Dream-Tac: A Unified Tactile World Action Model for Contact-Rich Robot Manipulation
Pith reviewed 2026-06-27 18:15 UTC · model grok-4.3
The pith
Dream-Tac jointly models actions with future visual and tactile observations to raise accuracy in contact-rich robot manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
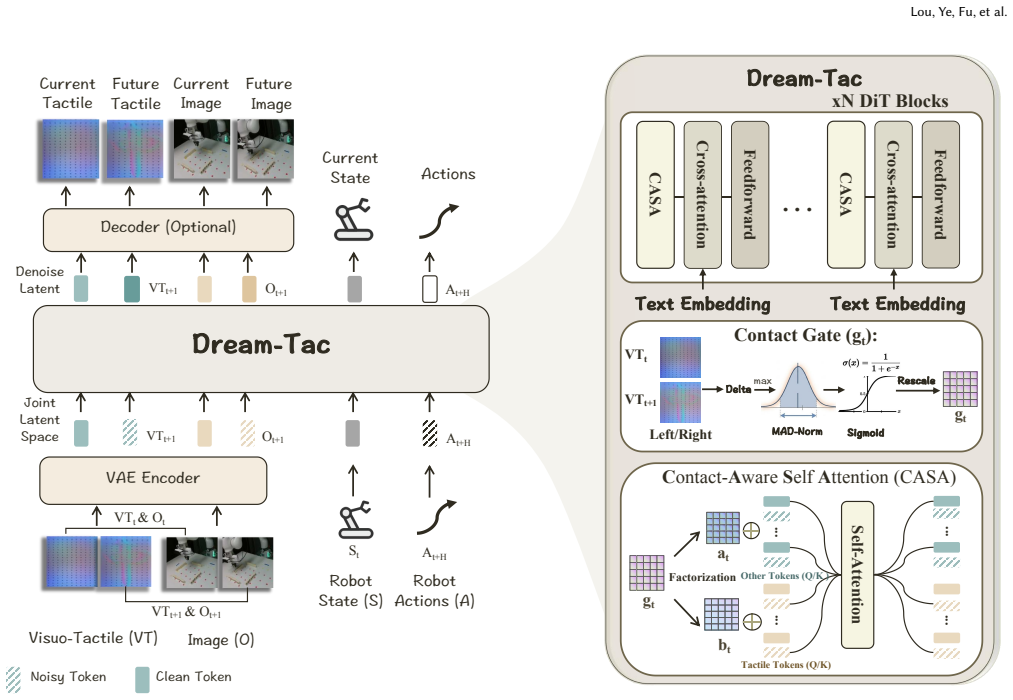
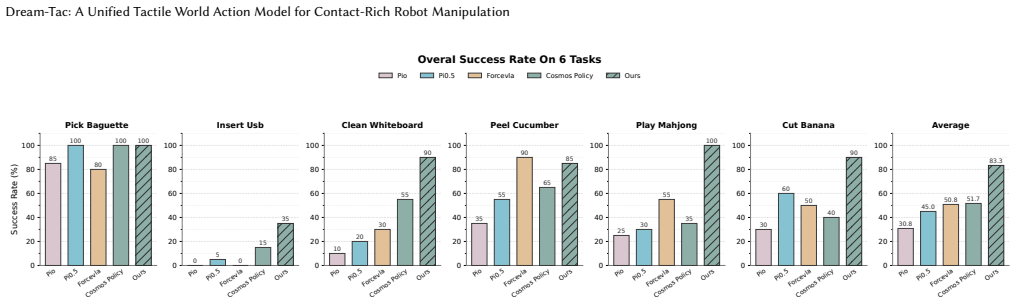
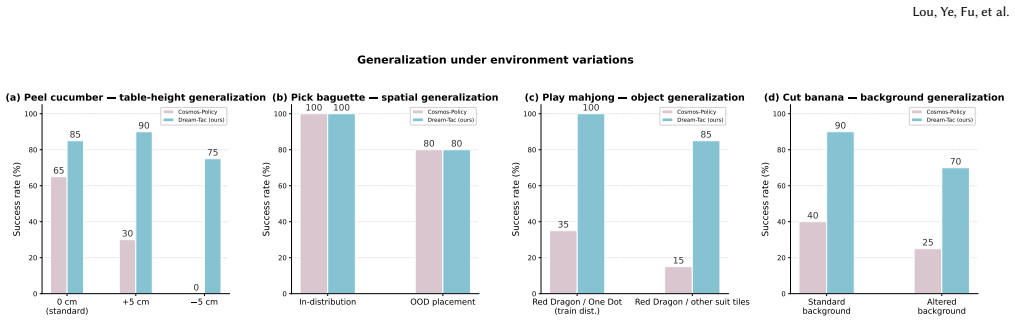
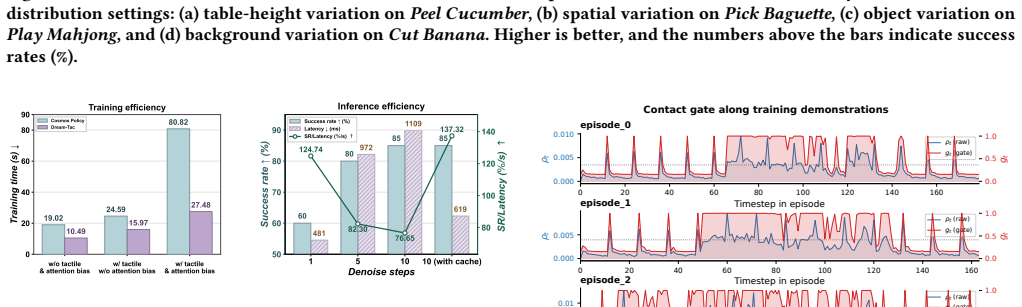
Dream-Tac is a unified tactile world action model that jointly models actions, future visual observations, and tactile dynamics. It does so through contact-gated visuotactile fusion to selectively integrate tactile signals and a contact-aware attention bias to regulate cross-modal interactions. The approach delivers a 31.7 percent average improvement in action accuracy across six contact-rich manipulation tasks while supporting real-time use via dual-level acceleration that achieves up to 2.9 times faster training and 1.8 times faster inference.
What carries the argument
Contact-gated visuotactile fusion, which selectively integrates tactile signals, together with contact-aware attention bias, which regulates cross-modal interactions during manipulation.
If this is right
- Action generation can be guided by anticipated tactile dynamics in addition to visual observations.
- The accuracy gains apply across six distinct contact-rich manipulation tasks.
- Dual-level acceleration preserves the fused attention path while delivering up to 2.9 times faster training and 1.8 times faster inference.
- Real-time deployment on contact-rich tasks becomes feasible without separate vision and touch pipelines.
Where Pith is reading between the lines
- The model could reduce the need for high-frequency force-torque sensors if the learned tactile predictions prove sufficiently accurate.
- Similar contact-aware mechanisms might apply to other modalities such as audio when tasks involve audible contact events.
- Performance on tasks with varying contact forces or object properties would reveal the robustness limits of the gating and bias components.
Load-bearing premise
The contact-gated fusion and contact-aware attention bias mechanisms capture the critical physical interaction cues needed for the reported accuracy gains.
What would settle it
An ablation study on the same six tasks that removes the contact-gated fusion and contact-aware attention bias and measures whether the 31.7 percent accuracy improvement disappears would directly test the central claim.
Figures





read the original abstract
World action models inherit the predictive capability of world models, enabling action generation to be guided by anticipated future observations. However, they rely primarily on vision and often fail in contact-rich manipulation, where critical cues arise from physical interaction. In this paper, we propose Dream-Tac, a unified Tactile-World Action Model that jointly models actions, future visual observations, and tactile dynamics. Specifically, Dream-Tac introduces (i) contact-gated visuotactile fusion to selectively integrate tactile signals and (ii) a contact-aware attention bias to better regulate cross-modal interactions during manipulation. To support real-time deployment, we further design a dual-level acceleration strategy, reformulating the contact-aware bias to preserve the fused attention path during training and introducing cache-based diffusion acceleration at inference, achieving up to 2.9$\times$ faster training and 1.8$\times$ faster inference. Across six contact-rich manipulation tasks, Dream-Tac improves action accuracy by 31.7\% on average, demonstrating the effectiveness of unified visuotactile world modeling.Code is available at https://github.com/LYFCLOUDFAN/Dream-Tac.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dream-Tac, a unified tactile-world action model for contact-rich robot manipulation. It jointly models actions, future visual observations, and tactile dynamics via contact-gated visuotactile fusion and contact-aware attention bias, plus a dual-level acceleration strategy (reformulated bias for training and cache-based diffusion at inference) that yields up to 2.9× faster training and 1.8× faster inference. The central empirical claim is a 31.7% average improvement in action accuracy across six contact-rich tasks.
Significance. If the reported gains are supported by proper controls, this could meaningfully advance world-model approaches in robotics by incorporating tactile dynamics for physical interaction, addressing a known limitation of vision-only models in contact-rich settings.
major comments (1)
- [Abstract] Abstract: the central claim of a 31.7% average accuracy improvement cannot be assessed because no information is supplied on the baselines, number of trials, error bars, statistical tests, or whether the evaluation protocol was fixed before seeing results.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify the presentation of our results. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 31.7% average accuracy improvement cannot be assessed because no information is supplied on the baselines, number of trials, error bars, statistical tests, or whether the evaluation protocol was fixed before seeing results.
Authors: We agree that the abstract, as currently written, does not contain sufficient information on the evaluation protocol to allow the 31.7% claim to be assessed in isolation. The manuscript body (Section 4) reports the six tasks, the specific baselines compared, results aggregated over 5 random seeds with standard deviations, and the fixed evaluation protocol (including task definitions and success metrics) that was established prior to running the final experiments. To make the central claim more self-contained and address the referee's concern directly, we will revise the abstract to include a concise statement of the evaluation setup (number of tasks, trials per task, and reporting of variability). revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an empirical ML contribution proposing architectural components (contact-gated fusion, contact-aware attention bias) and reporting task accuracy gains from experiments. No derivation, prediction, or first-principles result is claimed that reduces by construction to fitted inputs or self-citations. The abstract and referenced full text contain no equations or steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Tactile-WAM: Touch-Aware World Action Model with Tactile Asymmetric Attention
Tactile-WAM with TAAM improves mean success rate by 38.9% overall and 86% on contact-rich tasks on ManiFeel by using VideoClean mask and touch-aware bias to prevent tactile pollution in world action models.
Reference graph
Works this paper leans on
-
[1]
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, et al. 2025. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575(2025)
Pith/arXiv arXiv 2025
-
[2]
Nvidia Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, et al
-
[3]
https://api.semanticscholar.org/CorpusID:281725645
World Simulation with Video Foundation Models for Physical AI.ArXiv abs/2511.00062 (2025). https://api.semanticscholar.org/CorpusID:281725645
Pith/arXiv arXiv 2025
-
[4]
Marina Y Aoyama, Sethu Vijayakumar, and Tetsuya Narita. 2025. Few-shot transfer of tool-use skills using human demonstrations with proximity and tactile sensing.IEEE Robotics and Automation Letters(2025)
2025
-
[5]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, et al
-
[6]
arXiv:2506.09985 [cs.AI] https://arxiv.org/abs/2506.09985
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning. arXiv:2506.09985 [cs.AI] https://arxiv.org/abs/2506.09985
-
[7]
Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, et al. 2025. Cosmos- reason1: From physical common sense to embodied reasoning.arXiv preprint arXiv:2503.15558(2025)
Pith/arXiv arXiv 2025
-
[8]
Jianxin Bi, Kevin Yuchen Ma, Ce Hao, Mike Zheng Shou, and Harold Soh. 2025. Vla-touch: Enhancing vision-language-action models with dual-level tactile feed- back.arXiv preprint arXiv:2507.17294(2025)
arXiv 2025
-
[9]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, et al. 2024. 𝜋0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164(2024)
Pith/arXiv arXiv 2024
-
[10]
Roberto Calandra, Andrew Owens, Dinesh Jayaraman, Justin Lin, Wenzhen Yuan, et al. 2018. More than a feeling: Learning to grasp and regrasp using vision and touch.IEEE Robotics and Automation Letters3, 4 (2018), 3300–3307
2018
-
[11]
Jun Cen, Siteng Huang, Yuqian Yuan, Kehan Li, Hangjie Yuan, et al . 2025. Rynnvla-002: A unified vision-language-action and world model.arXiv preprint arXiv:2511.17502(2025)
Pith/arXiv arXiv 2025
-
[12]
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, et al
-
[13]
Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539(2025)
Pith/arXiv arXiv 2025
-
[14]
Zhengxue Cheng, Yiqian Zhang, Wenkang Zhang, Haoyu Li, Keyu Wang, et al
-
[15]
Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing.arXiv preprint arXiv:2508.08706(2025)
arXiv 2025
-
[16]
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, et al. 2025. Wow: Towards a world omniscient world model through embodied interaction.arXiv preprint arXiv:2509.22642(2025)
arXiv 2025
-
[17]
Tri Dao. 2024. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. InInternational Conference on Learning Representations (ICLR)
2024
-
[18]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS)
2022
-
[19]
Siyuan Dong, Devesh K Jha, Diego Romeres, Sangwoon Kim, Daniel Nikovski, et al. 2021. Tactile-rl for insertion: Generalization to objects of unknown geom- etry. In2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 6437–6443
2021
-
[20]
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, et al . 2023. Learn- ing universal policies via text-guided video generation.Advances in neural information processing systems36 (2023), 9156–9172
2023
-
[21]
Yankai Fu, Qiuxuan Feng, Ning Chen, Zichen Zhou, Mengzhen Liu, et al. 2025. Cordvip: Correspondence-based visuomotor policy for dexterous manipulation in real-world.arXiv preprint arXiv:2502.08449(2025)
arXiv 2025
-
[22]
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. 2019. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603(2019)
Pith/arXiv arXiv 2019
-
[23]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. 2023. Mas- tering diverse domains through world models.arXiv preprint arXiv:2301.04104 (2023)
Pith/arXiv arXiv 2023
-
[24]
Liang Heng, Haoran Geng, Kaifeng Zhang, Pieter Abbeel, and Jitendra Malik
-
[25]
ViTacFormer: Learning cross-modal representation for visuo-tactile dex- terous manipulation.arXiv preprint arXiv:2506.15953(2025)
Pith/arXiv arXiv 2025
-
[26]
Carolina Higuera, Sergio Arnaud, Byron Boots, Mustafa Mukadam, Fran- cois Robert Hogan, and Franziska Meier. 2026. Visuo-Tactile World Models. arXiv preprint arXiv:2602.06001(2026)
arXiv 2026
-
[27]
Carolina Higuera, Akash Sharma, Taosha Fan, Chaithanya Krishna Bodduluri, By- ron Boots, et al. 2025. Tactile beyond pixels: Multisensory touch representations for robot manipulation. InConference on Robot Learning. PMLR, 105–123
2025
-
[28]
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, et al
-
[29]
Video prediction policy: A generalist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803(2024)
Pith/arXiv arXiv 2024
-
[30]
Jialei Huang, Shuo Wang, Fanqi Lin, Yihang Hu, Chuan Wen, et al. 2025. Tactile- VLA: unlocking vision-language-action model’s physical knowledge for tactile generalization.arXiv preprint arXiv:2507.09160(2025)
arXiv 2025
-
[31]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dha- balia, et al . [n. d.]. 𝜋0. 5: a vision-language-action model with open-world generalization, 2025.URL https://arxiv. org/abs/2504.160541, 2 ([n. d.]), 3. Lou, Ye, Fu, et al
Pith/arXiv arXiv 2025
-
[32]
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, et al. 2026. Cosmos policy: Fine-tuning video models for visuomotor control and planning. arXiv preprint arXiv:2601.16163(2026)
Pith/arXiv arXiv 2026
-
[33]
Jinzhou Li, Tianhao Wu, Jiyao Zhang, Zeyuan Chen, Haotian Jin, et al . 2025. Adaptive visuo-tactile fusion with predictive force attention for dexterous ma- nipulation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 3232–3239
2025
-
[34]
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, et al. 2026. Causal World Modeling for Robot Control.arXiv preprint arXiv:2601.21998(2026)
Pith/arXiv arXiv 2026
-
[35]
Qiang Li, Oliver Kroemer, Zhe Su, Filipe Fernandes Veiga, Mohsen Kaboli, et al
-
[36]
A review of tactile information: Perception and action through touch.IEEE Transactions on Robotics36, 6 (2020), 1619–1634
2020
-
[37]
Rui Li, Robert Platt, Wenzhen Yuan, Andreas Ten Pas, Nathan Roscup, et al. 2014. Localization and manipulation of small parts using gelsight tactile sensing. In 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 3988–3993
2014
-
[38]
Yue Liao, Pengfei Zhou, Siyuan Huang, Donglin Yang, Shengcong Chen, et al
-
[39]
Genie envisioner: A unified world foundation platform for robotic manip- ulation.arXiv preprint arXiv:2508.05635(2025)
Pith/arXiv arXiv 2025
-
[40]
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, et al . 2024. Timestep Embedding Tells: It’s Time to Cache for Video Diffusion Model.arXiv preprint arXiv:2411.19108(2024)
arXiv 2024
-
[41]
Yunfan Lou, Xiaowei Chi, Xiaojie Zhang, Zezhong Qian, Chengxuan Li, Rongyu Zhang, Yaoxu Lyu, Guoyu Song, Chuyao Fu, Haoxuan Xu, Pengwei Wang, and Shanghang Zhang. 2026. Mask World Model: Predicting What Matters for Robust Robot Policy Learning. arXiv:2604.19683 [cs.RO] https://arxiv.org/abs/ 2604.19683
Pith/arXiv arXiv 2026
-
[42]
Daolin Ma, Elliott Donlon, Siyuan Dong, and Alberto Rodriguez. 2019. Dense tactile force estimation using GelSlim and inverse FEM. In2019 international conference on robotics and automation (ICRA). IEEE, 5418–5424
2019
-
[44]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[45]
Marsela Polic, Ivona Krajacic, Nathan Lepora, and Matko Orsag. 2019. Convolu- tional autoencoder for feature extraction in tactile sensing.IEEE Robotics and Automation Letters4, 4 (2019), 3671–3678
2019
-
[46]
Haozhi Qi, Brent Yi, Sudharshan Suresh, Mike Lambeta, Yi Ma, et al. 2023. General in-hand object rotation with vision and touch. InConference on Robot Learning. PMLR, 2549–2564
2023
-
[47]
Yu She, Shaoxiong Wang, Siyuan Dong, Neha Sunil, Alberto Rodriguez, et al. 2021. Cable manipulation with a tactile-reactive gripper.The International Journal of Robotics Research40, 12-14 (2021), 1385–1401
2021
-
[48]
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, et al . 2025. VideoVLA: Video Generators Can Be Generalizable Robot Manipulators. (2025). https://openreview.net/forum?id=UPHlqbZFZB
2025
-
[49]
HJ Terry Suh, Naveen Kuppuswamy, Tao Pang, Paul Mitiguy, Alex Alspach, et al
-
[50]
In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Seed: Series elastic end effectors in 6d for visuotactile tool use. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 4684–4691
-
[51]
Haixu Wu, Minghao Guo, Yuezhou Ma, Yuanxu Sun, Jianmin Wang, et al. 2025. FlashBias: Fast Computation of Attention with Bias. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. https://openreview.net/ forum?id=7L4NvUtZY3
2025
-
[52]
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, et al. 2023. Unleashing large-scale video generative pre-training for visual robot manipula- tion.arXiv preprint arXiv:2312.13139(2023)
Pith/arXiv arXiv 2023
-
[53]
Tianhao Wu, Jinzhou Li, Jiyao Zhang, Mingdong Wu, and Hao Dong. 2025. Canonical representation and force-based pretraining of 3d tactile for dexterous visuo-tactile policy learning. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 6786–6792
2025
-
[54]
Han Xue, Jieji Ren, Wendi Chen, Gu Zhang, Yuan Fang, et al. 2025. Reactive diffu- sion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation. arXiv preprint arXiv:2503.02881(2025)
arXiv 2025
-
[55]
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, et al
-
[56]
World action models are zero-shot policies.arXiv preprint arXiv:2602.15922 (2026)
Pith/arXiv arXiv 2026
-
[57]
Yifan Ye, Jun Cen, Jing Chen, and Zhihe Lu. 2025. Self-evolved Imitation Learning in Simulated World.arXiv preprint arXiv:2509.19460(2025)
arXiv 2025
-
[58]
Yifan Ye, Jiaqi Ma, Jun Cen, and Zhihe Lu. 2025. Token Expand-Merge: Training- Free Token Compression for Vision-Language-Action Models.arXiv preprint arXiv:2512.09927(2025)
arXiv 2025
-
[59]
Jiawen Yu, Hairuo Liu, Qiaojun Yu, Jieji Ren, Ce Hao, et al . 2025. Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipulation. arXiv preprint arXiv:2505.22159(2025)
arXiv 2025
-
[60]
Chaofan Zhang, Peng Hao, Xiaoge Cao, Xiaoshuai Hao, Shaowei Cui, et al. 2025. Vtla: Vision-tactile-language-action model with preference learning for insertion manipulation.arXiv preprint arXiv:2505.09577(2025)
arXiv 2025
-
[61]
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, et al. 2025. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge.arXiv preprint arXiv:2507.04447(2025)
Pith/arXiv arXiv 2025
-
[62]
Zongzheng Zhang, Haobo Xu, Zhuo Yang, Chenghao Yue, Zehao Lin, et al. 2025. Ta-vla: Elucidating the design space of torque-aware vision-language-action models.arXiv preprint arXiv:2509.07962(2025)
arXiv 2025
-
[63]
Pengfei Zhou, Liliang Chen, Shengcong Chen, Di Chen, Wenzhi Zhao, et al. 2025. Act2Goal: From World Model To General Goal-conditioned Policy.arXiv preprint arXiv:2512.23541(2025)
arXiv 2025
-
[64]
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, et al
-
[65]
Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792(2025)
Pith/arXiv arXiv 2025
-
[66]
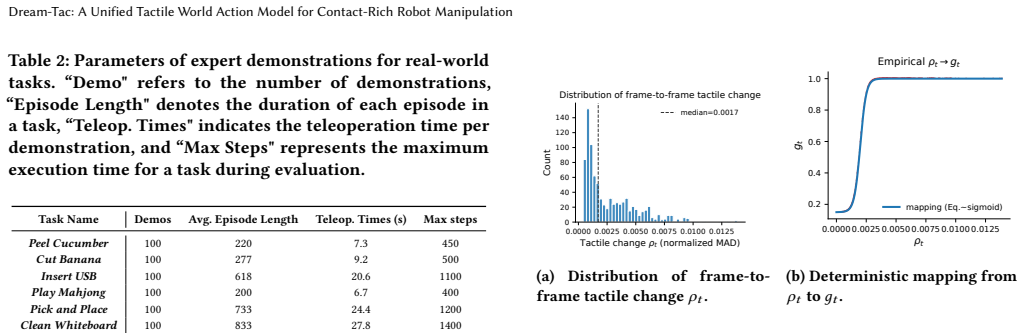
Xinyue Zhu, Binghao Huang, and Yunzhu Li. 2025. Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper.arXiv preprint arXiv:2507.15062(2025). Dream-Tac: A Unified Tactile World Action Model for Contact-Rich Robot Manipulation A Additional Experimental Details A.1 Real-World Experimental Setup Realsense D435i Realsense ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.