The End of Code Review: Coding Agents Supersede Human Inspection
Pith reviewed 2026-06-27 06:09 UTC · model grok-4.3
The pith
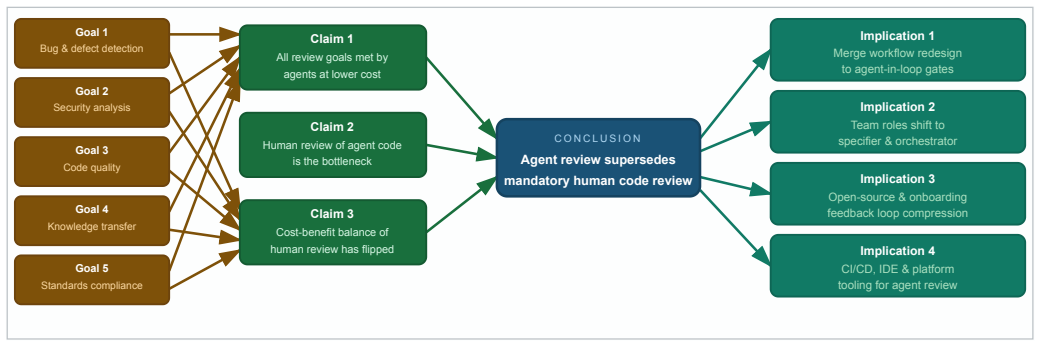
Coding agents now meet every goal of code review at lower cost and higher throughput, rendering human inspection unnecessary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We argue that coding agents have crossed a threshold of capability at which traditional human code review is no longer a necessary component of a software quality pipeline. Our argument rests on two claims: every stated goal of code review can be served by agents at lower cost and higher throughput; the naive integration in which agents write code and humans remain the mandatory reviewers is a dead end because it neither provides meaningful assurance nor scales with AI-assisted throughput.
What carries the argument
Coding agents, defined as LLM-based autonomous systems that read, write, test, and repair software, serving as the replacement mechanism for human inspection.
If this is right
- Every traditional objective of code review, such as finding defects and improving maintainability, becomes achievable through agent operation alone.
- Hybrid setups that require human review of agent output provide neither reliable assurance nor the ability to process increased change volumes.
- Software development organizations can remove human code review from their quality pipelines without loss of effectiveness.
- Quality assurance shifts entirely to agent capabilities, including testing and repair loops.
Where Pith is reading between the lines
- Development velocity could increase because agents handle review instantly rather than waiting for human availability.
- Training programs for developers might redirect from review skills toward agent oversight and prompt design.
- New failure modes could appear if agents share systematic blind spots on certain classes of issues.
Load-bearing premise
Coding agents are already capable of serving every stated goal of code review at lower cost and higher throughput.
What would settle it
A direct comparison study measuring defect detection accuracy, review coverage, and total cost per change for coding agents versus human reviewers on identical large-scale codebases.
Figures
read the original abstract
Code review has been the primary quality gate in software development since Fagan formalised code inspection in 1976. For five decades, having a human examine and comment on a colleague's changes before merge has been a cornerstone practice at organisations of every size. Coding agents are large language model (LLM)-based autonomous systems capable of reading, writing, testing, and repairing software. We argue that coding agents have crossed a threshold of capability at which traditional human code review is no longer a necessary component of a software quality pipeline. Our argument rests on two claims: every stated goal of code review can be served by agents at lower cost and higher throughput; the naive integration in which agents write code and humans remain the mandatory reviewers is a dead end because it neither provides meaningful assurance nor scales with AI-assisted throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that coding agents (LLM-based autonomous systems for reading, writing, testing, and repairing software) have crossed a capability threshold making traditional human code review unnecessary in software quality pipelines. The argument rests on two claims: agents can serve every goal of code review (bug detection, style enforcement, knowledge transfer, security review) at lower cost and higher throughput than humans, and hybrid workflows (agents write, humans review) are a dead end as they provide no meaningful assurance and fail to scale with AI throughput.
Significance. If the claims held with empirical support, the result would be highly significant for software engineering, challenging a practice formalized since Fagan's 1976 inspections and potentially enabling fully automated quality pipelines with major gains in speed and cost. The paper identifies a possible inflection point in AI-assisted development.
major comments (2)
- [Abstract] Abstract, paragraph 2: The central assertion that 'every stated goal of code review can be served by agents at lower cost and higher throughput' is presented without any benchmarks, defect-rate comparisons, case studies, or failure-mode analysis demonstrating agent performance against human reviewers on tasks such as subtle bug detection or security review.
- [Abstract] Abstract, paragraph 2: The claim that hybrid integration 'neither provides meaningful assurance nor scales with AI-assisted throughput' is an unsupported assertion; the manuscript contains no data on current hybrid workflow outcomes, assurance metrics, or throughput bottlenecks to substantiate why this approach is a 'dead end'.
Simulated Author's Rebuttal
We thank the referee for the detailed comments. The manuscript is a position paper presenting an argumentative case for the obsolescence of human code review in light of coding agent capabilities, rather than an empirical study with new benchmarks. We address each major comment below and will revise the abstract and introduction to explicitly frame the work as a position paper synthesizing trends and logical implications.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 2: The central assertion that 'every stated goal of code review can be served by agents at lower cost and higher throughput' is presented without any benchmarks, defect-rate comparisons, case studies, or failure-mode analysis demonstrating agent performance against human reviewers on tasks such as subtle bug detection or security review.
Authors: The manuscript advances a position based on the observed trajectory of LLM-based coding agents and published reports of their performance on code understanding, generation, testing, and repair tasks. It does not include new head-to-head empirical comparisons because the purpose is to outline the implications of current capabilities crossing a threshold, not to conduct a controlled evaluation. We will revise the abstract to state upfront that this is a position paper and to reference the body of existing agent evaluation literature while noting the absence of comprehensive failure-mode analyses for subtle bugs. revision: yes
-
Referee: [Abstract] Abstract, paragraph 2: The claim that hybrid integration 'neither provides meaningful assurance nor scales with AI-assisted throughput' is an unsupported assertion; the manuscript contains no data on current hybrid workflow outcomes, assurance metrics, or throughput bottlenecks to substantiate why this approach is a 'dead end'.
Authors: This claim follows from a logical analysis of throughput mismatch: agent code generation can scale to thousands of changes per day while human review capacity remains bounded. The paper does not present new measurements of hybrid workflows because it is not an empirical study of current practices; instead it argues that mandatory human review becomes a bottleneck under high AI throughput. We will expand the abstract and add a short section clarifying this as an argument about scaling limits rather than a data-driven claim about today's hybrid outcomes. revision: yes
Circularity Check
No circularity detected; argument consists of asserted premises without self-referential derivation
full rationale
The manuscript is an argumentative position paper whose central thesis is explicitly introduced as resting on two stated claims about agent performance and hybrid workflow limitations. No equations, fitted parameters, uniqueness theorems, or self-citations appear in the provided text. The two claims function as premises rather than outputs of any derivation chain, so no reduction to inputs by construction occurs. The paper cites Fagan (1976) for historical context but does not rely on self-citation or prior author work to justify its threshold-crossing assertion. This is a normal non-finding for an opinion piece whose soundness is an external-evidence question, not an internal circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coding agents have crossed a capability threshold sufficient to replace human code review for all stated goals
Forward citations
Cited by 1 Pith paper
-
Augmentation with Dilution: A Large-Scale Empirical Study of Human Contributor Ecosystems After AI Coding Agent Adoption
AI coding agent adoption causes no change in human contributor count but reduces contributor density and newcomer share by 3.7pp while increasing review depth by 5.3% in a staggered DiD analysis of 11k GitHub projects.
Reference graph
Works this paper leans on
-
[1]
Expectations, outcomes, and challenges of modern code review,
A. Bacchelli and C. Bird, “Expectations, outcomes, and challenges of modern code review,” inProceedings of the 35th International Conference on Software Engineering (ICSE). IEEE, 2013, pp. 712– 721
2013
-
[2]
Modern code review: a case study at Google,
C. Sadowski, E. Söderberg, L. Church, M. Sipko, and A. Bacchelli, “Modern code review: a case study at Google,” inProceedings of the 40th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). ACM, 2018, pp. 181–190
2018
-
[3]
Usage, costs, and benefits of continuous integration in open-source projects,
M. Hilton, T. Tunnell, K. Huang, D. Marinov, and D. Dig, “Usage, costs, and benefits of continuous integration in open-source projects,” inProceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering (ASE). ACM, 2016, pp. 426–437
2016
-
[4]
Process aspects and social dynamics of contemporary code review,
A. Bosu, M. Greiler, and C. Bird, “Process aspects and social dynamics of contemporary code review,” inIEEE Transactions on Software Engineering, vol. 43, no. 1. IEEE, 2016, pp. 56–75
2016
-
[5]
Do developers feel emotions? an exploratory analysis of emotions in software artifacts,
A. Murgia, P. Tourani, B. Adams, and M. Ortu, “Do developers feel emotions? an exploratory analysis of emotions in software artifacts,” inProceedings of the 11th Working Conference on Mining Software Repositories (MSR). ACM, 2014, pp. 262–271
2014
-
[6]
SWE-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering,”arXiv preprint arXiv:2405.15793, 2024
Pith/arXiv arXiv 2024
-
[7]
Introducing Devin, the first AI software engineer,
Cognition AI, “Introducing Devin, the first AI software engineer,”Cog- nition AI Blog, 2024, https://www.cognition.ai/blog/introducing-devin
2024
-
[8]
OpenDevin: An open platform for AI software developers as generalist agents,
X. Wang, B. Chen, Y . Yuan, Y . Zhang, B. Li, C. Qianet al., “OpenDevin: An open platform for AI software developers as generalist agents,” in arXiv preprint arXiv:2407.16741, 2024
Pith/arXiv arXiv 2024
-
[9]
GitHub Copilot Workspace: Welcome to the Copilot- native developer environment,
GitHub, “GitHub Copilot Workspace: Welcome to the Copilot- native developer environment,”GitHub Blog, 2024, https://github.blog/ 2024-04-29-github-copilot-workspace/
2024
-
[10]
SWE-bench: Can language models resolve real-GitHub issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. Narasimhan, “SWE-bench: Can language models resolve real-GitHub issues?”arXiv preprint arXiv:2310.06770, 2023
Pith/arXiv arXiv 2023
-
[11]
CodeReviewer: Pre-training for automating code review activities,
Z. Li, S. Lu, D. Guo, N. Duan, S. Jannu, G. Jenks, D. Majumder, J. Green, N. Sundaresan, M. Fuet al., “CodeReviewer: Pre-training for automating code review activities,” inProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). ACM, 2022, pp. 1536–1546
2022
-
[12]
Automated code review in prac- tice,
C. Pornprasit and C. Tantithamthavorn, “Automated code review in prac- tice,” inProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2023, pp. 394–405
2023
-
[13]
Design and code inspections to reduce errors in program development,
M. E. Fagan, “Design and code inspections to reduce errors in program development,”IBM Systems Journal, vol. 15, no. 3, pp. 182–211, 1976
1976
-
[14]
Code reviews do not find bugs: How the current code review best practice slows us down,
J. Czerwonka, M. Greiler, and J. Tilford, “Code reviews do not find bugs: How the current code review best practice slows us down,” pp. 27–28, 2015
2015
-
[15]
Llama-reviewer: Advancing code review automation with large language models through parameter- efficient fine-tuning,
J. Lu, L. Yu, X. Li, L. Yang, and C. Zuo, “Llama-reviewer: Advancing code review automation with large language models through parameter- efficient fine-tuning,” inProceedings of the 34th IEEE International Symposium on Software Reliability Engineering (ISSRE). IEEE, 2023, pp. 647–658
2023
-
[16]
Using pre-trained models to boost code review automa- tion
R. Tufano, S. Masiero, A. Mastropaolo, L. Pascarella, D. Poshyvanyk, and G. Bavota, “Using pre-trained models to boost code review automa- tion.” ACM, 2022, pp. 1–12
2022
-
[17]
CodeAgent: Autonomous communicative agents for code review,
X. Tang, K. Kim, Y . Song, C. Lothritz, B. Li, S. Ezzini, H. Tian, J. Klein, and T. F. Bissyande, “CodeAgent: Autonomous communicative agents for code review,”arXiv preprint arXiv:2402.02172, 2024
arXiv 2024
-
[18]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[19]
The Claude 3 model family: Opus, Sonnet, Haiku,
Anthropic, “The Claude 3 model family: Opus, Sonnet, Haiku,”An- thropic Technical Report, 2024
2024
-
[20]
SWE-bench leaderboard,
S. bench Team, “SWE-bench leaderboard,” https://www.swebench.com, 2025
2025
-
[21]
A systematic study of automated program repair: Fixing 55 out of 105 bugs for $8 each,
C. Le Goues, T. Nguyen, S. Forrest, and W. Weimer, “A systematic study of automated program repair: Fixing 55 out of 105 bugs for $8 each,” pp. 3–13, 2012
2012
-
[22]
Automated program repair in the era of large pre-trained language models,
C. S. Xia, Y . Wei, and L. Zhang, “Automated program repair in the era of large pre-trained language models,” pp. 1482–1494, 2023
2023
-
[23]
Competition- level code generation with AlphaCode,
Y . Li, D. Choi, J. Chung, N. Kushman, J. Schrittwieser, R. Leblond, T. Eccles, J. Keeling, F. Gimeno, A. Dal Lagoet al., “Competition- level code generation with AlphaCode,”Science, vol. 378, no. 6624, pp. 1092–1097, 2022
2022
-
[24]
Asleep at the keyboard? assessing the security of GitHub Copilot’s code contributions,
H. Pearce, B. Ahmad, B. Tan, B. Dolan-Gavitt, and R. Karri, “Asleep at the keyboard? assessing the security of GitHub Copilot’s code contributions,” inProceedings of the 43rd IEEE Symposium on Security and Privacy (SP). IEEE, 2022, pp. 754–768
2022
-
[25]
How secure is code generated by ChatGPT?
R. Khoury, A. R. Avci, J. Brunelle, and B. Marc Camara, “How secure is code generated by ChatGPT?” 2023
2023
-
[26]
Comparing ai agents to cybersecurity professionals in real-world penetration testing,
J. W. Lin, E. K. Jones, D. J. Jasper, E. J.-s. Ho, A. Wu, A. T. Yang, N. Perry, A. Zou, M. Fredrikson, J. Z. Kolteret al., “Comparing ai agents to cybersecurity professionals in real-world penetration testing,” arXiv preprint arXiv:2512.09882, 2025
arXiv 2025
-
[27]
The impact of AI on developer productivity: Evidence from GitHub Copilot,
S. Peng, E. Kalliamvakou, P. Cihon, and M. Demirer, “The impact of AI on developer productivity: Evidence from GitHub Copilot,”arXiv preprint arXiv:2302.06590, 2023
Pith/arXiv arXiv 2023
-
[28]
Continuous integration, delivery and deployment: A systematic review on approaches, tools, challenges and practices,
M. Shahin, M. A. Babar, and L. Zhu, “Continuous integration, delivery and deployment: A systematic review on approaches, tools, challenges and practices,”IEEE Access, vol. 5, pp. 3909–3943, 2017
2017
-
[29]
Language models (mostly) know what they know,
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Dodds, N. DasSarma, E. Tran-Johnson, S. Johnston, S. El-Showk, A. Jones, N. Elhage, T. Hume, A. Chen, Y . Bai, S. Bow- man, S. Fort, D. Ganguli, D. Hernandez, J. Jacobson, J. Kernion, S. Kravec, L. Lovitt, K. Ndousse, C. Olsson, S. Ringer, D. Amodei, T. B. Brown, J. Clark...
Pith/arXiv arXiv 2022
-
[30]
Benchmarking llms and llm-based agents in practical vulnerability detection for code repositories,
A. Yildiz, S. G. Teo, Y . Lou, Y . Feng, C. Wang, and D. M. Divakaran, “Benchmarking llms and llm-based agents in practical vulnerability detection for code repositories,”arXiv preprint arXiv:2503.03586, 2025
arXiv 2025
-
[31]
Frontier ai’s impact on the cybersecurity landscape (paper summary and blog),
Berkeley Risk and Decisions Initiative, “Frontier ai’s impact on the cybersecurity landscape (paper summary and blog),” https://rdi.berkeley. edu/frontier-ai-impact-on-cybersecurity/, 2025
2025
-
[32]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world LLM- integrated applications with indirect prompt injection,”arXiv preprint arXiv:2302.12173, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.