Rethinking the Divergence Regularization in LLM RL
Pith reviewed 2026-06-27 17:12 UTC · model grok-4.3
The pith
DRPO replaces DPPO's hard divergence mask with a smooth advantage-weighted quadratic regularizer while preserving the same trust-region geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
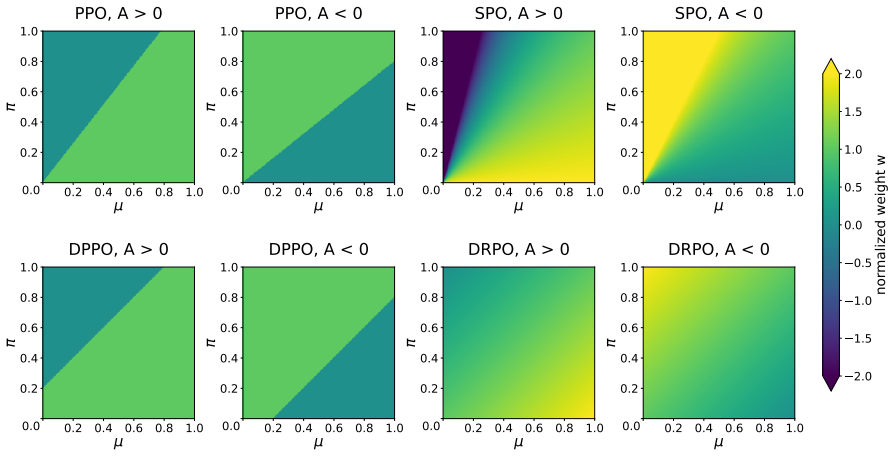
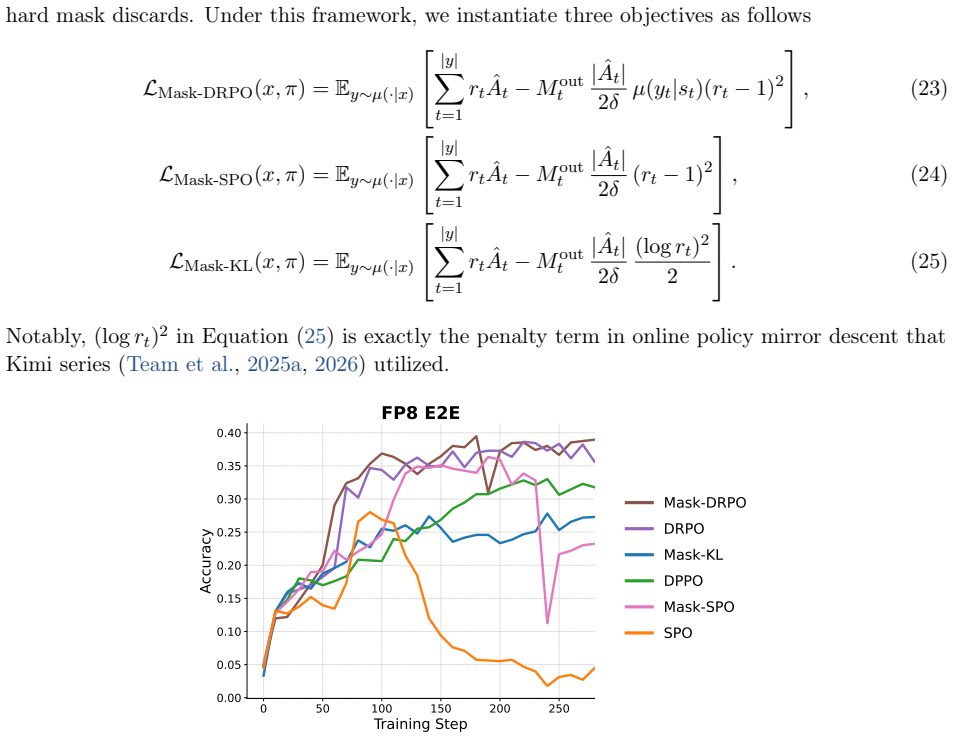
DRPO replaces the hard mask in DPPO with a smooth advantage-weighted quadratic regularizer on policy shift. It preserves the same trust-region geometry defined by the sampled token's absolute probability shift while inducing bounded, continuous gradient weights that attenuate diverging updates and provide corrective signals beyond the boundary.
What carries the argument
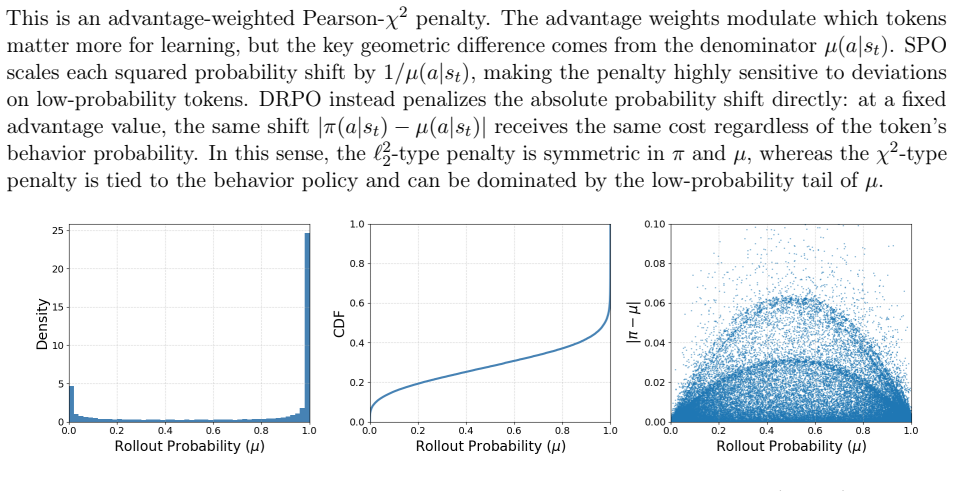
Advantage-weighted quadratic regularizer on absolute probability shift
If this is right
- DRPO preserves the exact trust-region geometry of DPPO.
- Gradient weights remain bounded and continuous rather than abruptly zeroed.
- Corrective gradient signals are supplied for updates that cross the boundary in harmful directions.
- Training stability and efficiency improve across model scales, architectures, and precision settings.
Where Pith is reading between the lines
- The same regularizer form might substitute for ratio clipping in non-LLM off-policy methods that face long-tailed action spaces.
- Empirical measurement of how often the regularizer activates on real training trajectories would quantify its corrective contribution.
Load-bearing premise
Replacing the hard mask with an advantage-weighted quadratic regularizer on absolute probability shift will maintain the intended trust region without introducing new instabilities or requiring additional tuning parameters that dominate performance.
What would settle it
A controlled comparison on the same LLM, tasks, and hyperparameters where DRPO training shows higher variance or lower final reward than DPPO.
Figures


read the original abstract
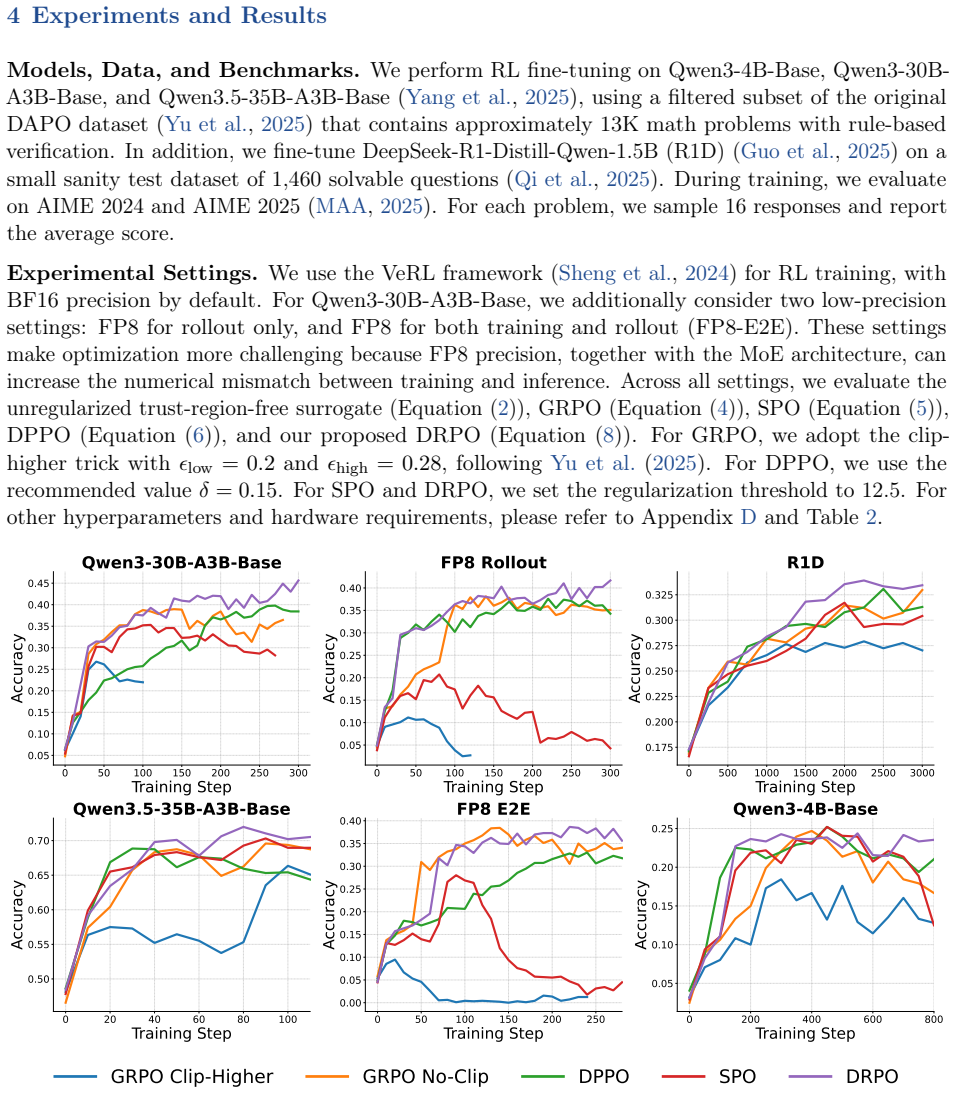
Reinforcement learning (RL) has become a key component of post-training large language models (LLMs). In practice, LLM RL is often off-policy because of training-inference mismatch and policy staleness, making trust-region control essential for stable optimization. Mainstream methods such as PPO and GRPO approximate this control with a ratio-clipping mechanism, but the importance ratio can be a poor proxy for distributional shift in long-tailed vocabularies. Recent work such as DPPO addresses this mismatch by replacing ratio-based clipping with a divergence-based mask, yielding a trust region defined by the sampled token's absolute probability shift. However, DPPO still relies on a hard mask: once a token crosses the trust-region boundary in a harmful direction, its gradient is discarded rather than corrected. To address this, we propose Divergence Regularized Policy Optimization (DRPO), which replaces the hard mask with a smooth advantage-weighted quadratic regularizer on policy shift. DRPO preserves the same trust-region geometry as DPPO while inducing bounded, continuous gradient weights that attenuate diverging updates and provide corrective signals beyond the boundary. Experiments across model scales, architectures, and precision settings show that DRPO improves the stability and efficiency of LLM RL training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Divergence Regularized Policy Optimization (DRPO) to improve upon DPPO for off-policy LLM RL. It replaces DPPO's hard divergence-based mask (on absolute probability shift) with an advantage-weighted quadratic regularizer on policy shift. The central claim is that DRPO preserves exactly the same trust-region geometry as DPPO while inducing bounded continuous gradient weights that attenuate diverging updates and supply corrective signals beyond the boundary, yielding improved stability and efficiency; this is asserted to hold across model scales, architectures, and precision settings based on experiments.
Significance. If the geometry-preservation claim and the absence of new instabilities can be rigorously established, DRPO would offer a principled softening of hard trust-region constraints that retains the distributional-shift focus of DPPO while avoiding abrupt gradient discarding. This could meaningfully advance stable off-policy optimization for long-tailed LLM vocabularies beyond ratio-clipping methods. The manuscript's current presentation, however, provides no quantitative results, ablations, or derivations, leaving the practical impact and correctness of the central claim difficult to evaluate.
major comments (2)
- [Abstract] Abstract: the claim that DRPO 'preserves the same trust-region geometry as DPPO' while simultaneously 'provide corrective signals beyond the boundary' is load-bearing for the contribution yet appears inconsistent on the given description. DPPO's hard mask sets the gradient contribution to zero once the absolute probability shift crosses the boundary in a harmful direction; an advantage-weighted quadratic regularizer is a soft penalty whose gradient remains non-zero (and can be positive in the diverging direction when the advantage term favors it). No limiting argument, equivalent constrained formulation, or explicit proof that the effective feasible set remains identical is supplied, so the geometry-preservation assertion rests on an unshown equivalence.
- [Abstract] Abstract: the soundness of the empirical claim ('experiments across model scales... show that DRPO improves the stability and efficiency') cannot be assessed because the abstract supplies neither quantitative metrics, baseline comparisons, ablation results on the quadratic coefficient, nor details on how the trust-region boundary is enforced or measured. Without these, the central claim that the new regularizer improves upon DPPO without introducing instabilities cannot be verified.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of the geometry claim and to include quantitative support in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that DRPO 'preserves the same trust-region geometry as DPPO' while simultaneously 'provide corrective signals beyond the boundary' is load-bearing for the contribution yet appears inconsistent on the given description. DPPO's hard mask sets the gradient contribution to zero once the absolute probability shift crosses the boundary in a harmful direction; an advantage-weighted quadratic regularizer is a soft penalty whose gradient remains non-zero (and can be positive in the diverging direction when the advantage term favors it). No limiting argument, equivalent constrained formulation, or explicit proof that the effective feasible set remains identical is supplied, so the geometry-preservation assertion rests on an unshown equivalence.
Authors: We thank the referee for this observation. The DRPO formulation uses an advantage-weighted quadratic penalty that is identically zero inside the DPPO boundary (defined by absolute probability shift) and grows outside it, with the weighting ensuring that corrective gradients oppose harmful divergence. While the manuscript states the geometry is preserved, it does not supply the requested limiting argument or constrained equivalence. We will add a short derivation in the revised version (new subsection in Section 3) showing that, in the limit of increasing regularization strength, the soft penalty recovers the hard-mask behavior and identical feasible set. revision: yes
-
Referee: [Abstract] Abstract: the soundness of the empirical claim ('experiments across model scales... show that DRPO improves the stability and efficiency') cannot be assessed because the abstract supplies neither quantitative metrics, baseline comparisons, ablation results on the quadratic coefficient, nor details on how the trust-region boundary is enforced or measured. Without these, the central claim that the new regularizer improves upon DPPO without introducing instabilities cannot be verified.
Authors: We agree that the abstract would be more informative with supporting numbers. The full manuscript reports experiments across scales with stability and efficiency metrics versus DPPO, plus ablations on the quadratic coefficient, and defines the boundary via absolute probability shift in Section 3. We will revise the abstract to include concise quantitative results (e.g., stability gains and convergence speedups) and a brief reference to the boundary definition and ablations. revision: yes
Circularity Check
No circularity: DRPO is a novel regularizer proposal whose geometry claim is a design assertion, not a reduction by construction.
full rationale
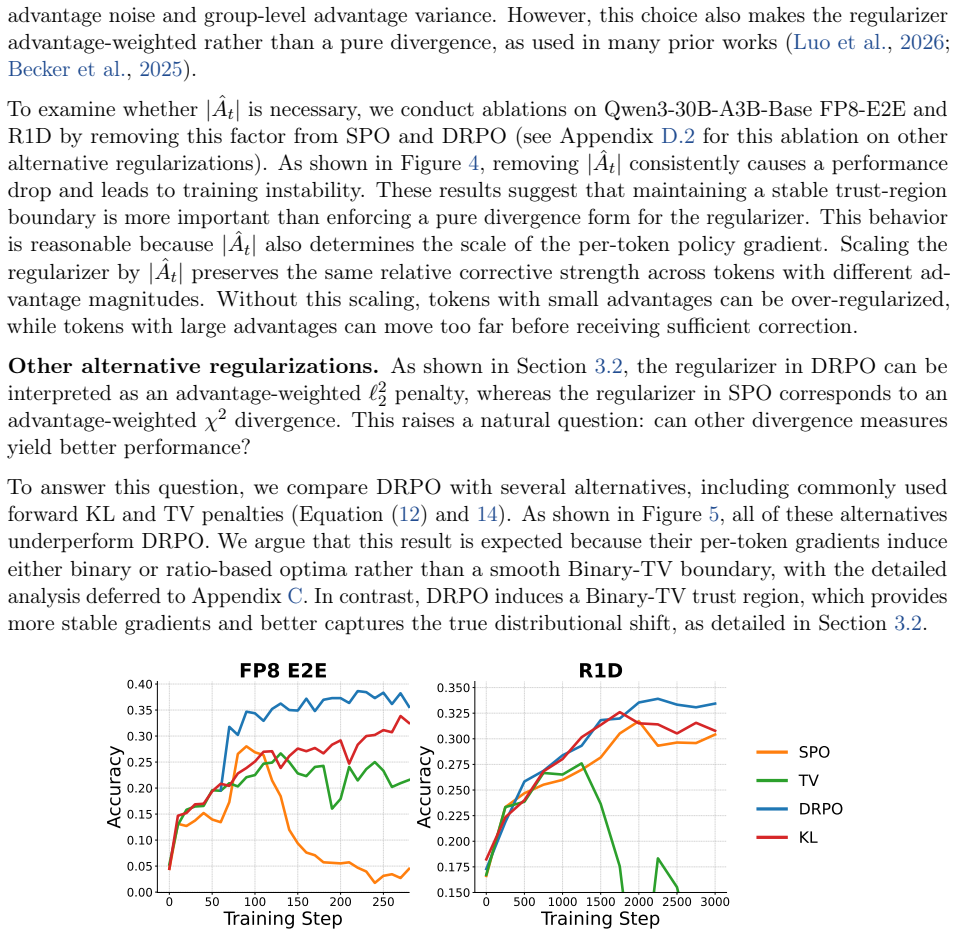
The paper defines DRPO by substituting DPPO's hard mask with an advantage-weighted quadratic penalty on the same absolute probability shift divergence. This substitution is presented as an explicit design choice that yields bounded continuous weights and corrective signals. No equation reduces the new objective to a prior fitted quantity or renames an input as output. The trust-region preservation statement is a claim about the regularizer's effect rather than an algebraic identity forced by self-definition or self-citation. The derivation therefore stands as an independent proposal whose validity rests on the stated equations and experiments, not on circular reuse of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The divergence measure used in DPPO correctly captures distributional shift for long-tailed vocabularies.
Forward citations
Cited by 1 Pith paper
-
Learning from Your Own Mistakes: Constructing Learnable Micro-Reflective Trajectories for Self-Distillation
TAPO constructs learnable micro-reflective trajectories from contrastive model rollouts during RL training to provide explicit error diagnoses and corrections, reporting consistent gains over GRPO on AIME and HMMT mat...
Reference graph
Works this paper leans on
-
[1]
Philipp Becker, Niklas Freymuth, Serge Thilges, Fabian Otto, and Gerhard Neumann. Troll: Trust regions improve reinforcement learning for large language models.arXiv preprint arXiv:2510.03817,
-
[2]
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585,
-
[3]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[4]
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025a. Jiacai Liu, Yingru Li, Yuqian Fu, Jiawei Wang, Qian Liu, and Yu Shen. When speed kills stability: Demystifying rl collaps...
-
[5]
Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788,
Penghui Qi, Zichen Liu, Xiangxin Zhou, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788,
-
[6]
Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879,
Penghui Qi, Xiangxin Zhou, Zichen Liu, Tianyu Pang, Chao Du, Min Lin, and Wee Sun Lee. Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879,
-
[7]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[8]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
-
[9]
Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
-
[10]
Megatron-lm: Training multi-billion parameter language models using model parallelism
13 Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053,
Pith/arXiv arXiv 1909
-
[11]
Kimi k1.5: Scaling reinforcement learning with llms
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1.5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025a. Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: ...
-
[12]
Ling Team, Anqi Shen, Baihui Li, Bin Hu, Bin Jing, Cai Chen, Chao Huang, Chao Zhang, Chaokun Yang, Cheng Lin, et al. Every step evolves: Scaling reinforcement learning for trillion-scale thinking model.arXiv preprint arXiv:2510.18855, 2025b. Manan Tomar, Lior Shani, Yonathan Efroni, and Mohammad Ghavamzadeh. Mirror descent policy optimization. InInternati...
-
[13]
URL https://openreview.net/forum?id=aBO5SvgSt1. Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning.arXiv preprint arXiv:2506.01939,
-
[14]
Zhengpeng Xie, Qiang Zhang, Fan Yang, Marco Hutter, and Renjing Xu. Simple policy optimization. arXiv preprint arXiv:2401.16025,
-
[15]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
-
[16]
https://fengyao.notion.site/off- policy-rl. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[17]
14 Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892,
-
[18]
Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, et al. Stabilizing reinforcement learning with llms: Formulation and practices.arXiv preprint arXiv:2512.01374, 2025a. Haizhong Zheng, Jiawei Zhao, and Beidi Chen. Prosperity before collapse: How far can off-policy rl reach with stale data ...
-
[19]
Despite its success, the clipping mechanism neither strictly bounds the likelihood ratio nor enforces a well-defined divergence constraint (Wang et al., 2020)
replaces the explicit KL constraint with a ratio-clipping heuristic, enabling first-order optimization. Despite its success, the clipping mechanism neither strictly bounds the likelihood ratio nor enforces a well-defined divergence constraint (Wang et al., 2020). Truly PPO (Wang et al.,
2020
-
[20]
Most relevant to our work, SPO (Xie et al.,
connects trust-region policy optimization with mirror descent (Beck and Teboulle, 2003), approximately solving the trust-region subproblem via multiple gradient steps on a Bregman divergence objective rather than enforcing a hard constraint. Most relevant to our work, SPO (Xie et al.,
2003
-
[21]
The per-token optimum of the resulting concave quadratic exactly matches PPO’s clipping boundary, while providing non-zero corrective gradients outside the trust region
replaces PPO’s hard clipping with a smooth quadratic regularizer on the importance ratio. The per-token optimum of the resulting concave quadratic exactly matches PPO’s clipping boundary, while providing non-zero corrective gradients outside the trust region. Our method adopts SPO’s smooth regularization principle but changes the trust-region geometry fro...
2025
-
[22]
ThedominantapproachusesPPO-stylehardclippingtoimposeratio-basedtrustregions
and mini-batch policy staleness (Liu et al., 2025a), making trust-region optimization essential for stable training. ThedominantapproachusesPPO-stylehardclippingtoimposeratio-basedtrustregions. GRPO(Shao et al., 2024; Liu et al., 2025c) retains this objective while replacing critic-based advantages with group-relative advantages (Liu et al., 2025c; Zeng e...
2024
-
[23]
removes clipping through truncated importance sampling, and M2PO (Zheng et al., 2025b) constrains the second moment of importance weights. To reduce variance under off-policy data, prior work has also proposed truncated (Yao et al., 2025; Zheng et al., 2025a) and masked (Liu et al., 2025b; Team et al., 2025b) importance sampling. Another line of work uses...
2025
-
[24]
as the 20 Table 2: Hyperparameters. Hyperparameters Qwen3-4B-Base Qwen3-30B-A3B-Base Qwen3.5-35B-A3B-Base R1D Learning Rate 1e-6 1e-6 1e-6 1e-6 PPO Epochs 1 1 1 1 Max Prompt Length 2048 2048 2048 2048 Max Response Length 8192 8192 8192 8192 Train Batch Size 64 256 256 64 PPO Mini Batch Size 32 32 32 16 Rollout Temperature 1.0 1.0 1.0 1.0 Group Size 8 16 1...
2048
-
[25]
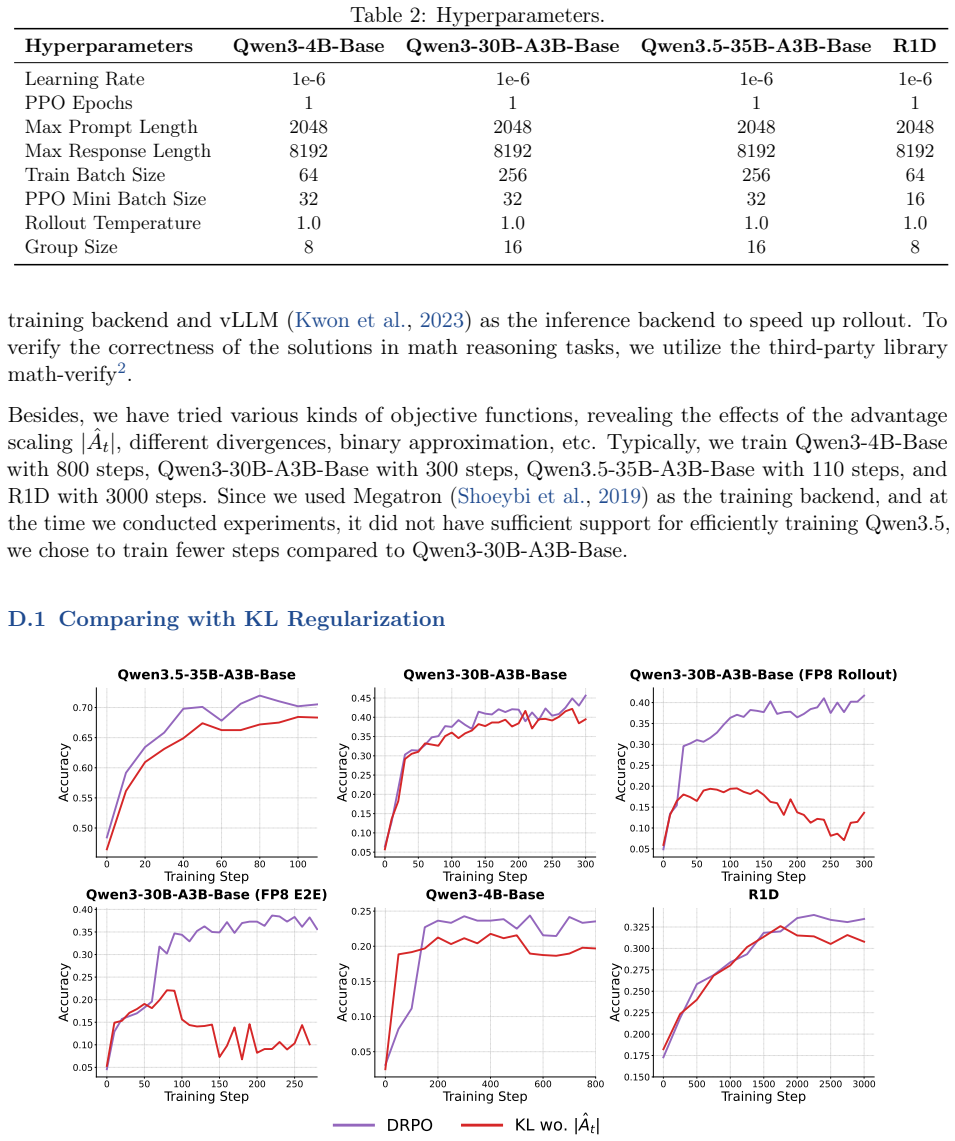
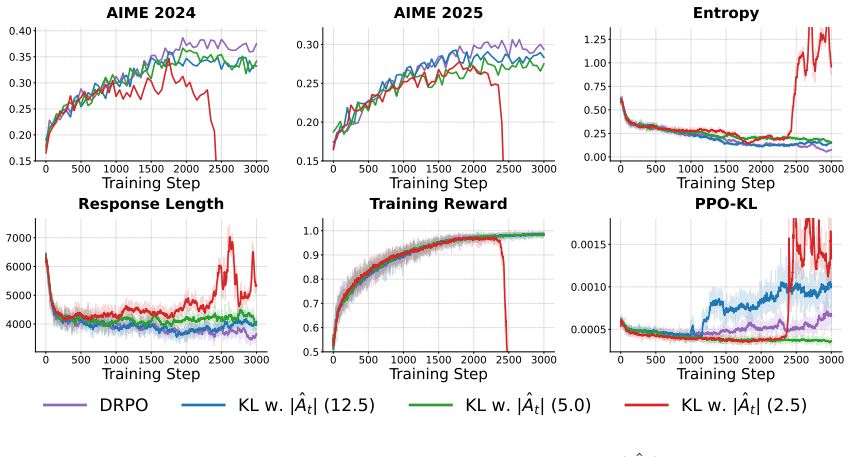
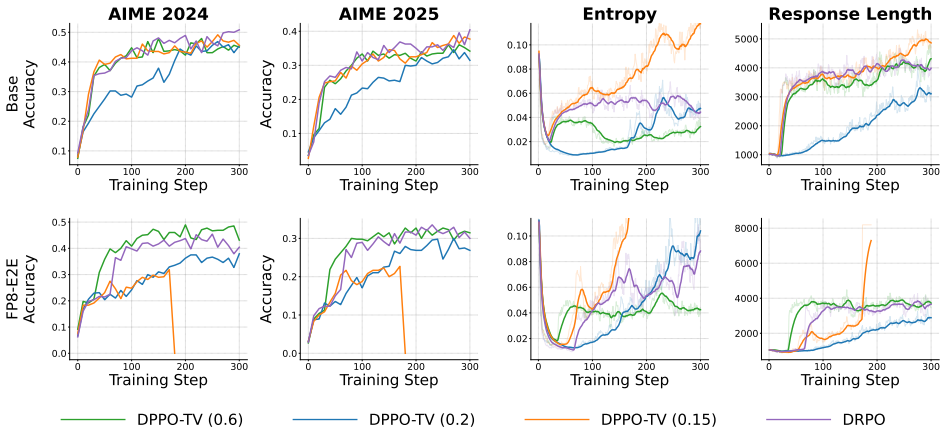
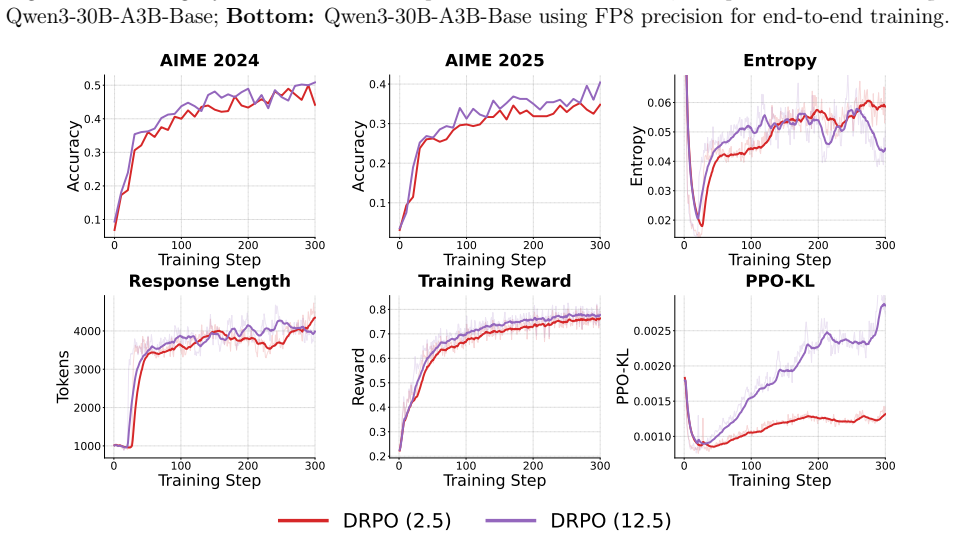
as the training backend, and at the time we conducted experiments, it did not have sufficient support for efficiently training Qwen3.5, we chose to train fewer steps compared to Qwen3-30B-A3B-Base. D.1 Comparing with KL Regularization 0 20 40 60 80 100 Training Step 0.50 0.55 0.60 0.65 0.70Accuracy Qwen3.5-35B-A3B-Base 0 50 100 150 200 250 300 Training St...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.