FF-JEPA: Long-Horizon Planning in World Models with Latent Planners
Pith reviewed 2026-06-27 16:51 UTC · model grok-4.3
The pith
An action-free latent planner decomposes long trajectories into short optimizations for goal-free planning in world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
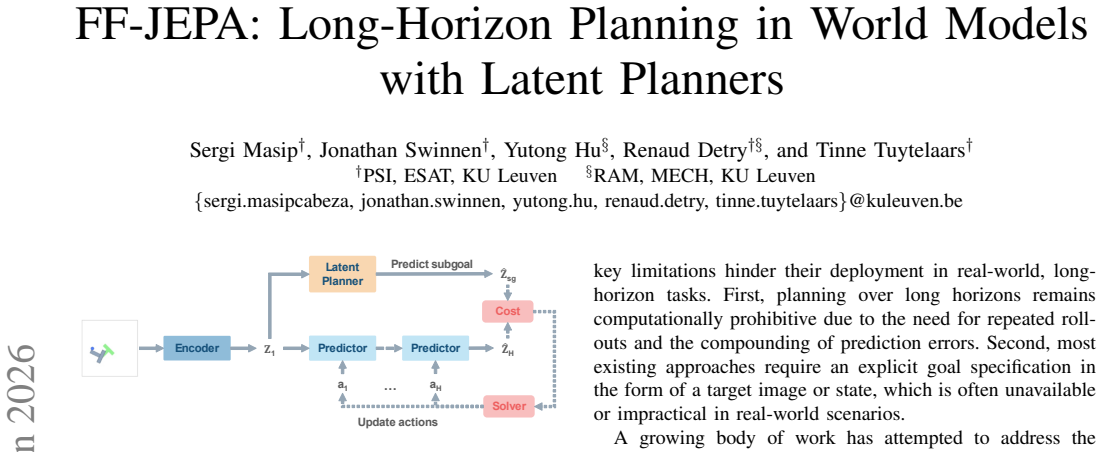
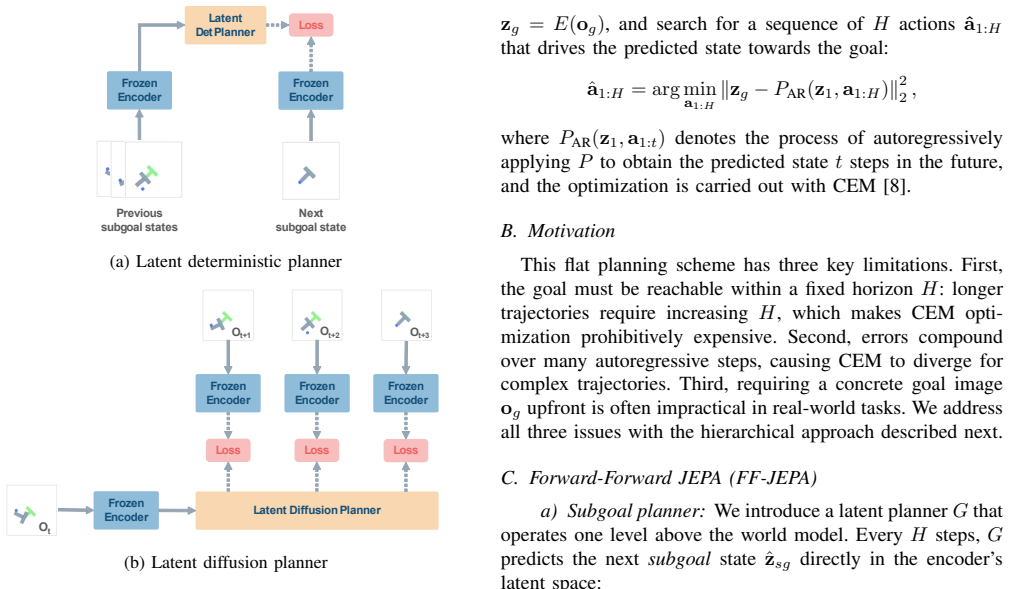
FF-JEPA augments a conventional action-conditioned forward dynamics model with an action-free latent planner; the planner outputs the next subgoal state, which then serves as the target for short-horizon optimization by the action model, allowing the overall system to solve long-horizon tasks without ever receiving an explicit goal image.
What carries the argument
The action-free latent planner, a forward dynamics model that receives only the current state and emits the next subgoal in latent space.
If this is right
- Planning cost scales with the length of short subproblems rather than the full horizon.
- Tasks without a visual goal image become solvable by treating the terminal subgoal as the implicit end condition.
- Long-horizon collapse in flat latent models is avoided by resetting the optimization target at each subgoal.
- The two-model structure separates subgoal generation from action execution, allowing independent training or fine-tuning of each.
Where Pith is reading between the lines
- The same subgoal-prediction mechanism could be inserted into other latent planners to extend their effective horizon without increasing CEM population size.
- If the latent planner is trained on the same data as the action model, the approach may reduce the need for explicit goal supervision in imitation or reinforcement settings.
- The method suggests a general template: any latent world model could gain long-horizon capability by adding an auxiliary forward model that predicts intermediate targets.
Load-bearing premise
Subgoals produced by the action-free planner must be reachable by the action-conditioned model and must compose into successful full-length trajectories.
What would settle it
Run FF-JEPA and a flat JEPA baseline on PushT tasks whose required horizon exceeds the short optimization window; if success rates remain comparable or the subgoal sequence frequently produces unreachable states, the hierarchical advantage disappears.
Figures
read the original abstract
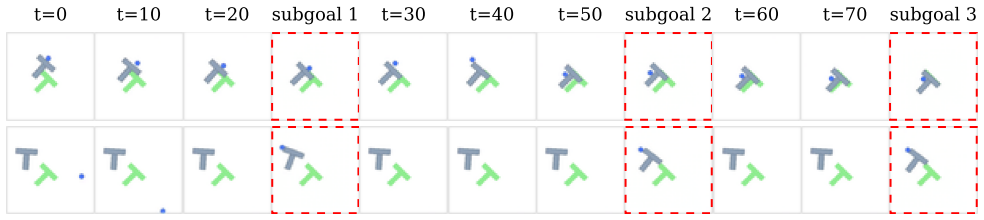
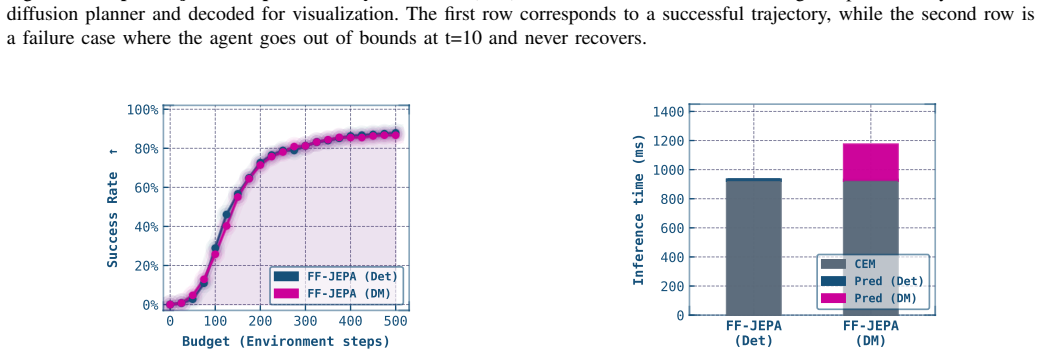
Joint Embedding Predictive Architectures (JEPAs) have shown promising world modeling capabilities, enabling planning in latent space by optimizing action trajectories using methods like the Cross-Entropy Method (CEM). These methods are, however, too computationally expensive and ineffective for long-horizon planning. Furthermore, these methods typically require an explicit image of the goal state, which is not always possible in real-world tasks. In this work, we tackle these limitations by proposing Forward-Forward-JEPA (FF-JEPA), a hierarchical approach leveraging two forward dynamics models. Alongside a standard action-conditioned forward model, we introduce an action-free latent planner that predicts the next subgoal given the current state. This approach removes the need for goal images and enables long-horizon planning by decomposing complex trajectories into a sequence of tractable, short-term optimization problems. Preliminary results on PushT demonstrate that FF-JEPA successfully overcomes flat world models' long-horizon collapse, highlighting this approach as a promising direction for goal-free planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FF-JEPA, a hierarchical JEPA variant that pairs a standard action-conditioned forward model with a new action-free latent planner. The planner predicts subgoals from the current state to decompose long-horizon planning into sequences of short-horizon CEM optimizations in latent space, removing the requirement for explicit goal images. The abstract claims that preliminary results on the PushT task show the method overcomes the long-horizon collapse exhibited by flat world models.
Significance. If the reachability of planner subgoals is enforced and the empirical claims are substantiated with metrics and controls, the hierarchical decomposition could meaningfully extend JEPA-style world models to goal-free, long-horizon settings where flat CEM planning becomes intractable.
major comments (2)
- [Abstract] Abstract: the central empirical claim that FF-JEPA 'successfully overcomes flat world models' long-horizon collapse' rests on 'preliminary results on PushT' that report neither quantitative metrics, baselines, nor ablation details; without these the claim cannot be evaluated and is load-bearing for the paper's contribution.
- [Abstract] Abstract (hierarchical approach description): no training objective, consistency loss, or architectural constraint is stated that would enforce dynamic reachability between subgoals produced by the action-free latent planner and trajectories realizable by the action-conditioned forward model; absent such a mechanism the decomposition into short-horizon problems can fail even if each model is accurate in distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that FF-JEPA 'successfully overcomes flat world models' long-horizon collapse' rests on 'preliminary results on PushT' that report neither quantitative metrics, baselines, nor ablation details; without these the claim cannot be evaluated and is load-bearing for the paper's contribution.
Authors: We agree that the abstract's phrasing is too strong given the level of detail provided. The full manuscript contains quantitative success rates, comparisons against flat JEPA baselines, and ablation studies on the PushT task in the experiments section. To make the abstract self-contained and address the concern, we will revise it to report the key metrics (e.g., success rate and maximum planning horizon) while retaining the 'preliminary' qualifier. revision: yes
-
Referee: [Abstract] Abstract (hierarchical approach description): no training objective, consistency loss, or architectural constraint is stated that would enforce dynamic reachability between subgoals produced by the action-free latent planner and trajectories realizable by the action-conditioned forward model; absent such a mechanism the decomposition into short-horizon problems can fail even if each model is accurate in distribution.
Authors: The referee correctly notes that the abstract does not describe an explicit reachability mechanism. The two models are trained jointly within the JEPA framework, but no dedicated consistency term is stated. In the revision we will add and describe a reachability consistency loss that aligns planner subgoals with states reachable under the action-conditioned forward model; this will be presented in the methods section along with the updated training objective. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract and available text describe a hierarchical architecture with an action-conditioned forward model and an action-free latent planner for subgoal prediction. No equations, fitted parameters, or self-citations are presented that would make any prediction or result equivalent to its inputs by construction. The claimed long-horizon advantage is attributed to trajectory decomposition, but this does not reduce to a self-definitional step, fitted-input renaming, or load-bearing self-citation. The paper is self-contained against external benchmarks with no exhibited circular reductions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Conformal Orbit-Valid Trust Horizons for Equivariant World Models
Conformal calibration produces orbit-valid trust horizons for equivariant world models, with zero violations in 50 audits and non-vacuous certificates on 2D/3D substrates.
Reference graph
Works this paper leans on
-
[1]
stable-pretraining- v1: Foundation model research made simple.arXiv preprint arXiv:2511.19484, 2025
Randall Balestriero, Hugues Van Assel, Sami BuGhanem, and Lucas Maes. stable-pretraining- v1: Foundation model research made simple.arXiv preprint arXiv:2511.19484, 2025
arXiv 2025
-
[2]
Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[3]
Sparse imagination for efficient visual world model planning,
Junha Chun, Youngjoon Jeong, and Taesup Kim. Sparse imagination for efficient visual world model planning,
-
[4]
URL https://arxiv.org/abs/2506.01392
-
[5]
stable-worldmodel: A platform for reproducible world modeling research and evaluation, 2026
Lucas Maes, Quentin Le Lidec, Luiz Facury, Nassim Massaudi, Ayush Chaurasia, Francesco Capuano, Richard Gao, Taj Gillin, Dan Haramati, Damien Scieur, Yann LeCun, and Randall Balestriero. stable-worldmodel: A platform for reproducible world modeling research and evaluation, 2026. URL https://arxiv.org/abs/2605.21800
Pith/arXiv arXiv 2026
-
[6]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
Pith/arXiv arXiv 2026
-
[7]
Hierarchical foresight: Self- supervised learning of long-horizon tasks via visual sub- goal generation
Suraj Nair and Chelsea Finn. Hierarchical foresight: Self- supervised learning of long-horizon tasks via visual sub- goal generation. InInternational Conference on Learn- ing Representations, 2020. URL https://openreview.net/ forum?id=H1gzR2VKDH
2020
-
[8]
Scalable diffu- sion models with transformers
William Peebles and Saining Xie. Scalable diffu- sion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, October 2023
2023
-
[9]
Springer, 2004
Reuven Y Rubinstein and Dirk P Kroese.The cross- entropy method: a unified approach to combinatorial op- timization, Monte-Carlo simulation, and machine learn- ing, volume 133. Springer, 2004
2004
-
[10]
When does predictive inverse dynamics outperform behavior cloning?, 2026
Lukas Sch ¨afer, Pallavi Choudhury, Abdelhak Lemkhen- ter, Chris Lovett, Somjit Nath, Luis Franc ¸a, Matheus Ribeiro Furtado de Mendonc ¸a, Alex Lamb, Riashat Is- lam, Siddhartha Sen, John Langford, Katja Hofmann, and Sergio Valcarcel Macua. When does predictive inverse dynamics outperform behavior cloning?, 2026. URL https://arxiv.org/abs/2601.21718
Pith/arXiv arXiv 2026
-
[11]
Latent diffusion planning for imitation learning
Amber Xie, Oleh Rybkin, Dorsa Sadigh, and Chelsea Finn. Latent diffusion planning for imitation learning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste- Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd Inter- national Conference on Machine Learning, volume 267 ofProceedings of Machine Learnin...
2025
-
[12]
Hierarchical planning with latent world models,
Wancong Zhang, Basile Terver, Artem Zholus, Soham Chitnis, Harsh Sutaria, Mido Assran, Randall Balestriero, Amir Bar, Adrien Bardes, Yann LeCun, and Nicolas Ballas. Hierarchical planning with latent world models,
-
[13]
URL https://arxiv.org/abs/2604.03208
-
[14]
Disentangled robot learning via separate forward and inverse dynamics pretraining
Wenyao Zhang, Bozhou Zhang, Zekun Qi, Wenjun Zeng, Xin Jin, and Li Zhang. Disentangled robot learning via separate forward and inverse dynamics pretraining. InThe Fourteenth International Conference on Learn- ing Representations, 2026. URL https://openreview.net/ forum?id=DdrsHWobR1
2026
-
[15]
Dino-wm: World models on pre-trained visual features enable zero-shot planning
Gaoyue Zhou, Hengkai Pan, Yann Lecun, and Lerrel Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning. InInternational Conference on Machine Learning, pages 79115–79135. PMLR, 2025
2025
-
[16]
Grounding generated videos in feasible plans via world models, 2026
Christos Ziakas, Amir Bar, and Alessandra Russo. Grounding generated videos in feasible plans via world models, 2026. URL https://arxiv.org/abs/2602.01960
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.