User as Engram: Internalizing Per-User Memory as Local Parametric Edits
Pith reviewed 2026-06-26 20:34 UTC · model grok-4.3
The pith
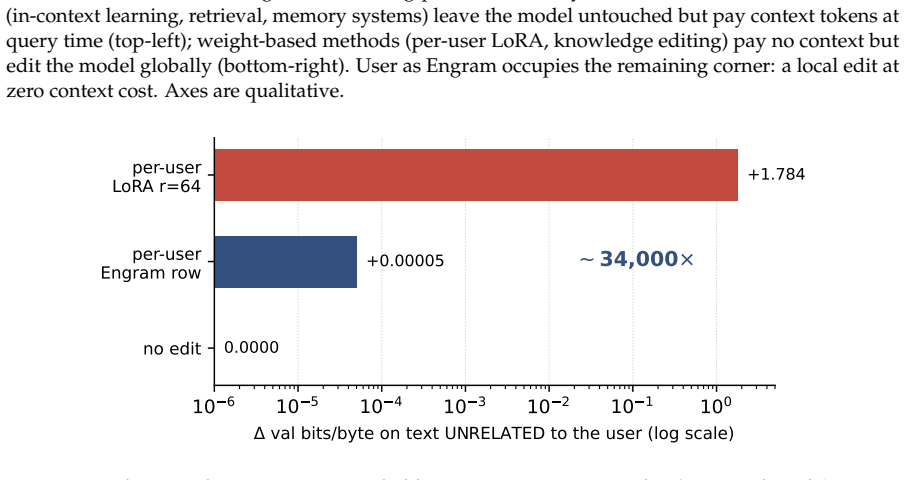
Storing each user's facts as precise local edits inside an Engram model's hash-keyed table, while keeping reasoning skill in one shared adapter, matches LoRA direct recall yet raises indirect-reasoning accuracy 5.6 times and shrinks memory
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
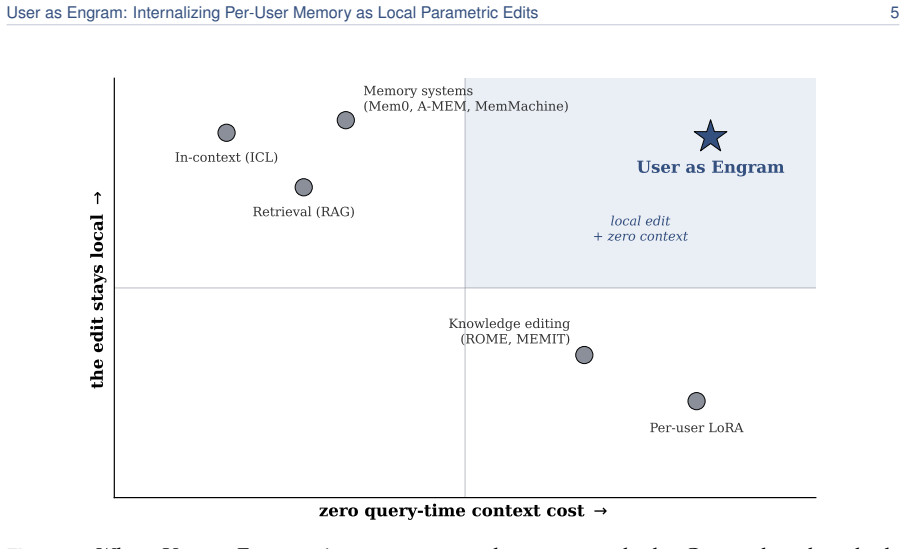
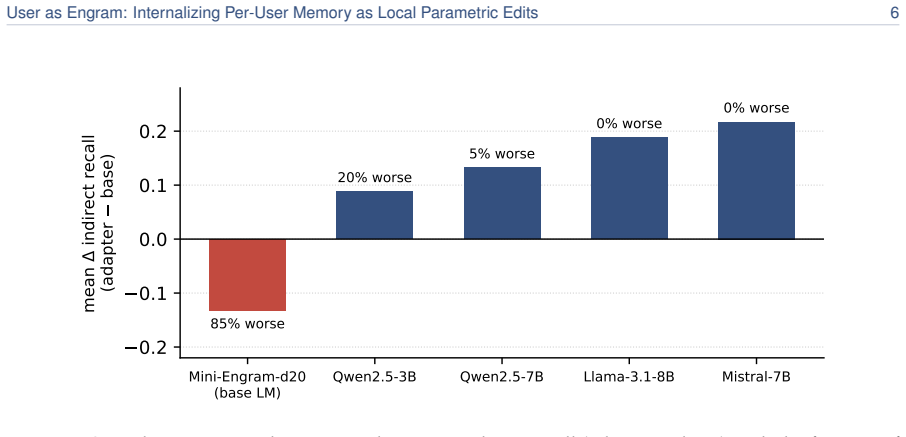
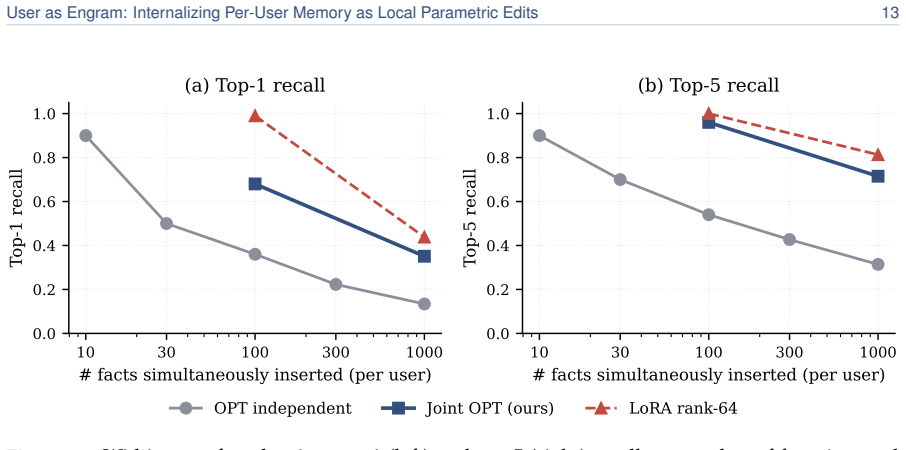
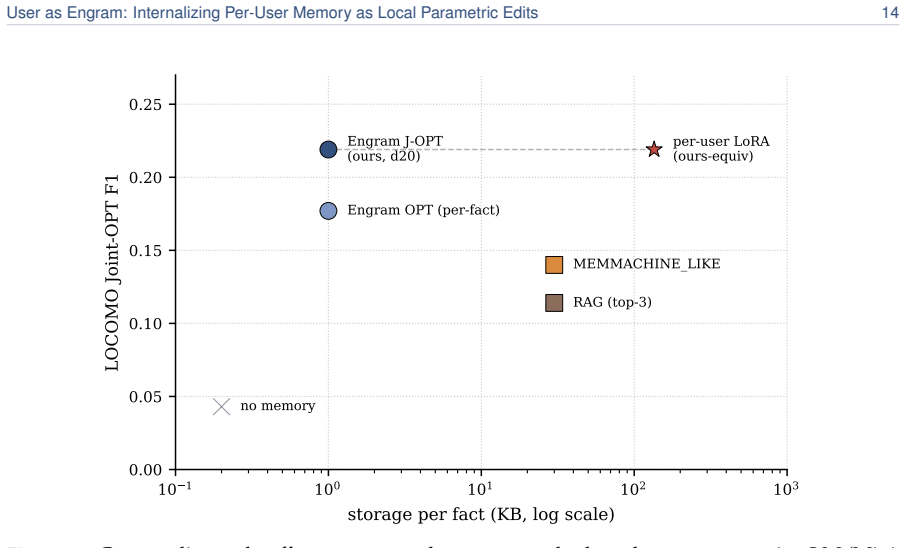
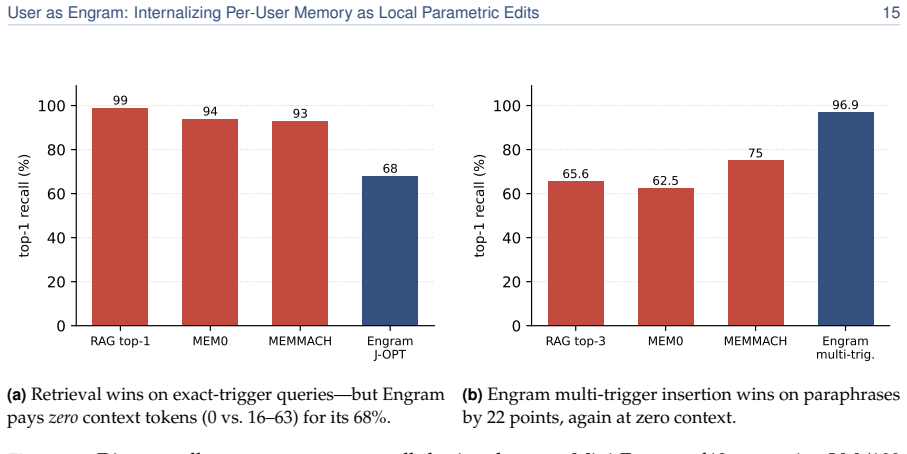
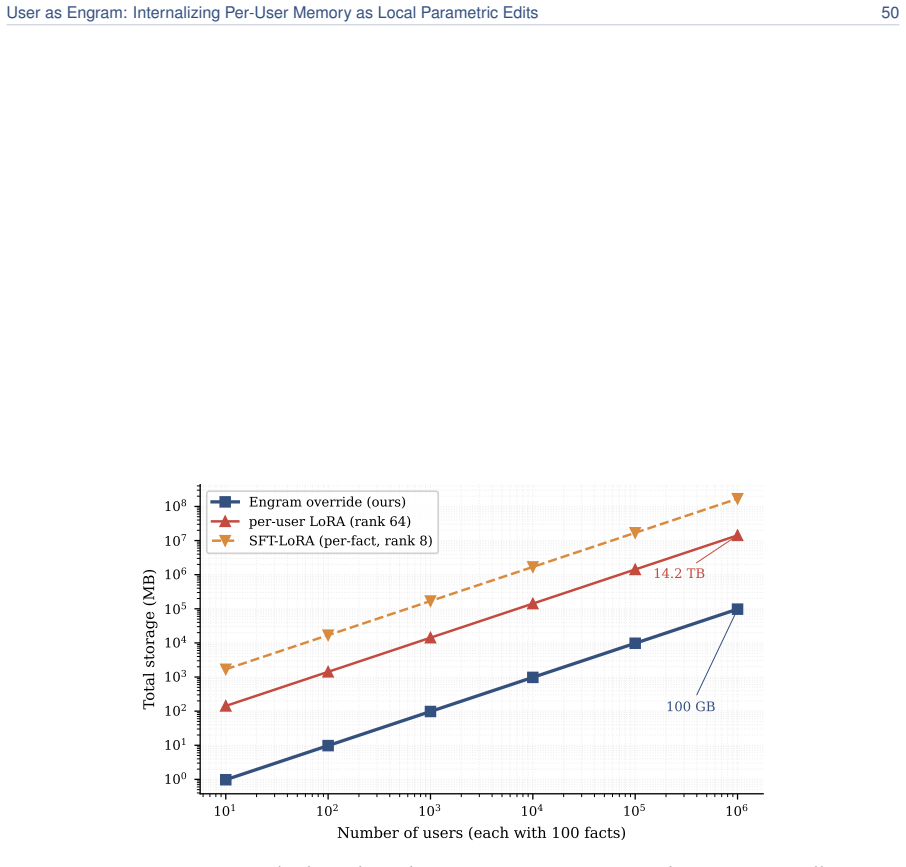
User facts can be internalized by writing them as local parametric edits to the hash-keyed memory table of an Engram model while the reasoning skill remains in a single shared adapter. The edits match the direct-recall performance of per-user LoRAs, deliver 5.6 times higher accuracy on indirect reasoning tasks on average, never degrade any user below the untouched base model, and occupy roughly 33,000 times less memory. Because different users land in disjoint hash slots their edits stack losslessly; upon retrieval the per-user table does not grow with population size and therefore overtakes retrieval pipelines once the fact count exceeds roughly 100.
What carries the argument
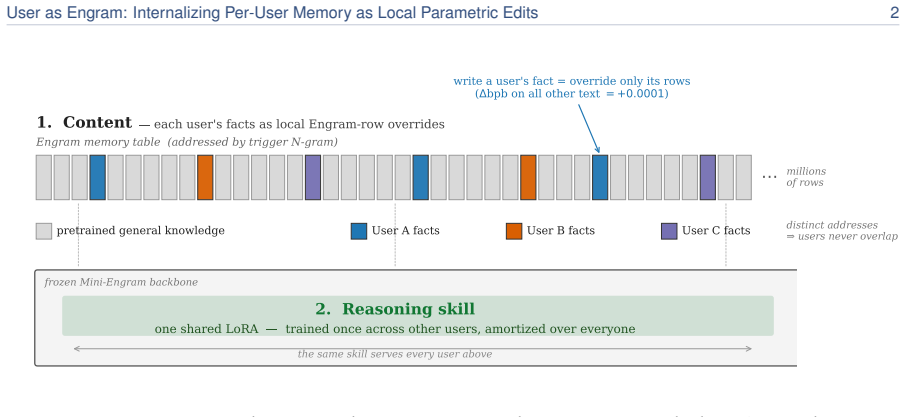
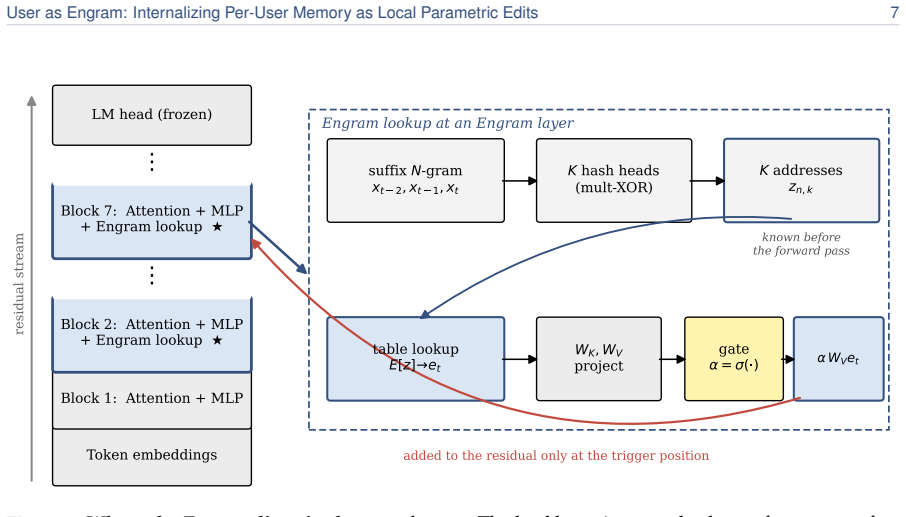
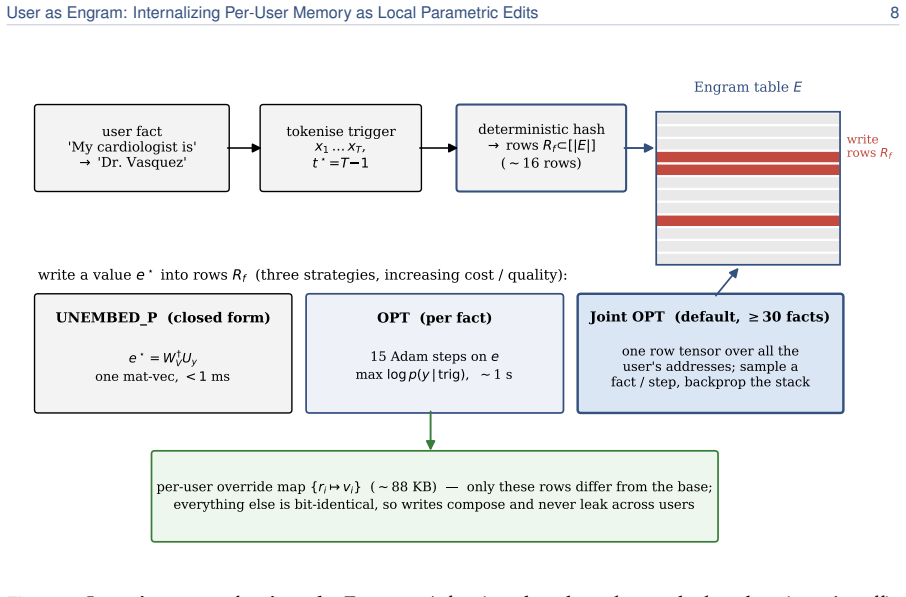
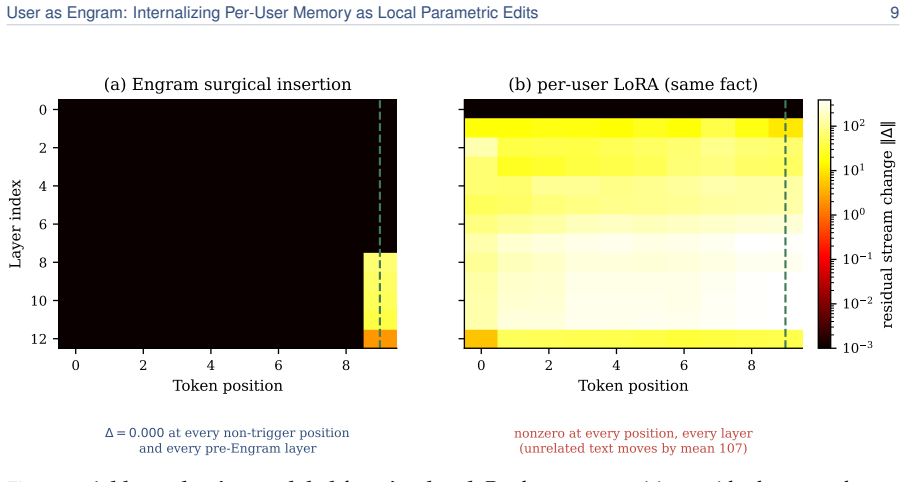
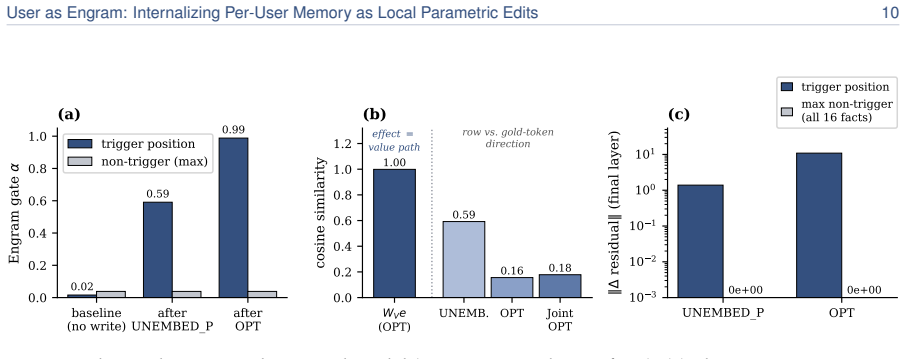
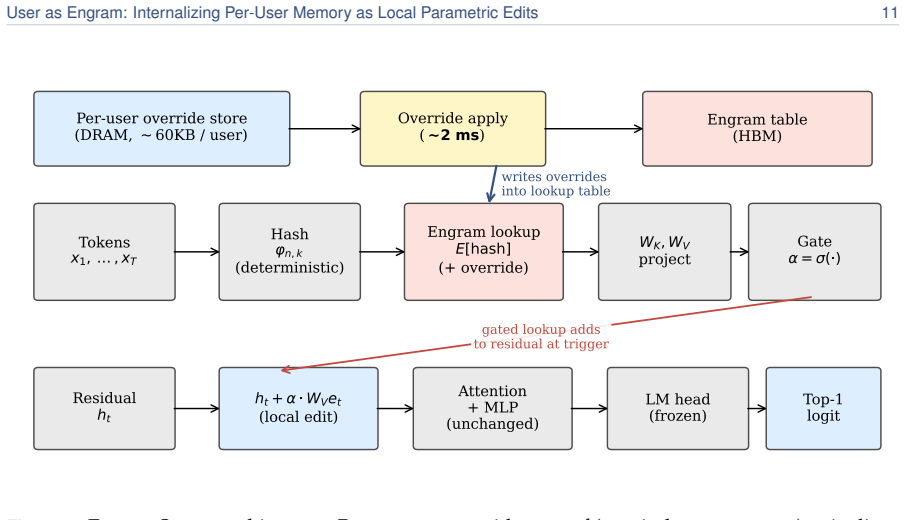
Surgical edits to the hash-keyed memory table of an Engram model, which activate lookup only at the exact trigger position, add the required value, and leave every other weight position mathematically unchanged to the last bit.
If this is right
- Direct recall of stored facts equals that of a dedicated per-user LoRA.
- Indirect reasoning accuracy rises 5.6 times on average while no user falls below base-model performance.
- Multiple users' facts occupy disjoint hash slots and compose additively without interference.
- Memory footprint remains roughly 33,000 times smaller than per-user adapters.
- Past approximately 100 facts the per-user table overtakes retrieval on a 2.5 times larger model.
Where Pith is reading between the lines
- Dynamic insertion and deletion of individual facts becomes possible without retraining or global weight changes.
- The same table could support verifiable fact provenance because each edit is isolated and reversible.
- Retrieval pipelines could be replaced by the table for populations larger than a few hundred users without proportional search cost growth.
Load-bearing premise
An Engram model already exists or can be built whose hash-keyed memory table accepts arbitrary user facts as edits that affect only the intended trigger positions and leave all other weights untouched.
What would settle it
A controlled test that writes a new fact into the table and then measures whether any token unrelated to that fact changes its output probability or whether the edit fails to activate exactly at the trigger position.
Figures
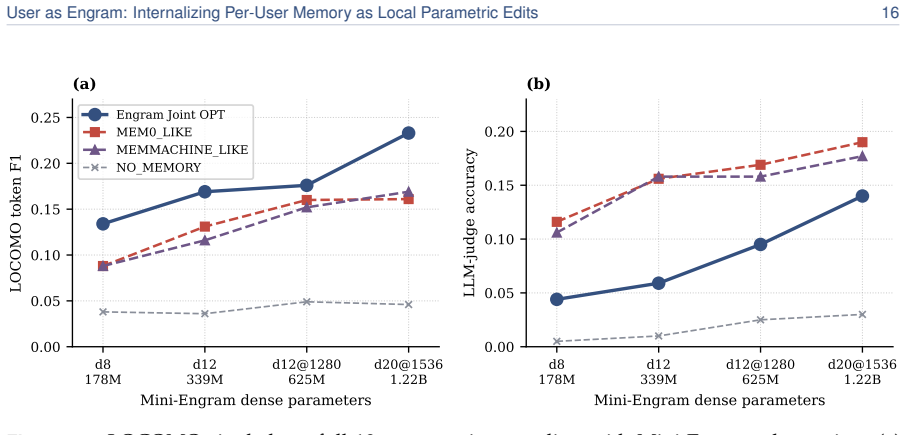
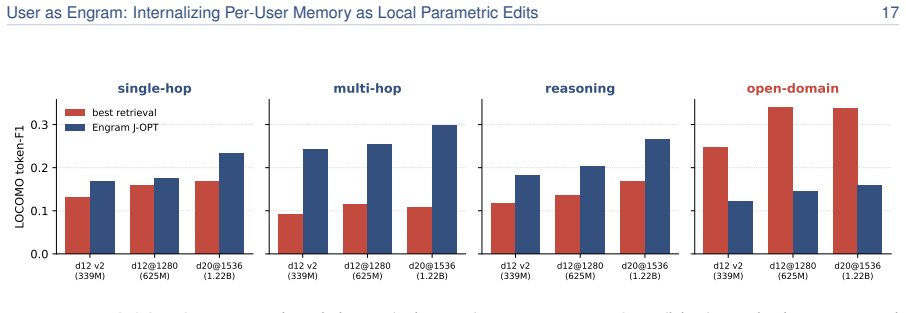
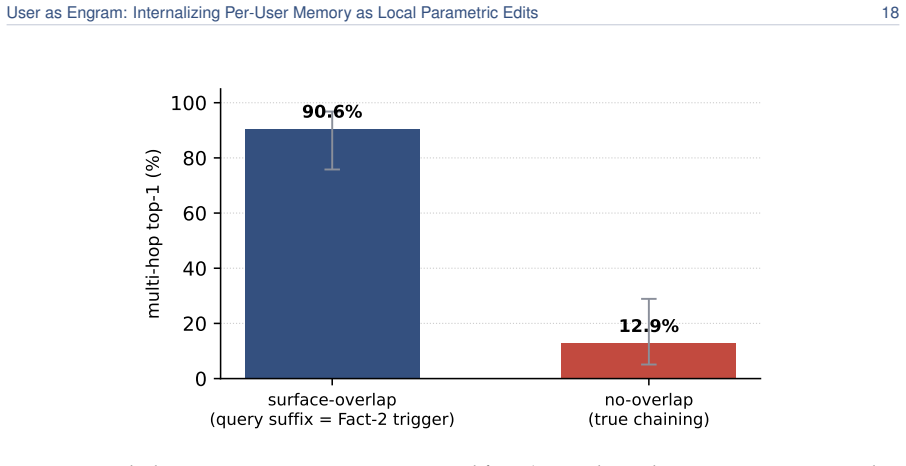
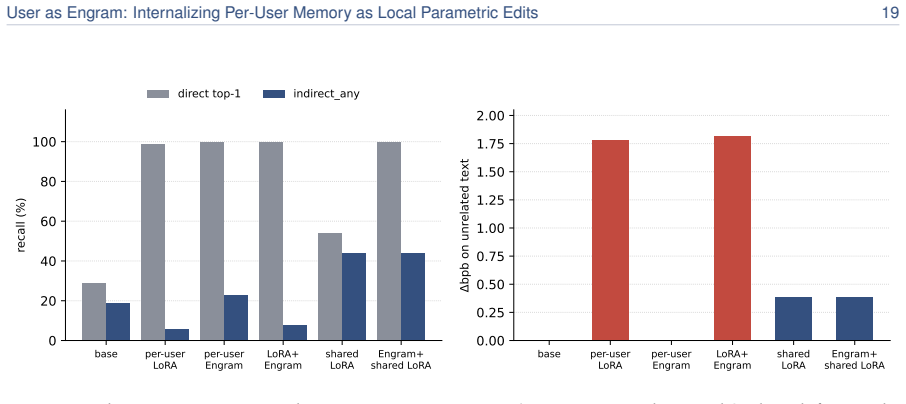
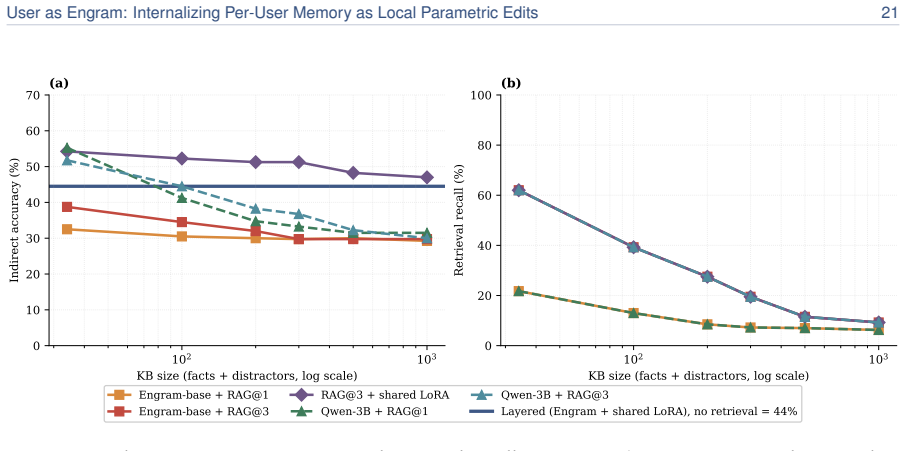
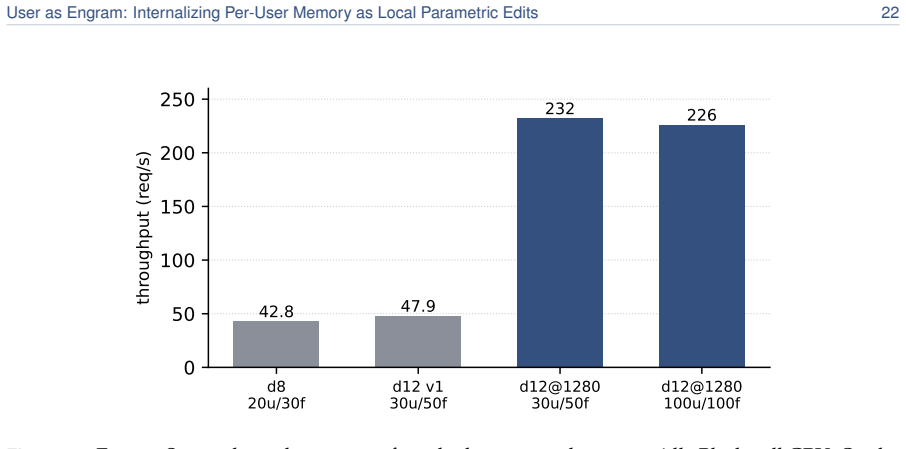
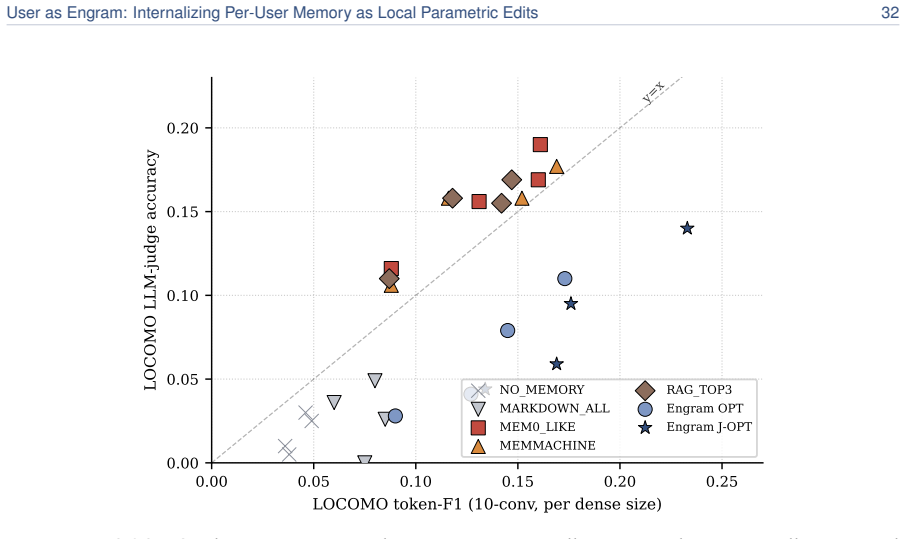
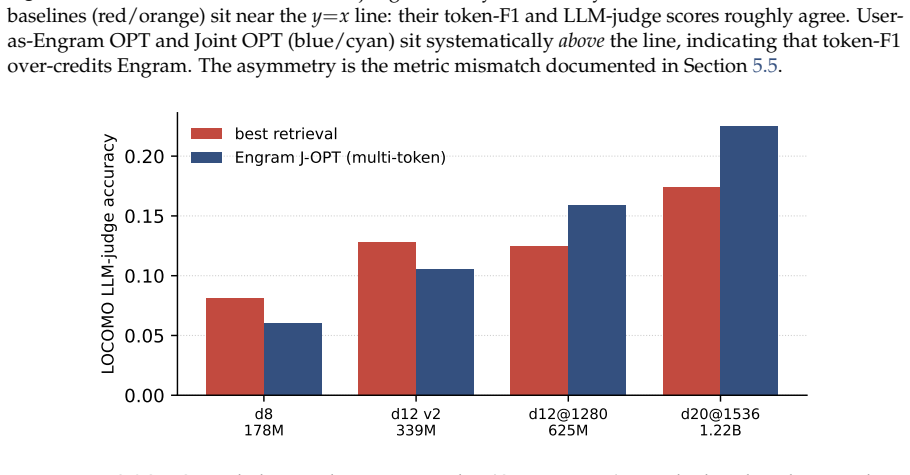
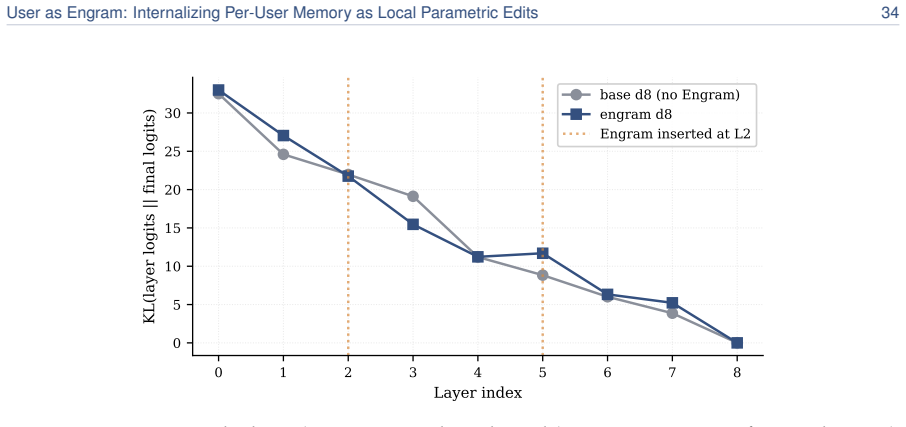
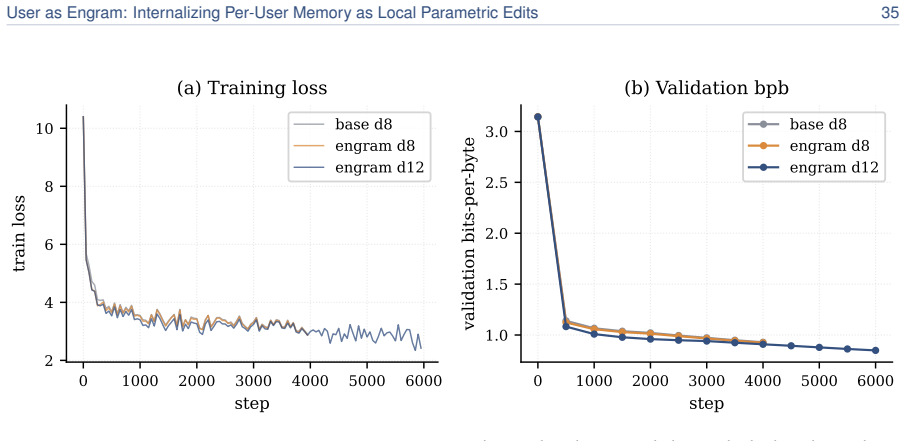
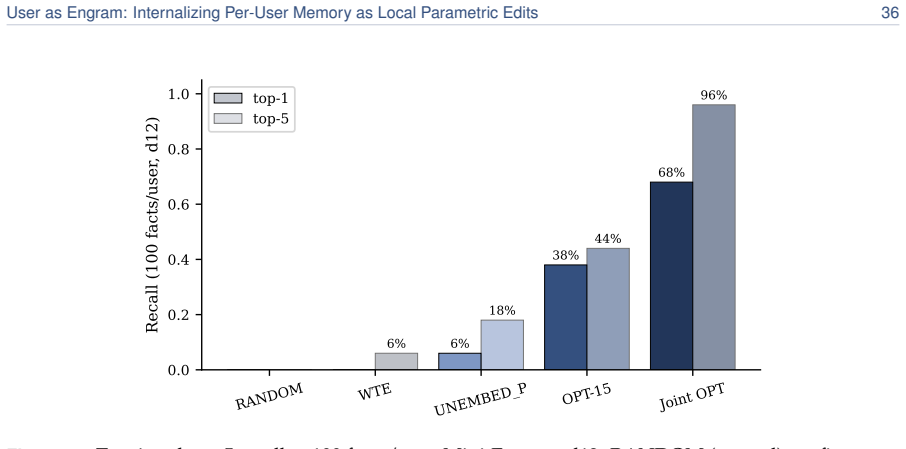
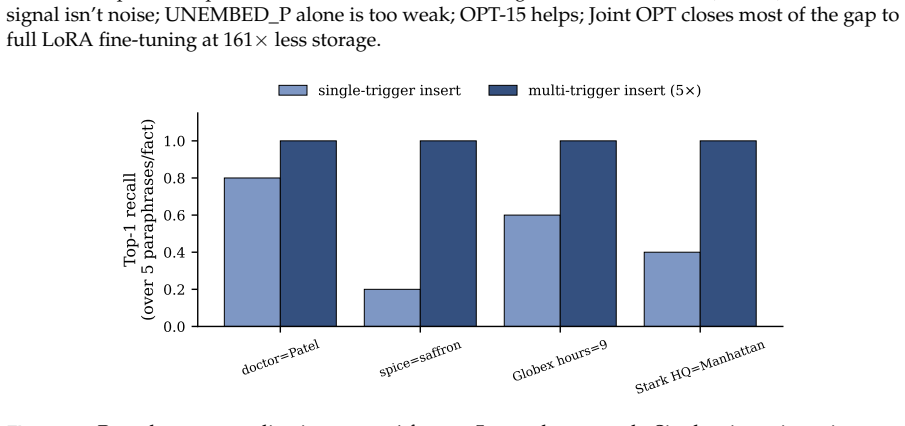
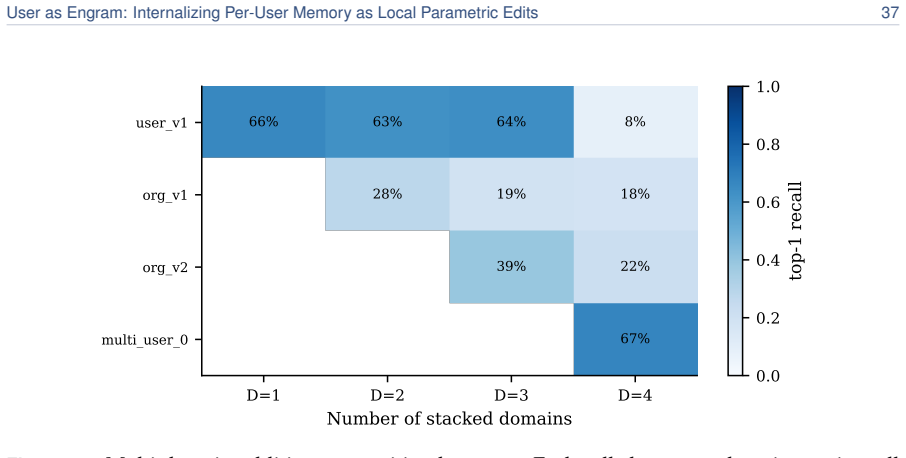
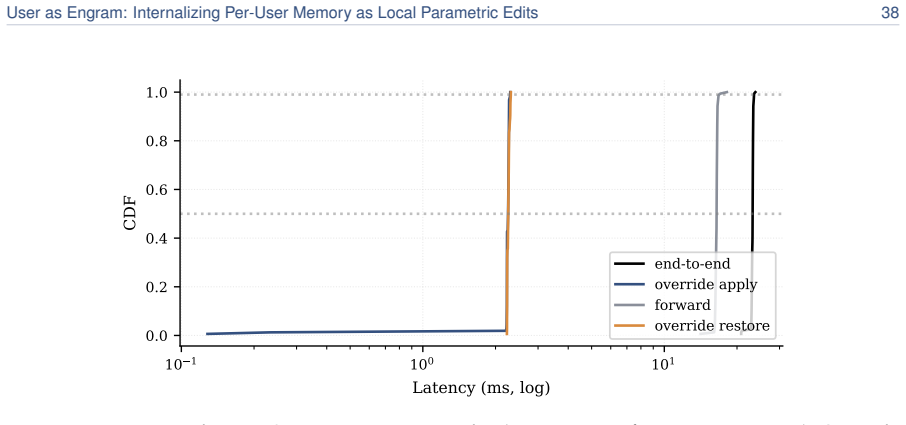
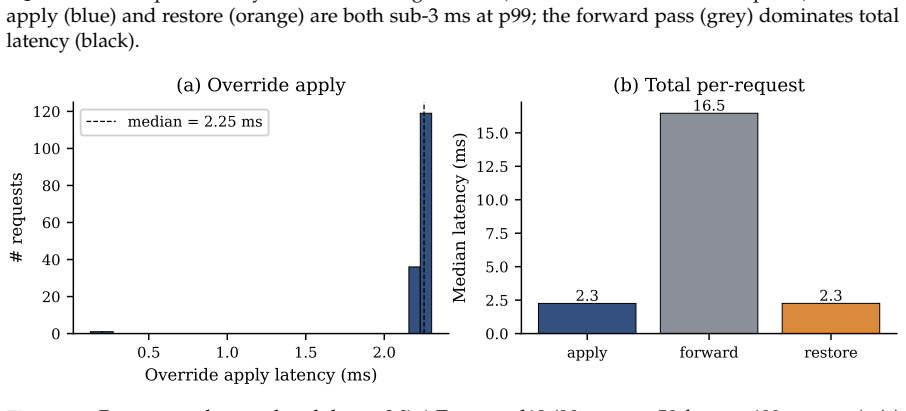
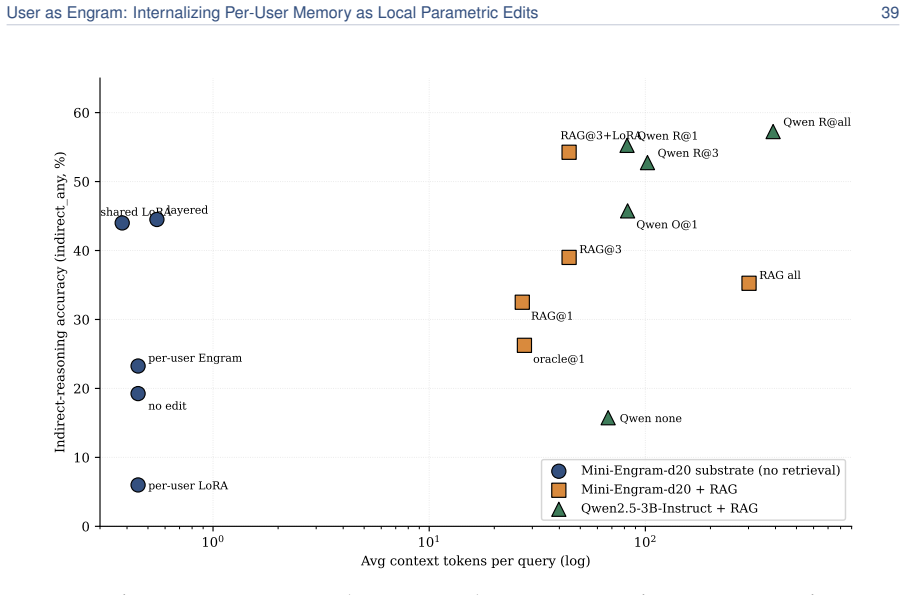
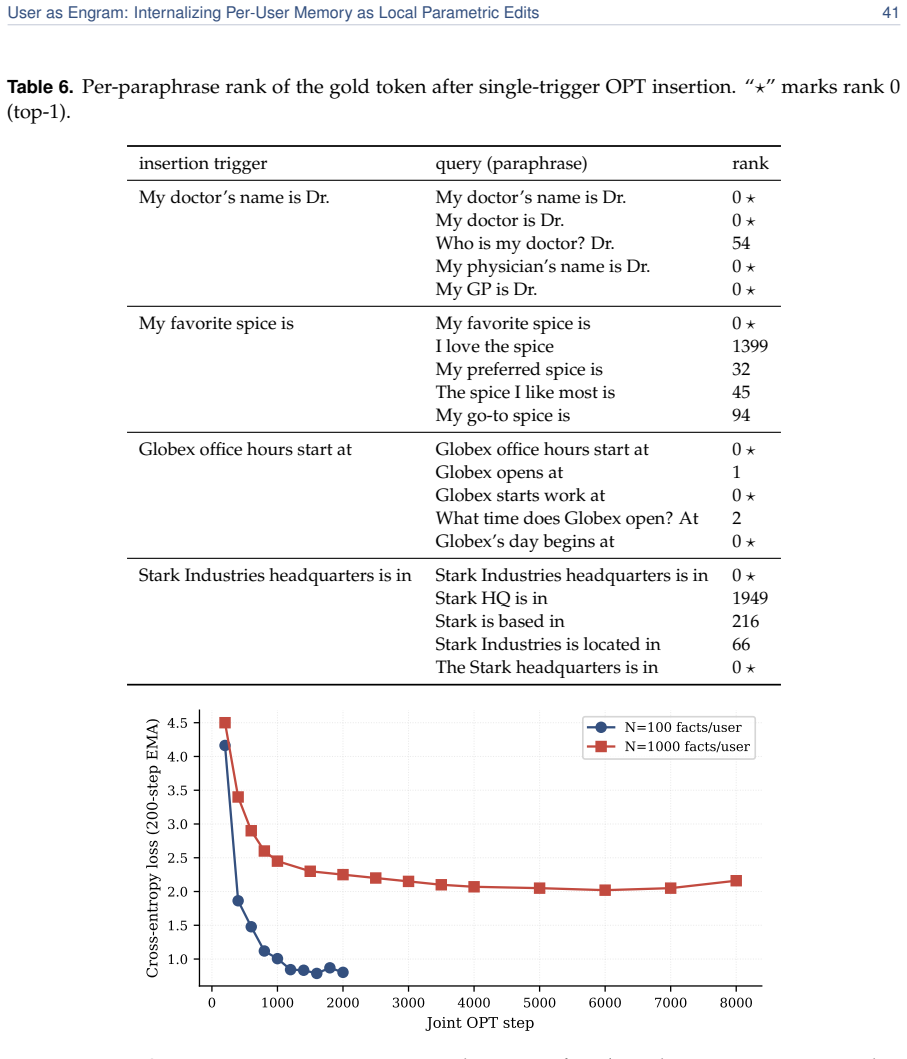
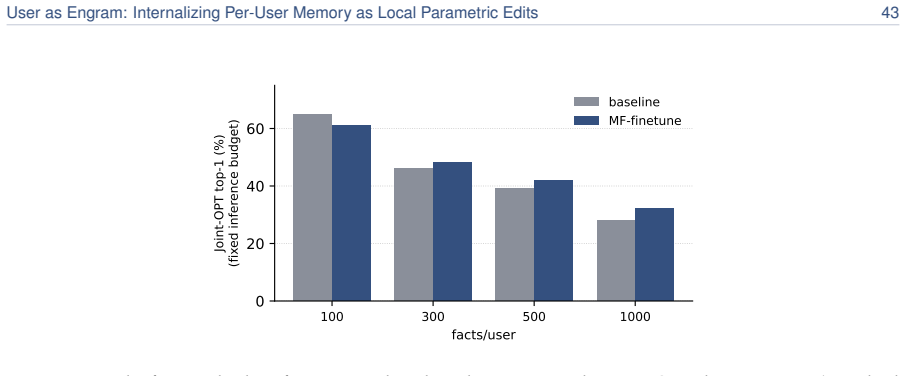
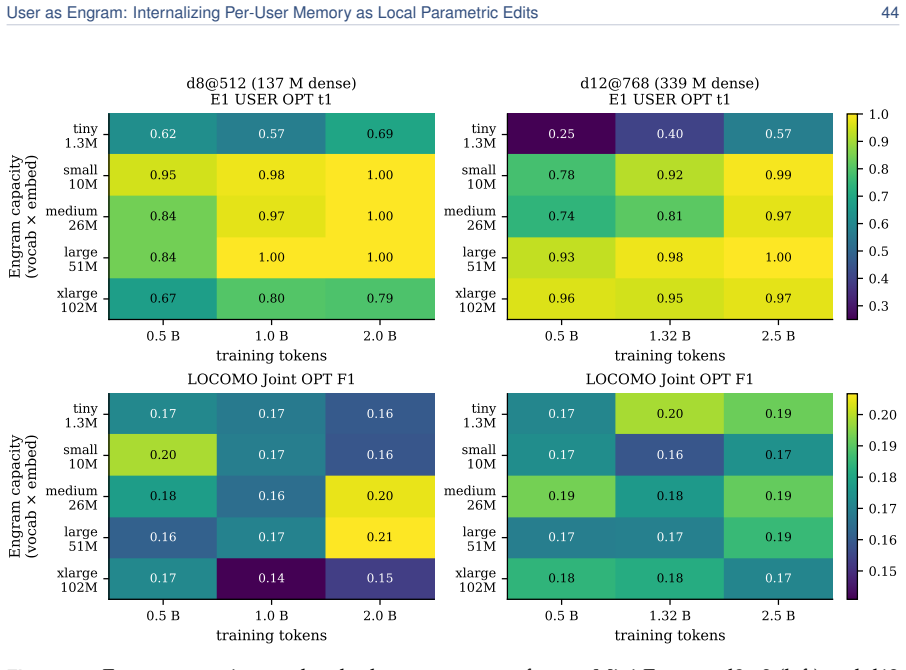
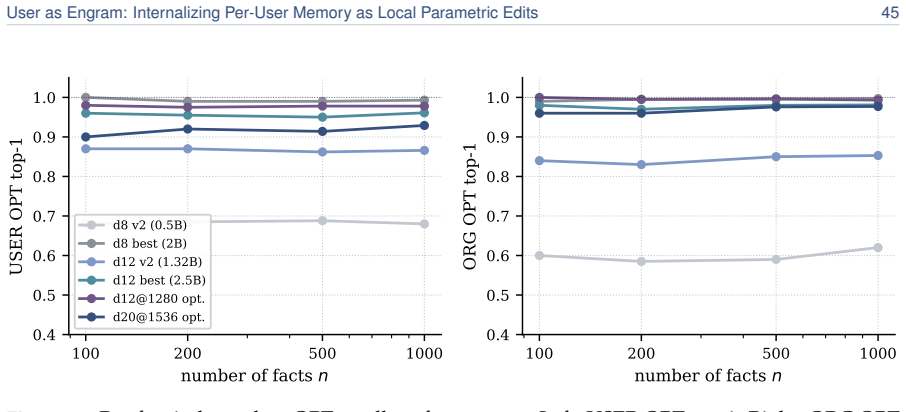
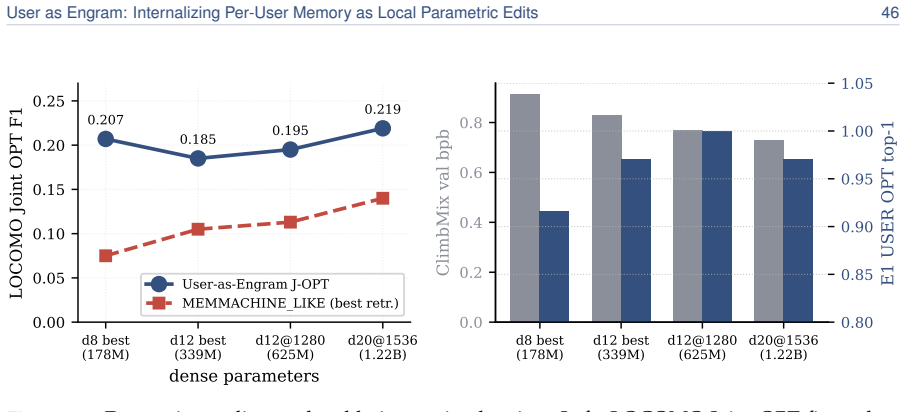
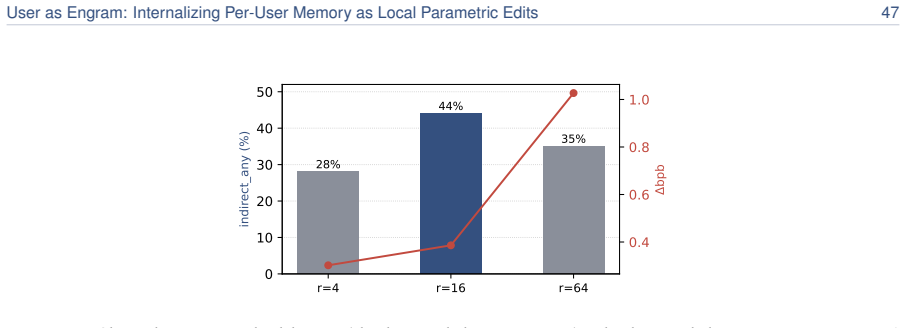
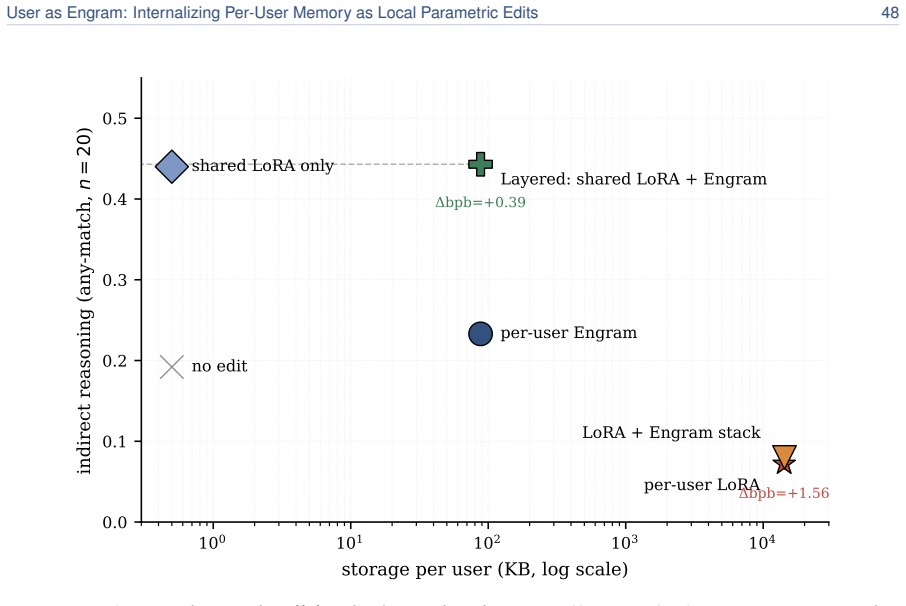
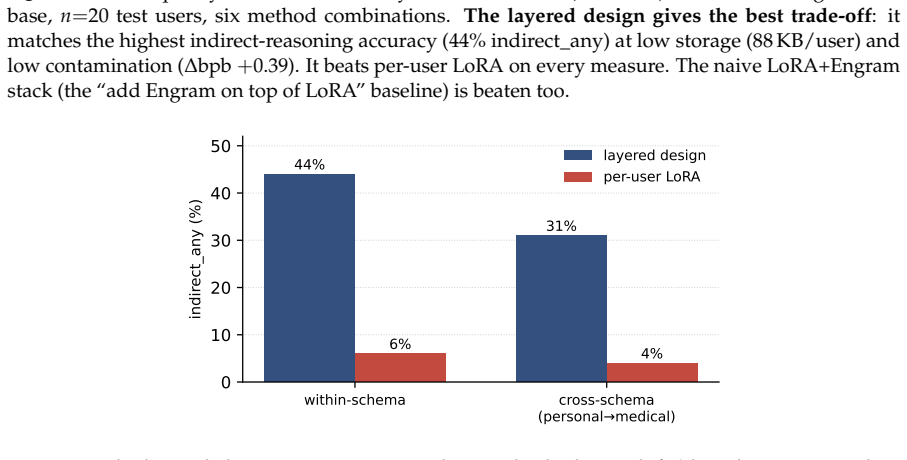
read the original abstract
Personal memory in a language model is two problems: content and reasoning skill. The brain keeps the two apart (a sparse, local engram in the hippocampus for each episode, a slow neocortex for the shared skills that interpret it), so a new fact need not overwrite everything else. Most personalization today keeps a user's facts outside the weights, in a natural-language memory file or a retrieval index. When facts are written into the model instead, the standard recipe is the per-user LoRA adapter, which does the opposite of the brain, folding content and skill into one global weight delta. Writing a user's facts as a LoRA contaminates text unrelated to them; writing the same facts as local Engram rows leaves it mathematically untouched, resulting in a roughly 33,000x smaller memory footprint. We therefore propose User as Engram: store a user's content as surgical edits to the hash-keyed memory table of an Engram model, and carry the reasoning skill in one shared adapter. This layered design matches per-user LoRA's direct recall while delivering 5.6x higher indirect-reasoning accuracy on average, and never makes a single user worse at reasoning than the untouched base. The edit is a glass box: writing a fact switches on its lookup at exactly the trigger, adds the value the answer needs, leaves every other position unchanged to the last bit, and fails if written into the wrong layer. Because different users' facts land in disjoint hash slots, their edits compose: many users live in one shared table at once, stacking additively and losslessly, where a per-user LoRA, a single global weight delta, admits only one. Upon retrieval, a per-user Engram table does not grow with the population the retriever must search, so past ~100 facts it overtakes a retrieval pipeline on a 2.5x larger model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'User as Engram,' a layered personalization method that stores per-user facts as surgical edits to the hash-keyed memory table of an Engram model while carrying reasoning skill in one shared adapter. It claims this matches per-user LoRA on direct recall, delivers 5.6x higher indirect-reasoning accuracy on average, produces a roughly 33,000x smaller memory footprint, enables lossless additive composition across users, and never degrades any user's reasoning relative to the base model. The edits are described as glass-box operations that affect only exact trigger positions.
Significance. If the isolation property and empirical results hold, the approach could meaningfully advance scalable multi-user personalization by separating content storage from reasoning skill, avoiding the interference and memory scaling issues of per-user LoRA while outperforming retrieval on larger models past ~100 facts. The lossless composition and 'never worse' guarantee would be particularly valuable if rigorously shown.
major comments (2)
- [Abstract / Engram model description] Abstract and Engram model section: the central claims of bit-exact isolation ('leaves every other position unchanged to the last bit'), 33,000x footprint reduction, and 'never makes a single user worse' all rest on the existence of a hash-keyed memory table enabling surgical edits with no side effects on unrelated positions or layers; no construction, hashing scheme, layer placement, or edit operator is provided to demonstrate how arbitrary facts achieve this isolation.
- [Abstract] Abstract: the quantitative performance claims (5.6x indirect-reasoning accuracy, matching direct recall, no degradation) are stated without any reference to datasets, baselines, number of users/facts, evaluation protocol, or error bars, making it impossible to assess whether the layered design actually delivers the reported advantages over per-user LoRA.
minor comments (1)
- [Notation / Model description] The term 'Engram rows' and 'hash-keyed memory table' are introduced without a formal definition, pseudocode, or equation showing the mapping from fact to edit and the exact lookup mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the clear identification of areas where additional detail is required. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Engram model description] Abstract and Engram model section: the central claims of bit-exact isolation ('leaves every other position unchanged to the last bit'), 33,000x footprint reduction, and 'never makes a single user worse' all rest on the existence of a hash-keyed memory table enabling surgical edits with no side effects on unrelated positions or layers; no construction, hashing scheme, layer placement, or edit operator is provided to demonstrate how arbitrary facts achieve this isolation.
Authors: The referee is correct that the abstract and Engram model section currently provide only a high-level description of the hash-keyed table and do not specify the concrete construction, hashing scheme, layer placement, or edit operator. We will revise the Engram model section to include these details: a deterministic hash function that maps fact keys to disjoint slots, placement within designated feed-forward sublayers, and an additive edit operator applied only to the value vector at the hashed index. This addition will make the bit-exact isolation property explicit and verifiable. revision: yes
-
Referee: [Abstract] Abstract: the quantitative performance claims (5.6x indirect-reasoning accuracy, matching direct recall, no degradation) are stated without any reference to datasets, baselines, number of users/facts, evaluation protocol, or error bars, making it impossible to assess whether the layered design actually delivers the reported advantages over per-user LoRA.
Authors: We agree that the abstract presents the numerical claims without the necessary experimental context. We will revise the abstract to reference the evaluation setup, including the datasets and tasks used, the number of users and facts, the per-user LoRA and retrieval baselines, the evaluation protocol, and the fact that error bars appear in the main results section. revision: yes
Circularity Check
No circularity; proposal rests on external model assumption and empirical claims
full rationale
The manuscript proposes a layered architecture that stores user facts as edits to a hash-keyed Engram memory table while sharing one adapter for reasoning skill. All performance claims (5.6x indirect-reasoning gain, 33,000x footprint reduction, lossless composition, bit-exact isolation) are presented as direct consequences of the stated properties of that table rather than derived from any equation, fitted parameter, or self-citation chain inside the paper. No self-definitional loops, renamed predictions, or load-bearing self-citations appear; the central premise is an engineering assumption about the existence and behavior of the Engram substrate, not a reduction of the target result to itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The brain separates episodic content (hippocampus) from shared reasoning skill (neocortex).
invented entities (1)
-
Engram model with hash-keyed memory table
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Memory Depth, Not Memory Access: Selective Parametric Consolidation for Long-Running Language Agents
EVAF, a surprise- and valence-gated LoRA mechanism, provides memory depth for goal persistence in language agents via the loop-drift protocol, complementary to retrieval.
Reference graph
Works this paper leans on
-
[1]
B. Li. User as code: Executable memory for personalized agents. arXiv:2606.16707, 2026
arXiv 2026
-
[2]
R. Semon. The Mneme. George Allen & Unwin, London, 1921. (English translation of Die Mneme, 1904; origin of the term ``engram'')
1921
-
[3]
J. L. McClelland, B. L. McNaughton, and R. C. O'Reilly. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory. Psychological Review, 102(3):419--457, 1995
1995
-
[4]
Tonegawa, X
S. Tonegawa, X. Liu, S. Ramirez, and R. Redondo. Memory engram cells have come of age. Neuron, 87(5):918--931, 2015
2015
-
[5]
Kumaran, D
D. Kumaran, D. Hassabis, and J. L. McClelland. What learning systems do intelligent agents need? Complementary learning systems theory updated. Trends in Cognitive Sciences, 20(7):512--534, 2016
2016
-
[6]
X. Cheng, W. Zeng, D. Dai, Q. Chen, B. Wang, Z. Xie, K. Huang, X. Yu, Z. Hao, Y. Li, H. Zhang, H. Zhang, D. Zhao, and W. Liang. Conditional memory via scalable lookup: A new axis of sparsity for large language models. arXiv:2601.07372, January 2026
Pith/arXiv arXiv 2026
-
[7]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. NeurIPS 2017
2017
-
[8]
Brown et al
T. Brown et al. Language models are few-shot learners. NeurIPS 2020
2020
-
[9]
Radford, J
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever. Language models are unsupervised multitask learners ( GPT-2 ). OpenAI technical report, 2019
2019
-
[10]
S. Min, X. Lyu, A. Holtzman, M. Artetxe, M. Lewis, H. Hajishirzi, and L. Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? EMNLP 2022
2022
-
[11]
uttler, M. Lewis, W. Yih, T. Rockt\
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K\"uttler, M. Lewis, W. Yih, T. Rockt\"aschel, S. Riedel, and D. Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. NeurIPS 2020
2020
-
[12]
Y. Gao et al. Retrieval-augmented generation for large language models: A survey. arXiv:2312.10997, 2023
Pith/arXiv arXiv 2023
-
[13]
Shazeer, A
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. ICLR 2017
2017
-
[14]
D. Dai et al. DeepSeekMoE : Towards ultimate expert specialization in mixture-of-experts language models. arXiv:2401.06066, 2024
Pith/arXiv arXiv 2024
-
[15]
Mangrulkar et al
S. Mangrulkar et al. PEFT : State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022
2022
-
[16]
Jordan et al
K. Jordan et al. Muon : An optimiser for hidden layers in neural networks. GitHub / blog post, 2024
2024
-
[17]
C. Huang et al. LoRAHub : Efficient cross-task generalization via dynamic LoRA composition. arXiv:2307.13269, 2023
arXiv 2023
-
[18]
Wu et al
D. Wu et al. LongMemEval : Benchmarking chat assistants on long-term memory. arXiv 2024
2024
-
[19]
Maharana et al
A. Maharana et al. LOCOMO : Evaluating very long-term conversational memory of LLM agents. ACL 2024
2024
-
[20]
M. Tavakoli, A. Salemi, C. Ye, M. Abdalla, H. Zamani, and J. R. Mitchell. Beyond a million tokens: Benchmarking and enhancing long-term memory in LLM s ( BEAM ). arXiv:2510.27246, 2025
arXiv 2025
-
[21]
B. Jiang, Y. Yuan, M. Shen, Z. Hao, Z. Xu, Z. Chen, Z. Liu, A. R. Vijjini, J. He, H. Yu, R. Poovendran, G. Wornell, L. Ungar, D. Roth, S. Chen, and C. J. Taylor. PersonaMem-v2 : Towards personalized intelligence via learning implicit user personas and agentic memory. arXiv:2512.06688, 2025
arXiv 2025
-
[22]
Karpathy
A. Karpathy. nanochat: an experimental training harness for LLMs. https://github.com/karpathy/nanochat, 2026
2026
-
[23]
E. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA : Low-rank adaptation of large language models. ICLR 2022
2022
-
[24]
Houlsby et al
N. Houlsby et al. Parameter-efficient transfer learning for NLP . ICML 2019
2019
- [25]
- [26]
-
[27]
J. Chen, H. Zhang, L. Pang, Y. Tong, H. Zhou, Y. Zhan, W. Lin, and Z. Zheng. Privacy-preserving reasoning with knowledge-distilled parametric retrieval-augmented generation ( DistilledPRAG ). arXiv:2509.01088, 2025
arXiv 2025
-
[28]
Z. Tan, Q. Liu, and M. Jiang. Democratizing large language models via personalized parameter-efficient fine-tuning ( OPPU ). EMNLP 2024 (arXiv:2402.04401)
arXiv 2024
-
[29]
Zhuang et al
Y. Zhuang et al. HYDRA : Per-user adapters for personalised LLMs . arXiv 2024
2024
-
[30]
M. Bini, O. Bohdal, U. Michieli, Z. Akata, M. Ozay, and T. Ceritli. MemLoRA : Distilling expert adapters for on-device memory systems. arXiv:2512.04763, 2025
arXiv 2025
-
[31]
R. Charakorn, E. Cetin, Y. Tang, and R. T. Lange. Text-to- LoRA : Instant transformer adaption. arXiv:2506.06105, 2025
arXiv 2025
-
[32]
Tan et al
Z. Tan et al. PER-PCS : Per-user post-hoc LoRA composition. arXiv 2024
2024
- [33]
-
[34]
L. Chen, Z. Ye, Y. Wu, et al. Punica: Multi-tenant LoRA serving. MLSys 2024
2024
-
[35]
Lample, A
G. Lample, A. Sablayrolles, M. Ranzato, L. Denoyer, and H. J\'egou. Large memory layers with product keys. NeurIPS 2019
2019
-
[36]
P. He. PEER : Mixture of one million experts. arXiv 2024
2024
-
[37]
Berges, B
V. Berges, B. O g uz, D. Haziza, W. Yih, L. Zettlemoyer, and G. Ghosh. Memory layers at scale. ICML 2025
2025
- [38]
-
[39]
Huang et al
J. Huang et al. OverEncoding : hashed N-gram embeddings via averaging. 2025
2025
-
[40]
Yu et al
L. Yu et al. SCONE : scalable contextual N-gram embeddings. 2025
2025
-
[41]
A. Pagnoni, R. Pasunuru, P. Rodriguez, et al. BLT : byte latent transformer with hashed N-gram embeddings. arXiv:2412.09871, 2025
arXiv 2025
-
[42]
Liu et al
A. Liu et al. SuperBPE : word-level BPE for compositional patterns. 2025
2025
-
[43]
LoRA stacking patterns for Stable Diffusion
CivitAI Community . LoRA stacking patterns for Stable Diffusion. https://civitai.com/, 2024
2024
-
[44]
K. Meng, D. Bau, A. Andonian, and Y. Belinkov. Locating and editing factual associations in GPT ( ROME ). NeurIPS 2022
2022
-
[45]
Meng et al
K. Meng et al. MEMIT : Mass-editing memory in a transformer. ICLR 2023
2023
-
[46]
Cohen et al
R. Cohen et al. Evaluating the ripple effects of knowledge editing in language models ( MQuAKE ). 2023
2023
-
[47]
Cohen et al
R. Cohen et al. RippleEdits : A benchmark for ripple effects of model editing. 2024
2024
-
[48]
Meng et al
K. Meng et al. CounterFact : a counterfactual editing benchmark. 2022
2022
- [49]
-
[50]
Sun et al
Z. Sun et al. Recitation-augmented language models. ICLR 2023
2023
-
[51]
A. Yang, B. Yang, B. Zhang, et al. Qwen2.5 technical report. arXiv:2412.15115, 2025
Pith/arXiv arXiv 2025
-
[52]
A. Yang, A. Li, B. Yang, et al. Qwen3 technical report. arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[53]
A. Grattafiori, A. Dubey, A. Jauhri, et al. The Llama 3 herd of models. arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[54]
A. Q. Jiang, A. Sablayrolles, A. Mensch, et al. Mistral 7B. arXiv:2310.06825, 2023
Pith/arXiv arXiv 2023
-
[55]
DeepSeek-AI. DeepSeek-V3 technical report. arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[56]
Reimers and I
N. Reimers and I. Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. EMNLP-IJCNLP 2019
2019
-
[57]
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. NeurIPS 2020
2020
-
[58]
L. Zheng, W.-L. Chiang, Y. Sheng, et al. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. NeurIPS 2023 Datasets and Benchmarks. arXiv:2306.05685
Pith/arXiv arXiv 2023
-
[59]
C. Packer, S. Wooders, K. Lin, et al. MemGPT: Towards LLMs as operating systems. arXiv:2310.08560, 2023
Pith/arXiv arXiv 2023
-
[60]
P. Chhikara, D. Khant, S. Aryan, T. Singh, and D. Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. arXiv:2504.19413, 2025
Pith/arXiv arXiv 2025
-
[61]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, and Y. Zhang. A-MEM: Agentic memory for LLM agents. arXiv:2502.12110, 2025
Pith/arXiv arXiv 2025
-
[62]
P. Rasmussen, P. Paliychuk, T. Beauvais, J. Ryan, and D. Chalef. Zep: A temporal knowledge graph architecture for agent memory. arXiv:2501.13956, 2025
Pith/arXiv arXiv 2025
-
[63]
Z. Li, S. Song, H. Wang, et al. MemOS: An operating system for memory-augmented generation in large language models. arXiv:2505.22101, 2025
arXiv 2025
-
[64]
S. Wang, E. Yu, O. Love, T. Zhang, T. Wong, S. Scargall, and C. Fan. MemMachine: A ground-truth-preserving memory system for personalized AI agents. arXiv:2604.04853, 2026
Pith/arXiv arXiv 2026
-
[65]
C. Hu, X. Gao, Z. Zhou, et al. EverMemOS: A self-organizing memory operating system for structured long-horizon reasoning. arXiv:2601.02163, 2026
arXiv 2026
-
[66]
D. Patel and S. Patel. ENGRAM: Effective, lightweight memory orchestration for conversational agents. arXiv:2511.12960, 2025
arXiv 2025
-
[67]
S. Yan, X. Yang, Z. Huang, et al. Memory-R1: Enhancing large language model agents to manage and utilize memories via reinforcement learning. arXiv:2508.19828, 2025
Pith/arXiv arXiv 2025
-
[68]
Y. Yu, L. Yao, Y. Xie, et al. Agentic memory: Learning unified long-term and short-term memory management for LLM agents. arXiv:2601.01885, 2026
Pith/arXiv arXiv 2026
-
[69]
Y. Wang, R. Takanobu, Z. Liang, et al. Mem- : Learning memory construction via reinforcement learning. arXiv:2509.25911, 2025
Pith/arXiv arXiv 2025
-
[70]
Z. Zhang, X. Bo, C. Ma, et al. A survey on the memory mechanism of large language model based agents. arXiv:2404.13501, 2024
Pith/arXiv arXiv 2024
-
[71]
Y. Wu, S. Liang, C. Zhang, et al. From human memory to AI memory: A survey on memory mechanisms in the era of LLMs. arXiv:2504.15965, 2025
Pith/arXiv arXiv 2025
-
[72]
P. Du. Memory for autonomous LLM agents: Mechanisms, evaluation, and emerging frontiers. arXiv:2603.07670, 2026
arXiv 2026
-
[73]
N. Pollertlam and W. Kornsuwannawit. Beyond the context window: A cost-performance analysis of fact-based memory vs.\ long-context LLMs for persistent agents. arXiv:2603.04814, 2026
arXiv 2026
- [74]
- [75]
-
[76]
J. Liu, Z. Qiu, Z. Li, et al. A survey of personalized large language models: Progress and future directions. arXiv:2502.11528, 2025
arXiv 2025
-
[77]
Y. Xu, Q. Chen, Z. Ma, et al. Toward personalized LLM-powered agents: Foundations, evaluation, and future directions. arXiv:2602.22680, 2026
arXiv 2026
-
[78]
Mitchell, C
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning. Fast model editing at scale. ICLR 2022
2022
-
[79]
Mitchell, C
E. Mitchell, C. Lin, A. Bosselut, C. D. Manning, and C. Finn. Memory-based model editing at scale. ICML 2022
2022
-
[80]
D. Dai, L. Dong, Y. Hao, Z. Sui, B. Chang, and F. Wei. Knowledge neurons in pretrained transformers. ACL 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.