Factors affecting ASR performance: A study using state of the art ASR models in Indic Languages
Pith reviewed 2026-06-27 15:08 UTC · model grok-4.3
The pith
Speaker traits and audio processing choices influence word error rates differently across Indic languages in zero-shot ASR evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that both cross-lingual patterns and language-specific sensitivities exist in how speaker-level and acoustic factors affect ASR word error rates in Indic languages, demonstrated through correlations observed across multiple model-dataset pairs in zero-shot evaluations on diverse Indian speech datasets.
What carries the argument
Correlation analysis between word error rate and speaker traits (average word length, speaking rate, utterance duration) together with audio factors (telephone codecs, bit depth, resampling, background noise) across model-dataset pairs.
If this is right
- Cross-lingual patterns imply that some speaker and acoustic factors degrade ASR performance similarly regardless of the specific Indic language.
- Language-specific sensitivities imply that mitigation strategies may need to be tuned differently for Hindi versus Bengali or Kannada.
- Signal processing choices such as resampling and noise handling directly shape robustness in telephone and noisy environments.
- Speaker traits like speaking rate and utterance duration provide measurable predictors of transcription difficulty across multiple models.
Where Pith is reading between the lines
- Dataset creators could prioritize balanced distributions of speaking rates and word lengths to reduce average WER.
- The same correlation approach could be applied to fine-tuned rather than zero-shot models to test whether adaptation reduces the observed sensitivities.
- Real-time systems might monitor utterance duration and background noise to trigger adaptive preprocessing before decoding.
Load-bearing premise
The chosen Indian speech datasets and zero-shot evaluation setting are representative enough of real-world Indic usage that the observed correlations between WER and speaker/acoustic factors will generalize beyond the specific model-dataset pairs tested.
What would settle it
Re-running the same models on a fresh collection of Indic recordings that shows no statistically significant correlation between WER and factors such as speaking rate or codec type would falsify the reported patterns.
Figures
read the original abstract
ASR performance varies across languages, speakers, and recording conditions, yet systematic analysis for Indic languages remain limited. We present a large-scale study of decoded outputs from multiple open-source ASR models evaluated on diverse Indian speech datasets in zero-shot settings. We analyze linguistic, speaker-level, and acoustic factors across Hindi, Bengali, Kannada, Telugu, and Marathi. We examine correlations between WER and speaker traits such as average word length, speaking rate, and utterance duration across multiple model dataset pairs. For Hindi, we further analyze audio factors including telephone codecs, bit depth, resampling, and background noise. Results reveal both cross lingual patterns and language-specific sensitivities, showing how speaker behavior and signal processing choices affect ASR robustness in real world Indic scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a large-scale observational study evaluating multiple open-source ASR models on Indic-language speech datasets (Hindi, Bengali, Kannada, Telugu, Marathi) in zero-shot settings. It reports correlations between word error rate (WER) and speaker-level factors (average word length, speaking rate, utterance duration) across model-dataset pairs, plus acoustic factors (telephone codecs, bit depth, resampling, background noise) for Hindi. The central claim is the existence of both cross-lingual patterns and language-specific sensitivities in how these factors affect ASR robustness.
Significance. If the reported correlations prove statistically robust, the work supplies useful descriptive data on ASR behavior in under-studied Indic languages and could guide targeted data collection or preprocessing choices. The multi-model, multi-dataset design is a strength that increases the chance that observed patterns are not artifacts of a single system.
major comments (2)
- [Methods / Results] Methods / Results sections: No details are provided on the statistical procedures used to compute or assess the reported correlations (e.g., Pearson vs. Spearman, handling of multiple model-dataset pairs, multiple-testing correction, error bars, or data-exclusion rules). These omissions are load-bearing for the claim that 'patterns' and 'sensitivities' have been identified.
- [Discussion] Discussion: The paper does not examine whether the chosen Indian speech datasets and zero-shot protocol are representative of real-world Indic usage; this directly affects the generalizability of the observed WER-factor correlations and is the central assumption underlying the practical implications.
minor comments (2)
- [Abstract] Abstract: 'cross lingual' should be hyphenated as 'cross-lingual'; 'state of the art' should be 'state-of-the-art'.
- [Abstract] Abstract: 'remain limited' should read 'remains limited' for subject-verb agreement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical details and generalizability. We address both major comments below and will revise the manuscript to incorporate clarifications and additional discussion.
read point-by-point responses
-
Referee: [Methods / Results] Methods / Results sections: No details are provided on the statistical procedures used to compute or assess the reported correlations (e.g., Pearson vs. Spearman, handling of multiple model-dataset pairs, multiple-testing correction, error bars, or data-exclusion rules). These omissions are load-bearing for the claim that 'patterns' and 'sensitivities' have been identified.
Authors: We agree that the statistical procedures require explicit documentation. In the revised manuscript, the Methods section will specify: (1) Pearson correlation for normally distributed variables and Spearman rank correlation otherwise, selected via Shapiro-Wilk tests; (2) correlations computed per model-dataset pair with results aggregated only when consistent across pairs; (3) Bonferroni correction applied for multiple comparisons across the five languages and three speaker factors; (4) 95% confidence intervals shown as error bars on all reported correlation plots; and (5) explicit exclusion rules (utterances <1 s or with >50% silence removed, affecting <3% of data). These additions will directly support the claims of cross-lingual patterns and language-specific sensitivities. revision: yes
-
Referee: [Discussion] Discussion: The paper does not examine whether the chosen Indian speech datasets and zero-shot protocol are representative of real-world Indic usage; this directly affects the generalizability of the observed WER-factor correlations and is the central assumption underlying the practical implications.
Authors: We acknowledge the need for explicit discussion of representativeness. The revised Discussion will add a dedicated paragraph noting that the datasets (Common Voice, IndicTTS, and others) are the largest publicly available resources for these languages and have been used in prior Indic ASR benchmarks, while clarifying that they primarily capture read and prompted speech rather than spontaneous conversational or heavily accented dialects. We will also state that the zero-shot protocol reflects current practical deployment scenarios for open-source models but does not include fine-tuning or domain adaptation; limitations on coverage of telephone vs. studio conditions and background noise diversity will be listed. This addition addresses generalizability without changing the reported empirical findings. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely observational empirical study that evaluates multiple ASR models on Indic language datasets in zero-shot settings and reports correlations between WER and speaker/acoustic factors. No mathematical derivations, fitted parameters presented as predictions, or load-bearing self-citations are present in the abstract or described scope. All claims rest on direct experimental outputs and statistical correlations computed from the data, with no reduction of results to inputs by construction or renaming of known patterns as novel derivations. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The diverse Indian speech datasets used are representative of real-world conditions for the five languages studied.
Reference graph
Works this paper leans on
-
[1]
Despite these advances, robust performance across linguisti- cally diverse and under-resourced languages remains challeng- ing [4]
Introduction Automatic Speech Recognition (ASR) has advanced signif- icantly due to deep learning methods such as Connection- ist Temporal Classification (CTC) [1], attention-based en- coder–decoder models [2], and Transformer architectures [3]. Despite these advances, robust performance across linguisti- cally diverse and under-resourced languages remain...
-
[2]
Factors affecting ASR performance: A study using state of the art ASR models in Indic Languages
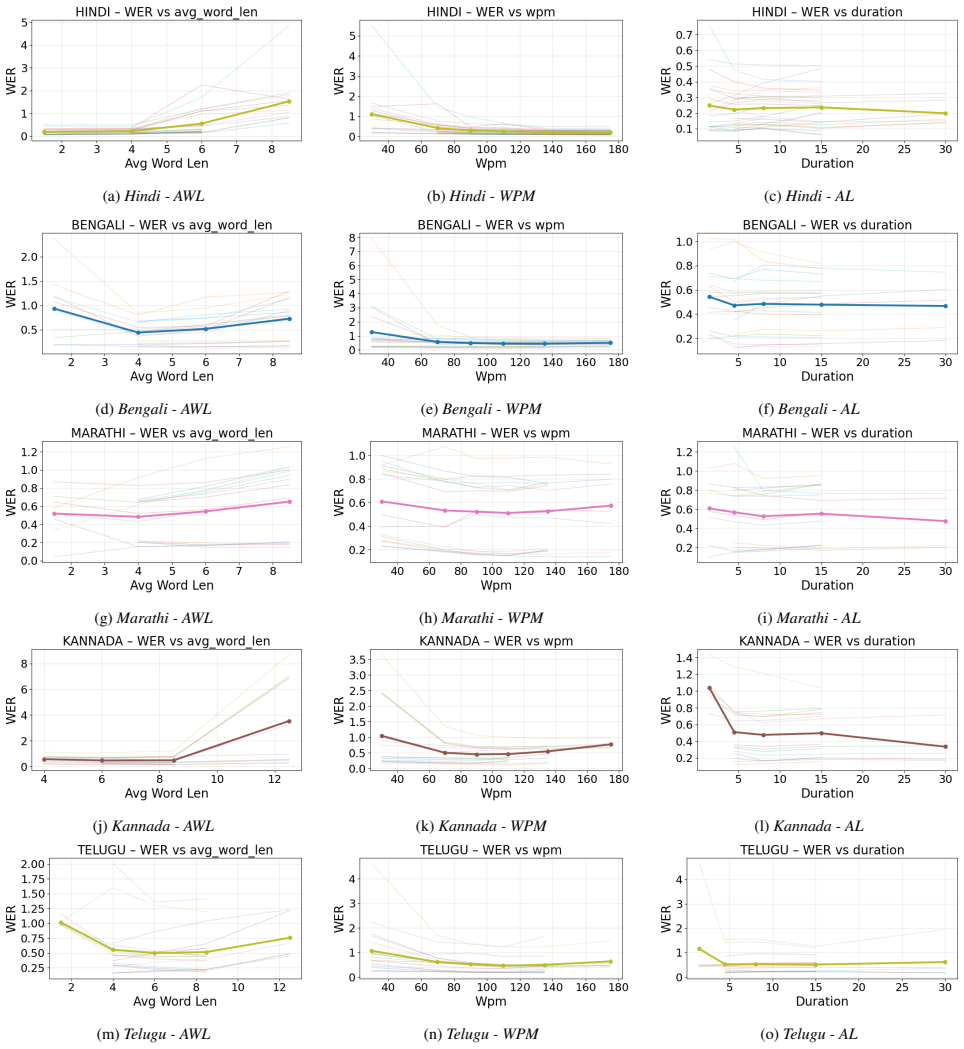
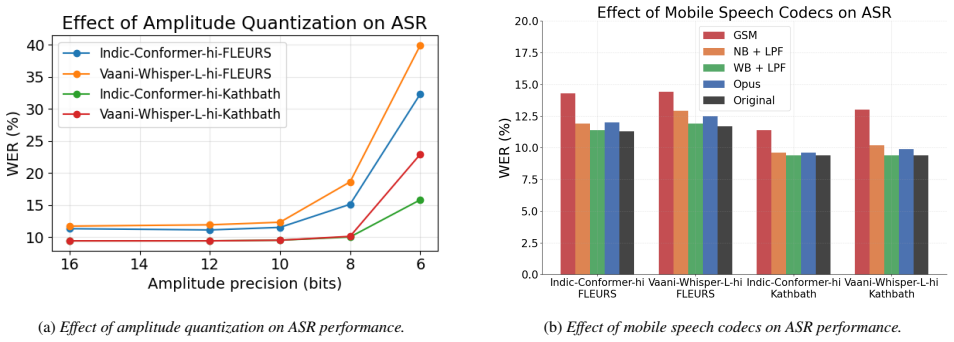
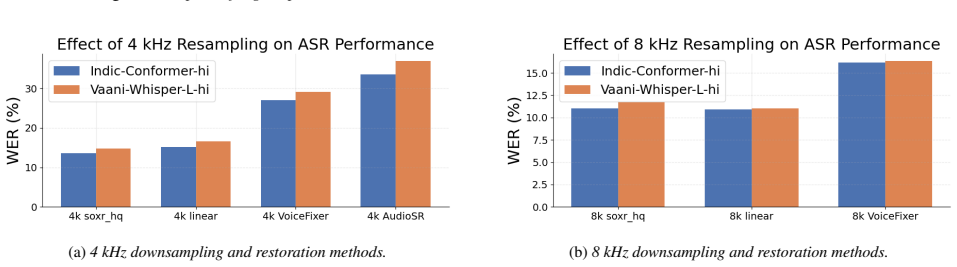
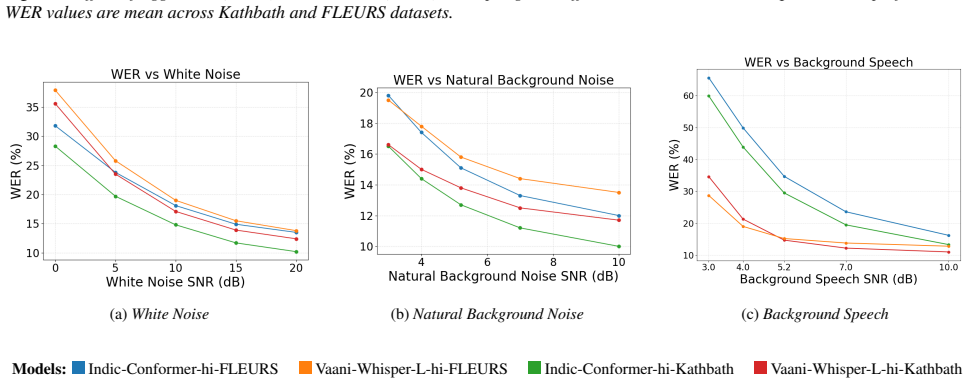
Experimental Setup 2.1. Experimental Factors We analyze both speaker-level and audio-level factors that are hypothesized to influence ASR performance. All analyses are conducted using Word Error Rate (WER) as the primary evalu- ation metric. 2.1.1. Speaker-Level Factors Speaker-level factors are derived from reference transcriptions and capture linguistic...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Prior to scoring, both hypotheses and ref- erences are normalized by removing punctuation, tags, special tokens, and other non-verbal artifacts
Results and Observations We evaluate the aforementioned open-source ASR models on the described Indic speech datasets using word error rate (WER) as the primary metric. Prior to scoring, both hypotheses and ref- erences are normalized by removing punctuation, tags, special tokens, and other non-verbal artifacts. 3.1. Effect of Speaker-Level Factors We exa...
-
[4]
Conclusion We present a unified analysis of speaker- and audio-level factors affecting Indic ASR under zero-shot settings, with direct im- plications for telephony and real-world deployment. Speaker- level trends show consistent WER degradation as conditions worsen, with similar trajectories across models and datasets, in- dicating systematic rather than ...
-
[5]
Con- nectionist temporal classification: Labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: Labelling unsegmented se- quence data with recurrent neural networks,” inProceedings of the 23rd International Conference on Machine Learning (ICML). ACM, 2006, pp. 369–376
2006
-
[6]
Speech recognition with deep recurrent neural networks,
A. Graves, A.-r. Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks,” inProc. ICASSP, 2013, pp. 6645–6649
2013
-
[7]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017, pp. 5998–6008
2017
-
[8]
Massively multilingual asr: 50 languages, 1 model, 1 billion parameters,
V . Pratapet al., “Massively multilingual asr: 50 languages, 1 model, 1 billion parameters,” inInterspeech, 2020
2020
-
[10]
Available: https://arxiv.org/abs/2107.07402
[Online]. Available: https://arxiv.org/abs/2107.07402
-
[11]
An overview of noise-robust automatic speech recognition,
J. Li, L. Deng, Y . Gong, and R. Haeb-Umbach, “An overview of noise-robust automatic speech recognition,”IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 22, no. 4, pp. 745–777, 2014
2014
-
[12]
Indic speech recognition: Chal- lenges and approaches,
M. Jha, A. Mittal, and S. Dey, “Indic speech recognition: Chal- lenges and approaches,” inProc. SLTU, 2018
2018
-
[13]
Acoustic modeling for indian lan- guages,
K. S. Rao and H. A. Murthy, “Acoustic modeling for indian lan- guages,” inProc. INTERSPEECH, 2016, pp. 2726–2730
2016
-
[14]
Multilingual transfer learning for low-resource indian languages,
A. Singh, S. Sitaram, and A. W. Black, “Multilingual transfer learning for low-resource indian languages,” inProc. INTER- SPEECH, 2021, pp. 1917–1921
2021
-
[15]
Noise and channel ro- bust speech recognition for indian languages,
S. Banerjee, A. Ghosh, and K. S. Rao, “Noise and channel ro- bust speech recognition for indian languages,” inProc. INTER- SPEECH, 2017, pp. 2731–2735. [11]Digital cellular telecommunications system (Phase 2); Full rate speech; Transcoding, ETSI Std. GSM 06.10, 1991. [12]Transmission performance characteristics of pulse code modula- tion channels, ITU-T S...
2017
-
[16]
Definition of the opus audio codec,
J.-M. Valin, K. V os, and T. Terriberry, “Definition of the opus audio codec,” inIETF RFC 6716, 2012
2012
-
[17]
J. O. S. III,Digital Audio Resampling Home Page, 2002, stanford University, Online resource
2002
-
[18]
A. V . Oppenheim and R. W. Schafer,Discrete-Time Signal Pro- cessing. Prentice Hall, 1999
1999
-
[19]
V oice- fixer: Towards general speech restoration with neural vocoder,
H. Liu, Y . Yuan, X. Liu, Q. Kong, and M. D. Plumbley, “V oice- fixer: Towards general speech restoration with neural vocoder,” in Proc. Interspeech, 2022
2022
-
[20]
Audiosr: Versatile audio super-resolution at scale,
H. Liu, X. Liu, Q. Kong, and M. D. Plumbley, “Audiosr: Versatile audio super-resolution at scale,” inProc. ICASSP, 2023
2023
-
[21]
Indicconformer,
T. Javed and K. Bhogale, “Indicconformer,” https://ai4bharat.iitm. ac.in/areas/model/ASR/IndicConformer, 2025, accessed: 2025- 07-22
2025
-
[22]
data2vec- aqc: Search for the right teaching assistant in the teacher- student training setup,
V . S. Lodagala, S. Ghosh, and S. Umesh, “data2vec- aqc: Search for the right teaching assistant in the teacher- student training setup,” 2022. [Online]. Available: https: //arxiv.org/abs/2211.01246
-
[23]
Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, and Michael Auli
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “data2vec: A general framework for self-supervised learning in speech, vision and language,” 2022. [Online]. Available: https://arxiv.org/abs/2202.03555
-
[24]
Vaani whisper collection,
ARTPARK and IISc, “Vaani whisper collection,” https://huggingface.co/collections/ARTPARK-IISc/ vaani-whisper-67d4438f63799fb4eb94aec2, 2025, accessed: 2025-07-22
2025
- [25]
-
[26]
Shrutam-hindiasr-1.0: Hindi automatic speech recognition model,
BharatGenAI, “Shrutam-hindiasr-1.0: Hindi automatic speech recognition model,” 2025, accessed: Sep. 29,
2025
-
[27]
Available: https://huggingface.co/bharatgenai/ Shrutam-HindiASR-1.0
[Online]. Available: https://huggingface.co/bharatgenai/ Shrutam-HindiASR-1.0
-
[28]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the 40th International Conference on Machine Learning (ICML), vol. 202. PMLR, 2023, pp. 28 492–28 518. [Online]. Available: https://proceedings.mlr. press/v202/radford23a.html
2023
-
[29]
Mucs asr challenge,
MUCS, “Mucs asr challenge,” https://navana-tech.github.io/ MUCS2021/data.html, 2025, accessed: 2025-07-22
2025
-
[30]
Indicsuperb: A speech processing universal performance benchmark for indian languages,
T. Javed, K. S. Bhogale, A. Raman, A. Kunchukuttan, P. Kumar, and M. M. Khapra, “Indicsuperb: A speech processing universal performance benchmark for indian languages,” 2022. [Online]. Available: https://arxiv.org/abs/2208.11761
-
[31]
Indictts: A text-to-speech dataset for indian languages,
Speech Technology Consortium, IIT Madras, “Indictts: A text-to-speech dataset for indian languages,” 2025, accessed: 2025-09-29. [Online]. Available: https://www.iitm.ac.in/donlab/ indictts/database
2025
-
[32]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” in Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020), 2020, pp. 4211–4215
2020
-
[33]
Fleurs: Few-shot learning evaluation of universal representations of speech,
A. Conneau, M. Ma, S. Khanuja, Y . Zhang, V . Axelrod, S. Dalmia, J. Riesa, C. Rivera, and A. Bapna, “Fleurs: Few-shot learning evaluation of universal representations of speech,” arXiv preprint arXiv:2205.12446, 2022. [Online]. Available: https://arxiv.org/abs/2205.12446
-
[34]
VAANI: Capturing the language landscape for an inclusive digital India
S. Pulikodan, A. Singh, A. Basu, N. Desai, P. K. J, P. D. Bhat, R. Dharmaraju, R. Gupta, S. Udupa, S. Kumar, S. Sharma, V . Vishwakarma, V . Sanka, D. Tewari, H. Dhand, A. Kamat, S. Singh, S. Vashishth, P. Talukdar, R. Acharya, and P. K. Ghosh, “Vaani: Capturing the language landscape for an inclusive digital india,” 2026. [Online]. Available: https://arx...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
RESPIN Corpus: A read-speech corpus of 10,000+ hours in dialects of nine indian languages,
Saurabh Kumar et al, “RESPIN Corpus: A read-speech corpus of 10,000+ hours in dialects of nine indian languages,” Available at https://spiredatasets.ee.iisc.ac.in/respincorpus, 2025, open-source corpus developed by IISc RESPIN project, covering read speech across 9 Indian languages
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.