Tight Boundary Prediction in Speaker Diarization Using Causal-Anticausal Consistency
Pith reviewed 2026-06-27 08:33 UTC · model grok-4.3
The pith
Causal and anticausal models generate tighter speech boundaries from loose labels by avoiding learned looseness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that causal and anticausal models are unable to reproduce the loosening behavior present in loose labels, so their predictions can serve as tighter pseudo labels; an iterative co-training procedure that alternates between label tightening and model updates then recovers roughly 70 percent of the boundary-tightening benefit that would be obtained from ideal tight-label training and yields measurable gains on downstream automatic speech recognition.
What carries the argument
Causal-anticausal consistency: the agreement between a forward (causal) model and a backward (anticausal) model supplies the tightened pseudo labels that drive the co-training loop.
If this is right
- The co-training recovers about 70 percent of the tightening effect obtained by training on ideal tight labels.
- Downstream automatic speech recognition performance improves when the diarization output uses the tightened boundaries.
- Iterative refinement produces progressively tighter labels without external supervision.
- The same loose-labeled data can support both standard and tight-boundary diarization models.
Where Pith is reading between the lines
- The same consistency principle could be tested on other sequence tasks that suffer from margin-inflated annotations, such as action segmentation in video.
- If the tightening effect scales with model size, very large causal-anticausal pairs might approach the performance of models trained on expensive tight labels.
- The method supplies a concrete way to measure how much looseness a given architecture has internalized, which could guide architecture choices for boundary-sensitive applications.
Load-bearing premise
Causal and anticausal models are inherently incapable of learning loosening behavior from the loose labels.
What would settle it
Training a causal or anticausal model on the same loose labels and observing that its boundary predictions remain as loose as those of a standard bidirectional model would falsify the central premise.
Figures

read the original abstract
Multi-talker conversational automatic speech recognition data are often used to train speaker diarization models. Because such data prioritize semantic continuity, pauses and boundary margins are included within speech segments, resulting in loose annotations. Models trained on such data tend to internalize mechanisms that reproduce this looseness, although tight speech intervals are sometimes preferable for downstream applications. In this paper, we address the novel task of enabling models to produce tight predictions using loose labels. Our method generates tighter pseudo labels using causal and anticausal models, which are inherently incapable of learning loosening behavior. We further propose a co-training scheme that iteratively tightens labels and updates both models for more progressive refinement. Experimental results show that the proposed method recovers about 70 % of the tightening effect achieved by ideal tight-label training and improves downstream performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the task of producing tight speech boundary predictions for speaker diarization when models are trained on loose labels (which include pauses and margins for semantic continuity). It proposes generating tighter pseudo-labels via causal and anticausal models, which are asserted to be inherently incapable of learning loosening behavior, combined with an iterative co-training scheme that refines both models and labels. The abstract reports that the method recovers approximately 70% of the tightening effect obtained from ideal tight-label training and yields downstream performance gains.
Significance. If the directional-model assumption is substantiated and the reported recovery rate holds under controlled experiments with proper baselines, the approach could offer a label-efficient route to improved boundary precision in diarization without requiring re-annotation, directly benefiting downstream tasks such as multi-talker ASR. The consistency-based tightening idea is novel in this domain.
major comments (2)
- [Abstract] Abstract: the claim that causal and anticausal models are 'inherently incapable of learning loosening behavior' from loose labels is presented without derivation, ablation, or even a qualitative counter-example showing why unidirectional processing prevents reproduction of extra boundary margins. This assumption is load-bearing for the entire pseudo-label generation step; if the models can still learn loosening via acoustic cues or label statistics, the claimed tightening advantage collapses.
- [Abstract] Abstract: the 70% recovery figure and downstream gains are stated without any description of experimental setup, baselines (e.g., standard bidirectional model, oracle tight labels), metrics (DER, boundary F1, etc.), datasets, or error analysis, rendering the quantitative claim unverifiable from the given information.
minor comments (1)
- The co-training procedure and the precise mechanism for enforcing causal-anticausal consistency should be formalized with equations or pseudocode in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point-by-point below, with proposed revisions to the abstract where they improve clarity without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that causal and anticausal models are 'inherently incapable of learning loosening behavior' from loose labels is presented without derivation, ablation, or even a qualitative counter-example showing why unidirectional processing prevents reproduction of extra boundary margins. This assumption is load-bearing for the entire pseudo-label generation step; if the models can still learn loosening via acoustic cues or label statistics, the claimed tightening advantage collapses.
Authors: The abstract is concise by design, but the full manuscript (Sections 2–3) derives the claim from the unidirectional architectures: a causal model has access only to past frames and cannot anticipate or reproduce future pauses/margins that loose labels encode for semantic continuity; an anticausal model lacks past context for the same reason. We include qualitative examples in the paper showing that even when trained on loose labels these models produce tighter boundaries than bidirectional counterparts. We will revise the abstract to incorporate a brief qualitative counter-example and a pointer to the architectural rationale. revision: partial
-
Referee: [Abstract] Abstract: the 70% recovery figure and downstream gains are stated without any description of experimental setup, baselines (e.g., standard bidirectional model, oracle tight labels), metrics (DER, boundary F1, etc.), datasets, or error analysis, rendering the quantitative claim unverifiable from the given information.
Authors: We agree the abstract omits experimental details due to length constraints. The full manuscript (Sections 4–5) specifies the datasets, metrics (DER and boundary F1), baselines (bidirectional loose-label model and oracle tight-label training), and the exact computation of the 70% recovery (fraction of the boundary-tightness gap closed relative to the loose-label baseline). Downstream gains are measured on multi-talker ASR. We will revise the abstract to add one sentence summarizing the evaluation protocol and recovery definition. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central method rests on the stated property that causal and anticausal models are inherently incapable of learning loosening behavior from loose labels, used to generate tighter pseudo-labels via co-training. No equations, fitting procedures, or self-citations are present in the provided text that reduce this claim or the reported 70% recovery to a self-referential quantity by construction. The derivation does not match any enumerated circularity pattern and remains self-contained, relying on directional model properties rather than inputs renamed as outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal and anticausal models are inherently incapable of learning loosening behavior
Reference graph
Works this paper leans on
-
[1]
takes around twice the video duration
Introduction Speaker diarization is the task of determining who is speaking when from an audio signal. It is typically addressed using mod- els that take audio as input and output speaker-wise speech seg- ments [1–8]. Training such models requires a large amount of data annotated with speaker-wise speech intervals, and in prac- tice, multi-talker automati...
Pith/arXiv arXiv 2026
-
[2]
Speaker diarization Training end-to-end neural diarization (EEND) models requires a large-scale dataset
Related work 2.1. Speaker diarization Training end-to-end neural diarization (EEND) models requires a large-scale dataset. In early studies, since it was difficult to achieve large-scale training using only real data, simulated mix- tures were used for pretraining [1, 4–6]. In recent years, an increasing number of corpora have been developed for multi- ta...
-
[3]
Formulation of the conventional speaker diarization Speaker diarization is the problem of estimating speaker-wise speech activity at each frame
Problem formulation 3.1. Formulation of the conventional speaker diarization Speaker diarization is the problem of estimating speaker-wise speech activity at each frame. LetX= [x 1, . . . ,xT ]∈R D×T denote frame-wiseD-dimensional acoustic features, whereT is the number of frames. GivenX, the goal is to estimate the speaker activities ˆY= [ˆy1, . . . ,ˆyT...
-
[4]
Concept As illustrated in Fig
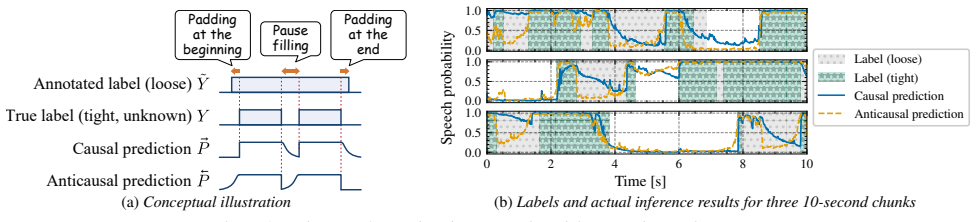
Proposed method 4.1. Concept As illustrated in Fig. 1, conventional training leads speaker di- arization models to estimate not only who is speaking when but also to pad segment boundaries and fill pauses. If the former functionality can be isolated, it would benefit downstream tasks. However, once these functions are internalized in a diarization model, ...
-
[5]
To determine how much to pad segment boundaries or how long to fill a silent interval, a model must first identify tightly bounded speech segments and then examine the surrounding context. Since diarization models are typically based on bidi- rectional [1], fully attentive [2,5], or large-receptive-field archi- tectures [33,43], such capabilities tend to ...
-
[6]
Experimental settings 5.1. Speaker diarization pipeline We adopted the EEND-vector clustering framework [4], which consists of i) local diarization with a 10-second window and a 1- second shift, ii) speaker embedding extraction for each detected speaker in each window, and iii) clustering of the speaker em- beddings to determine speaker correspondence acr...
-
[7]
Speaker diarization 6.1.1
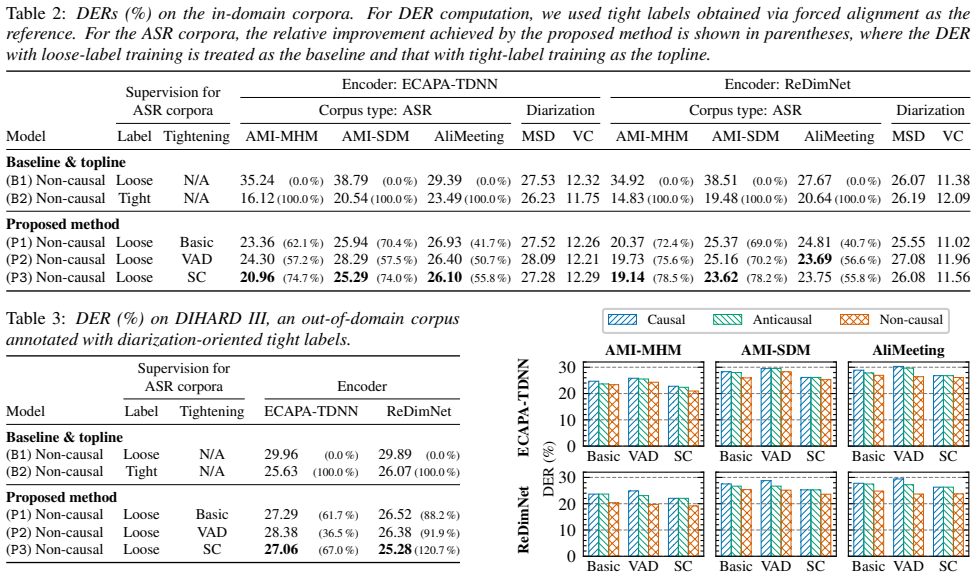
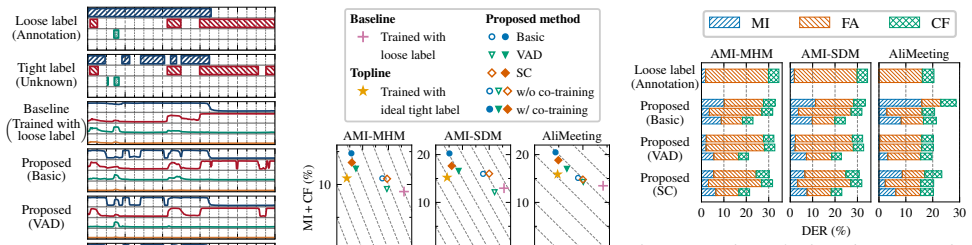
Results 6.1. Speaker diarization 6.1.1. Main results We first present the overall results on the in-domain corpora in Table 2. For the baseline models (B1), we use the annotated la- bels shown in Table 1 as supervision, whereas the topline mod- els (B2) use the ideally tightened labels via forced alignment for the ASR corpora, while the diarization corpor...
-
[8]
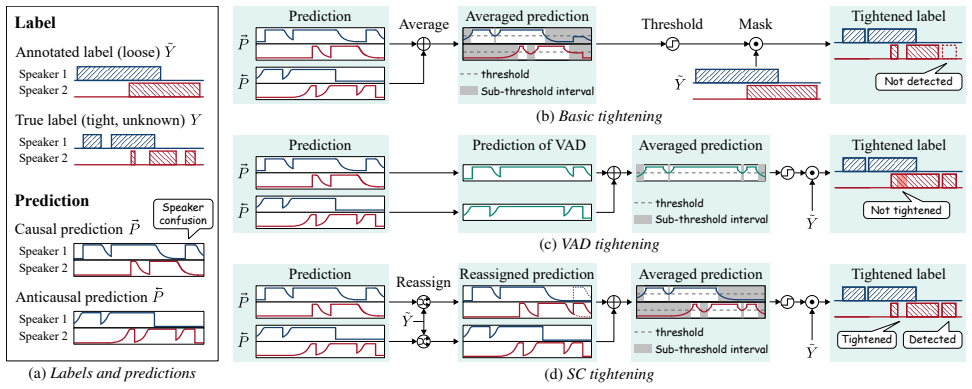
By leveraging the asymmetric padding properties of causal and anticausal models, the method refines loose anno- tations through co-training
Conclusions In this paper, we proposed a training method for speaker diariza- tion models with loose ASR labels while enabling tight bound- ary inference. By leveraging the asymmetric padding properties of causal and anticausal models, the method refines loose anno- tations through co-training. This eliminates the need for costly manual annotation or acce...
-
[9]
All technical content was developed and verified by the authors
Generative AI Use Disclosure The authors used a large language model (ChatGPT) only to assist with language editing and polishing. All technical content was developed and verified by the authors
-
[10]
End-to-end neural speaker diarization with permutation-free objectives,
Y . Fujita, N. Kanda, S. Horiguchi, K. Nagamatsu, and S. Watan- abe, “End-to-end neural speaker diarization with permutation-free objectives,” inProc. Interspeech, 2019, pp. 4300–4304
2019
-
[11]
End-to-end neural speaker diarization with self- attention,
Y . Fujita, N. Kanda, S. Horiguchi, Y . Xue, K. Nagamatsu, and S. Watanabe, “End-to-end neural speaker diarization with self- attention,” inProc. ASRU, 2019, pp. 296–303
2019
-
[12]
Target- speaker voice activity detection: a novel approach for multi- speaker diarization in a dinner party scenario,
I. Medennikov, M. Korenevsky, T. Prisyach, Y . Khokhlov, M. Ko- renevskaya, I. Sorokin, T. Timofeeva, A. Mitrofanov, A. An- drusenko, I. Podluzhny, A. Laptev, and A. Romanenko, “Target- speaker voice activity detection: a novel approach for multi- speaker diarization in a dinner party scenario,” inProc. Inter- speech, 2020, pp. 274–278
2020
-
[13]
Integrating end-to- end neural and clustering-based diarization: Getting the best of both worlds,
K. Kinoshita, M. Delcroix, and N. Tawara, “Integrating end-to- end neural and clustering-based diarization: Getting the best of both worlds,” inProc. ICASSP, 2021, pp. 7198–7202
2021
-
[14]
Encoder-decoder based attractors for end-to-end neural diariza- tion,
S. Horiguchi, Y . Fujita, S. Watanabe, Y . Xue, and P. Garc ´ıa, “Encoder-decoder based attractors for end-to-end neural diariza- tion,”IEEE/ACM TASLP, vol. 30, pp. 1493–1507, 2022
2022
-
[15]
Target speaker voice activity detection with transformers and its integra- tion with end-to-end neural diarization,
D. Wang, X. Xiao, N. Kanda, T. Yoshioka, and J. Wu, “Target speaker voice activity detection with transformers and its integra- tion with end-to-end neural diarization,” inProc. ICASSP, 2023
2023
-
[16]
EEND-M2F: Masked-attention mask transformers for speaker diarization,
M. H ¨ark¨onen, S. J. Broughton, and L. Samarakoon, “EEND-M2F: Masked-attention mask transformers for speaker diarization,” in Proc. Interspeech, 2024, pp. 37–41
2024
-
[17]
Sequence-to-sequence neural di- arization with automatic speaker detection and representation,
M. Cheng, Y . Lin, and M. Li, “Sequence-to-sequence neural di- arization with automatic speaker detection and representation,” IEEE TASLPRO, vol. 33, pp. 2719–2734, 2025
2025
-
[18]
pyannote.audio 2.1 speaker diarization pipeline: prin- ciple, benchmark, and recipe,
H. Bredin, “pyannote.audio 2.1 speaker diarization pipeline: prin- ciple, benchmark, and recipe,” inProc. Interspeech, 2023, pp. 1983–1987
2023
-
[19]
Powerset multi-class cross entropy loss for neural speaker diarization,
A. Plaquet and H. Bredin, “Powerset multi-class cross entropy loss for neural speaker diarization,” inProc. Interspeech, 2023, pp. 3222–3226
2023
-
[20]
Leveraging self-supervised learning for speaker diarization,
J. Han, F. Landini, J. Rohdin, A. Silnova, M. Diez, and L. Burget, “Leveraging self-supervised learning for speaker diarization,” in Proc. ICASSP, 2025
2025
-
[21]
Fine-tune before structured pruning: Towards compact and accurate self-supervised models for speaker diariza- tion,
J. Han, F. Landini, J. Rohdin, A. Silnova, M. Diez, J. Cernocky, and L. Burget, “Fine-tune before structured pruning: Towards compact and accurate self-supervised models for speaker diariza- tion,” inProc. Interspeech, 2025, pp. 1583–1587
2025
-
[22]
Can we really repurpose multi-speaker ASR corpus for speaker diarization?
S. Horiguchi, N. Tawara, T. Ashihara, A. Ando, and M. Delcroix, “Can we really repurpose multi-speaker ASR corpus for speaker diarization?” inProc. ASRU, 2025
2025
-
[23]
AISHELL-4: An open source dataset for speech enhancement, separation, recognition and speaker diarization in conference scenario,
Y . Fu, L. Cheng, S. Lv, Y . Jv, Y . Kong, Z. Chen, Y . Hu, L. Xie, J. Wu, H. Bu, X. Xu, J. Du, and J. Chen, “AISHELL-4: An open source dataset for speech enhancement, separation, recognition and speaker diarization in conference scenario,” inProc. Inter- speech, 2021, pp. 3665–3669
2021
-
[24]
Unleashing the killer corpus: experiences in creating the multi-everything AMI Meeting Corpus,
J. Carletta, “Unleashing the killer corpus: experiences in creating the multi-everything AMI Meeting Corpus,”Language Resources and Evaluation, vol. 41, no. 2, pp. 181–190, 2007
2007
-
[25]
M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,
F. Yu, S. Zhang, Y . Fu, L. Xie, S. Zheng, Z. Du, W. Huang, P. Guo, Z. Yan, B. Ma, X. Xu, and H. Bu, “M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,” inProc. ICASSP, 2022, pp. 6167–6171
2022
-
[26]
The fifth ‘CHiME’ Speech Separation and Recognition Challenge: dataset, task and baselines,
J. Barker, S. Watanabe, E. Vincent, and J. Trmal, “The fifth ‘CHiME’ Speech Separation and Recognition Challenge: dataset, task and baselines,” inProc. Interspeech, 2018, pp. 1561–1565
2018
-
[27]
DiPCo—dinner party corpus,
M. Van Segbroeck, A. Zaid, K. Kutsenko, C. Huerta, T. Nguyen, X. Luo, B. Hoffmeister, J. Trmal, M. Omologo, and R. Maas, “DiPCo—dinner party corpus,” inProc. Interspeech, 2020, pp. 434–436
2020
-
[28]
Front-end processing for the CHiME-5 dinner party scenario,
C. Boeddeker, J. Heitkaemper, J. Schmalenstoeer, L. Drude, J. Heymann, and R. Haeb-Umbach, “Front-end processing for the CHiME-5 dinner party scenario,” inProc. CHiME-5, 2018, pp. 35–40
2018
-
[29]
GPU-accelerated guided source separation for meeting transcription,
D. Raj, D. Povey, and S. Khudanpur, “GPU-accelerated guided source separation for meeting transcription,” inProc. Interspeech, 2023, pp. 3507–3511
2023
-
[30]
Moshi: a speech-text foundation model for real-time dialogue,
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,” arXiv:2410.00037, 2024
Pith/arXiv arXiv 2024
-
[31]
Y .-K. Fu, C.-K. Lee, H.-H. Wang, and H.-y. Lee, “Investigat- ing the effects of large-scale pseudo-stereo data and different speech foundation model on dialogue generative spoken language model,” arXiv:2407.01911, 2024
arXiv 2024
-
[32]
Towards a japanese full-duplex spoken dialogue system,
A. Ohashi, S. Iizuka, J. Jiang, and R. Higashinaka, “Towards a japanese full-duplex spoken dialogue system,” inProc. Inter- speech, 2025, pp. 1783–1787
2025
-
[33]
Be- yond turn-based interfaces: Synchronous LLMs as full-duplex di- alogue agents,
B. Veluri, B. Peloquin, B. Yu, H. Gong, and S. Gollakota, “Be- yond turn-based interfaces: Synchronous LLMs as full-duplex di- alogue agents,” inProc. NAACL, 2024, pp. 21 390–21 402
2024
-
[34]
W. Cui, L. Zhu, X. Li, and Z. Gui, “TurnGuide: Enhancing mean- ingfull full duplex spoken interactions via dynamic turn-level text- speech interleaving,” arxiv:2508.07375, 2026
Pith/arXiv arXiv 2026
-
[35]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. ICML, 2023, pp. 28 492–28 518
2023
-
[36]
Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,
S. Ghosh, A. Goel, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.- H. H. Yang, R. Duraiswami, D. Manocha, R. Valleet al., “Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,” inProc. NeurIPS, 2025
2025
-
[37]
First DIHARD challenge evaluation plan,
N. Ryant, K. Church, C. Cieri, A. Cristia, J. Du, S. Ganapathy, and M. Liberman, “First DIHARD challenge evaluation plan,” https://zenodo.org/record/1199638, 2018
arXiv 2018
-
[38]
The Second DIHARD Diarization Challenge: Dataset, task, and baselines,
——, “The Second DIHARD Diarization Challenge: Dataset, task, and baselines,” inProc. Interspeech, 2019, pp. 978–982
2019
-
[39]
The third DI- HARD diarization challenge,
N. Ryant, P. Singh, V . Krishnamohan, R. Varma, K. Church, C. Cieri, J. Du, S. Ganapathy, and M. Liberman, “The third DI- HARD diarization challenge,” inProc. Interspeech, 2021, pp. 3570–3574
2021
-
[40]
Third DIHARD challenge evaluation plan,
N. Ryant, K. Church, C. Cieri, J. Du, S. Ganapathy, and M. Liberman, “Third DIHARD challenge evaluation plan,” arXiv:2006.05815, 2020
arXiv 2006
-
[41]
Spot the conversation: Speaker diarisation in the wild,
J. S. Chung, J. Huh, A. Nagrani, T. Afouras, and A. Zisserman, “Spot the conversation: Speaker diarisation in the wild,” inProc. Interspeech, 2020, pp. 299–303
2020
-
[42]
Pretrain- ing multi-speaker identification for neural speaker diarization,
S. Horiguchi, A. Ando, M. Delcroix, and N. Tawara, “Pretrain- ing multi-speaker identification for neural speaker diarization,” in Proc. Interspeech, 2025, pp. 1608–1612
2025
-
[43]
Efficient and generalizable speaker diarization via structured pruning of self-supervised models,
J. Han, P. P ´alka, M. Delcroix, F. Landini, J. Rohdin, J. Cernock`y, and L. Burget, “Efficient and generalizable speaker diarization via structured pruning of self-supervised models,” arXiv:2506.18623, 2025
arXiv 2025
-
[44]
Learning with noisy labels,
N. Natarajan, I. S. Dhillon, P. K. Ravikumar, and A. Tewari, “Learning with noisy labels,” inProc. NeurIPS, vol. 26, 2013, pp. 1196–1204
2013
-
[45]
Making deep neural networks robust to label noise: A loss cor- rection approach,
G. Patrini, A. Rozza, A. Krishna Menon, R. Nock, and L. Qu, “Making deep neural networks robust to label noise: A loss cor- rection approach,” inProc. CVPR, 2017, pp. 1944–1952
2017
-
[46]
Does label smoothing mitigate label noise?
M. Lukasik, S. Bhojanapalli, A. Menon, and S. Kumar, “Does label smoothing mitigate label noise?” inProc. ICML. PMLR, 2020, pp. 6448–6458
2020
-
[47]
Learning to reweight examples for robust deep learning,
M. Ren, W. Zeng, B. Yang, and R. Urtasun, “Learning to reweight examples for robust deep learning,” inProc. ICML, 2018, pp. 4334–4343
2018
-
[48]
MentorNet: Learning data-driven curriculum for very deep neural networks on corrupted labels,
L. Jiang, Z. Zhou, T. Leung, L.-J. Li, and L. Fei-Fei, “MentorNet: Learning data-driven curriculum for very deep neural networks on corrupted labels,” inProc. ICML, 2018, pp. 2304–2313
2018
-
[49]
CurriculumNet: Weakly supervised learning from large-scale web images,
S. Guo, W. Huang, H. Zhang, C. Zhuang, D. Dong, M. R. Scott, and D. Huang, “CurriculumNet: Weakly supervised learning from large-scale web images,” inProc. ECCV, 2018, pp. 135–150
2018
-
[50]
Co-teaching: Robust training of deep neural net- works with extremely noisy labels,
B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I. Tsang, and M. Sugiyama, “Co-teaching: Robust training of deep neural net- works with extremely noisy labels,” inProc. NeurIPS, vol. 31, 2018, pp. 8527–8537
2018
-
[51]
How does disagreement help generalization against label corruption?
X. Yu, B. Han, J. Yao, G. Niu, I. Tsang, and M. Sugiyama, “How does disagreement help generalization against label corruption?” inProc. ICML, 2019, pp. 7164–7173
2019
-
[52]
DIVE: End-to-end speech diarization via iterative speaker embeddings,
N. Zeghidour, O. Teboul, and D. Grangier, “DIVE: End-to-end speech diarization via iterative speaker embeddings,” inProc. ASRU, 2021, pp. 702–709
2021
-
[53]
Collar-aware training for streaming speaker change detection in broadcast speech,
J. Kalda and T. Alum ¨ae, “Collar-aware training for streaming speaker change detection in broadcast speech,” inProc. Odyssey 2022, 2022, pp. 141–147
2022
-
[54]
Forward-backward convolu- tional recurrent neural networks and tag-conditioned convolu- tional neural networks for weakly labeled semi-supervised sound event detection,
J. Ebbers and R. Haeb-Umbach, “Forward-backward convolu- tional recurrent neural networks and tag-conditioned convolu- tional neural networks for weakly labeled semi-supervised sound event detection,” inProc. DCASE, 2020, pp. 41–45
2020
-
[55]
V oxCeleb: A large- scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: A large- scale speaker identification dataset,” inProc. Interspeech, 2017, pp. 2616–2620
2017
-
[56]
Mamba-based segmentation model for speaker diariza- tion,
A. Plaquet, N. Tawara, M. Delcroix, S. Horiguchi, A. Ando, and S. Araki, “Mamba-based segmentation model for speaker diariza- tion,” inProc. ICASSP, 2025
2025
-
[57]
WavLM: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiaoet al., “WavLM: Large-scale self- supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[58]
ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,” inProc. Interspeech, 2020, pp. 3830–3834
2020
-
[59]
Reshape dimensions network for speaker recognition,
I. Yakovlev, R. Makarov, A. Balykin, P. Malov, A. Okhotnikov, and N. Torgashov, “Reshape dimensions network for speaker recognition,” inProc. Interspeech, 2024, pp. 3235–3239
2024
-
[60]
V oxCeleb: Large-scale speaker verification in the wild,
A. Nagrani, J. S. Chung, W. Xie, and A. Zisserman, “V oxCeleb: Large-scale speaker verification in the wild,”Computer Speech & Language, vol. 60, p. 101027, 2020
2020
-
[61]
Squeeze-and-excitation networks,
J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” inProc. CVPR, 2018, pp. 7132–7141
2018
-
[62]
Dual-mode ASR: Unify and improve streaming ASR with full-context modeling,
J. Yu, W. Han, A. Gulati, C.-C. Chiu, B. Li, T. N. Sainath, Y . Wu, and R. Pang, “Dual-mode ASR: Unify and improve streaming ASR with full-context modeling,” inProc. ICLR, 2021
2021
-
[63]
MSDWild: Multi- modal speaker diarization dataset in the wild,
T. Liu, S. Fan, X. Xiang, H. Song, S. Lin, J. Sun, T. Han, S. Chen, B. Yao, S. Liu, Y . Wu, Y . Qian, and K. Yu, “MSDWild: Multi- modal speaker diarization dataset in the wild,” inProc. Inter- speech, 2022, pp. 1476–1480
2022
-
[64]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,” inProc. ICLR, 2015
2015
-
[65]
SE-DiCoW: Self-enrolled diarization-conditioned Whisper,
A. Polok, D. Klement, S. Cornell, M. Wiesner, J. ˇCernock`y, S. Khudanpur, and L. Burget, “SE-DiCoW: Self-enrolled diarization-conditioned Whisper,” inProc. ICASSP, 2026
2026
-
[66]
MeetEval: A toolkit for computation of word error rates for meeting transcription systems,
T. von Neumann, C. Boeddeker, M. Delcroix, and R. Haeb- Umbach, “MeetEval: A toolkit for computation of word error rates for meeting transcription systems,” inProc. CHiME, 2023, pp. 27–32
2023
-
[67]
Speech enhancement us- ing self-supervised pre-trained model and vector quantization,
X.-Y . Zhao, Q.-S. Zhu, and J. Zhang, “Speech enhancement us- ing self-supervised pre-trained model and vector quantization,” in Proc. APSIPA ASC, 2022, pp. 330–334
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.