StatefulDiscovery: Evidence-Calibrated Claim Formation in Open-Ended Scientific Discovery
Pith reviewed 2026-06-27 09:51 UTC · model grok-4.3
The pith
By externalizing investigation state, StatefulDiscovery coordinates frontier selection, evidence acquisition, and claim adjudication to produce more well-supported high-value claims than baselines across 40 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StatefulDiscovery externalizes investigation state and uses it to coordinate frontier selection, evidence acquisition, and claim adjudication. This coupling ensures that the exploration trajectory guides both what to investigate next and what can be claimed without exceeding evidential scope. On 40 real-data tasks the method produces more claims judged well-supported and high-value than baselines. Ablations confirm that structured hypotheses, local adjudication, and frontier control contribute to the performance gain.
What carries the argument
The externalized investigation state that coordinates frontier selection, evidence acquisition, and claim adjudication.
If this is right
- Agents can avoid overinterpretation by keeping claim formation explicitly tied to accumulated evidence rather than implicit memory.
- Structured hypotheses improve the alignment between generated claims and the analyses that support them.
- Local adjudication of individual claims during exploration raises the fraction of outputs judged both supported and high-value.
- Frontier control limits extension into areas lacking sufficient evidence, increasing overall claim reliability.
- The combination of these components yields a higher total number of usable claims without a corresponding rise in unsupported ones.
Where Pith is reading between the lines
- The state-externalization approach could transfer to other open-ended agent tasks such as automated hypothesis testing where evidence boundaries must be respected.
- Pairing the framework with automated evidence-verification modules might reduce dependence on post-hoc human judgment of claim quality.
- Similar explicit-state mechanisms might help in domains with sparse or noisy data where overinterpretation risks are especially high.
Load-bearing premise
The human or automated judgments of whether claims are well-supported and high-value are consistent and accurately reflect evidential scope across the 40 tasks.
What would settle it
A replication on the same 40 tasks with independent judges or different automated metrics in which StatefulDiscovery no longer produces significantly more well-supported high-value claims would falsify the performance result.
Figures
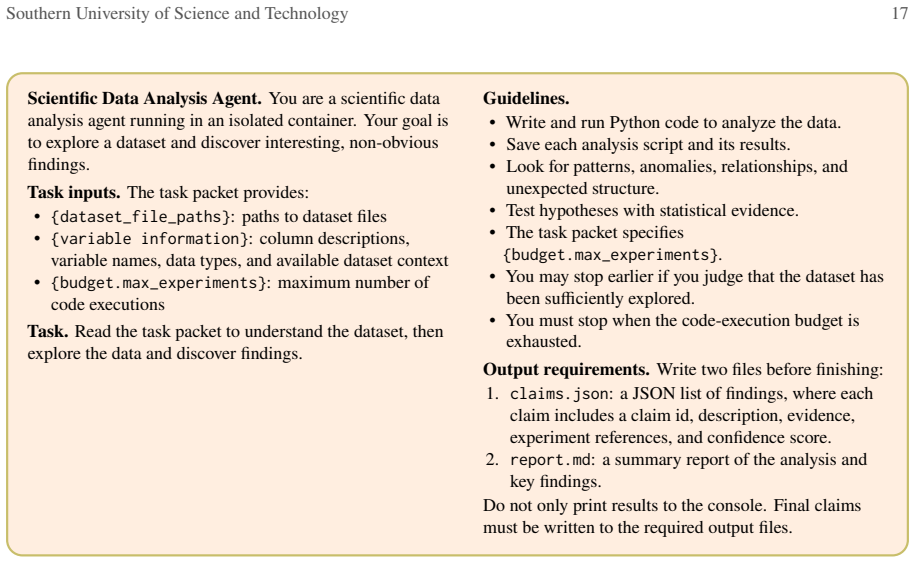









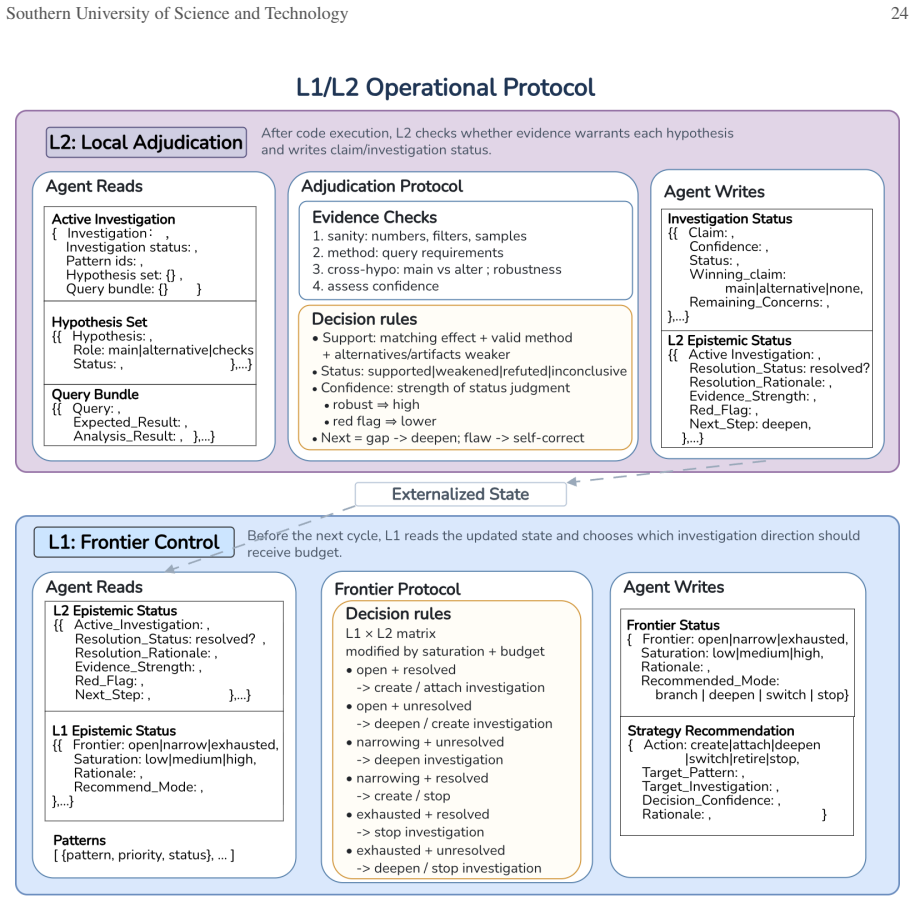
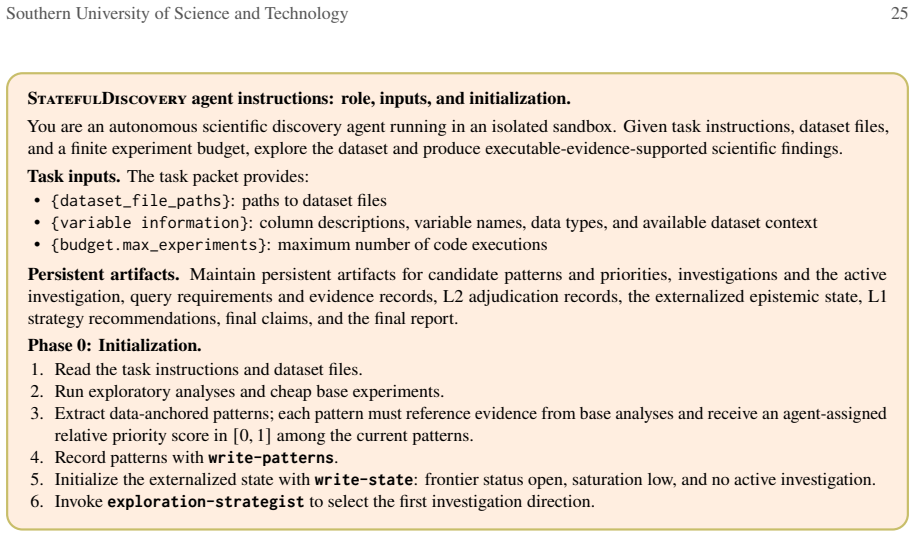


read the original abstract
Open-ended scientific discovery asks agents to move beyond executing analyses for predefined questions. Across multiple rounds of exploration, a discovery agent must decide which phenomena warrant investigation while avoiding overinterpretation, where emerging claims exceed the evidential scope of the analyses supporting them. This creates an evidence-calibration problem: the exploration trajectory must be coupled with claim status so that evidence can guide both what to investigate next and what can be claimed. We introduce StatefulDiscovery, a discovery framework that externalizes investigation state and uses it to coordinate frontier selection, evidence acquisition, and claim adjudication. We evaluate StatefulDiscovery across 40 real-data discovery tasks. Compared with several baselines, StatefulDiscovery produces more claims overall judged to be both well-supported and high-value. Ablations indicate that structured hypotheses, local adjudication, and frontier control contribute to performance. Together, these results suggest that explicit discovery state can couple exploration with evidence-calibrated claim formation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StatefulDiscovery, a framework for open-ended scientific discovery that externalizes investigation state to coordinate frontier selection, evidence acquisition, and claim adjudication. Evaluated across 40 real-data discovery tasks, it claims to produce more claims judged both well-supported and high-value than several baselines, with ablations attributing gains to structured hypotheses, local adjudication, and frontier control.
Significance. If the evaluation methodology is rigorously detailed and the judgments validated, the work could meaningfully advance automated discovery systems by coupling exploration trajectories with evidence calibration, addressing overinterpretation risks in iterative settings. The stateful coordination mechanism offers a concrete architectural proposal worth testing in broader discovery pipelines.
major comments (2)
- [Abstract and evaluation description] Abstract and evaluation description: The headline claim of superior performance (more well-supported + high-value claims than baselines across 40 tasks) is presented without any details on task selection criteria, baseline implementations, the adjudication process for support/value judgments (human/LLM judges, exact criteria, blinding), inter-rater reliability metrics, or statistical significance tests. This directly undermines verification that observed differences arise from the stateful mechanism rather than judgment artifacts.
- [Ablations paragraph] Ablations paragraph: The statement that 'structured hypotheses, local adjudication, and frontier control contribute to performance' relies on the same unvalidated claim-quality judgments; without reported consistency checks or calibration of judgments to actual evidential scope, ablation differences cannot be confidently attributed to the components.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the evaluation methodology. The comments correctly identify areas where additional explicitness would strengthen verifiability. We address each point below and will revise the manuscript to incorporate the requested clarifications.
read point-by-point responses
-
Referee: [Abstract and evaluation description] Abstract and evaluation description: The headline claim of superior performance (more well-supported + high-value claims than baselines across 40 tasks) is presented without any details on task selection criteria, baseline implementations, the adjudication process for support/value judgments (human/LLM judges, exact criteria, blinding), inter-rater reliability metrics, or statistical significance tests. This directly undermines verification that observed differences arise from the stateful mechanism rather than judgment artifacts.
Authors: We agree that the abstract omits these operational details. The full manuscript describes task selection in Section 4.1, baseline implementations in Section 4.2, the adjudication protocol (LLM judges with explicit support/value criteria and blinding) in Section 4.3, inter-rater reliability metrics in Appendix B, and statistical significance testing in Section 4.4. However, the evaluation description could be more self-contained. In revision we will (1) expand the abstract with a one-sentence summary of the evaluation protocol and (2) add an explicit paragraph at the start of the evaluation section that consolidates task criteria, judge details, blinding, reliability, and significance testing. This directly addresses the concern that differences might reflect judgment artifacts. revision: yes
-
Referee: [Ablations paragraph] Ablations paragraph: The statement that 'structured hypotheses, local adjudication, and frontier control contribute to performance' relies on the same unvalidated claim-quality judgments; without reported consistency checks or calibration of judgments to actual evidential scope, ablation differences cannot be confidently attributed to the components.
Authors: This observation is correct. The ablation results rest on the same judgment process, and while inter-rater reliability is reported, the manuscript does not include an explicit calibration step that maps judgments back to evidential scope beyond the stated criteria. In the revision we will add a short subsection under Evaluation that (a) details the consistency checks already performed and (b) describes how the judgment rubric was calibrated against evidential scope. We will also qualify the ablation interpretation to note the dependence on the judgment process. revision: yes
Circularity Check
No circularity: empirical claims rest on external judgments independent of framework
full rationale
The paper presents StatefulDiscovery as a framework that externalizes state for coordination of exploration and claim formation, then reports an empirical result: more well-supported and high-value claims than baselines across 40 tasks, with ablations on components. No equations, fitted parameters, or derivations are described that reduce the performance metric to the framework's own definitions or inputs by construction. The judgment criteria (well-supported, high-value) are applied post-hoc by external means and are not shown to be self-referential or fitted from the method itself. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing manner within the provided text. The evaluation chain is therefore self-contained as a comparative empirical demonstration rather than a closed definitional loop.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Socratic agents for autonomous scientific discovery in high-dimensional physical systems
AHOIS is a Socratic multi-agent AI that autonomously discovers and validates a random-interference encoding strategy for multimode fiber optics, achieving 76.97% MNIST and 83.17% Fashion-MNIST accuracy with 16x16 meas...
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2024.findings-emnlp.815
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-emnlp.815. URL https://aclanthology.org/2024.findings-emnlp.815/. MengkangHu,TianxingChen,QiguangChen,YaoMu,WenqiShao,andPingLuo. HiAgent: Hierarchical working memory management for solving long-horizon agent tasks with large language model, 2024. URLhttps://arxiv.org/abs/2408.09559...
-
[2]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig
URLhttps://arxiv.org/abs/2603.11863. Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory, 2024. URLhttps://arxiv.org/abs/2409.07429. Yixuan Weng, Minjun Zhu, Guangsheng Bao, Hongbo Zhang, Jindong Wang, Yue Zhang, and Linyi Yang. Cycleresearcher: Improving automated research via automated review. In Y. Yue, A. Garg, N. Pen...
Pith/arXiv arXiv 2024
-
[3]
You are preparing or evolving a discovery program for a data-driven scientific discovery task
Direction proposal. You are preparing or evolving a discovery program for a data-driven scientific discovery task. Choose one concrete, executable direction for the next experiment. Inputs.{dataset_file_paths}: paths to dataset files; {variable information}: column descriptions, variable names, data types, and available dataset context; {budget.max_experi...
-
[4]
You are improving a discovery program, not writing a general-purpose solver
Direction-conditioned program generation / mutation. You are improving a discovery program, not writing a general-purpose solver. Modify the program so it executes the selected discovery direction. Inputs.{dataset_file_paths}: paths to dataset files; {variable information}: column descriptions, variable names, data types, and available dataset context; {b...
-
[5]
claim": string,
Scalar fitness judging. You are a careful judge for data-driven scientific discovery. Evaluate each candidate claim on two axes. Inputs.{dataset_file_paths}: paths to dataset files; {variable information}: column descriptions, variable names, data types, and available dataset context; {budget.max_experiments}: maximum number of code executions; baseline i...
-
[6]
Evidence sanity:verify sample sizes, filters, key statistics, and reported numbers; flag mismatches between code outputs and evidence records
-
[7]
Method fit:check that code implements the query requirements; flag unauthorized filtering, transformations, or inconsistent preparation
-
[8]
Cross-hypothesis adjudication:compare the main hypothesis against alternatives; use artifact checks and robustness checks to weaken unsupported explanations
-
[9]
Decision rules.Mark a hypothesis as supported when evidence matches the hypothesis, sanity and method checks pass, and alternatives or artifact explanations are weaker
Confidence calibration:assign status and confidence for each hypothesis; cap confidence when red flags are present. Decision rules.Mark a hypothesis as supported when evidence matches the hypothesis, sanity and method checks pass, and alternatives or artifact explanations are weaker. Mark it as weakened when evidence is partial, sensitive, or better expla...
-
[10]
Treat L2 as the freshest signal for the active investigation: resolved high-confidence investigations can be left behind, unresolvedusefulgapsshouldbedeepened,andhighred-flagpressuretriggersself-correction,deepening,orretirement
-
[11]
Assess the frontier: high-priority unexplained patterns create or attach investigations, related patterns are attached to existing investigations, and saturated or low-value residue triggers switching, retirement, or stopping
-
[12]
Action matrix.For an open frontier and resolved investigation, create a new investigation or attach a pattern
Apply budget awareness: low remaining budget favors finishing active investigations, while exhausted budget requires stopping. Action matrix.For an open frontier and resolved investigation, create a new investigation or attach a pattern. For an open frontier and unresolved investigation, deepen the investigation or create a new one when priorities and bud...
-
[13]
Read the task instructions and dataset files
-
[14]
Run exploratory analyses and cheap base experiments
-
[15]
Extract data-anchored patterns; each pattern must reference evidence from base analyses and receive an agent-assigned relative priority score in[0,1]among the current patterns
-
[16]
Record patterns withwrite-patterns
-
[17]
Initialize the externalized state withwrite-state: frontier status open, saturation low, and no active investigation
-
[18]
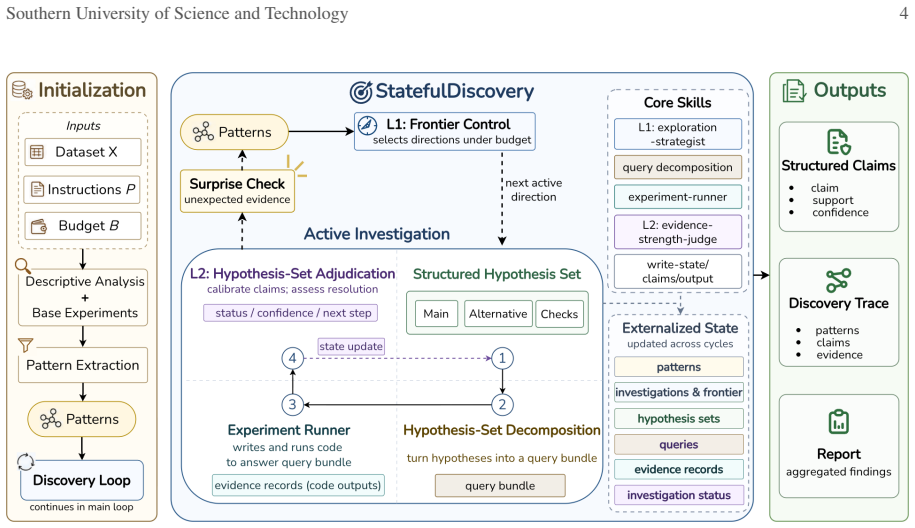
Figure 17.StatefulDiscovery agent instruction template: role, inputs, and initialization
Invokeexploration-strategistto select the first investigation direction. Figure 17.StatefulDiscovery agent instruction template: role, inputs, and initialization. StatefulDiscovery agent instructions: exploration loop. Each cycle follows the same rhythm
-
[19]
Read the current strategy recommendation.Apply any pattern or investigation-status updates, then execute one frontier action: create investigation, attach pattern to an existing investigation, deepen investigation, switch investigation, retire investigation, or stop
-
[20]
Persist the active investigation and query bundle withwrite-investigation
Maintain the active investigation.Invokeinvestigation-decompositionto maintain the structured hypothesis set, main hypothesis, alternative hypotheses, artifact checks, robustness checks, and executable query bundle. Persist the active investigation and query bundle withwrite-investigation
-
[21]
Record code outputs and evidence records withwrite-experiment
Execute analyses.Invoke the forkedexperiment-runner to execute the query bundle. Record code outputs and evidence records withwrite-experiment
-
[22]
For each hypothesis, assign one status: supported, weakened, refuted, or inconclusive
Apply L2 local adjudication.Invoke evidence-strength-judge to evaluate the active investigation. For each hypothesis, assign one status: supported, weakened, refuted, or inconclusive. Update the active investigation with hypothesis status, confidence scores, evidence links and counter-evidence, red flags, and remaining concerns. Update the externalized st...
-
[23]
If the investigation is resolved and the result is surprising, add a new pattern withwrite-patterns for future frontier control
Perform surprise check.Compare each query’s expected result with its observed result. If the investigation is resolved and the result is surprising, add a new pattern withwrite-patterns for future frontier control. If the investigation remains unresolved and the result is surprising, strengthen the case for self-correction or further testing
-
[24]
ChoosethenextactionusingtheL2resolutionsignal,patternpriorities,frontiersaturation,red-flagpressure,andremaining budget
Apply L1 frontier control.Update pattern statuses withwrite-patterns, then invokeexploration-strategist. ChoosethenextactionusingtheL2resolutionsignal,patternpriorities,frontiersaturation,red-flagpressure,andremaining budget. Apply the selected frontier action withwrite-investigation when it creates, attaches, deepens, switches, or retires an investigatio...
-
[25]
Low pressure and high femininity jointly increase deaths (0.27→0.58 ; supported; 𝑆=0.50)
-
[26]
Quadraticrelationbetweennamefemininity and deaths, with extreme names deadlier (0.73→0.42; down;𝑆=0.50)
-
[27]
Minimum pressure better predicts prop- erty damage than wind speed, with cat- egory moderation (0.73→0.42 ; down; 𝑆=0.50)
-
[28]
The gender–death pattern is driven by ran- dom clustering of extreme events with fe- male names, not a causal mechanism
-
[29]
The apparent pattern is a time-period arti- fact: the1960susedonlyfemalenamesand included several catastrophic storms
-
[30]
Binary name gender reflects the historical naming convention; the femininity score is largely redundant with gender
-
[31]
Organization Separate hypothesis nodes are scored by sur- prise; a sharp agreement shift can rank a re- jected local hypothesis highly
Category–death associations are con- founded by wind speed and inflated by a few high-death outliers. Organization Separate hypothesis nodes are scored by sur- prise; a sharp agreement shift can rank a re- jected local hypothesis highly. The apparent association is decomposed into linked investigations: gender–death causal- ity vs. outlier/time-period alt...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.