REAL: A Reasoning-Enhanced Graph Framework for Long-Term Memory Management of LLMs
Pith reviewed 2026-06-27 13:07 UTC · model grok-4.3
The pith
REAL builds LLM long-term memory as a temporal directed property graph and uses hybrid beam search plus counterfactual inference to retrieve compact subgraphs, delivering a 22.72 percent average gain over baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
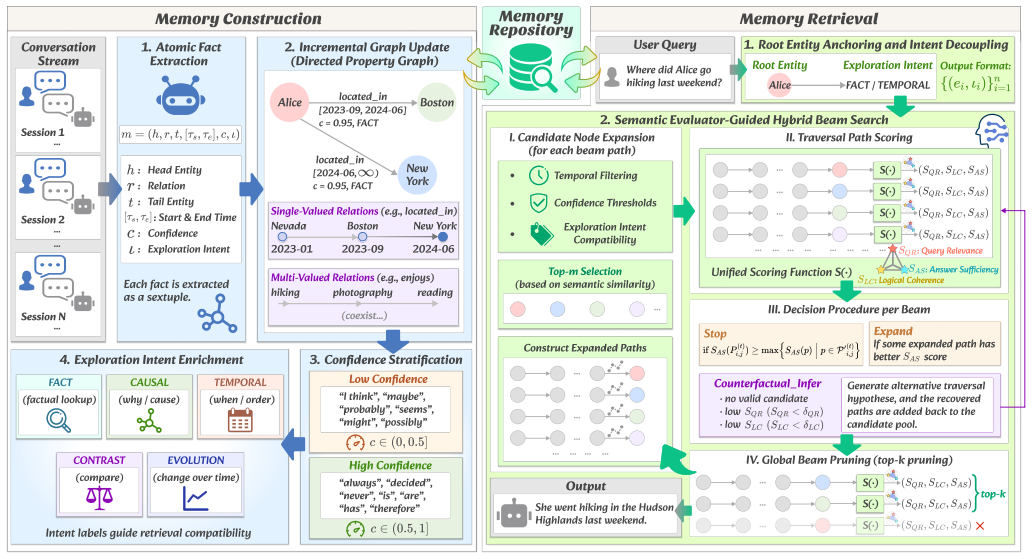
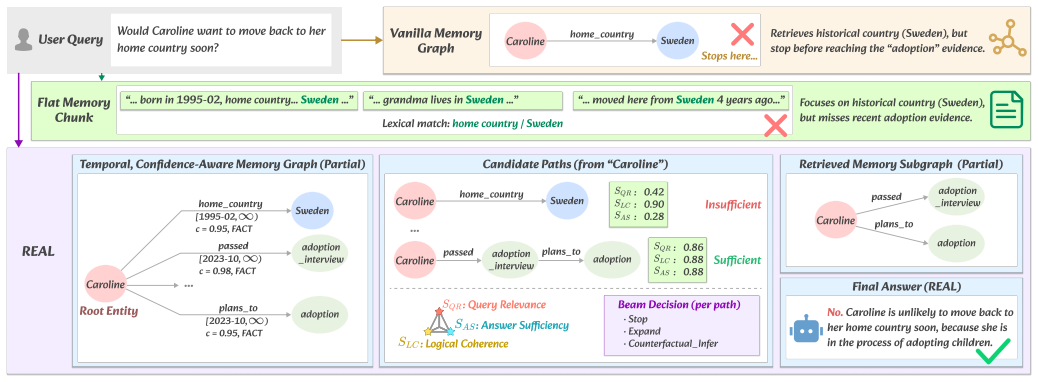
REAL represents long-term conversational memory as a temporal and confidence-aware directed property graph, applies non-destructive temporal updates that preserve parallel fact versions and validity intervals, and retrieves evidence via semantic evaluator-guided hybrid beam search followed by counterfactual inference that recovers missing memory through implicit logical relations.
What carries the argument
A temporal and confidence-aware directed property graph updated non-destructively and retrieved by semantic-evaluator-guided hybrid beam search plus counterfactual inference.
If this is right
- Evolving facts can be tracked without loss of prior versions because updates preserve parallel validity intervals.
- Retrieval can succeed even when direct evidence is absent because counterfactual inference fills gaps via implicit relations.
- Memory subgraphs remain compact because the beam search is guided by a semantic evaluator that scores relevance at each step.
- The same graph structure supports both storage of new interactions and faithful reconstruction of historical states.
Where Pith is reading between the lines
- The same non-destructive temporal mechanism could be applied to any evolving knowledge base that must retain multiple versions of a fact.
- Counterfactual repair might reduce the rate at which downstream LLM responses contradict earlier conversation turns.
- Because the graph already labels exploration intent, future work could route different query types to different search strategies without changing the core storage layer.
Load-bearing premise
The semantic evaluator-guided hybrid beam search combined with counterfactual inference can reliably extract compact subgraphs and recover missing evidence through implicit logical relations without introducing new errors.
What would settle it
Run the same set of long-horizon questions on a version of the system with counterfactual inference disabled and measure whether the fraction of correctly recovered missing facts drops below the level reported with the full pipeline.
Figures
read the original abstract
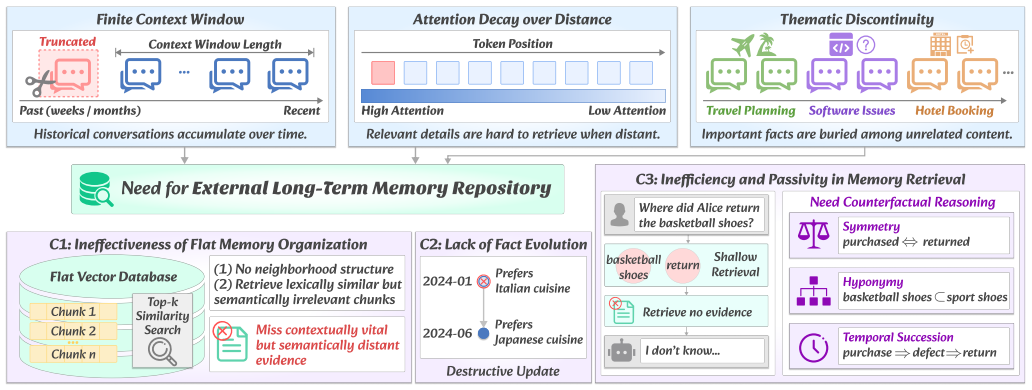
Large Language Models (LLMs) are increasingly expected to interact with users over long time horizons. However, due to their finite context window, LLMs cannot retain all past interactions, making long-term memory management essential for storing, updating, and retrieving historical information beyond the context limit. Although recent memory systems attempt to address this issue by storing historical information externally, existing approaches suffer from three key limitations: flat text-based memory organizations fail to capture explicit relations among memories, structured memory systems often destructively overwrite evolving facts, and current retrieval mechanisms remain query-agnostic and passive when evidence is incomplete. REAL constructs long-term conversational memory as a temporal and confidence-aware directed property graph, where each atomic fact is represented with entities, relations, valid-time intervals, confidence scores, and exploration intent labels. During memory construction, REAL adopts a non-destructive temporal update strategy that preserves parallel fact versions and their validity intervals, enabling faithful tracking of fact evolution. During retrieval, REAL anchors query-relevant root entities, decouples their exploration intents, and performs semantic evaluator-guided hybrid beam search to extract compact memory subgraphs. It further incorporates counterfactual inference to repair unreliable retrieval states and recover missing memory evidence through implicit logical relations. Comprehensive experiments demonstrate that REAL substantially improves long-term memory performance over flat-text, graph-based, and existing memory baselines, achieving an average improvement of 22.72\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes REAL, a reasoning-enhanced graph framework for long-term memory management in LLMs. Memory is stored as a temporal and confidence-aware directed property graph with entities, relations, valid-time intervals, confidence scores, and exploration intent labels. The system uses non-destructive temporal updates to preserve parallel fact versions, and retrieval employs semantic evaluator-guided hybrid beam search on query-anchored root entities plus counterfactual inference to recover missing evidence via implicit relations. Experiments report an average 22.72% improvement over flat-text, graph-based, and existing memory baselines.
Significance. If the reported gains hold under rigorous evaluation, the work would advance LLM memory systems by providing an explicit relational structure that tracks fact evolution without destructive overwrites and augments retrieval with targeted reasoning steps. The combination of temporal property graphs and hybrid search with counterfactual repair addresses three stated limitations of prior approaches and could inform more reliable long-horizon conversational agents.
minor comments (3)
- [Abstract] Abstract: the 22.72% average improvement is stated without naming the primary evaluation metric(s), number of tasks/datasets, or whether the figure is macro- or micro-averaged; a single clarifying sentence would strengthen the claim.
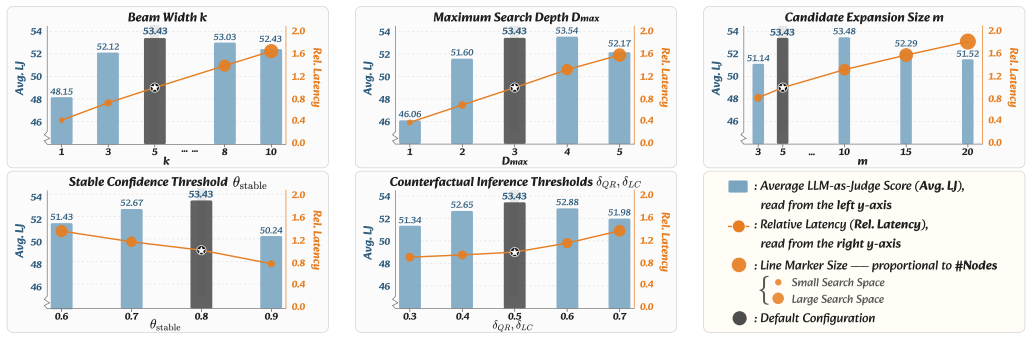
- The description of the semantic evaluator-guided hybrid beam search and counterfactual inference step would benefit from an explicit statement of the evaluator model size and any temperature or threshold hyperparameters used during subgraph extraction.
- Figure captions and table headers should explicitly define all abbreviations (e.g., EA, CI) on first use to improve readability for readers outside the immediate sub-area.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; empirical result independent of inputs
full rationale
The paper describes a graph construction method, non-destructive temporal updates, semantic evaluator-guided hybrid beam search, and counterfactual inference for memory retrieval, then reports an empirical 22.72% average improvement over baselines. No equations, parameter fits, or self-citations are invoked as load-bearing steps in any derivation chain. The central claim is an experimental outcome measured against external baselines rather than a quantity defined by the authors' own prior work or by construction from the method inputs, satisfying the criteria for a self-contained result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs have finite context windows that prevent retention of all past interactions
invented entities (1)
-
temporal and confidence-aware directed property graph
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Written by AI, Managed by AI: Semantic Space Control and Index Sickness Elimination Across 391 Consecutive Sessions
Single-project case study identifies Index Sickness from complex symbolic LLM management and reports that Baseline-Log Physical Separation reduced instructions by 75% with no recurrence observed.
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[2]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[3]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[4]
A survey on the memory mechanism of large language model- based agents,
Z. Zhang, Q. Dai, X. Bo, C. Ma, R. Li, X. Chen, J. Zhu, Z. Dong, and J.- R. Wen, “A survey on the memory mechanism of large language model- based agents,”ACM Transactions on Information Systems, vol. 43, no. 6, pp. 1–47, 2025
2025
-
[5]
Chatdb: Aug- menting llms with databases as their symbolic memory,
C. Hu, J. Fu, C. Du, S. Luo, J. Zhao, and H. Zhao, “Chatdb: Aug- menting llms with databases as their symbolic memory,”arXiv preprint arXiv:2306.03901, 2023
arXiv 2023
-
[6]
Memory matters: The need to improve long-term memory in llm-agents,
K. Hatalis, D. Christou, J. Myers, S. Jones, K. Lambert, A. Amos-Binks, Z. Dannenhauer, and D. Dannenhauer, “Memory matters: The need to improve long-term memory in llm-agents,” inProceedings of the AAAI Symposium Series, vol. 2, no. 1, 2023, pp. 277–280
2023
-
[7]
Memory os of ai agent,
J. Kang, M. Ji, Z. Zhao, and T. Bai, “Memory os of ai agent,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 25 972–25 981
2025
-
[8]
Mem0: Building production-ready ai agents with scalable long-term memory,
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav, “Mem0: Building production-ready ai agents with scalable long-term memory,” arXiv preprint arXiv:2504.19413, 2025
Pith/arXiv arXiv 2025
-
[9]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,
G. Team, P. Georgiev, V . I. Lei, R. Burnell, L. Bai, A. Gulati, G. Tanzer, D. Vincent, Z. Pan, S. Wanget al., “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
Pith/arXiv arXiv 2024
-
[10]
Mechanics of next token prediction with self-attention,
Y . Li, Y . Huang, M. E. Ildiz, A. S. Rawat, and S. Oymak, “Mechanics of next token prediction with self-attention,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2024, pp. 685–693
2024
-
[11]
Same task, more tokens: the impact of input length on the reasoning performance of large language models,
M. Levy, A. Jacoby, and Y . Goldberg, “Same task, more tokens: the impact of input length on the reasoning performance of large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Li...
2024
-
[12]
A-mem: Agentic memory for llm agents,
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y . Zhang, “A-mem: Agentic memory for llm agents,”arXiv preprint arXiv:2502.12110, 2025
Pith/arXiv arXiv 2025
-
[13]
Does memory need graphs? a unified framework and empirical analysis for long-term dialog memory,
S. Hu, Y . Wei, J. Ran, Z. Yao, X. Han, H. Wang, R. Chen, and L. Zou, “Does memory need graphs? a unified framework and empirical analysis for long-term dialog memory,” inProceedings of the 64th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2026
2026
-
[14]
Memotime: Memory-augmented temporal knowledge graph enhanced large language model reasoning,
X. Tan, X. Wang, Q. Liu, X. Xu, X. Yuan, L. Zhu, and W. Zhang, “Memotime: Memory-augmented temporal knowledge graph enhanced large language model reasoning,” inProceedings of the ACM Web Conference 2026, 2026, pp. 4220–4231
2026
-
[15]
Survey of vector database management systems,
J. J. Pan, J. Wang, and G. Li, “Survey of vector database management systems,”The VLDB Journal, vol. 33, no. 5, pp. 1591–1615, 2024
2024
-
[16]
Constructing tree-based index for efficient and effective dense retrieval,
H. Li, Q. Ai, J. Zhan, J. Mao, Y . Liu, Z. Liu, and Z. Cao, “Constructing tree-based index for efficient and effective dense retrieval,” inProceed- ings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023, pp. 131–140
2023
-
[17]
The graph traversal pattern,
M. A. Rodriguez and P. Neubauer, “The graph traversal pattern,” in Graph data management: Techniques and applications. IGI Global Scientific Publishing, 2012, pp. 29–46
2012
-
[18]
Random walks: A review of algorithms and applications,
F. Xia, J. Liu, H. Nie, Y . Fu, L. Wan, and X. Kong, “Random walks: A review of algorithms and applications,”IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 4, no. 2, pp. 95–107, 2019
2019
-
[19]
Topic-sensitive pagerank,
T. H. Haveliwala, “Topic-sensitive pagerank,” inProceedings of the 11th international conference on World Wide Web, 2002, pp. 517–526
2002
-
[20]
Memory is reconstructed, not retrieved: Graph memory for llm agents,
S. Ji, Y . Li, and B. Hooi, “Memory is reconstructed, not retrieved: Graph memory for llm agents,” inICLR 2026 Workshop on Memory for LLM- Based Agentic Systems, 2026
2026
-
[21]
Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead,
J. He, C. Treude, and D. Lo, “Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead,” ACM Transactions on Software Engineering and Methodology, vol. 34, no. 5, pp. 1–30, 2025
2025
-
[22]
A survey of llm-based agents in medicine: How far are we from baymax?
W. Wang, Z. Ma, Z. Wang, C. Wu, J. Ji, W. Chen, X. Li, and Y . Yuan, “A survey of llm-based agents in medicine: How far are we from baymax?” Findings of the Association for Computational Linguistics: ACL 2025, pp. 10 345–10 359, 2025
2025
-
[23]
Evaluating very long-term conversational memory of llm agents,
A. Maharana, D.-H. Lee, S. Tulyakov, M. Bansal, F. Barbieri, and Y . Fang, “Evaluating very long-term conversational memory of llm agents,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 13 851–13 870
2024
-
[24]
Longmemeval: Benchmarking chat assistants on long-term interactive memory,
D. Wu, H. Wang, W. Yu, Y . Zhang, K.-W. Chang, and D. Yu, “Longmemeval: Benchmarking chat assistants on long-term interactive memory,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[25]
Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale,
B. Jiang, Z. Hao, Y . M. Cho, B. Li, Y . Yuan, S. Chen, L. Ungar, C. J. Taylor, and D. Roth, “Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale,” inNeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling, 2025
2025
-
[26]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering,
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering,” inProceedings of the 2018 conference on empirical methods in natural language processing, 2018, pp. 2369–2380
2018
-
[27]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,
X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa, “Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,” inProceedings of the 28th International Conference on Computational Linguistics, 2020, pp. 6609–6625
2020
-
[28]
Musique: Multihop questions via single-hop question composition,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Musique: Multihop questions via single-hop question composition,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 539–554, 2022
2022
-
[29]
Memgpt: Towards llms as operating systems,
C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez, “Memgpt: Towards llms as operating systems,”arXiv preprint arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[30]
Ahrens,How to take smart notes: One simple technique to boost writing, learning and thinking
S. Ahrens,How to take smart notes: One simple technique to boost writing, learning and thinking. S ¨onke Ahrens, 2022
2022
-
[31]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[32]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[33]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu, “Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,”arXiv preprint arXiv:2402.03216, 2024
Pith/arXiv arXiv 2024
-
[34]
Datasculpt: A holistic data management frame- work for long-context llms training,
K. Lu, X. Nie, Z. Liang, D. Pan, S. Zhang, K. Zhao, W. Chen, Z. Zhou, G. Dong, B. Cuiet al., “Datasculpt: A holistic data management frame- work for long-context llms training,” in2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 2025, pp. 4234–4247
2025
-
[35]
Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated soft- ware engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50 528–50 652, 2024
2024
-
[36]
Alfworld: Aligning text and embodied environments for interactive learning,
M. Shridhar, X. Yuan, M.-A. Cote, Y . Bisk, A. Trischler, and M. Hausknecht, “Alfworld: Aligning text and embodied environments for interactive learning,” inInternational Conference on Learning Rep- resentations, 2021
2021
-
[37]
From human memory to ai memory: A survey on memory mechanisms in the era of llms,
Y . Wu, S. Liang, C. Zhang, Y . Wang, Y . Zhang, H. Guo, R. Tang, and Y . Liu, “From human memory to ai memory: A survey on memory mechanisms in the era of llms,”arXiv preprint arXiv:2504.15965, 2025
Pith/arXiv arXiv 2025
-
[38]
Longformer: The long- document transformer,
I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long- document transformer,”arXiv preprint arXiv:2004.05150, 2020
Pith/arXiv arXiv 2004
-
[39]
Make your llm fully utilize the context,
S. An, Z. Ma, Z. Lin, N. Zheng, J.-G. Lou, and W. Chen, “Make your llm fully utilize the context,”Advances in Neural Information Processing Systems, vol. 37, pp. 62 160–62 188, 2024
2024
-
[40]
Data engineering for scaling language models to 128k context,
Y . Fu, R. Panda, X. Niu, X. Yue, H. Hajishirzi, Y . Kim, and H. Peng, “Data engineering for scaling language models to 128k context,” in Proceedings of the 41st International Conference on Machine Learning, 2024, pp. 14 125–14 134
2024
-
[41]
Large language models can be easily distracted by irrelevant context,
F. Shi, X. Chen, K. Misra, N. Scales, D. Dohan, E. H. Chi, N. Sch ¨arli, and D. Zhou, “Large language models can be easily distracted by irrelevant context,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 31 210–31 227
2023
-
[42]
Lost in the middle: How language models use long contexts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” Transactions of the association for computational linguistics, vol. 12, pp. 157–173, 2024
2024
-
[43]
Length extrapolation of transformers: A survey from the perspective of positional encoding,
L. Zhao, X. Feng, X. Feng, W. Zhong, D. Xu, Q. Yang, H. Liu, B. Qin, and T. Liu, “Length extrapolation of transformers: A survey from the perspective of positional encoding,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 9959–9977
2024
-
[44]
Dape: Data-adaptive positional encoding for length extrapolation,
C. Zheng, Y . Gao, H. Shi, M. Huang, J. Li, J. Xiong, X. Ren, M. Ng, X. Jiang, Z. Liet al., “Dape: Data-adaptive positional encoding for length extrapolation,”Advances in Neural Information Processing Systems, vol. 37, pp. 26 659–26 700, 2024
2024
-
[45]
Ringattention with blockwise transformers for near-infinite context,
H. Liu, M. Zaharia, and P. Abbeel, “Ringattention with blockwise transformers for near-infinite context,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[46]
M+: Extending memoryllm with scalable long-term memory,
Y . Wang, D. Krotov, Y . Hu, Y . Gao, W. Zhou, J. Mcauley, D. Gutfreund, R. Feris, and Z. He, “M+: Extending memoryllm with scalable long-term memory,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 63 308–63 323
2025
-
[47]
Lm2: Large memory models for long context reasoning,
J. Kang, W. Wu, F. Christianos, A. J. Chan, F. D. Greenlee, G. Thomas, M. Purtorab, and A. Toulis, “Lm2: Large memory models for long context reasoning,” inWorkshop on Reasoning and Planning for Large Language Models, 2025
2025
-
[48]
HMT: Hierarchical memory transformer for efficient long context language processing,
Z. He, Y . Cao, Z. Qin, N. Prakriya, Y . Sun, and J. Cong, “HMT: Hierarchical memory transformer for efficient long context language processing,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), L. Chiruzzo, A. Ritter, and L. W...
2025
-
[49]
Adapting language models to compress contexts,
A. Chevalier, A. Wettig, A. Ajith, and D. Chen, “Adapting language models to compress contexts,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 3829– 3846
2023
-
[50]
Llmlingua: Com- pressing prompts for accelerated inference of large language models,
H. Jiang, Q. Wu, C.-Y . Lin, Y . Yang, and L. Qiu, “Llmlingua: Com- pressing prompts for accelerated inference of large language models,” inProceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 13 358–13 376
2023
-
[51]
Learning to compress prompts with gist tokens,
J. Mu, X. Li, and N. Goodman, “Learning to compress prompts with gist tokens,”Advances in Neural Information Processing Systems, vol. 36, pp. 19 327–19 352, 2023
2023
-
[52]
Recomp: Improving retrieval-augmented lms with context compression and selective augmentation,
F. Xu, W. Shi, and E. Choi, “Recomp: Improving retrieval-augmented lms with context compression and selective augmentation,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[53]
Augmenting language models with long-term memory,
W. Wang, L. Dong, H. Cheng, X. Liu, X. Yan, J. Gao, and F. Wei, “Augmenting language models with long-term memory,”Advances in Neural Information Processing Systems, vol. 36, pp. 74 530–74 543, 2023
2023
-
[54]
Hipporag: Neurobiologically inspired long-term memory for large language mod- els,
B. J. Guti ´errez, Y . Shu, Y . Gu, M. Yasunaga, and Y . Su, “Hipporag: Neurobiologically inspired long-term memory for large language mod- els,”Advances in neural information processing systems, vol. 37, pp. 59 532–59 569, 2024
2024
-
[55]
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents,
Z. Tan, J. Yan, I.-H. Hsu, R. Han, Z. Wang, L. Le, Y . Song, Y . Chen, H. Palangi, G. Leeet al., “In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents,” inProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 8416–8439
2025
-
[56]
From rag to memory: Non-parametric continual learning for large language models,
B. J. Guti ´errez, Y . Shu, W. Qi, S. Zhou, and Y . Su, “From rag to memory: Non-parametric continual learning for large language models,” inInternational Conference on Machine Learning. PMLR, 2025, pp. 21 497–21 515
2025
-
[57]
Kag: Boosting llms in professional domains via knowledge augmented generation,
L. Liang, Z. Bo, Z. Gui, Z. Zhu, L. Zhong, P. Zhao, M. Sun, Z. Zhang, J. Zhou, W. Chenet al., “Kag: Boosting llms in professional domains via knowledge augmented generation,” inCompanion Proceedings of the ACM on Web Conference 2025, 2025, pp. 334–343
2025
-
[58]
The hippocampal memory indexing theory
T. J. Teyler and P. DiScenna, “The hippocampal memory indexing theory.”Behavioral neuroscience, vol. 100, no. 2, p. 147, 1986
1986
-
[59]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,”NeurIPS, vol. 33, pp. 1877–1901, 2020
1901
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.