Lost in the Non-convex Loss Landscape: How to Fine-tune the Large Time Series Model?
Pith reviewed 2026-06-27 19:04 UTC · model grok-4.3
The pith
Linear interpolation between pre-trained and random weights smooths the non-convex loss landscape to improve fine-tuning of large time series models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
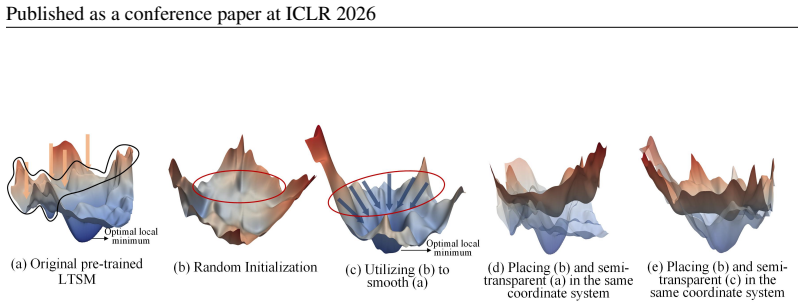
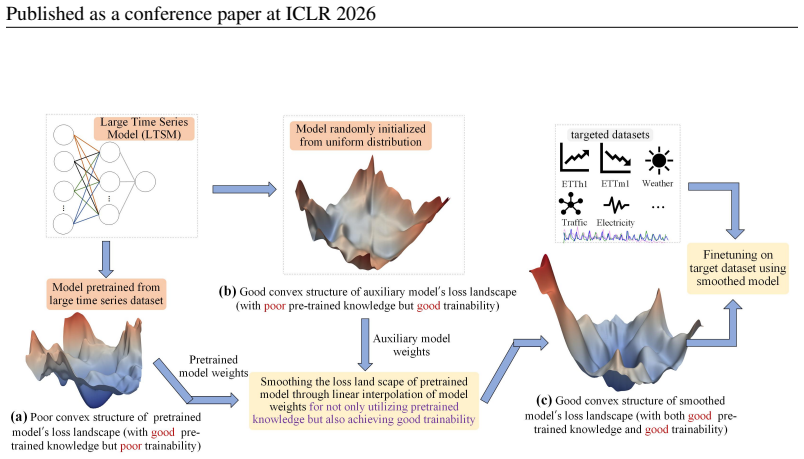
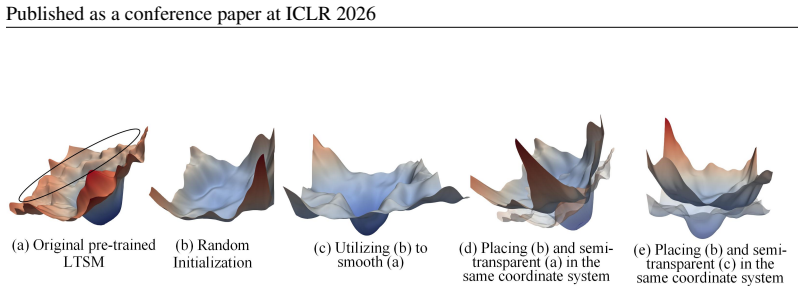
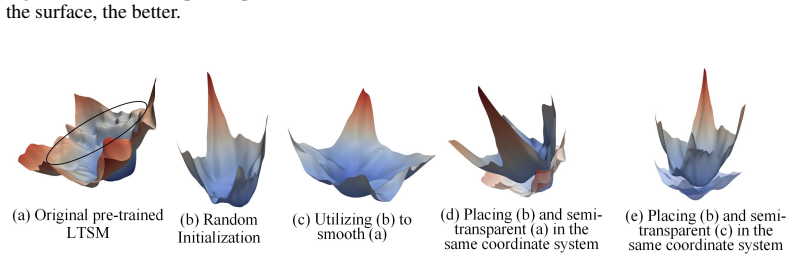
Smoothed Full Fine-tuning (SFF) obtains a smoother loss landscape by linearly interpolating the weights of the pre-trained large time series model with those of an auxiliary model created via random initialization. From an optimization view, this perturbs sharp minima without significantly harming flat regions and helps the optimizer escape poor local basins toward smoother, more generalizable solutions. Experiments show consistent gains on eight representative models across diverse downstream tasks.
What carries the argument
Linear weight interpolation between a pre-trained large time series model and a randomly initialized auxiliary model, which produces the smoothed loss landscape used for fine-tuning.
If this is right
- SFF enables effective use of pre-trained knowledge on downstream tasks where direct fine-tuning previously failed.
- The method perturbs sharp minima while preserving flat regions, leading to more generalizable solutions.
- Performance gains hold across eight representative LTSMs including Timer, TimesFM, MOMENT, UniTS, MOIRAI, Chronos, TTMs, and Sundial.
- No task-specific adjustment of the interpolation ratio is needed for the smoothing effect.
Where Pith is reading between the lines
- The same interpolation idea could be tested on large models in other modalities where non-convex fine-tuning landscapes are known to be problematic.
- If the smoothing effect scales with model size, it might reduce the need for more complex regularization techniques during adaptation.
- One could measure whether the interpolated landscape actually changes the distribution of Hessian eigenvalues at minima to confirm the claimed perturbation of sharp regions.
Load-bearing premise
Linear interpolation between pre-trained weights and randomly initialized weights produces a loss landscape that is both smoother and more amenable to generalization than the original, without requiring task-specific tuning of the interpolation ratio.
What would settle it
If SFF-tuned models show no consistent improvement over direct fine-tuning or training from scratch across the eight tested LTSMs and multiple benchmark tasks, the claim of improved trainability would be falsified.
Figures



read the original abstract
Recently, large time series models (LTSMs) have gained increasing attention due to their similarities to large language models, including flexible context length, scalability, and task generality, outperforming advanced task-specific models. However, prior studies indicate that pre-trained LTSMs may exhibit a poorly conditioned non-convex loss landscape, leading to limited trainability. As a result, direct fine-tuning tends to cause overfitting and suboptimal performance, sometimes even worse than training from scratch, substantially diminishing the benefits of pre-training. To overcome this limitation, we propose Smoothed Full Fine-tuning (SFF), a novel fine-tuning technology. Specifically, we construct an auxiliary LTSM via random initialization to obtain a smoother loss landscape, and then linearly interpolate its weights with those of the pre-trained model to smooth the original landscape. This process improves trainability while preserving pre-trained knowledge, thereby enabling more effective downstream fine-tuning. From an optimization perspective, SFF perturbs sharp minima without significantly harming flat regions, facilitating escape from poor local basins toward smoother and more generalizable solutions. Extensive experiments on benchmark datasets demonstrate consistent improvements across eight representative LTSMs, including Timer, TimesFM, MOMENT, UniTS, MOIRAI, Chronos, TTMs, and Sundial, on diverse downstream tasks. The code is available at the link: https://github.com/Meteor-Stars/SFF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pre-trained large time series models (LTSMs) suffer from poorly conditioned non-convex loss landscapes that cause direct fine-tuning to overfit or underperform training from scratch. It proposes Smoothed Full Fine-tuning (SFF), which builds an auxiliary randomly initialized LTSM and linearly interpolates its weights with the pre-trained model to smooth the landscape by perturbing sharp minima while preserving flat regions. This is asserted to improve trainability and generalization without task-specific tuning of the interpolation ratio. Experiments are said to show consistent gains across eight LTSMs (Timer, TimesFM, MOMENT, UniTS, MOIRAI, Chronos, TTMs, Sundial) on diverse downstream tasks.
Significance. If the mechanism and empirical gains are validated, SFF would supply a lightweight, architecture-agnostic fine-tuning procedure that could make pre-trained LTSMs more reliably usable, addressing a practical bottleneck in the emerging LTSM literature. The public code release is a clear strength for reproducibility.
major comments (2)
- [§3] §3: The core claim that linear interpolation produces a smoother loss landscape (rather than acting as generic regularization or changed initialization scale) is load-bearing for the method's justification, yet the manuscript provides no quantitative landscape diagnostics such as Hessian trace, sharpness metrics, or barrier heights along the interpolation line, and no ablation that isolates the geometric effect.
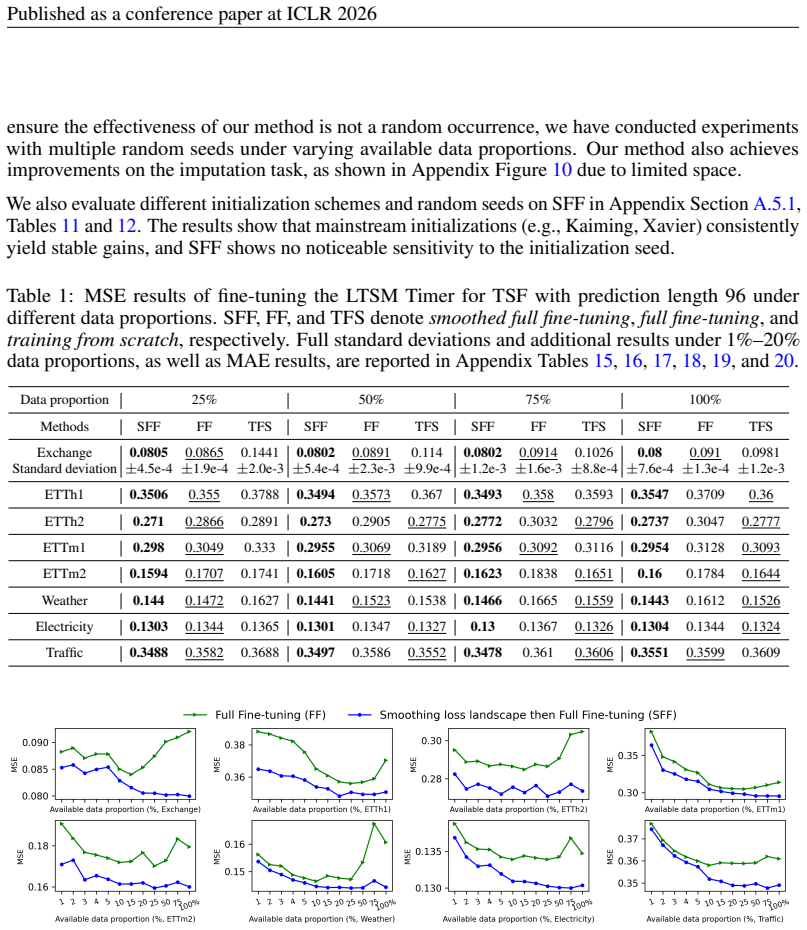
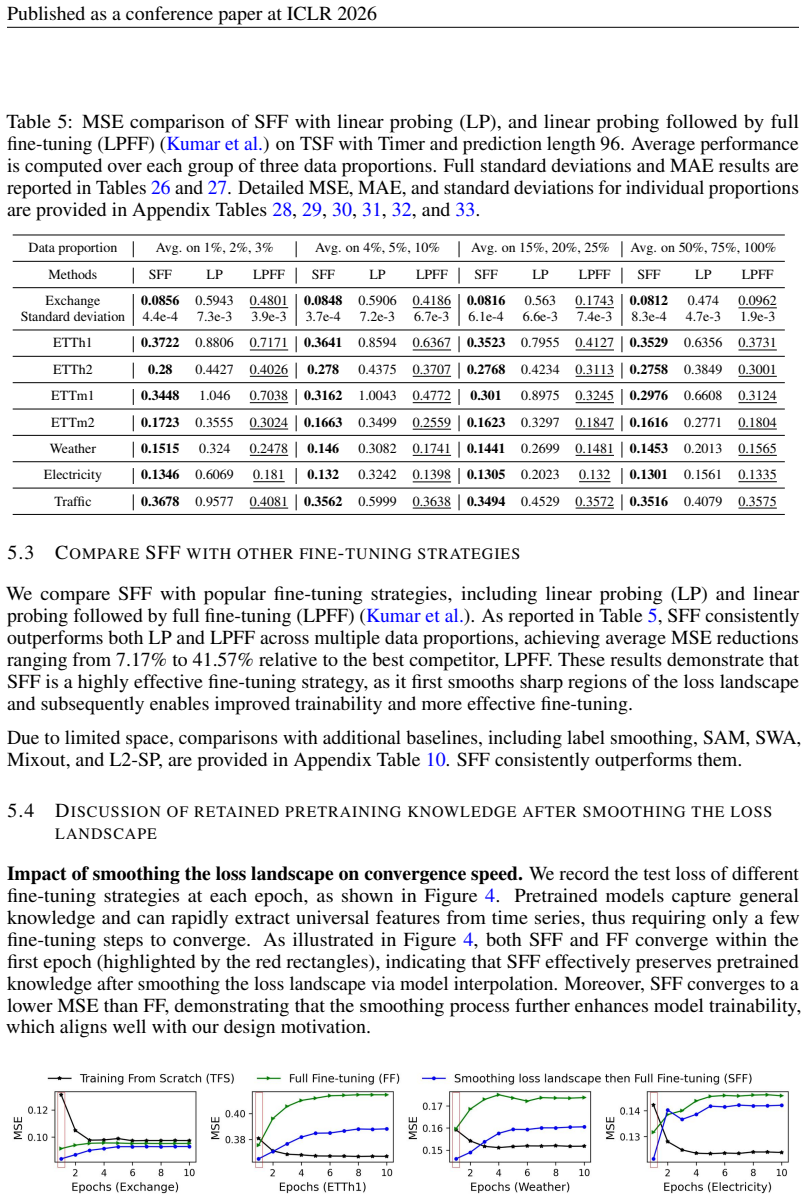
- [Experiments] Experiments (throughout): The abstract asserts 'consistent improvements' and 'extensive experiments' across eight models, but supplies no numerical results, baseline comparisons, statistical tests, or controls; without these, it is impossible to determine whether the data support the central claim that SFF enables more effective downstream fine-tuning.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the claims where needed.
read point-by-point responses
-
Referee: [§3] §3: The core claim that linear interpolation produces a smoother loss landscape (rather than acting as generic regularization or changed initialization scale) is load-bearing for the method's justification, yet the manuscript provides no quantitative landscape diagnostics such as Hessian trace, sharpness metrics, or barrier heights along the interpolation line, and no ablation that isolates the geometric effect.
Authors: We agree that quantitative landscape analysis would strengthen the geometric justification. Section 3 motivates the smoothing effect via optimization arguments (perturbing sharp minima while preserving flat regions), but lacks explicit metrics. In revision we will add Hessian trace, sharpness, and barrier height measurements along the interpolation path, plus ablations against pure regularization and rescaled initialization to isolate the interpolation geometry. revision: yes
-
Referee: [Experiments] Experiments (throughout): The abstract asserts 'consistent improvements' and 'extensive experiments' across eight models, but supplies no numerical results, baseline comparisons, statistical tests, or controls; without these, it is impossible to determine whether the data support the central claim that SFF enables more effective downstream fine-tuning.
Authors: The manuscript reports results across eight LTSMs and diverse tasks with comparisons to direct fine-tuning and scratch training, supported by the released code. To improve clarity we will expand the experimental section with full numerical tables, additional baseline controls, and statistical tests (e.g., paired t-tests with p-values) in the revision. revision: yes
Circularity Check
No circularity: method defined independently and evaluated via external experiments
full rationale
The paper introduces SFF as an explicit procedure (random auxiliary model + linear interpolation of weights) whose claimed benefit is then tested on eight external LTSMs across downstream tasks. No derivation step reduces a claimed outcome to a fitted parameter or self-referential definition; the smoothing effect is asserted as a geometric consequence of the interpolation construction and is not used to justify its own inputs. No self-citations appear in the provided text as load-bearing premises, and the experimental results are presented as independent validation rather than tautological outputs. The absence of Hessian diagnostics is a limitation of evidence strength, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear interpolation of weights between a pre-trained LTSM and a randomly initialized model produces a smoother loss landscape that improves generalization
Forward citations
Cited by 1 Pith paper
-
Self-Adaptive Scale Handling for Forecasting Time Series with Scale Heterogeneity
The self-adaptive scale-handling (AS) module with scale calibrating and scaling selection learns per-input scale factors to improve forecasting on scale-heterogeneous time series.
Reference graph
Works this paper leans on
-
[1]
Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
Abdul Fatir Ansari, Lorenzo Stella, Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
-
[2]
Ching Chang, Wen-Chih Peng, and Tien-Fu Chen. Llm4ts: Two-stage fine-tuning for time-series forecasting with pre-trained llms.arXiv preprint arXiv:2308.08469,
-
[3]
Pierre Foret, Ariel Kleiner, Hossein Mobahi, and Behnam Neyshabur. Sharpness-aware minimization for efficiently improving generalization.arXiv preprint arXiv:2010.01412,
Pith/arXiv arXiv 2010
-
[4]
Darksim: A similarity-based time-series analytic framework for darknet traffic
Max Gao, Ricky Mok, Esteban Carisimo, Eric Li, Shubham Kulkarni, and kc claffy. Darksim: A similarity-based time-series analytic framework for darknet traffic. InProceedings of the 2024 ACM on Internet Measurement Conference, pp. 241–258, 2024a. Shanghua Gao, Teddy Koker, Owen Queen, Thomas Hartvigsen, Theodoros Tsiligkaridis, and Marinka Zitnik. Units: B...
arXiv 2024
-
[5]
Averaging weights leads to wider optima and better generalization
P Izmailov, AG Wilson, D Podoprikhin, D Vetrov, and T Garipov. Averaging weights leads to wider optima and better generalization. In34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, pp. 876–885,
2018
-
[6]
Time-llm: Time series forecasting by reprogramming large language models
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y Zhang, Xiaoming Shi, Pin-Yu Chen, Yux- uan Liang, Yuan-Fang Li, Shirui Pan, et al. Time-llm: Time series forecasting by reprogramming large language models. InThe Twelfth International Conference on Learning Representations. 12 Published as a conference paper at ICLR 2026 Nitish Shirish Keskar, Dheevat...
Pith/arXiv arXiv 2026
-
[7]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
-
[8]
Sundial: A family of highly capable time series foundation models.arXiv preprint arXiv:2502.00816,
Yong Liu, Guo Qin, Zhiyuan Shi, Zhi Chen, Caiyin Yang, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Sundial: A family of highly capable time series foundation models.arXiv preprint arXiv:2502.00816,
-
[9]
Self-adaptive scale handling for forecasting time series with scale hetero- geneity
Xu Zhang, Zhengang Huang, Yunzhi Wu, Xun Lu, Erpeng Qi, Yunkai Chen, Zhongya Xue, Peng Wang, and Wei Wang. Self-adaptive scale handling for forecasting time series with scale hetero- geneity. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7485–7489. IEEE,
2024
-
[10]
Multi-period learning for financial time series forecasting
13 Published as a conference paper at ICLR 2026 Xu Zhang, Zhengang Huang, Yunzhi Wu, Xun Lu, Erpeng Qi, Yunkai Chen, Zhongya Xue, Qitong Wang, Peng Wang, and Wei Wang. Multi-period learning for financial time series forecasting. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pp. 2848–2859, 2025a. Xu Zhang, P...
arXiv 2026
-
[11]
14 Published as a conference paper at ICLR 2026 A TECHNICALAPPENDICES ANDSUPPLEMENTARYMATERIAL A.1 RELATED WORKS Fine-tuning large time series models.Most works focus on designing pre-training architecture and collecting large-scale time series data (Das et al., 2024; Goswami et al., 2024; Woo et al., 2024b; Liu et al.,
2026
-
[12]
TimeLLM (Jin et al.) aligns the text prompt with time series to enhance prediction
encodes time series into numerical tokens to utilize LLMs for time series forecasting. TimeLLM (Jin et al.) aligns the text prompt with time series to enhance prediction. These methods demonstrate the potential of LLMs for time series analysis.Another categoryincludes pre-trained models on large-scale time series. Moirai (Woo et al., 2024b), an encoder-on...
2024
-
[13]
conducts GPT-style pre-training on the carefully processed and collected UTSD dataset and has achieved advanced accuracy on various tasks, including forecasting (Zhang et al., 2026b;c; 2025c), imputation (Zhang et al., 2026a), and anomaly detection (Liu et al., 2024; Zhang et al., 2025b). A.2 PYTORCH CODES TO SMOOTH THE LOSS LANDSCAPE OF THE PRETRAINEDLTS...
2024
-
[14]
By combining the strengths of the randomly initialized LTSM (good trainability with a smoother loss landscape) and the pretrained LTSM (good pretrained knowledge), the convergence of the smoothed LTSM can be improved during fine-tuning. A.3 MORE DETAILS ABOUT REPRODUCING PAPER RESULTS Datasets.In forecasting and imputation, we conduct extensive experiment...
2024
-
[15]
" " model1 : pre − t r a i n e d LTSM, model2 : randomly i n i t i a l i z e d LTSM
for anomaly detection. 15 Published as a conference paper at ICLR 2026 Algorithm 1:Smoothing the loss landscape of the pre-trained LTSM for fine-tuning defSmoothing_Landscape ( model1 , model2 ) : " " " model1 : pre − t r a i n e d LTSM, model2 : randomly i n i t i a l i z e d LTSM" " " f o rparam1 , param2i n z i p( model1 . p a r a m e t e r s ( ) , mod...
2026
-
[16]
google/timesfm-2.0-500m-pytorch
Based on the limited computing resources and settings supported by each model, the input lengths for MOMENT and TimesFM are 512 and 256, while the forecast lengths are 96, and 128, respectively. Following Timer (Liu et al., 2024), the fine-tuning epochs are fixed at 10, and we report the best metric in all epochs. The learning rate is 3e-5 and the optimiz...
2024
-
[17]
Hourly These datasets used in this paper are extensively used for TSF algorithm evaluation, including exchange rate forecasting in the financial field, electricity consumption forecasting in the energy field, climate parameter forecasting in the weather domain, and machine parameter (e.g., loads and oil temperature) forecasting in the industrial field: • ...
2012
-
[18]
All datasets can be downloaded from the link11
• Traffic10 dataset contains the occupation rate of freeway systems in California, USA. All datasets can be downloaded from the link11. A.5 ADDITIONAL EXPERIMENT RESULTS AND DISCUSSIONS The experiments in the appendix serve as supplements to those in the main paper, including complete standard deviations, MAE results, and interpolation experiments. All fi...
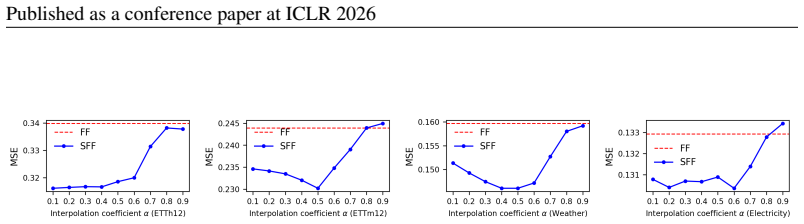
2026
-
[19]
As reported in Table 10, our approach outperforms LoRA. This is reasonable: LoRA trades full fine-tuning for a low-rank constraint, achieving appealing parameter efficiency, yet this restriction can limit the model’s fine-tuning capacity. Comparison with popular optimization strategies.We further compare our method with several widely used optimization st...
2019
-
[20]
flat” and “sharp
We independently run four times with four random seeds to enhance the solidity of the results and report the mean value and standard deviation. Exchange ETTh1 ETTh2 ETTm1 ETTm2 Weather Original full fine-tuning 0.09±0.0007 0.367±0.0027 0.304±0.0049 0.312±0.0008 0.176±0.0013 0.158±0.0012 LoRA 0.122±0.0003 0.418±0.0005 0.304±0.0006 0.401±0.0019 0.197±0.0001...
2026
-
[21]
“-” indicates that the preprocessed dataset is not included (Chronos) or out of memory (Sundial). MOIRAI +Smooth Chronos +Smooth TTMs +Smooth Sundial +Smooth ETTh1 0.4390.447 - - 0.4210.424 0.4370.453 ETTh2 0.3860.4 - - 0.4040.408 0.4090.417 ETTm1 0.6010.603 - - 0.4350.439 0.4090.417 ETTm2 0.4070.438 - - 0.4090.41 0.3970.408 Weather 0.3990.424 - - 0.3280....
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.