A study on the impact of region specific data on the performance of Indic ASR
Pith reviewed 2026-06-27 15:04 UTC · model grok-4.3
The pith
Fine-tuning Indic ASR models on speech from one district produces higher word error rates on other districts, with the gap correlating to geographic distance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using fine-tuning on single-district data as a controlled probe, the study shows consistent positive correlations between inter-district geographic distance and word error rate on held-out districts; the result holds across train-test pairs and two distance metrics, supporting the claim that geographically diverse speech data is required for robust Indic ASR.
What carries the argument
Single-district fine-tuning followed by cross-district evaluation, paired with correlation analysis of WER against geographic distance.
Load-bearing premise
That performance gaps between districts are driven mainly by geographic and linguistic differences rather than by differences in microphones, recording environments, or speaker demographics.
What would settle it
A replication that finds no correlation between WER and distance after matching districts on recording equipment and speaker age/gender distribution.
Figures
read the original abstract
Automatic Speech Recognition (ASR) systems are widely deployed across linguistically diverse regions, yet their ability to generalize across fine-grained geographic variation remains underexplored. We present a systematic study of cross-district ASR generalization for Indian languages, analyzing the impact of regional variation on performance. Using finetuning as a controlled probe, we train models on speech from a single district and evaluate them on other districts within the same language. We examine trends across multiple train test district pairs and quantify performance differences. To assess geographic effects, we analyze the correlation between WER and inter district distance using two distance measures. Our results show consistent correlations between geographic distance and WER, highlighting the challenges of regional generalization and the need for geographically diverse speech data in ASR development and evaluation in India.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on cross-district generalization in Indic ASR. It describes training ASR models via finetuning on speech from a single district and evaluating on other districts within the same language, then quantifying correlations between word error rate (WER) and inter-district geographic distance using two distance measures. The central claim is that consistent correlations exist, underscoring challenges in regional generalization and the need for geographically diverse training data.
Significance. If the correlations prove robust after addressing potential confounders and are supported by statistical evidence, the work would provide concrete empirical motivation for prioritizing geographic diversity in Indic ASR data collection and evaluation, addressing an underexplored aspect of generalization in multilingual, low-resource settings.
major comments (2)
- [Abstract] Abstract: The central claim of 'consistent correlations between geographic distance and WER' is presented without any quantitative results, statistical tests, error bars, data sizes, model architectures, number of districts/languages, or exclusion criteria, so the claim cannot be evaluated from the provided text.
- [Abstract] Abstract (method description): The finetuning probe is asserted to isolate geographic/linguistic variation, yet no controls or matching criteria are described for recording equipment, acoustic conditions, speaker demographics, or collection protocols across districts. If these factors covary with inter-district distance, the reported correlations would not demonstrate a geographic effect.
minor comments (1)
- [Abstract] The two distance measures used for the correlation analysis are not named or defined, which would clarify the geographic analysis.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of clarity in the abstract and potential confounding factors in the experimental design. We address each point below and have made revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'consistent correlations between geographic distance and WER' is presented without any quantitative results, statistical tests, error bars, data sizes, model architectures, number of districts/languages, or exclusion criteria, so the claim cannot be evaluated from the provided text.
Authors: We agree that the abstract as currently written does not allow direct evaluation of the central claim. The full manuscript contains these details (model architecture, dataset sizes, number of languages and districts, correlation coefficients with statistical tests, and exclusion criteria) in the methods and results sections. To address the concern, we will revise the abstract to incorporate key quantitative elements such as the number of languages and districts studied, the range of observed correlations, and reference to the statistical significance of the findings. revision: yes
-
Referee: [Abstract] Abstract (method description): The finetuning probe is asserted to isolate geographic/linguistic variation, yet no controls or matching criteria are described for recording equipment, acoustic conditions, speaker demographics, or collection protocols across districts. If these factors covary with inter-district distance, the reported correlations would not demonstrate a geographic effect.
Authors: This is a substantive concern regarding internal validity. The study relies on an existing corpus collected under a single standardized protocol across districts, which provides some uniformity in collection procedures. However, the abstract and current manuscript text do not explicitly describe matching criteria or available metadata on equipment, acoustics, or demographics. We will revise the manuscript to add a dedicated paragraph in the methods section detailing the corpus collection protocol and any available controls, and we will add a limitations subsection acknowledging that unmeasured covariates could influence the correlations. We do not have additional per-district metadata to perform explicit covariate analysis at this time. revision: partial
Circularity Check
Purely empirical study; no derivation chain or self-referential predictions
full rationale
The paper reports measured WER values from fine-tuning ASR models on single-district data and evaluating on other districts, then computes correlations with inter-district distances. No equations, fitted parameters, or derivations are present that could reduce the reported correlations to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central results are direct empirical quantities, not quantities forced by the method itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in supervised ASR fine-tuning and word error rate evaluation hold across districts
Reference graph
Works this paper leans on
-
[1]
Introduction Automatic Speech Recognition (ASR) systems have become a foundational component of voice-driven technologies, enabling applications ranging from voice assistants and transcription ser- vices to accessibility tools. Despite rapid progress driven by large-scale pretraining and multilingual modeling, ASR perfor- mance continues to vary substanti...
-
[2]
A study on the impact of region specific data on the performance of Indic ASR
Materials and Methods 2.1. Datasets The training datasets used in this study are sourced from Vaani. The Vaani dataset is a district-anchored dataset, which allows us to obtain sufficient data for each district-language pair. Table 1 provides the duration (hrs.) of the dataset for each district. We selected these five languages and their corresponding dis...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
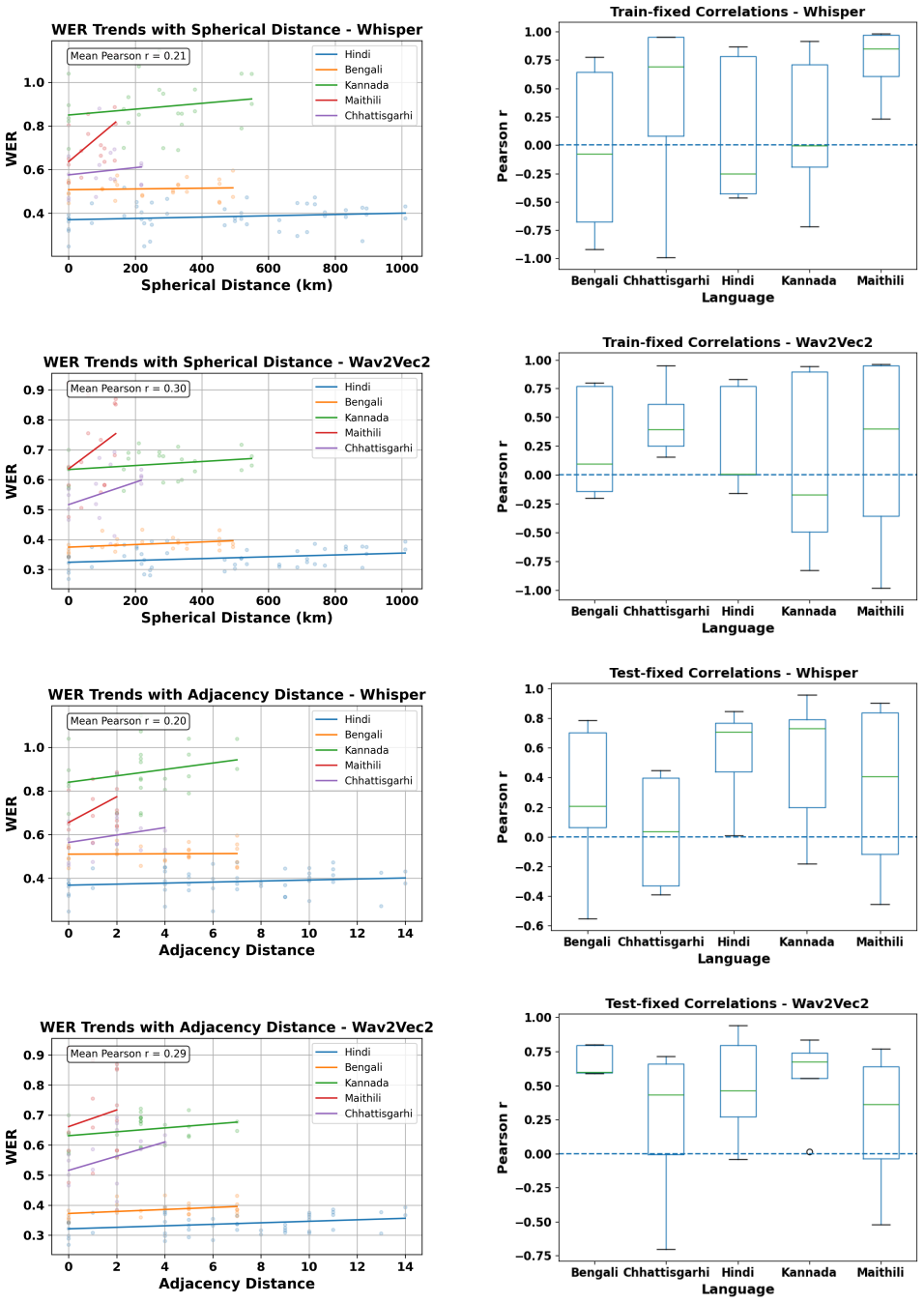
[3]
Results 3.1. Baseline vs Fine-Tuned WER Table 2 reports three evaluation settings: (i) Baseline, where the pretrained model is evaluated without fine-tuning (be- ing an encoder only model, the Wav2Vec2 pretrained model is missing the baseline values); (ii) In-District Fine-Tuning (In-Dist.), where models are fine-tuned and evaluated on the same district; ...
-
[4]
We also observe a general increase in WER as the distance between training and testing districts grows
Discussion and Conclusion We examine district-level ASR generalization in the context of Indic languages and find that although district-specific fine- tuning improves local performance, gains do not reliably trans- fer to distant regions, highlighting a trade-off between special- ization and robustness. We also observe a general increase in WER as the di...
-
[5]
ASR for low resource and multilingual noisy code-mixed speech,
T. Verma, A. Shree, and A. Modi, “ASR for low resource and multilingual noisy code-mixed speech,” inINTERSPEECH 2023. ISCA: ISCA, Aug. 2023, pp. 3242–3246
2023
-
[6]
Gram Vaani ASR challenge on spontaneous telephone speech recordings in regional variations of Hindi,
A. Bhanushali, G. Bridgmanet al., “Gram Vaani ASR challenge on spontaneous telephone speech recordings in regional variations of Hindi,” inProceedings of Interspeech, 2022, pp. 3548–3552
2022
-
[7]
Census of india 2011: Language atlas of india,
Office of the Registrar General and Census Commissioner, India, “Census of india 2011: Language atlas of india,” https://language. census.gov.in/, 2011
2011
-
[8]
G. N. Devyet al.,People’s Linguistic Survey of India. Baroda, India: Orient BlackSwan, 2013
2013
-
[9]
Muril: Multilingual representations for indian languages,
S. Khanuja, S. Dandapat, A. Srinivasanet al., “Muril: Multilingual representations for indian languages,”arXiv preprint arXiv:2103.10730, 2021. [Online]. Available: https://arxiv.org/ abs/2103.10730
-
[10]
Lahaja: A robust multi-accent benchmark for evaluating hindi asr systems,
A. Mishra, V . K. Jha, A. Jainet al., “Lahaja: A robust multi-accent benchmark for evaluating hindi asr systems,” arXiv preprint arXiv:2408.11440, 2024. [Online]. Available: https://arxiv.org/abs/2408.11440
-
[11]
Towards inclusive automatic speech recognition,
“Towards inclusive automatic speech recognition,”Computer Speech & Language, vol. 84, p. 101567, 2024. [On- line]. Available: https://www.sciencedirect.com/science/article/ pii/S0885230823000864
2024
-
[12]
Automatic dialect and accent speech recognition of south indian english,
A. Shigli, I. Patel, and K. Rao, “Automatic dialect and accent speech recognition of south indian english,” 09 2018
2018
-
[13]
Fine-tuning ASR model performance on indian re- gional accents for accurate chemical term prediction in audio,
S. Kothari, “Fine-tuning ASR model performance on indian re- gional accents for accurate chemical term prediction in audio,” International Journal of Intelligent Systems and Applications in Engineering, vol. 11, no. 4, pp. 485–494, Sep. 2023
2023
-
[14]
VAANI: Capturing the language landscape for an inclusive digital India
S. Pulikodan, A. Singh, A. Basu, N. Desai, P. K. J, P. D. Bhat, R. Dharmaraju, R. Gupta, S. Udupa, S. Kumar, S. Sharma, V . Vishwakarma, V . Sanka, D. Tewari, H. Dhand, A. Kamat, S. Singh, S. Vashishth, P. Talukdar, R. Acharya, and P. K. Ghosh, “Vaani: Capturing the language landscape for an inclusive digital india,” 2026. [Online]. Available: https://arx...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Multilingual transfer learning for low-resource Indian languages,
A. Singh, S. Sitaram, and A. W. Black, “Multilingual transfer learning for low-resource Indian languages,” inProceedings of Interspeech, 2021, pp. 1917–1921
2021
-
[16]
IndicSUPERB: A speech processing univer- sal performance benchmark for Indian languages,
T. Javed, K. S. Bhogale, A. Raman, A. Kunchukuttan, P. Kumar, and M. M. Khapra, “IndicSUPERB: A speech processing univer- sal performance benchmark for Indian languages,” 2022
2022
-
[17]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Unsupervised cross-lingual representation learning for speech recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsupervised cross-lingual representation learning for speech recognition,” 2020. [Online]. Available: https: //arxiv.org/abs/2006.13979
-
[19]
Is word error rate a good indicator for spoken language understanding accuracy,
Y .-Y . Wang, A. Acero, and C. Chelba, “Is word error rate a good indicator for spoken language understanding accuracy,” in2003 IEEE Workshop on Automatic Speech Recognition and Under- standing (IEEE Cat. No.03EX721), 2003, pp. 577–582
2003
-
[20]
Word error rate estimation without asr out- put: e-wer2,
A. Ali and S. Renals, “Word error rate estimation without asr out- put: e-wer2,” inProceedings of Interspeech 2020, 2020, pp. 616– 620
2020
-
[21]
Virtues of the haversine,
R. W. Sinnott, “Virtues of the haversine,”Sky and Telescope, vol. 68, no. 2, p. 159, 1984
1984
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.