit intermediate states, allowing progressive movement toward the target distribution without a prescribed forward process.
If this is right
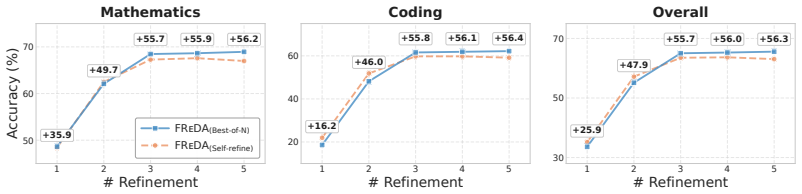
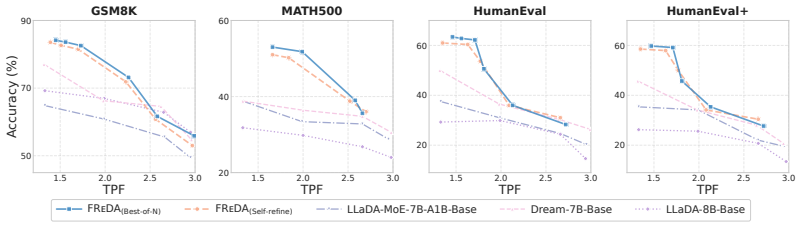
- A 4B FReDA model outperforms larger diffusion base models on reasoning and coding benchmarks with absolute gains up to 15%.
- FReDA reaches 1.5-1.8x average speedup over diffusion baselines.
- Performance scales effectively with additional refinement computation.
- The approach is neighborhood-agnostic and compatible with flexible refinement parameterizations.
Where Pith is reading between the lines
- The same draft-refinement idea could be tested on other discrete generative tasks where explicit noise schedules have been hard to define.
- Hybrid systems might combine an initial autoregressive draft with subsequent diffusion-style refinement steps.
- If the method works, it suggests that explicit forward processes may be unnecessary in many discrete diffusion settings.
Load-bearing premise
Model-generated drafts can serve as effective implicit intermediate states that let a learned refinement model move the distribution toward the target without any prescribed forward process.
What would settle it
Running the same benchmarks and compute budget shows FReDA-4B failing to match or exceed the performance and speed of standard diffusion baselines.
Figures

read the original abstract
Diffusion language models generate text through iterative denoising, offering a powerful alternative to autoregressive generation. However, discrete language spaces lack a natural neighborhood structure for defining effective perturbations, so some artificial corruption schemes are proposed in the forward process. Such prescribed forward processes often produce states that are mathematically convenient but misaligned with drafts and errors encountered during generation, resulting in degraded sample quality. To address this limitation, we propose FReDA, a forward-free diffusion language model that eliminates the need for a hand-designed forward process. We formulate diffusion language modeling as recursive distribution refinement, in which model-generated drafts serve as implicit intermediate states, and the learned refinement model progressively moves the draft distribution toward the target distribution. Concretely, FReDA refines drafts by proposing candidate draft sequences and either directly performing self-refinement or selecting among parallel candidates via best-of-N refinement. With this design, FReDA is neighborhood-agnostic, model-complexity-aware, and compatible with flexible refinement parameterizations. Extensive evaluations in the sub-8B regime show that FReDA-4B outperforms larger diffusion base models on reasoning and coding benchmarks, achieving absolute gains of up to 15%, while reaching a 1.5-1.8x average speedup over diffusion baselines and scaling effectively with additional refinement computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FReDA, a forward-free diffusion language model that reframes diffusion LM as recursive distribution refinement. Model-generated drafts serve as implicit intermediate states; a learned refinement model (via self-refinement or best-of-N selection among parallel candidates) progressively shifts the draft distribution toward the target without any hand-designed forward corruption process. In the sub-8B regime, FReDA-4B is reported to outperform larger diffusion baselines on reasoning and coding benchmarks (absolute gains up to 15%), deliver 1.5-1.8x average speedup, and scale with additional refinement compute.
Significance. If the recursive-refinement construction can be shown to converge reliably without an explicit forward process or strong bootstrap assumptions, the approach would address a recognized limitation of discrete diffusion LMs (misalignment between prescribed noise schedules and actual generation errors). The claimed performance and speed advantages, together with neighborhood-agnostic and model-complexity-aware properties, would be of interest to the diffusion-LM community.
major comments (2)
- [§3] §3 (recursive distribution refinement): The central claim that model-generated drafts can serve as effective implicit intermediate states rests on an unstated assumption that the training-time draft distribution overlaps sufficiently with inference-time drafts. No analysis, bound, or ablation is provided to verify that the refinement operator remains contractive when early drafts lie far from the data distribution; this makes convergence dependent on an implicit bootstrap rather than the forward-free property itself.
- [§4] §4 (training procedure): The paper states that the refinement model is trained on model-generated drafts, yet provides no description of how the base model is initialized or whether an initial supervised phase on ground-truth data is required before self-refinement begins. Without this detail the claimed elimination of a forward process cannot be evaluated for circularity.
minor comments (2)
- The abstract claims 'extensive evaluations' and specific speed-up numbers, but the manuscript should include a table or section explicitly listing the diffusion baselines, their sizes, and the exact refinement budgets used for the 1.5-1.8x comparison.
- Notation for the refinement operator and the best-of-N selection step should be introduced with a single equation or pseudocode block for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [§3] §3 (recursive distribution refinement): The central claim that model-generated drafts can serve as effective implicit intermediate states rests on an unstated assumption that the training-time draft distribution overlaps sufficiently with inference-time drafts. No analysis, bound, or ablation is provided to verify that the refinement operator remains contractive when early drafts lie far from the data distribution; this makes convergence dependent on an implicit bootstrap rather than the forward-free property itself.
Authors: The referee correctly identifies that our formulation relies on an implicit assumption regarding the distribution overlap. While the empirical results in the sub-8B regime support the practical utility of the recursive refinement, we did not include a theoretical analysis of contractiveness. We will add an expanded discussion section addressing this assumption and include relevant ablations in the revised version. revision: yes
-
Referee: [§4] §4 (training procedure): The paper states that the refinement model is trained on model-generated drafts, yet provides no description of how the base model is initialized or whether an initial supervised phase on ground-truth data is required before self-refinement begins. Without this detail the claimed elimination of a forward process cannot be evaluated for circularity.
Authors: We agree that the training procedure description lacks detail on model initialization. The process begins with supervised training of the base model on ground-truth data, after which drafts are generated for training the refinement model. This will be explicitly stated in the revised manuscript to clarify the absence of circularity. revision: yes
- A formal bound demonstrating that the refinement remains contractive without relying on bootstrap assumptions for distant initial drafts.
Circularity Check
No significant circularity detected
full rationale
The provided abstract formulates FReDA as recursive distribution refinement using model-generated drafts as implicit intermediates, but contains no equations, derivations, or self-citations that reduce any claimed result to its inputs by construction. No load-bearing step is exhibited where a prediction equals a fitted quantity or where a uniqueness theorem collapses to prior author work. The central claims rest on empirical benchmarks rather than tautological redefinition, rendering the derivation self-contained against external evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model-generated drafts serve as effective implicit intermediate states for distribution refinement.
Forward citations
Cited by 1 Pith paper
-
Continuous Language Diffusion as a Decoder-Interface Problem
Continuous language diffusion works by entering high-margin decoder basins where frozen T5 embeddings recover 93-96% of native decisions and linear readouts reach 97.9% agreement, implying models should be evaluated a...
Reference graph
Works this paper leans on
-
[1]
Alamdari, N
S. Alamdari, N. Thakkar, R. van den Berg, A. X. Lu, N. Fusi, A. P. Amini, and K. K. Yang. Protein generation with evolutionary diffusion: sequence is all you need.bioRxiv, 2023
2023
-
[2]
A. G. ALIAS PARTH GOYAL, N. R. Ke, S. Ganguli, and Y . Bengio. Variational walkback: Learning a transition operator as a stochastic recurrent net.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[3]
A. N. Amin, N. Gruver, and A. G. Wilson. Why Masking Diffusion Works: Condition on the Jump Schedule for Improved Discrete Diffusion.arXiv, 2025
2025
-
[4]
Arriola, A
M. Arriola, A. Gokaslan, J. T. Chiu, Z. Yang, Z. Qi, J. Han, S. S. Sahoo, and V . Kuleshov. Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models.arXiv, 2025
2025
-
[5]
Austin, D
J. Austin, D. D. Johnson, J. Ho, D. Tarlow, and R. v. d. Berg. Structured Denoising Diffusion Models in Discrete State-Spaces.arXiv, 2021
2021
-
[6]
Avdeyev, C
P. Avdeyev, C. Shi, Y . Tan, K. Dudnyk, and J. Zhou. Dirichlet diffusion score model for biological sequence generation, 2023
2023
-
[7]
Ben-Hamu, I
H. Ben-Hamu, I. Gat, D. Severo, N. Nolte, and B. Karrer. Accelerated sampling from masked diffusion models via entropy bounded unmasking, 2025
2025
-
[8]
T. Bie, M. Cao, X. Cao, B. Chen, F. Chen, K. Chen, L. Du, D. Feng, H. Feng, M. Gong, Z. Gong, Y . Gu, J. Guan, K. Guan, H. He, Z. Huang, J. Jiang, Z. Jiang, Z. Lan, C. Li, J. Li, Z. Li, H. Liu, L. Liu, G. Lu, Y . Lu, Y . Ma, X. Mou, Z. Pan, K. Qiu, Y . Ren, J. Tan, Y . Tian, Z. Wang, L. Wei, T. Wu, Y . Xing, W. Ye, L. Zha, T. Zhang, X. Zhang, J. Zhao, D. ...
2026
-
[9]
T. Bie, M. Cao, K. Chen, L. Du, M. Gong, Z. Gong, Y . Gu, J. Hu, Z. Huang, Z. Lan, C. Li, C. Li, J. Li, Z. Li, H. Liu, L. Liu, G. Lu, X. Lu, Y . Ma, J. Tan, L. Wei, J.-R. Wen, Y . Xing, X. Zhang, J. Zhao, D. Zheng, J. Zhou, J. Zhou, Z. Zhou, L. Zhu, and Y . Zhuang. Llada2.0: Scaling up diffusion language models to 100b, 2025
2025
-
[10]
Campbell, J
A. Campbell, J. Benton, V . D. Bortoli, T. Rainforth, G. Deligiannidis, and A. Doucet. A continuous time framework for discrete denoising models, 2022
2022
-
[11]
Campbell, V
A. Campbell, V . D. Bortoli, J. Shi, and A. Doucet. Self-Speculative Masked Diffusions.arXiv, 2025
2025
-
[12]
A. Chandiramani, A. Blakeman, A. Olaoye, A. Gupta, A. Somasamudramath, A. Khattar, A. Adesoba, A. Renduchintala, A. Asif, A. Agrawal, et al. Nemotron 3 super: Open, efficient mixture-of-experts hybrid mamba-transformer model for agentic reasoning.arXiv preprint arXiv:2604.12374, 2026
Pith/arXiv arXiv 2026
-
[13]
Chang, A
K.-W. Chang, A. Krishnamurthy, A. Agarwal, H. D. III, and J. Langford. Learning to search better than your teacher, 2015
2015
-
[14]
B. Chen, D. M. Monso, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion, 2024
2024
-
[15]
J. Chen, Y . Liang, and Z. Liu. DFlash: Block Diffusion for Flash Speculative Decoding.arXiv, 2026
2026
-
[16]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Her...
2021
-
[17]
Z. Chen, G. Fang, X. Ma, R. Yu, and X. Wang. DMax: Aggressive Parallel Decoding for dLLMs.arXiv, 2026
2026
-
[18]
Cheng, Y
S. Cheng, Y . Bian, D. Liu, L. Zhang, Q. Yao, Z. Tian, W. Wang, Q. Guo, K. Chen, B. Qi, and B. Zhou. SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation.arXiv, 2025
2025
-
[19]
Cobbe, V
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems, 2021
2021
-
[20]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruan, D. Dai, D. Guo, D. Yang, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Bao, H. Xu, H. Wang, H. Zhang, H. Ding, H. Xin, H. Gao, H. Li, H. Qu, J. L. Cai, J. Liang, J. Guo, J. Ni, J. Li, J. Wang, J. Chen, J. Chen, J. Yuan, J...
2025
-
[21]
J. Dong, B. Feng, D. Guessous, Y . Liang, and H. He. Flex attention: A programming model for generating optimized attention kernels, 2024
2024
-
[22]
Ethayarajh
K. Ethayarajh. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings, 2019
2019
-
[23]
I. Gat, T. Remez, N. Shaul, F. Kreuk, R. T. Q. Chen, G. Synnaeve, Y . Adi, and Y . Lipman. Discrete Flow Matching.arXiv, 2024
2024
-
[24]
I. Gat, N. Shaul, U. Singer, and Y . Lipman. Corrector Sampling in Language Models.arXiv, 2025
2025
-
[25]
Gloeckle, B
F. Gloeckle, B. Y . Idrissi, B. Rozière, D. Lopez-Paz, and G. Synnaeve. Better & Faster large language models via multi-token prediction, 2024
2024
-
[26]
S. Gong, S. Agarwal, Y . Zhang, J. Ye, L. Zheng, M. Li, C. An, P. Zhao, W. Bi, J. Han, H. Peng, and L. Kong. Scaling Diffusion Language Models via Adaptation from Autoregressive Models. arXiv, 2024
2024
-
[27]
J. Gu, C. Wang, and J. Zhao. Levenshtein Transformer.arXiv, 2019
2019
-
[28]
Gulrajani and T
I. Gulrajani and T. B. Hashimoto. Likelihood-based diffusion language models.Advances in Neural Information Processing Systems, 36:16693–16715, 2023
2023
-
[29]
H. He, K. Renz, Y . Cao, and A. Geiger. Mdpo: Overcoming the training-inference divide of masked diffusion language models, 2025
2025
-
[30]
Z. He, T. Sun, Q. Tang, K. Wang, X.-J. Huang, and X. Qiu. Diffusionbert: Improving generative masked language models with diffusion models. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 4521–4534, 2023
2023
-
[31]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding, 2021. 12
2021
-
[32]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models, 2020
2020
-
[33]
Hoogeboom, D
E. Hoogeboom, D. Nielsen, P. Jaini, P. Forré, and M. Welling. Argmax flows and multinomial diffusion: Learning categorical distributions, 2021
2021
-
[34]
Huang, Y
Z. Huang, Y . Wang, Z. Chen, and G.-J. Qi. Don’t Settle Too Early: Self-Reflective Remasking for Diffusion Language Models.arXiv, 2025
2025
-
[35]
Y . Ji, T. Wang, Y . Ge, Z. Liu, S. Yang, Y . Shan, and P. Luo. From Denoising to Refining: A Corrective Framework for Vision-Language Diffusion Model.arXiv, 2025
2025
-
[36]
Karras, M
T. Karras, M. Aittala, T. Aila, and S. Laine. Elucidating the design space of diffusion-based generative models, 2022
2022
-
[37]
J. Kim, S. Kim, T. Lee, D. Z. Pan, H. Kim, S. Kakade, and S. Chen. Fine-Tuning Masked Diffusion for Provable Self-Correction.arXiv, 2025
2025
-
[38]
Y . Li, F. Wei, C. Zhang, and H. Zhang. Eagle-2: Faster inference of language models with dynamic draft trees, 2024
2024
-
[39]
Y . Li, F. Wei, C. Zhang, and H. Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test, 2025
2025
-
[40]
Y . Li, F. Wei, C. Zhang, and H. Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty, 2025
2025
-
[41]
Lightman, V
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let’s verify step by step, 2023
2023
-
[42]
J. Liu, X. Dong, Z. Ye, R. Mehta, Y . Fu, V . Singh, J. Kautz, C. Zhang, and P. Molchanov. TiDAR: Think in Diffusion, Talk in Autoregression.arXiv, 2025
2025
-
[43]
J. Liu, C. S. Xia, Y . Wang, and L. Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation, 2023
2023
-
[44]
A. Lou, C. Meng, and S. Ermon. Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution.arXiv, 2023
2023
-
[45]
X. Ma, R. Yu, G. Fang, and X. Wang. dKV-Cache: The Cache for Diffusion Language Models. arXiv, 2025
2025
-
[46]
C. J. Maddison, D. Tarlow, and T. Minka. A* sampling.Advances in neural information processing systems, 27, 2014
2014
-
[47]
R. K. Mahabadi, S. Satheesh, S. Prabhumoye, M. Patwary, M. Shoeybi, and B. Catanzaro. Nemotron-cc-math: A 133 billion-token-scale high quality math pretraining dataset, 2025
2025
-
[48]
Mohamed, Y
A. Mohamed, Y . Zhang, M. Vazirgiannis, and G. Shang. Fast-decoding diffusion language models via progress-aware confidence schedules, 2025
2025
-
[49]
A. Q. Nichol and P. Dhariwal. Improved denoising diffusion probabilistic models. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 8162–8171. PMLR, 18–24 Jul 2021
2021
-
[50]
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.-R. Wen, and C. Li. Large Language Diffusion Models.arXiv, 2025
2025
-
[51]
Penedo, H
G. Penedo, H. Kydlí ˇcek, L. B. allal, A. Lozhkov, M. Mitchell, C. Raffel, L. V . Werra, and T. Wolf. The fineweb datasets: Decanting the web for the finest text data at scale, 2024
2024
-
[52]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei, H. Lin, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Lin, K. Dang, K. Lu, K. Bao, K. Yang, L. Yu, M. Li, M. Xue, P. Zhang, Q. Zhu, R. Men, R. Lin, T. Li, T. Tang, T. Xia, X. Ren, X. Ren, Y . Fan, Y . Su, Y . Zhang, Y . Wan, Y . Liu, Z. Cui, Z. Zhang, ...
2024
-
[53]
M. Reid, V . J. Hellendoorn, and G. Neubig. DiffusER: Discrete Diffusion via Edit-based Reconstruction.arXiv, 2022
2022
-
[54]
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman. Gpqa: A graduate-level google-proof Q&A benchmark, 2023
2023
-
[55]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models, 2022
2022
-
[56]
D. v. Rütte, J. Fluri, Y . Ding, A. Orvieto, B. Schölkopf, and T. Hofmann. Generalized Interpo- lating Discrete Diffusion.arXiv, 2025
2025
-
[57]
S. S. Sahoo, M. Arriola, Y . Schiff, A. Gokaslan, E. Marroquin, J. T. Chiu, A. Rush, and V . Kuleshov. Simple and Effective Masked Diffusion Language Models.arXiv, 2024
2024
-
[58]
Shabalin, V
A. Shabalin, V . Meshchaninov, and D. Vetrov. Smoothie: Smoothing Diffusion on Token Embeddings for Text Generation.arXiv, 2025
2025
-
[59]
J. Shi, K. Han, Z. Wang, A. Doucet, and M. K. Titsias. Simplified and Generalized Masked Diffusion for Discrete Data.arXiv, 2024
2024
-
[60]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency models, 2023
2023
-
[61]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations, 2021
2021
-
[62]
Y . Song, Z. Zhang, C. Luo, P. Gao, F. Xia, H. Luo, Z. Li, Y . Yang, H. Yu, X. Qu, Y . Fu, J. Su, G. Zhang, W. Huang, M. Wang, L. Yan, X. Jia, J. Liu, W.-Y . Ma, Y .-Q. Zhang, Y . Wu, and H. Zhou. Seed diffusion: A large-scale diffusion language model with high-speed inference, 2025
2025
-
[63]
K. Wang, Z. Jiang, H. Feng, W. Zhao, L. Liu, J. Li, Z. Lan, and W. Lin. CreditDecoding: Accelerating Parallel Decoding in Diffusion Large Language Models with Trace Credits.arXiv, 2025
2025
-
[64]
X. Wang, C. Xu, Y . Jin, J. Jin, H. Zhang, and Z. Deng. Diffusion llms can do faster-than-ar inference via discrete diffusion forcing, 2025
2025
-
[65]
Y . Wang, L. Yang, B. Li, Y . Tian, K. Shen, and M. Wang. Revolutionizing reinforcement learning framework for diffusion large language models, 2025
2025
-
[66]
J. Wen, B. Dai, L. Li, and D. Schuurmans. Batch stationary distribution estimation.arXiv preprint arXiv:2003.00722, 2020
arXiv 2003
-
[67]
C. Wu, H. Zhang, S. Xue, S. Diao, Y . Fu, Z. Liu, P. Molchanov, P. Luo, S. Han, and E. Xie. Fast-dllm v2: Efficient block-diffusion llm, 2025
2025
-
[68]
C. Wu, H. Zhang, S. Xue, Z. Liu, S. Diao, L. Zhu, P. Luo, S. Han, and E. Xie. Fast-dllm: Training-free acceleration of diffusion llm by enabling kv cache and parallel decoding, 2025
2025
-
[69]
M. Xu, T. Geffner, K. Kreis, W. Nie, Y . Xu, J. Leskovec, S. Ermon, and A. Vahdat. Energy-based diffusion language models for text generation.arXiv, 2024
2024
-
[70]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
2025
-
[71]
J. Ye, Z. Xie, L. Zheng, J. Gao, Z. Wu, X. Jiang, Z. Li, and L. Kong. Dream 7B: Diffusion Large Language Models.arXiv, 2025
2025
- [72]
-
[73]
Y . Zhao, J. Shi, F. Chen, S. Druckmann, L. Mackey, and S. Linderman. Informed Correctors for Discrete Diffusion Models.arXiv, 2025
2025
-
[74]
Zheng, Y
K. Zheng, Y . Chen, H. Mao, M.-Y . Liu, J. Zhu, and Q. Zhang. Masked Diffusion Models are Secretly Time-Agnostic Masked Models and Exploit Inaccurate Categorical Sampling.arXiv, 2024
2024
-
[75]
logE x2:N ∼K SR θ (·|x′)
F. Zhu, Z. You, Y . Xing, Z. Huang, L. Liu, Y . Zhuang, G. Lu, K. Wang, X. Wang, L. Wei, H. Guo, J. Hu, W. Ye, T. Chen, C. Li, C. Tang, H. Feng, J. Hu, J. Zhou, X. Zhang, Z. Lan, J. Zhao, D. Zheng, C. Li, J. Li, and J.-R. Wen. LLaDA-MoE: A Sparse MoE Diffusion Language Model.arXiv, 2025. 15 A Theoretical Derivations A.1 Proof of Proposition 1 Proof.The ma...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.