APT: Action Expert Pretraining Improves Instruction Generalization of Vision-Language-Action Policies
Pith reviewed 2026-06-27 09:47 UTC · model grok-4.3
The pith
Pretraining the action expert on vision-action pairs before language integration improves generalization of vision-language-action policies to unseen instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
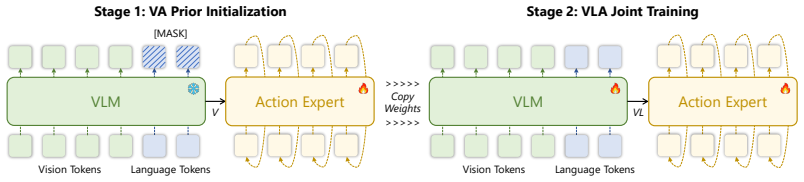
APT factorizes the policy into a language-agnostic vision-action prior and a language-conditioned VLA likelihood; the action expert is pretrained as the prior on vision-action pairs from a frozen VLM, after which language tokens are injected via gated fusion to produce the full policy without corrupting the prior or the VLM's language capability.
What carries the argument
The two-stage training process that pretrains the action expert as a vision-action prior on frozen-VLM pairs, followed by gated fusion to incorporate language tokens.
If this is right
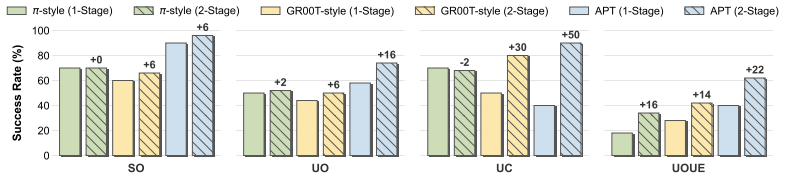
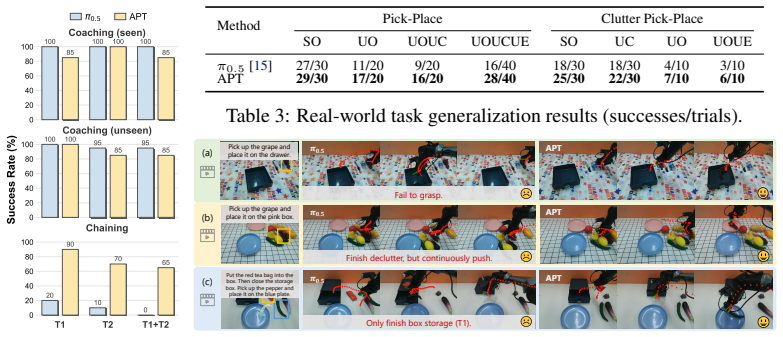
- APT produces consistent gains on unseen instructions.
- APT improves performance on compositional tasks.
- The method applies to mainstream VLA architectures.
Where Pith is reading between the lines
- The pretraining approach could lower the amount of diverse language data required to train capable VLA policies.
- Similar modality-specific pretraining might help other multimodal control settings where one input type dominates the data distribution.
- Evaluating the learned prior on physical robots with novel verbal commands would test whether the gains transfer beyond simulation.
Load-bearing premise
Pretraining the action expert solely on vision-action pairs produces a language-agnostic prior that the gated fusion stage can integrate without losing the VLM's language capability or introducing new imbalances.
What would settle it
An ablation that removes the pretraining stage, trains the action expert from random initialization on the full imbalanced dataset, and measures equivalent or superior generalization to unseen instructions would falsify the claim.
Figures










read the original abstract
Vision-Language-Action (VLA) models that couple pretrained Vision-Language Models (VLMs) with continuous action experts have achieved strong manipulation performance, yet generalization to out-of-distribution (OOD) language instructions remains poor. A known challenge is the structural imbalance in VLA data, where language is far less diverse than visual and action content, making policies prone to visual shortcuts. While discrete-action methods mitigate this through vision-language co-training, continuous action experts lack such protection: they start from random initialization and learn entirely from imbalanced data, producing noisy gradients that corrupt the VLM and fail to exploit its language capability. We address this from a Bayesian perspective, factorizing the policy into a language-agnostic Vision-Action (VA) prior and a language-conditioned VLA likelihood, and propose APT, a two-stage training method emphasizing Action expert PreTraining. In Stage 1, the action expert is pretrained as a VA prior on vision-action pairs from a frozen VLM, bypassing the language imbalance. In Stage 2, language tokens are injected through a gated fusion mechanism that integrates VLM features while preserving the learned visuomotor prior. APT applies to mainstream VLA architectures, including the $\pi$ and GR00T-style architectures. Comprehensive experiments validate that APT achieves consistent gains on unseen instructions and compositional tasks. Project Page: https://xukechun.github.io/papers/APT/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes APT, a two-stage training method for Vision-Language-Action (VLA) policies that factorizes the policy into a language-agnostic Vision-Action (VA) prior and a language-conditioned VLA likelihood. In Stage 1 the action expert is pretrained on vision-action pairs from a frozen VLM; in Stage 2 language tokens are injected via a gated fusion mechanism. The approach is claimed to apply to mainstream architectures including π and GR00T-style models and to deliver consistent gains on unseen instructions and compositional tasks by mitigating language imbalance in the training data.
Significance. If the experimental gains hold, the method supplies a practical Bayesian-motivated factorization that isolates visuomotor pretraining from language conditioning, potentially allowing better exploitation of pretrained VLMs without noisy gradients corrupting language capability. This addresses a recognized structural imbalance in continuous-action VLA data and could improve OOD instruction generalization across existing architectures.
major comments (1)
- [Abstract] Abstract: the central claim of 'consistent gains on unseen instructions and compositional tasks' rests on 'comprehensive experiments,' yet the manuscript provides no information on dataset sizes, baseline comparisons, error bars, ablation controls, or statistical significance, rendering it impossible to verify whether the reported improvements are supported by the data or affected by post-hoc choices.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. The concern about insufficient experimental transparency in the abstract is valid, and we address it directly below while committing to revisions that improve verifiability without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent gains on unseen instructions and compositional tasks' rests on 'comprehensive experiments,' yet the manuscript provides no information on dataset sizes, baseline comparisons, error bars, ablation controls, or statistical significance, rendering it impossible to verify whether the reported improvements are supported by the data or affected by post-hoc choices.
Authors: We agree the abstract is overly concise and omits key experimental metadata, which limits immediate verification. The manuscript body details the datasets (including sizes and sources), baseline architectures and implementations, ablation studies isolating the pretraining and fusion components, and results aggregated over multiple random seeds. We will revise the abstract to explicitly state dataset sizes, number of baselines evaluated, presence of ablations, and that reported gains include error bars. If statistical significance tests (e.g., paired t-tests) are absent from the current results, we will add them in the revision to strengthen the evidence for consistent OOD gains. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper describes a two-stage training procedure (pretrain action expert on vision-action pairs with frozen VLM, then gated language fusion) as an independent methodological fix for data imbalance. No equations, fitted parameters renamed as predictions, or self-citations appear as load-bearing elements in the derivation chain. The Bayesian factorization is presented as a modeling choice rather than a derived result that reduces to its inputs. The approach is self-contained against external benchmarks via described experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The policy distribution can be factorized into a language-agnostic vision-action prior and a language-conditioned VLA likelihood.
invented entities (1)
-
gated fusion mechanism
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Learning Action Priors for Cross-embodiment Robot Manipulation
A two-stage framework pretrains an action module with temporal motion priors from unconditioned trajectories using flow-matching, then transfers it to VLA training via decoder reuse and distillation, yielding better p...
Reference graph
Works this paper leans on
-
[1]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[2]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[3]
G. A. Team. Gen-0: Embodied foundation models that scale with physical interaction.Gener- alist AI Blog, 2025. https://generalistai.com/blog/preview-uqlxvb-bb.html
2025
-
[4]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. Libero-pro: To- wards robust and fair evaluation of vision-language-action models beyond memorization.arXiv preprint arXiv:2510.03827, 2025
Pith/arXiv arXiv 2025
-
[5]
J. Gao, S. Belkhale, S. Dasari, A. Balakrishna, D. Shah, and D. Sadigh. A taxonomy for evaluating generalist robot policies.arXiv preprint arXiv:2503.01238, 2025
arXiv 2025
-
[6]
K. Xu, Z. Zhu, A. Chen, S. Zhao, Q. Huang, Y . Yang, H. Lu, R. Xiong, M. Tomizuka, and Y . Wang. Seeing to act, prompting to specify: A bayesian factorization of vision language action policy.arXiv preprint arXiv:2512.11218, 2025
arXiv 2025
-
[7]
Y . Fang, Y . Feng, D. Jing, J. Liu, Y . Yang, Z. Wei, D. Szafir, and M. Ding. When vision overrides language: Evaluating and mitigating counterfactual failures in vlas.arXiv preprint arXiv:2602.17659, 2026
arXiv 2026
-
[8]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning (CoRL), pages 2165–2183. PMLR, 2023
2023
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL), pages 2679–2713, 2024
2024
-
[10]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[11]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
Pith/arXiv arXiv 2025
-
[12]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, et al. Cot- vla: Visual chain-of-thought reasoning for vision-language-action models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1702– 1713, 2025. 9
2025
-
[13]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. RDT-1B: A dif- fusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[14]
J. Wen, Y . Zhu, M. Zhu, Z. Tang, J. Li, Z. Zhou, X. Liu, C. Shen, Y . Peng, and F. Feng. Diffusionvla: Scaling robot foundation models via unified diffusion and autoregression. In International Conference on Machine Learning (ICML), pages 66558–66574. PMLR, 2025
2025
-
[15]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[16]
Driess, J
D. Driess, J. T. Springenberg, L. Yu, A. Li-Bell, K. Pertsch, A. Z. Ren, H. Walke, Q. Vuong, L. X. Shi, S. Levine, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[17]
Bjorck, F
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1.5: An improved open foundation model for generalist humanoid robots. 2025
2025
-
[18]
Y . Zhong, F. Bai, S. Cai, X. Huang, Z. Chen, X. Zhang, Y . Wang, S. Guo, T. Guan, K. N. Lui, et al. A survey on vision-language-action models: An action tokenization perspective.arXiv preprint arXiv:2507.01925, 2025
Pith/arXiv arXiv 2025
-
[19]
X. Li, P. Li, L. Qian, M. Liu, D. Wang, J. Liu, B. Kang, X. Ma, X. Wang, D. Guo, et al. What matters in building vision-language-action models for generalist robots.Nature Machine Intelligence, pages 1–15, 2026
2026
-
[20]
C. Cui, P. Ding, W. Song, S. Bai, X. Tong, Z. Ge, R. Suo, W. Zhou, Y . Liu, B. Jia, et al. Openhelix: A short survey, empirical analysis, and open-source dual-system vla model for robotic manipulation.arXiv preprint arXiv:2505.03912, 2025
arXiv 2025
-
[21]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale. Robotics: Science and Systems (RSS), 2023
2023
-
[22]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[23]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.Robotics: Science and Systems (RSS), 2023
2023
-
[24]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. Vima: Robot manipulation with multimodal prompts. InInternational Conference on Machine Learning (ICML), pages 14975–15022, 2023
2023
-
[25]
O. X.-E. Collaboration. Open X-Embodiment: Robotic learning datasets and RT-X models. https://arxiv.org/abs/2310.08864, 2023
Pith/arXiv arXiv 2023
-
[26]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. DROID: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems (RSS), 2024
2024
-
[27]
H.-S. Fang, H. Fang, Z. Tang, J. Liu, C. Wang, J. Wang, H. Zhu, and C. Lu. Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot. InIEEE International Conference on Robotics and Automation (ICRA), pages 653–660. IEEE, 2024. 10
2024
-
[28]
K. Wu, C. Hou, J. Liu, Z. Che, X. Ju, Z. Yang, M. Li, Y . Zhao, Z. Xu, G. Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024
Pith/arXiv arXiv 2024
-
[29]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[30]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[31]
H. Geng, F. Wang, S. Wei, Y . Li, B. Wang, B. An, C. T. Cheng, H. Lou, P. Li, Y .-J. Wang, et al. Roboverse: Towards a unified platform, dataset and benchmark for scalable and generalizable robot learning.arXiv preprint arXiv:2504.18904, 2025
arXiv 2025
-
[32]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[33]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[34]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[35]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[36]
M. Zhu, Y . Zhu, J. Li, J. Wen, Z. Xu, N. Liu, R. Cheng, C. Shen, Y . Peng, F. Feng, et al. Scaling diffusion policy in transformer to 1 billion parameters for robotic manipulation. InIEEE Inter- national Conference on Robotics and Automation (ICRA), pages 10838–10845. IEEE, 2025
2025
-
[37]
J. Liu, H. Chen, P. An, Z. Liu, R. Zhang, C. Gu, X. Li, Z. Guo, S. Chen, M. Liu, et al. Hy- bridvla: Collaborative diffusion and autoregression in a unified vision-language-action model. arXiv preprint arXiv:2503.10631, 2025
Pith/arXiv arXiv 2025
-
[38]
Q. Bu, H. Li, L. Chen, J. Cai, J. Zeng, H. Cui, M. Yao, and Y . Qiao. Towards synergistic, gen- eralized, and efficient dual-system for robotic manipulation.arXiv preprint arXiv:2410.08001, 2024
arXiv 2024
-
[39]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
- [40]
-
[41]
W. Wu, F. Lu, Y . Wang, S. Yang, S. Liu, F. Wang, Q. Zhu, H. Sun, Y . Wang, S. Ma, et al. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
Pith/arXiv arXiv 2026
-
[42]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[43]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. DreamVLA: A vision-language-action model dreamed with comprehensive world knowledge. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 11
2025
-
[44]
J. Sun, W. Zhang, Z. Qi, S. Ren, Z. Liu, H. Zhu, G. Sun, X. Jin, and Z. Chen. VLA- JEPA: Enhancing vision-language-action model with latent world model.arXiv preprint arXiv:2602.10098, 2026
arXiv 2026
-
[45]
P. Intelligence, B. Ai, A. Amin, R. Aniceto, A. Balakrishna, G. Balke, K. Black, G. Bokin- sky, S. Cao, T. Charbonnier, et al.π 0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026
Pith/arXiv arXiv 2026
-
[46]
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[47]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems (NeurIPS), 36:44776–44791, 2023
2023
-
[48]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
Pith/arXiv arXiv 2025
-
[49]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
-
[50]
J. Guo, Z. Wu, C. Tu, Y . Ma, X. Kong, Z. Liu, J. Ji, S. Zhang, Y . Chen, K. Chen, et al. On robustness of vision-language-action model against multi-modal perturbations.arXiv preprint arXiv:2510.00037, 2025
arXiv 2025
-
[51]
S. Orjuela et al. Robust skills, brittle grounding: Diagnosing restricted generalization in vision- language action policies via multi-object picking.arXiv preprint arXiv:2602.24143, 2026
arXiv 2026
-
[52]
S. L. Wanna, A. Luhtaru, R. Barron, J. Salfity, J. Moore, C. Matuszek, and M. Pryor. Let’s talk about language! investigating linguistic diversity in embodied ai datasets. In1st Work- shop on Safely Leveraging Vision-Language Foundation Models in Robotics: Challenges and Opportunities
-
[53]
I. Fang, J. Zhang, S. Tong, and C. Feng. From intention to execution: Probing the generaliza- tion boundaries of vision-language-action models.arXiv preprint arXiv:2506.09930, 2025
arXiv 2025
-
[54]
S. Lian, B. Yu, X. Lin, L. T. Yang, Z. Shen, C. Wu, Y . Miao, C. Huang, and K. Chen. Lang- Force: Bayesian decomposition of vision language action models via latent action queries. arXiv preprint arXiv:2601.15197, 2026
Pith/arXiv arXiv 2026
-
[55]
S. Yang, H. Li, Y . Chen, B. Wang, Y . Tian, T. Wang, H. Wang, F. Zhao, Y . Liao, and J. Pang. Instructvla: Vision-language-action instruction tuning from understanding to manipulation. arXiv preprint arXiv:2507.17520, 2025
arXiv 2025
-
[56]
C. Cheang, S. Chen, Z. Cui, Y . Hu, L. Huang, T. Kong, H. Li, Y . Li, Y . Liu, X. Ma, et al. Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
Pith/arXiv arXiv 2025
-
[57]
Huang, F
H. Huang, F. Liu, L. Fu, T. Wu, M. Mukadam, J. Malik, K. Goldberg, and P. Abbeel. Otter: A vision-language-action model with text-aware visual feature extraction. InInternational Conference on Machine Learning (ICML)
-
[58]
Nakamoto, O
M. Nakamoto, O. Mees, A. Kumar, and S. Levine. Steering your generalists: Improving robotic foundation models via value guidance. InConference on Robot Learning (CoRL), pages 4996–5013. PMLR, 2025
2025
-
[59]
Y . Wu, R. Tian, G. Swamy, and A. Bajcsy. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment.arXiv preprint arXiv:2502.01828, 2025. 12
arXiv 2025
- [60]
-
[61]
Z. Zhan, Y . Chen, J. Zhou, Q. Lv, H. Liu, K. Wang, L. Lin, and G. Wang. Stable language guidance for vision-language-action models.arXiv preprint arXiv:2601.04052, 2026
Pith/arXiv arXiv 2026
-
[62]
Perez, F
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 32, pages 3942–3951, 2018
2018
-
[63]
M. Fu, J. Yu, K. El-Refai, E. Kou, H. Xue, H. Huang, W. Xiao, G. Wang, F.-F. Li, G. Shi, et al. Cap-x: A framework for benchmarking and improving coding agents for robot manipulation. arXiv preprint arXiv:2603.22435, 2026
arXiv 2026
-
[64]
Z. Xu, Z. He, J. Wu, and S. Song. Learning 3d dynamic scene representations for robot manipulation. InConference on Robot Learning (CoRL), pages 126–142. PMLR, 2021
2021
-
[65]
Z. Chen, Q. Yan, Y . Chen, T. Wu, J. Zhang, Z. Ding, J. Li, Y . Yang, and H. Dong. ClutterDex- Grasp: A Sim-to-Real system for general dexterous grasping in cluttered scenes. InConference on Robot Learning (CoRL), pages 885–905. PMLR, 2025
2025
-
[66]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5738–5746, 2019
2019
-
[67]
A. Chen, Y . Yang, Z. Zhu, K. Xu, Z. Zhou, R. Xiong, and Y . Wang. Toward embodiment equivariant vision-language-action policy.arXiv preprint arXiv:2509.14630, 2025
arXiv 2025
-
[68]
R. Li, B. Yi, J. Liu, H. Gao, Y . Ma, and A. Kanazawa. Cameras as relative positional encoding. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[69]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[70]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems (NeurIPS), 33:6840–6851, 2020
2020
-
[71]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Con- ference on Learning Representations
-
[72]
Y . Tian, Y . Yang, Y . Xie, Z. Cai, X. Shi, N. Gao, H. Liu, X. Jiang, Z. Qiu, F. Yuan, et al. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 976–985, 2026
2026
-
[73]
X. Chen, Y . Chen, Y . Fu, N. Gao, J. Jia, W. Jin, H. Li, Y . Mu, J. Pang, Y . Qiao, et al. Internvla- m1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778, 2025
Pith/arXiv arXiv 2025
-
[74]
Karamcheti, S
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh. Prismatic vlms: Investigating the design space of visually-conditioned language models. InInternational Con- ference on Machine Learning (ICML), pages 23123–23144, 2024
2024
-
[75]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[76]
S. Tan, K. Dou, Y . Zhao, and P. Kr ¨ahenb¨uhl. Interactive post-training for vision-language- action models.arXiv preprint arXiv:2505.17016, 2025. 13
Pith/arXiv arXiv 2025
-
[77]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[78]
Isaac Sim
NVIDIA. Isaac Sim. URLhttps://github.com/isaac-sim/IsaacSim
-
[79]
K. Gao, D. Lau, B. Huang, K. E. Bekris, and J. Yu. Fast high-quality tabletop rearrangement in bounded workspace. InIEEE International Conference on Robotics and Automation (ICRA), pages 1961–1967. IEEE, 2022
1961
-
[80]
verb substitution
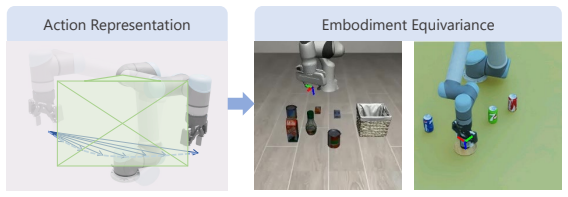
K. Xu, H. Yu, Q. Lai, Y . Wang, and R. Xiong. Efficient learning of goal-oriented push-grasping synergy in clutter.IEEE Robotics and Automation Letters, 6(4):6337–6344, 2021. A Implementation Details Action Representation.Actions are defined on the SE(3) manifold: 3D translation, 6D continu- ous rotation [66], and normalized gripper width (−1fully closed,...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.