Learning Action Priors for Cross-embodiment Robot Manipulation
Pith reviewed 2026-06-25 19:07 UTC · model grok-4.3
The pith
Pretraining an action module on unconditioned trajectories before VLA alignment equips policies with transferable motion structure that accelerates convergence and raises success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
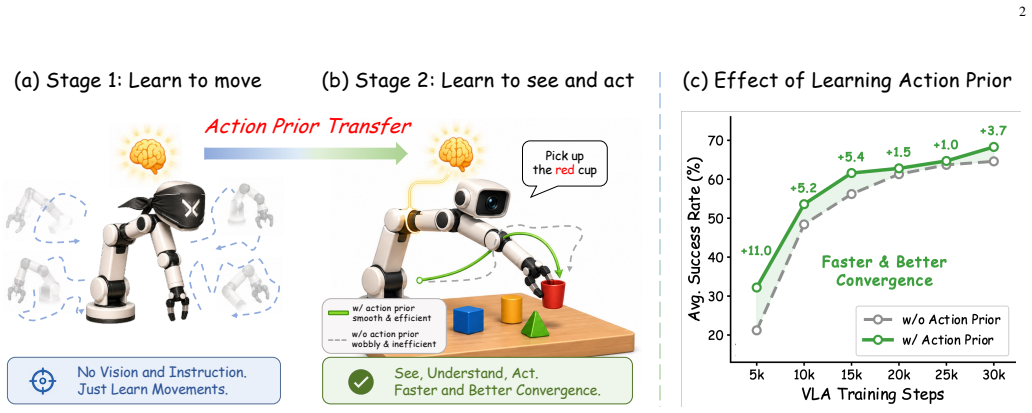
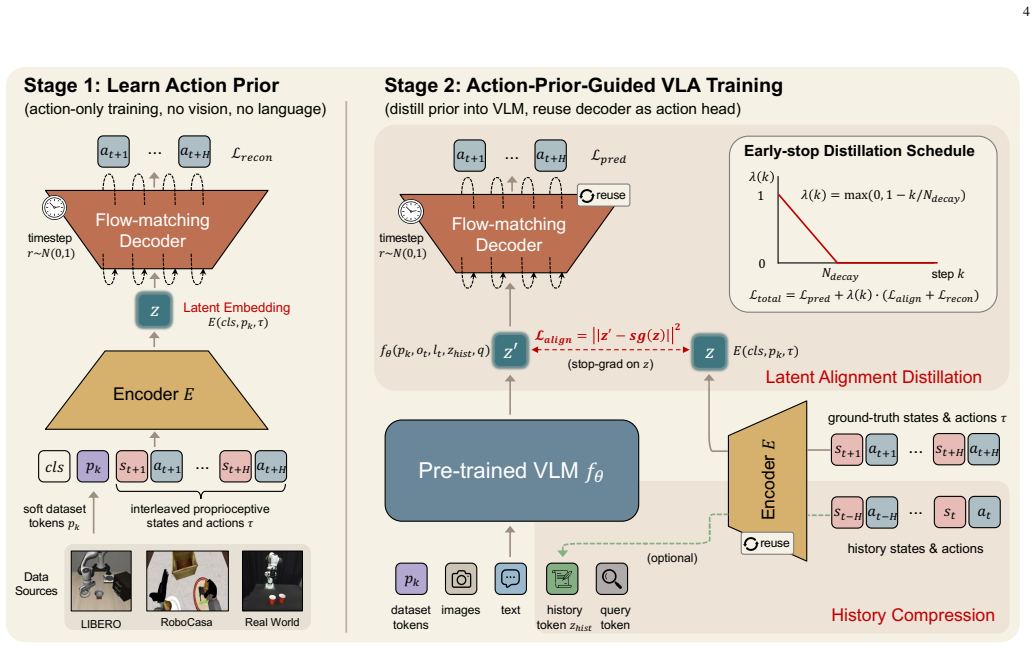
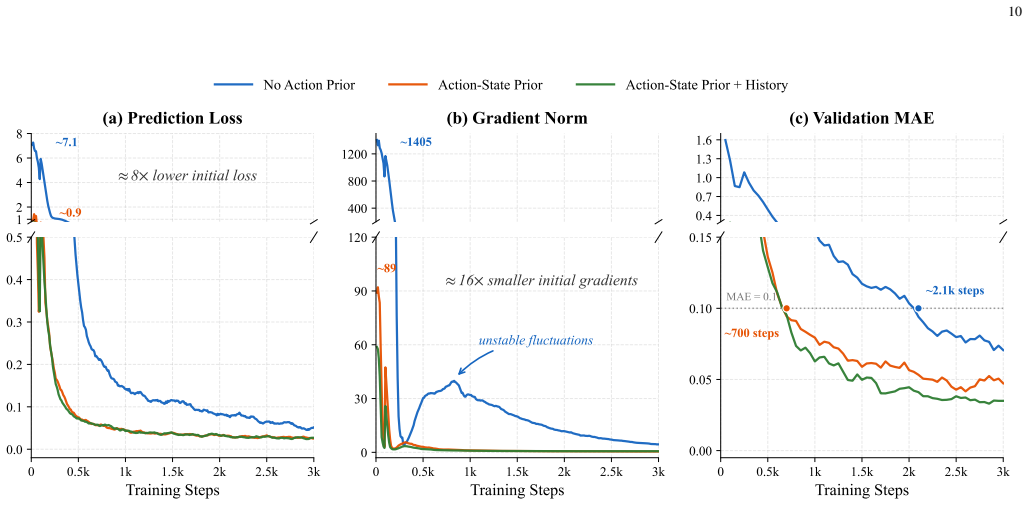
The central claim is that a two-stage framework equips the action module with cross-embodiment temporal motion structure before VLA training begins: stage one trains a lightweight flow-matching encoder-decoder solely on unconditioned action trajectories, and stage two reuses the decoder while distilling latents to align visual-language features with the pretrained action embedding space, yielding faster convergence, higher success rates, and stronger real-world results than VLA training without such priors.
What carries the argument
Two-stage training framework in which a flow-matching encoder-decoder first learns motion structure from action trajectories alone and then transfers it via decoder reuse and latent distillation into VLA policy optimization.
If this is right
- VLA training converges faster once the action module already encodes temporal motion structure.
- Success rates rise on both simulated and real-world cross-embodiment tasks.
- Performance gains are largest on data-scarce real-world deployments.
- Scaling the quantity of unconditioned action trajectories in stage one produces a more generalizable prior that lifts downstream VLA results.
- The pretrained encoder supplies a compact history compressor that summarizes state-action sequences into one token at low cost.
Where Pith is reading between the lines
- The separation of motion learning from semantic alignment may apply to other embodied sequence tasks where dynamics can be modeled independently of perception.
- Larger collections of raw action data could yield increasingly universal priors usable across many robot morphologies without embodiment-specific fine-tuning.
- The encoder-decoder could serve as a reusable motion backbone that multiple VLA models draw from rather than retraining from scratch each time.
Load-bearing premise
The motion structure learned from action trajectories alone can be aligned to visual-language features in the second stage without introducing misalignment that requires substantial extra adaptation.
What would settle it
A head-to-head comparison on the same thirteen tasks in which standard joint VLA training from scratch matches or exceeds the two-stage model's convergence speed and success rates would falsify the claimed benefit of the action priors.
Figures


read the original abstract
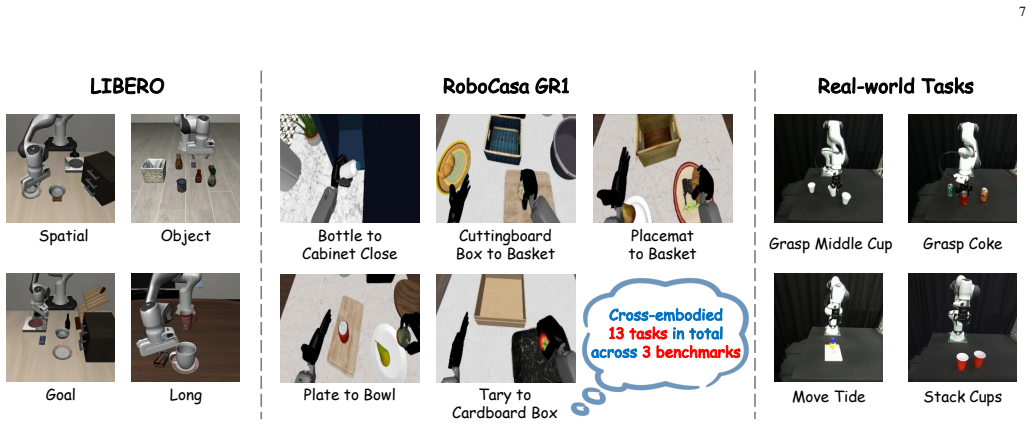
Most Vision-Language-Action (VLA) models build on a Vision-Language Model (VLM) backbone by attaching an action module and optimizing the full policy jointly. This design inherits strong visual and linguistic priors from the VLM, but leaves the action module to learn physical motion almost from scratch. As a result, the policy lacks an explicit motion prior, forcing early optimization to simultaneously discover temporal action dynamics and cross-modal alignment, a challenge further amplified in cross-embodiment settings. In this work, we propose to pretrain the action module with motion priors before cross-modal VLA alignment. Specifically, we introduce a two-stage training framework that equips the action module with cross-embodiment temporal motion structure before VLA training begins. In Stage~1, a lightweight flow-matching-based encoder-decoder action module efficiently learns temporal motion structure solely from unconditioned action trajectories, without processing visual or language tokens. In Stage~2, this learned prior is transferred to VLA training through decoder reuse and early-stage latent distillation, aligning visual-language features with the action embedding space while still allowing end-to-end policy refinement. In addition, the trained encoder serves as a compact history compressor, summarizing state-action histories into a single temporal context token for history-aware modeling at negligible cost. Extensive experiments across 13 diverse cross-embodiment tasks on both simulated and real-world platforms validate the effectiveness of our approach. Compared with VLA training without action priors, our model achieves faster convergence, higher success rates, and substantially stronger performance on data-scarce real-world tasks. Moreover, scaling up the action data in Stage~1 yields a more generalizable action prior that directly improves downstream VLA performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a two-stage training framework for Vision-Language-Action (VLA) models in cross-embodiment robot manipulation. In Stage 1, a lightweight flow-matching encoder-decoder learns temporal motion structure solely from unconditioned action trajectories. In Stage 2, the prior is transferred to VLA training via decoder reuse and early-stage latent distillation while allowing end-to-end refinement; the encoder is additionally reused as a compact history compressor. Experiments across 13 diverse simulated and real-world tasks are reported to show faster convergence, higher success rates, and stronger performance on data-scarce tasks relative to VLA training without action priors.
Significance. If the empirical gains are robust, the work supplies a practical pretraining recipe that injects explicit motion structure into VLA policies before cross-modal alignment, which is especially relevant for cross-embodiment and low-data regimes. The separation of motion-prior learning from visual-language alignment follows a standard pretrain-then-align pattern but is applied specifically to the action module using flow matching on raw trajectories.
minor comments (1)
- The abstract asserts performance gains across 13 tasks but supplies no quantitative results, baselines, error bars, or methodological details, preventing assessment of whether the data supports the stated claims.
Simulated Author's Rebuttal
We thank the referee for their review and for the positive assessment of the significance of our two-stage framework for pretraining action priors via flow matching before VLA alignment. We note that the recommendation is listed as uncertain and that no specific major comments were enumerated in the report. We are prepared to provide further details or clarifications on any aspect of the work if requested.
Circularity Check
No significant circularity; empirical pretraining procedure validated by external task evaluations
full rationale
The paper describes an empirical two-stage training procedure for VLA models: Stage 1 pretrains a flow-matching encoder-decoder action module solely on unconditioned action trajectories to capture temporal motion structure, and Stage 2 transfers the decoder and uses latent distillation during VLA alignment. All performance claims (faster convergence, higher success rates on 13 cross-embodiment tasks) rest on reported experimental results rather than any derivation that reduces to its own inputs by construction. No self-definitional equations, fitted parameters renamed as predictions, load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear in the method. The approach is a standard pretrain-then-finetune pattern whose validity is settled externally by task success metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A flow-matching-based encoder-decoder can learn useful cross-embodiment temporal motion structure solely from unconditioned action trajectories
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,”Advances in Neural Information Processing Systems, 2023
2023
-
[2]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Luet al., “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,”CVPR, 2024
2024
-
[3]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tanget al., “Qwen2. 5-vl technical report,”arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[4]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[5]
Learning universal policies via text- guided video generation,
Y . Du, M. Yang, B. Dai, H. Dai, O. Nachum, J. B. Tenenbaum, D. Schuurmans, and P. Abbeel, “Learning universal policies via text- guided video generation,”Advances in Neural Information Processing Systems, 2023
2023
-
[6]
Zero-shot robotic manipulation with pretrained image-editing diffusion models,
K. Black, M. Nakamoto, P. Atanasov, H. Walke, C. Finn, A. Kumar, and S. Levine, “Zero-shot robotic manipulation with pretrained image-editing diffusion models,”ICLR, 2024
2024
-
[7]
Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation,
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xia, Y . Yanet al., “Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation,”arXiv preprint arXiv:2410.06158, 2024
Pith/arXiv arXiv 2024
-
[8]
Cosmos 3: Omnimodal world models for physical ai,
N. Agarwal, A. Ali, J. Allen, M. Antolini, A. Aubame, A. Azzolini, J. Bai, M. Bala, Y . Balaji, J. Bapstet al., “Cosmos 3: Omnimodal world models for physical ai,”arXiv preprint arXiv:2606.02800, 2026
Pith/arXiv arXiv 2026
-
[9]
World action models are zero-shot policies,
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xianget al., “World action models are zero-shot policies,” arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[10]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[11]
Rt-2: Vision-language- action models transfer web knowledge to robotic control,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finnet al., “Rt-2: Vision-language- action models transfer web knowledge to robotic control,”arXiv preprint arXiv:2307.15818, 2023
Pith/arXiv arXiv 2023
-
[12]
Openvla: An open-source vision-language-action model,
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[13]
Learning robust perceptive locomotion for quadrupedal robots in the wild,
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter, “Learning robust perceptive locomotion for quadrupedal robots in the wild,”Science Robotics, vol. 7, no. 62, 2022
2022
-
[14]
Anymal parkour: Learning agile navigation for quadrupedal robots,
D. Hoeller, N. Rudin, D. Sako, and M. Hutter, “Anymal parkour: Learning agile navigation for quadrupedal robots,”Science Robotics, vol. 9, 2024
2024
-
[15]
Humanplus: Humanoid shadowing and imitation from humans,
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn, “Humanplus: Humanoid shadowing and imitation from humans,”CoRL, 2024
2024
-
[16]
Gr00t n1: An open foundation model for generalist humanoid robots,
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huanget al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[17]
C. Cheang, S. Chen, Z. Cui, Y . Hu, L. Huang, T. Kong, H. Li, Y . Li, Y . Liu, X. Maet al., “Gr-3 technical report,”arXiv preprint arXiv:2507.15493, 2025
Pith/arXiv arXiv 2025
-
[18]
pi 0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “ pi 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[19]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhanget al., “Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation,” arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[20]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jainet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[21]
Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers,
L. Wang, X. Chen, J. Zhao, and K. He, “Scaling proprioceptive-visual learning with heterogeneous pre-trained transformers,”Advances in Neural Information Processing Systems, 2024
2024
-
[22]
H. Yuan, Z. Liang, A. Chen, Y . Wang, H. Li, P. Lin, Y . Huang, Z. Lei, T. Zhang, J. Zhanget al., “Qwen-robotmanip technical report: Alignment unlocks scale for robotic manipulation foundation models,”arXiv preprint arXiv:2606.17846, 2026
Pith/arXiv arXiv 2026
-
[23]
Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data,
S. Deng, M. Yan, S. Wei, H. Ma, Y . Yang, J. Chen, Z. Zhang, T. Yang, X. Zhang, W. Zhang, H. Cui, Z. Zhang, and H. Wang, “Graspvla: a grasping foundation model pre-trained on billion-scale synthetic action data,” 2025
2025
-
[24]
Dreamvla: A vision- language-action model dreamed with comprehensive world knowledge,
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, L. Yi, W. Zeng, and X. Jin, “Dreamvla: A vision- language-action model dreamed with comprehensive world knowledge,” CoRR, vol. abs/2507.04447, 2025
Pith/arXiv arXiv 2025
-
[25]
Univla: Learning to act anywhere with task-centric latent actions,
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li, “Univla: Learning to act anywhere with task-centric latent actions,”arXiv preprint arXiv:2505.06111, 2025
Pith/arXiv arXiv 2025
-
[26]
Embodiedgpt: Vision-language pre-training via embodied chain of thought,
Y . Mu, Q. Zhang, M. Hu, W. Wang, M. Ding, J. Jin, B. Wang, J. Dai, Y . Qiao, and P. Luo, “Embodiedgpt: Vision-language pre-training via embodied chain of thought,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[27]
Starvla: A lego-like codebase for vision-language-action model developing,
Contributors, “Starvla: A lego-like codebase for vision-language-action model developing,” GitHub repository, 1 2025
2025
-
[28]
Tempovla: Learning speed-controllable vision-language-action policies,
D. Jing, J. Nie, T. Zhang, J. Liu, H. Yao, Z. Lu, and M. Ding, “Tempovla: Learning speed-controllable vision-language-action policies,” arXiv preprint arXiv:2606.06491, 2026
Pith/arXiv arXiv 2026
-
[30]
Paligemma 2: A family of versatile vlms for transfer,
A. Steiner, A. S. Pinto, M. Tschannen, D. Keysers, X. Wang, Y . Bitton, A. Gritsenko, M. Minderer, A. Sherbondy, S. Longet al., “Paligemma 2: A family of versatile vlms for transfer,”arXiv preprint arXiv:2412.03555, 2024
Pith/arXiv arXiv 2024
-
[31]
Fine-tuning vision-language-action models: Optimizing speed and success,
M. J. Kim, C. Finn, and P. Liang, “Fine-tuning vision-language-action models: Optimizing speed and success,”arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[32]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”arXiv preprint arXiv:2303.04137, 2023
Pith/arXiv arXiv 2023
-
[33]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” inProceedings of Robotics: Science and Systems, Daegu, Republic of Korea, July 2023
2023
-
[34]
Rdt-1b: a diffusion foundation model for bimanual manipulation,
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu, “Rdt-1b: a diffusion foundation model for bimanual manipulation,” arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[35]
Fast: Efficient action tokenization for vision-language-action models,
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine, “Fast: Efficient action tokenization for vision-language-action models,”arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[36]
Spatialvla: Exploring spatial representations for visual-language-action model,
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wanget al., “Spatialvla: Exploring spatial representations for visual-language-action model,”arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[37]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model,
F. Li, W. Song, H. Zhao, J. Wang, P. Ding, D. Wang, L. Zeng, and H. Li, “Spatial forcing: Implicit spatial representation alignment for vision-language-action model,”arXiv preprint arXiv:2510.12276, 2025
arXiv 2025
-
[38]
Geomanip: Geometric constraints as general interfaces for robot manipulation,
W. Tang, J.-H. Pan, Y .-H. Liu, M. Tomizuka, L. E. Li, C.-W. Fu, and M. Ding, “Geomanip: Geometric constraints as general interfaces for robot manipulation,”arXiv preprint arXiv:2501.09783, 2025
arXiv 2025
-
[39]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finnet al., “Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1702–1713
2025
-
[40]
Robotic control via embodied chain-of-thought reasoning,
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine, “Robotic control via embodied chain-of-thought reasoning,”arXiv preprint arXiv:2407.08693, 2024
Pith/arXiv arXiv 2024
-
[41]
Incentivizing multimodal reasoning in large models for direct robot manipulation,
W. Tang, D. Jing, J.-H. Pan, Z. Lu, Y .-H. Liu, L. E. Li, M. Ding, and C.-W. Fu, “Incentivizing multimodal reasoning in large models for direct robot manipulation,”arXiv preprint arXiv:2505.12744, 2025
arXiv 2025
-
[42]
R. Zheng, Y . Liang, S. Huang, J. Gao, H. Daum ´e III, A. Kolobov, F. Huang, and J. Yang, “Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies,”arXiv preprint arXiv:2412.10345, 2024
Pith/arXiv arXiv 2024
-
[43]
Worldvla: Towards autoregressive action world model,
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wanget al., “Worldvla: Towards autoregressive action world model,”arXiv preprint arXiv:2506.21539, 2025
Pith/arXiv arXiv 2025
-
[44]
Causal world modeling for robot control,
L. Li, Q. Zhang, Y . Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhuet al., “Causal world modeling for robot control,”arXiv preprint arXiv:2601.21998, 2026
Pith/arXiv arXiv 2026
-
[45]
Fast-wam: Do world action mod- els need test-time future imagination?
T. Yuan, Z. Dong, Y . Liu, and H. Zhao, “Fast-wam: Do world action mod- els need test-time future imagination?”arXiv preprint arXiv:2603.16666, 2026
Pith/arXiv arXiv 2026
-
[46]
Cosmos policy: Fine-tuning video models 14 for visuomotor control and planning,
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finnet al., “Cosmos policy: Fine-tuning video models 14 for visuomotor control and planning,”arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[47]
Bridgedata v2: A dataset for robot learning at scale,
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen- Estruch, A. W. He, V . Myers, M. J. Kim, M. Duet al., “Bridgedata v2: A dataset for robot learning at scale,” inConference on Robot Learning. PMLR, 2023, pp. 1723–1736
2023
-
[48]
Droid: A large-scale in-the-wild robot manipulation dataset,
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karam- cheti, S. Nasiriany, M. K. Srinivasan, L. Y . Zhu, O. Lingelbachet al., “Droid: A large-scale in-the-wild robot manipulation dataset,”arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[49]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huanget al., “Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems,”arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[50]
Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation,
K. Wu, C. Zhao, J. Chen, W. Li, Y . Xu, J. Zhuet al., “Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation,”arXiv preprint arXiv:2412.13877, 2024
Pith/arXiv arXiv 2024
-
[51]
Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, W. Deng, Y . Guo, T. Nian, X. Xie, Q. Chen, K. Su, T. Xu, G. Liu, M. Hu, H. ang Gao, K. Wang, Z. Liang, Y . Qin, X. Yang, P. Luo, and Y . Mu, “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,” 2025
2025
-
[52]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,”arXiv preprint arXiv:2306.03310, 2023
Pith/arXiv arXiv 2023
-
[53]
Robocasa: Large-scale simulation of everyday tasks for generalist robots,
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parber, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu, “Robocasa: Large-scale simulation of everyday tasks for generalist robots,”arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
-
[54]
Octo: An open-source generalist robot policy,
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xuet al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[55]
X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model,
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zenget al., “X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model,”arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[56]
Universal actions for enhanced embodied foundation models,
J. Zheng, J. Li, D. Liu, Y . Zheng, Z. Wang, Z. Ou, Y . Liu, J. Liu, Y .-Q. Zhang, and X. Zhan, “Universal actions for enhanced embodied foundation models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 508–22 519
2025
-
[57]
Learning structured output represen- tation using deep conditional generative models,
K. Sohn, H. Lee, and X. Yan, “Learning structured output represen- tation using deep conditional generative models,”Advances in neural information processing systems, vol. 28, 2015
2015
-
[58]
K. Xu, Z. Zhu, A. Chen, R. Xiong, and Y . Wang, “Apt: Action expert pretraining improves instruction generalization of vision-language-action policies,”arXiv preprint arXiv:2606.12366, 2026
Pith/arXiv arXiv 2026
-
[59]
Latent action pretraining from videos,
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Linet al., “Latent action pretraining from videos,” arXiv preprint arXiv:2410.11758, 2024
Pith/arXiv arXiv 2024
-
[60]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[61]
Igor: Image-goal representations are the atomic control units for foundation models in embodied ai,
X. Chen, J. Guo, T. He, C. Zhang, P. Zhang, D. C. Yang, L. Zhao, and J. Bian, “Igor: Image-goal representations are the atomic control units for foundation models in embodied ai,”arXiv preprint arXiv:2411.00785, 2024
arXiv 2024
-
[62]
Moto: Latent motion token as the bridging language for robot manipulation,
Y . Chen, Y . Ge, Y . Li, Y . Ge, M. Ding, Y . Shan, and X. Liu, “Moto: Latent motion token as the bridging language for robot manipulation,” arXiv preprint arXiv:2412.04445, 2024
arXiv 2024
-
[63]
Egodex: Learning dexterous manipulation from large-scale egocentric video,
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang, “Egodex: Learning dexterous manipulation from large-scale egocentric video,”
-
[64]
Available: https://arxiv.org/abs/2505.11709
[Online]. Available: https://arxiv.org/abs/2505.11709
-
[65]
Egoverse: An egocentric human dataset for robot learning from around the world,
R. Punamiya, S. Kareer, Z. Liu, J. Citron, R.-Z. Qiu, X. Cai, A. Gavryushin, J. Chen, D. Liconti, L. Y . Zhuet al., “Egoverse: An egocentric human dataset for robot learning from around the world,” arXiv preprint arXiv:2604.07607, 2026
Pith/arXiv arXiv 2026
-
[66]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liuet al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 18 995– 19 012
2022
-
[67]
Vla-jepa: Enhancing vision-language-action model with latent world model,
J. Ma, C. Wang, Y . Li, J. Liu, Y . Li, H. Huang, P. Xu, and H. Zhao, “Vla-jepa: Enhancing vision-language-action model with latent world model,”arXiv preprint arXiv:2602.10098, 2025
arXiv 2025
-
[68]
Latent action pretraining through world modeling,
D. Wu, Y . Cao, Y . Fuet al., “Latent action pretraining through world modeling,”arXiv preprint arXiv:2509.18428, 2025
arXiv 2025
-
[69]
Adaworld: Learning adaptable world models with latent actions,
S. Gao, S. Zhou, Y . Du, J. Zhang, and C. Gan, “Adaworld: Learning adaptable world models with latent actions,” inInternational Conference on Machine Learning (ICML), 2025
2025
-
[70]
Dreamdojo: A generalist robot world model from large-scale human videos,
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, Q. Ma, S. Nah, L. Magne, J. Xiang, Y . Xie, R. Zheng, D. Niu, Y . L. Tan, K. Zentner, G. Kurian, S. Indupuru, P. Jannaty, J. Gu, J. Zhang, J. Malik, P. Abbeel, M.-Y . Liu, Y . Zhu, J. Jang, and L. J. Fan, “Dreamdojo: A generalist robot world model from large-scale...
Pith/arXiv arXiv 2026
-
[71]
Dynamo: In-domain dynamics pretraining for visuo,
Z. Cui, H. Pan, A. Iyer, S. Haldar, and L. Pinto, “Dynamo: In-domain dynamics pretraining for visuo,”Motor Control, 2024
2024
-
[72]
Mixture of horizons in action chunking,
D. Jing, G. Wang, J. Liu, W. Tang, Z. Sun, Y . Yao, Z. Wei, Y . Liu, Z. Lu, and M. Ding, “Mixture of horizons in action chunking,”arXiv preprint arXiv:2511.19433, 2025
Pith/arXiv arXiv 2025
-
[73]
π0.5: a vision-language-action model with open-world generalization,
P. Intelligence, “π0.5: a vision-language-action model with open-world generalization,” 2025. [Online]. Available: https://arxiv.org/abs/2504. 16054
2025
-
[74]
Starvla: A lego-like codebase for vision-language-action model developing,
S. Community, “Starvla: A lego-like codebase for vision-language-action model developing,”arXiv preprint arXiv:2604.05014, 2026
Pith/arXiv arXiv 2026
-
[75]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” in International conference on machine learning. pmlr, 2015, pp. 2256– 2265
2015
-
[76]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[77]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[78]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2. 5 technical report,”arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[79]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.