ConvMemory v2: A Recall-Preserving Top-10 Evidence Reranker for Conversational Memory Retrieval
Pith reviewed 2026-06-27 13:26 UTC · model grok-4.3
The pith
ConvMemory v2 reranks only the top-10 candidates from v1 with a fine-tuned cross-encoder to raise MRR while preserving recall exactly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
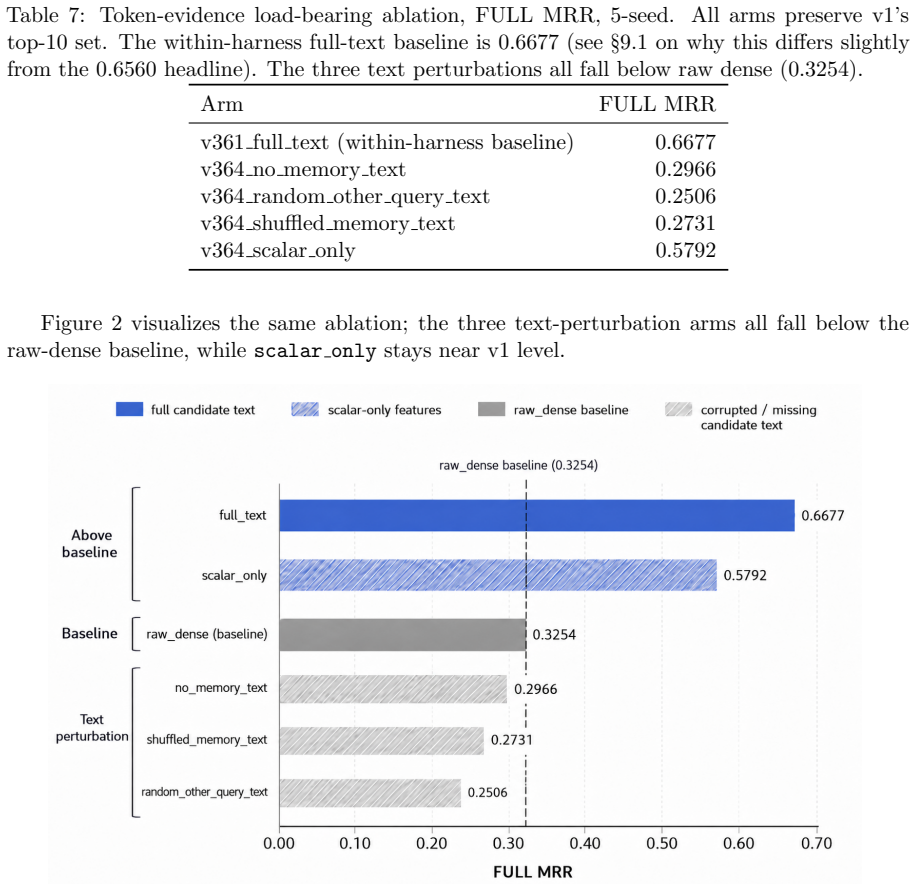
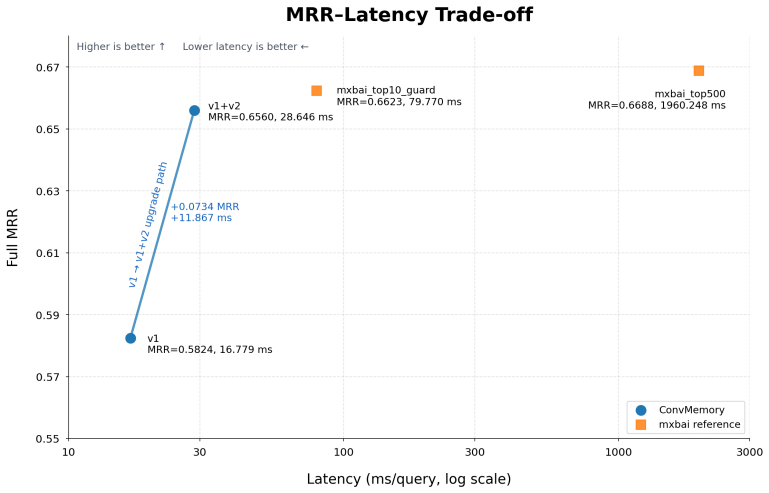
ConvMemory v2 is a recall-preserving cascade that fine-tunes ms-marco-MiniLM-L-6-v2 on the ten (query, memory) pairs returned by v1, raising FULL MRR by 0.0734 and H@1 by 0.1034 on LoCoMo while leaving Recall@10 and Hit@10 unchanged; the four-arm ablation isolates candidate-specific memory text as the load-bearing mechanism because any alteration of that text collapses MRR below the dense baseline, and the method reaches within 0.013 MRR of mxbai-rerank-large-v1 over the top-500.
What carries the argument
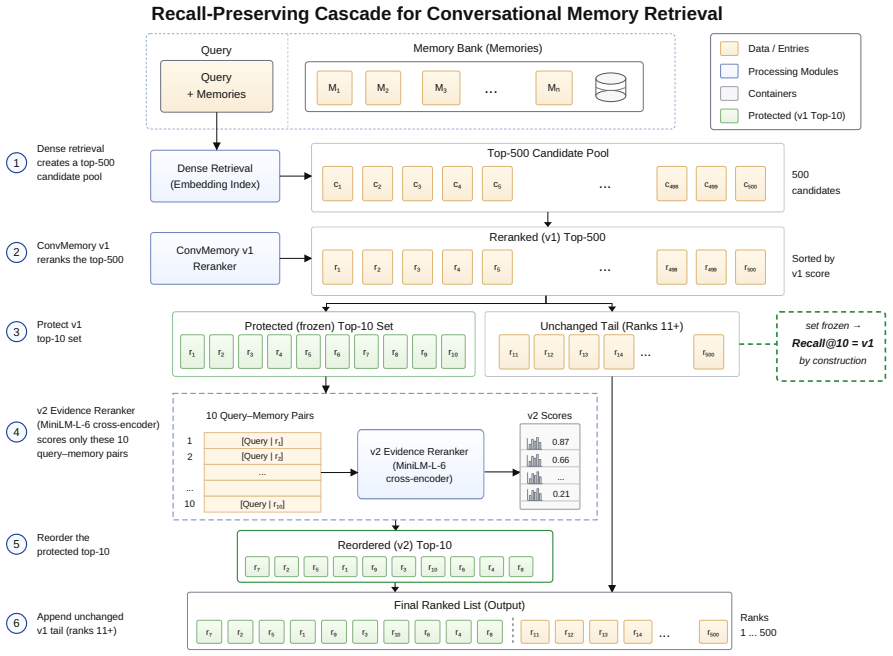
The opt-in token-evidence reranker that applies a 22-million-parameter cross-encoder only to the protected top-10 set from v1 under an explicit anti-shortcut contract that forbids changing the candidate pool.
If this is right
- v2 sits only 0.013 MRR below the much larger mxbai-rerank-large-v1 over the full top-500 pool.
- On two raw-dense-hard slices where v1's top-10 already has higher recall than mxbai's top-10, v2 exceeds mxbai_top500.
- The performance lift vanishes when the ablation removes or replaces the candidate-specific memory text.
- The design follows the standard recall-preserving cascade pattern with LoCoMo-specific fine-tuning and explicit load-bearing analysis.
Where Pith is reading between the lines
- The same two-stage pattern could be tested on other conversational retrieval benchmarks to measure how much additional MRR is recoverable without expanding the candidate pool.
- A hybrid system that routes different query slices to either v2 or a full-pool reranker might close the remaining 0.013 gap at modest extra cost.
- The slice-specific advantage over mxbai suggests that future work could identify which query types benefit most from the lightweight top-10 reranker versus heavier alternatives.
Load-bearing premise
The four-arm ablation correctly isolates candidate-specific memory text as the sole driver of the MRR gain such that altering or removing it collapses performance below the initial dense retriever.
What would settle it
Replace the memory text in each of the ten pairs with random or generic strings, rerun the model on the 4955-row test set, and check whether FULL MRR falls below v1's 0.5824.
Figures
read the original abstract
We describe ConvMemory v2, an opt-in token-evidence reranker that sits after the lightweight ConvMemory v1 reranker and reorders only v1's protected top-10 candidate set. v2 is a fine-tuned ms-marco-MiniLM-L-6-v2 cross-encoder (22,713,601 parameters, measured from the released checkpoint) applied to the ten (query, memory) pairs that v1 has already selected; it does not change which ten memories are returned, so Recall@10 and Hit@10 are identical to v1 by construction, not by statistical coincidence. On the LoCoMo conversational memory benchmark (5 seeds, n = 4955 test rows), v2 raises FULL MRR from v1's 0.5824 to 0.6560 (paired bootstrap +0.0734, 95% CI [+0.0645, +0.0827]) and H@1 from 0.4440 to 0.5474. v2 closes most but not all of the gap to a much more expensive full-pool cross-encoder reference (mxbai-rerank-large-v1 over the top-500, MRR 0.6688): on FULL MRR v2 sits 0.013 below mxbai_top500, but on two raw-dense-hard slices (where v1's protected top-10 has higher recall than mxbai's own top-10) v2 exceeds mxbai_top500. A four-arm load-bearing ablation shows candidate-specific memory text is the mechanism: removing, shuffling, or replacing it collapses MRR below raw dense retrieval. v2 is best understood as a standard recall-preserving cascade pattern with LoCoMo-specific fine-tuning, an explicit anti-shortcut inference contract, and disciplined load-bearing analysis; its advantage over mxbai is slice-specific rather than a general dominance claim. This report extends the v1 technical report (arXiv:2605.28062).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents ConvMemory v2, a recall-preserving reranker that applies a fine-tuned ms-marco-MiniLM-L-6-v2 cross-encoder (22.7M parameters) exclusively to the protected top-10 candidate set produced by ConvMemory v1. On the LoCoMo benchmark (5 seeds, n=4955 test rows), it reports a FULL MRR lift from 0.5824 to 0.6560 (paired bootstrap +0.0734, 95% CI [+0.0645, +0.0827]) and H@1 from 0.4440 to 0.5474 while Recall@10 and Hit@10 remain identical to v1 by construction. A four-arm ablation is presented as isolating candidate-specific memory text as the load-bearing mechanism, and v2 is shown to close most of the gap to an expensive full-pool mxbai-rerank-large-v1 reference (MRR 0.6688), with slice-specific outperformance on raw-dense-hard subsets. The work positions itself as a standard cascade with LoCoMo-specific fine-tuning and explicit anti-shortcut analysis, extending the v1 report.
Significance. If the ablation and bootstrap results hold without data leakage, the paper demonstrates a practical, low-overhead way to improve ranking metrics in conversational memory retrieval while preserving recall by design. The explicit construction that Recall@10/Hit@10 are unchanged, the use of paired bootstrap CIs, the slice-specific comparison to the mxbai reference, and the load-bearing ablation analysis are methodological strengths that support the central empirical claim.
major comments (1)
- [Abstract] Abstract (ablation description): the claim that the four-arm ablation isolates candidate-specific memory text as the mechanism rests on the statement that removing, shuffling, or replacing it collapses MRR below raw dense retrieval. Without the per-arm MRR values, exact arm definitions, or a supporting table, it is not possible to verify that the ablation fully rules out alternative explanations for the observed lift.
minor comments (2)
- The parameter count (22,713,601) is stated as measured from the released checkpoint; a brief note confirming it matches the base ms-marco-MiniLM-L-6-v2 architecture would aid reproducibility.
- [Abstract] The 'raw-dense-hard slices' on which v2 exceeds mxbai_top500 are referenced but not formally defined; a short definition or selection criterion would clarify the slice-specific advantage claim.
Simulated Author's Rebuttal
We thank the referee for the careful review, the positive assessment of the work's methodological strengths, and the recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (ablation description): the claim that the four-arm ablation isolates candidate-specific memory text as the mechanism rests on the statement that removing, shuffling, or replacing it collapses MRR below raw dense retrieval. Without the per-arm MRR values, exact arm definitions, or a supporting table, it is not possible to verify that the ablation fully rules out alternative explanations for the observed lift.
Authors: We agree that the abstract provides only a high-level summary of the four-arm ablation without numerical values, arm definitions, or a table, making independent verification of the load-bearing claim difficult from the abstract alone. The submitted manuscript text contains the same concise statement. In revision we will add an explicit ablation table (with arm definitions and per-arm MRR) to the experiments section and revise the abstract to reference the table or include the key comparative result, subject to length constraints. This change directly addresses the verifiability concern while preserving the original empirical claim. revision: yes
Circularity Check
No significant objection identified
full rationale
The paper reports direct empirical MRR/H@1 gains on a held-out test set (n=4955, 5 seeds) with explicit paired-bootstrap CIs; Recall@10/Hit@10 are identical to v1 by explicit construction of the cascade architecture. The single self-citation to arXiv:2605.28062 (v1) supplies only the baseline numbers and is not used to justify the v2 lift or the ablation mechanism. No equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear. The four-arm ablation is described as an empirical isolation of candidate-specific text and does not reduce to any self-referential definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- fine-tuned cross-encoder weights =
22,713,601
axioms (1)
- domain assumption The LoCoMo benchmark constitutes a representative test distribution for conversational memory retrieval tasks.
Forward citations
Cited by 1 Pith paper
-
ConvMemory v3: A Validity Context Layer for Conversational Memory via Target-Conditioned Relation Verification
ConvMemory v3 introduces a dual-evidence gate for target-conditioned memory validity verification, reporting 90.12% accuracy on synthetic benchmarks, 98.8% transfer to real data, and H@1 improvement from 45.1% to 95.7...
Reference graph
Works this paper leans on
-
[1]
Taiheng Pan. ConvMemory: A lightweight learned memory reranker, a negative attribution result, and a research-preview conflict editor. arXiv preprint arXiv:2605.28062, 2026.https: //arxiv.org/abs/2605.28062
Pith/arXiv arXiv 2026
-
[2]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024.https://arxiv.org/abs/2402.17753
Pith/arXiv arXiv 2024
-
[3]
MPNet: Masked and permuted pre-training for language understanding
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MPNet: Masked and permuted pre-training for language understanding. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2020.https://arxiv.org/abs/2004.09297. 19
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.