A Solver-Free Training Method for Predict-then-Optimize
Pith reviewed 2026-06-26 18:43 UTC · model grok-4.3
The pith
Measure transformation produces a solver-free surrogate loss for training predict-then-optimize models with consistency guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a measure transformation principle converts the intractable decision-regret objective into a new surrogate loss whose minimization during training requires no calls to the linear programming or combinatorial solver, while still guaranteeing Fisher consistency and excess risk bounds that link surrogate minimization to good decisions in the original problem.
What carries the argument
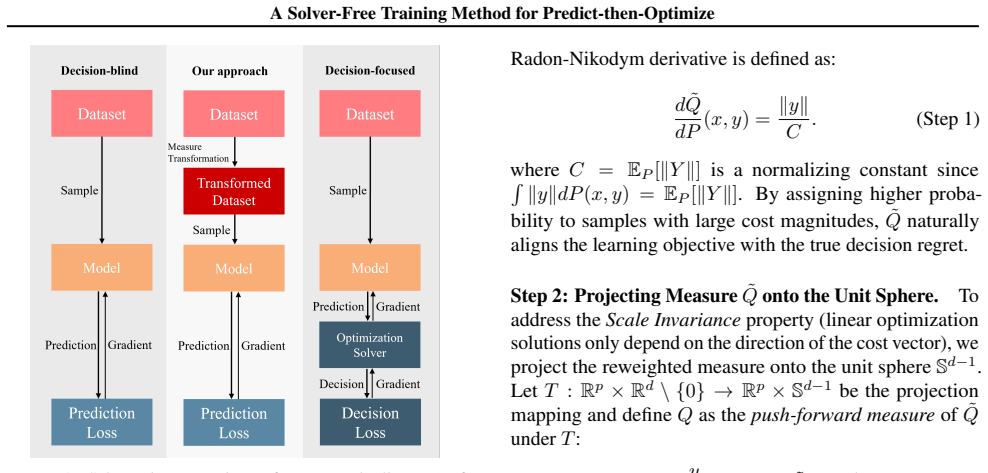
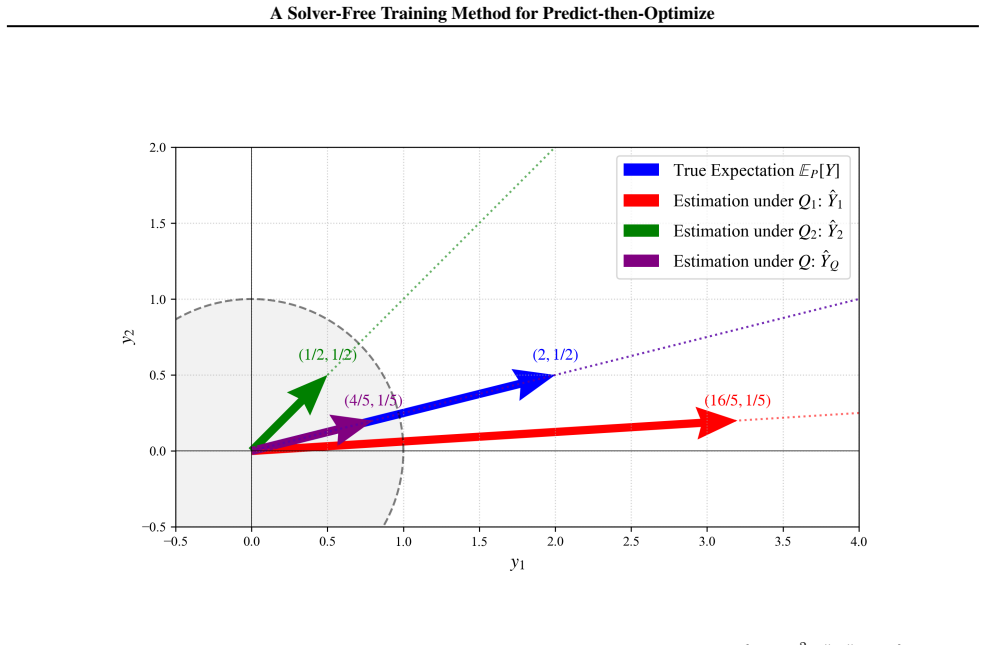
Measure transformation principle that re-expresses the decision regret as a surrogate loss depending only on predicted coefficients and true parameters, eliminating the need to solve the optimization problem inside the training loop.
If this is right
- Training becomes independent of solver runtime and therefore scales to larger datasets and more complex predictors.
- Fisher consistency ensures that as training data grows the learned model converges to the decision-optimal predictor.
- Excess risk bounds quantify how closely surrogate minimization approximates the true decision regret.
- The pipeline applies uniformly to linear programs and combinatorial problems without requiring differentiability of the solver.
Where Pith is reading between the lines
- The decoupling of training from solver calls could allow the method to be used with proprietary or non-differentiable black-box optimizers.
- Similar measure transformations might be explored for other non-smooth decision mappings such as those arising in integer or stochastic programming.
- Because the loss depends only on predictions and ground-truth parameters, it could support distributed or federated training where the optimizer itself cannot be shared.
Load-bearing premise
The surrogate obtained by the measure transformation has minimizers whose decisions match the quality of minimizers of the original decision regret.
What would settle it
A dataset where models trained to low surrogate loss still produce decisions with substantially higher regret than models trained by any direct regret approximation would falsify the claim that the surrogate preserves decision quality.
Figures

read the original abstract
We propose a scalable method for training prediction (machine learning) models in the predict-then-optimize paradigm, where model outputs serve as coefficients for a subsequent linear optimization task. Directly minimizing the empirical decision regret is intractable for linear programming and combinatorial optimization since the decision mapping is piecewise constant, and the gradients are zero almost everywhere. While existing methods address this by smoothing the differentiation process, they suffer from scalability issues, since a computationally expensive solver call is required for every gradient evaluation. To address this, we propose a decision-focused learning pipeline based on a measure transformation principle, which yields a new surrogate loss that is completely optimization-solver-free during training. We establish theoretical guarantees, including Fisher consistency and excess risk bounds. Empirically, our method achieves decision quality competitive with state-of-the-art methods while reducing training time by orders of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a decision-focused learning pipeline for predict-then-optimize problems that derives a new surrogate loss via a measure transformation principle. This surrogate is claimed to be completely solver-free during training, with theoretical guarantees of Fisher consistency and excess risk bounds, and empirical results showing competitive decision quality with orders-of-magnitude faster training compared to solver-dependent baselines.
Significance. If the measure transformation produces a surrogate whose minimization yields decisions with low regret in the original linear program (without introducing distribution-dependent biases), the approach would meaningfully advance scalability in decision-focused learning by removing per-gradient solver calls. The asserted theoretical guarantees (Fisher consistency plus excess risk bounds) would be a notable strength if they directly connect surrogate optimality to original-problem regret.
major comments (2)
- [Theoretical guarantees section (Fisher consistency and excess risk bounds)] The central claim that the measure-transformation surrogate yields decisions with low regret in the original LP rests on an unverified equivalence: Fisher consistency of the surrogate ensures recovery of the Bayes predictor under the transformed measure, but does not automatically ensure that argmin decisions match those of the original regret for finite samples or non-uniform cost distributions (see the weakest-assumption note). A direct argument or counter-example analysis linking the two is load-bearing and missing.
- [Measure transformation principle and its derivation] The excess-risk bound on the surrogate is presented as translating to decision quality, yet the reweighting induced by the measure transformation can alter the relative frequency of cost vectors near decision boundaries; without an additional condition on the cost distribution or a regret-transfer lemma, the bound does not guarantee low original regret.
minor comments (2)
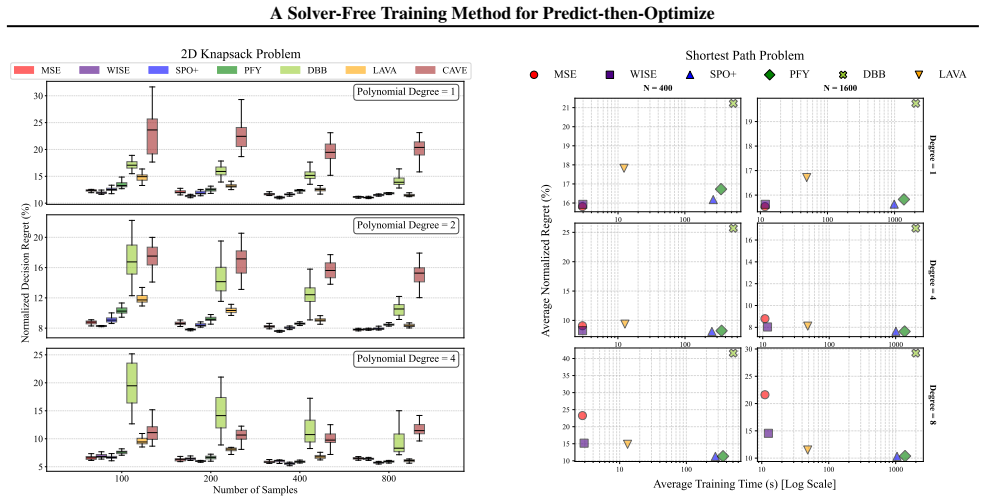
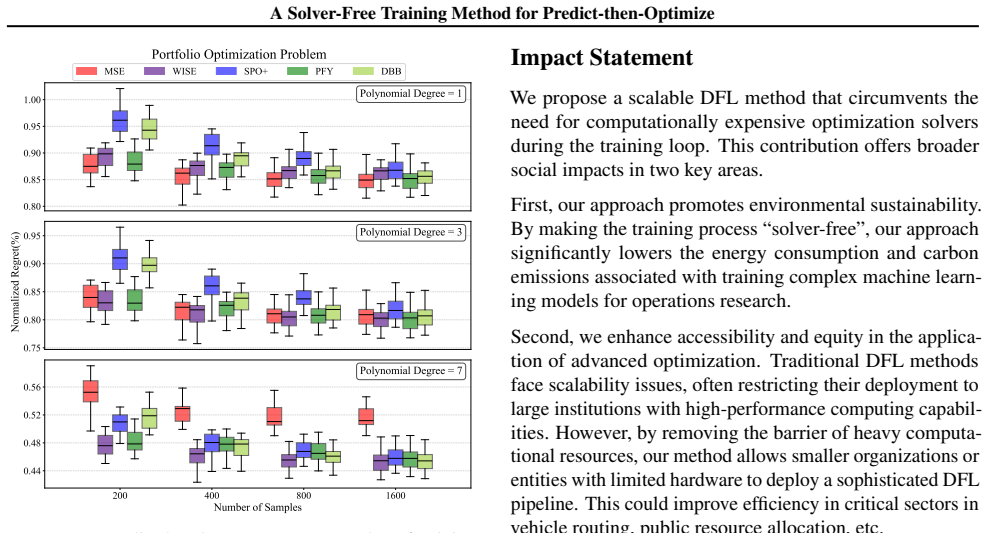
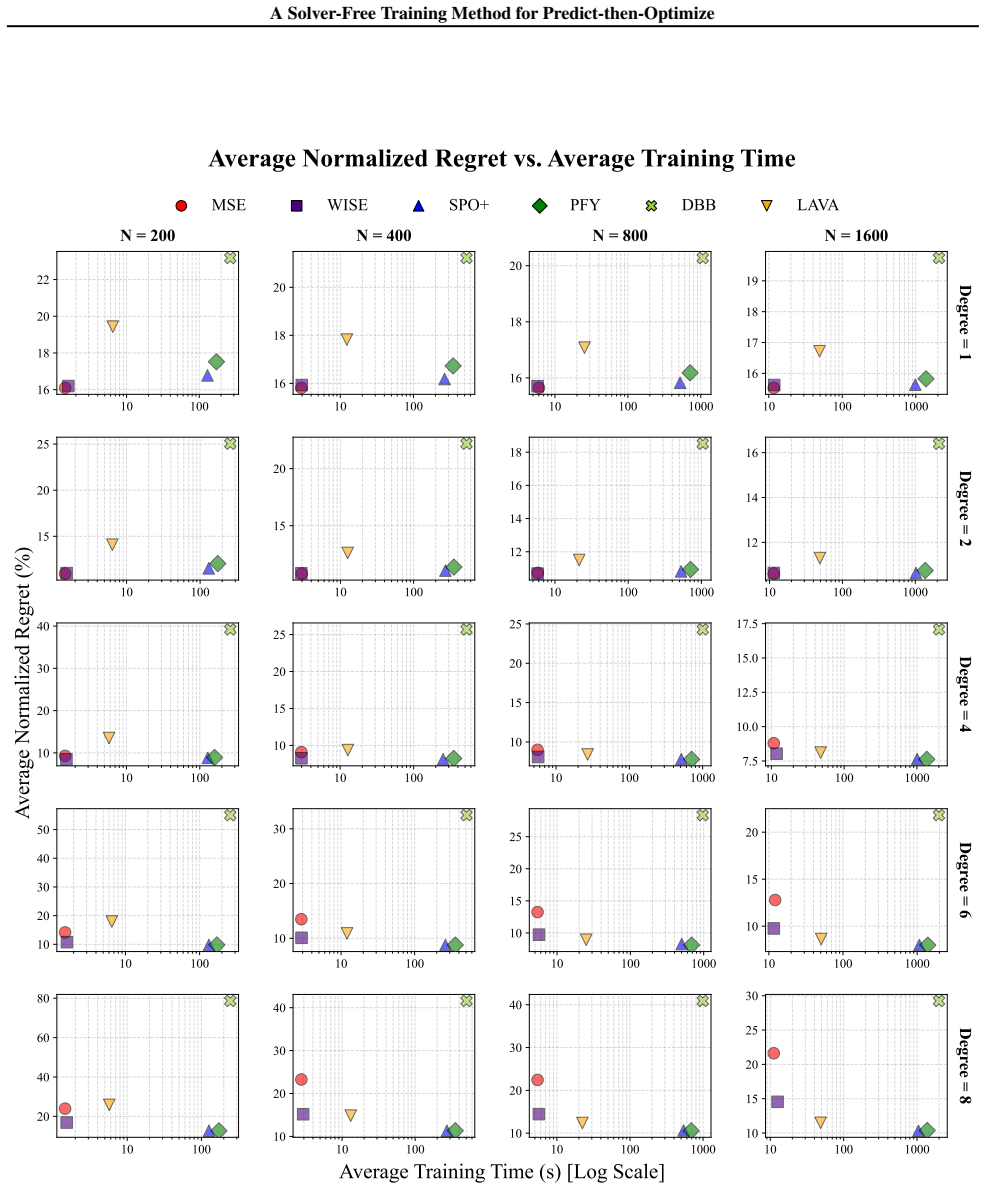
- [Experiments] The abstract states 'orders of magnitude' training-time reduction; the main experimental section should report concrete wall-clock ratios and solver-call counts versus the strongest baselines (e.g., SPO+, DCOL) for each benchmark.
- [Method] Notation for the transformed measure and the surrogate loss should be introduced with an explicit equation early in the method section to aid readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments correctly identify that the link between surrogate optimality and original regret requires an explicit transfer argument, which is not fully developed in the current manuscript. We will revise to add this connection.
read point-by-point responses
-
Referee: [Theoretical guarantees section (Fisher consistency and excess risk bounds)] The central claim that the measure-transformation surrogate yields decisions with low regret in the original LP rests on an unverified equivalence: Fisher consistency of the surrogate ensures recovery of the Bayes predictor under the transformed measure, but does not automatically ensure that argmin decisions match those of the original regret for finite samples or non-uniform cost distributions (see the weakest-assumption note). A direct argument or counter-example analysis linking the two is load-bearing and missing.
Authors: We agree that Fisher consistency under the transformed measure does not by itself guarantee matching argmin decisions on the original regret for finite samples or arbitrary cost distributions. The manuscript currently stops at consistency and excess-risk bounds on the surrogate. In revision we will add a direct regret-transfer lemma (under the paper's stated assumptions on the cost distribution) that bounds the original decision regret in terms of the surrogate excess risk, together with a brief counter-example analysis showing when the link would fail without the lemma. This addition will make the equivalence explicit rather than implicit. revision: yes
-
Referee: [Measure transformation principle and its derivation] The excess-risk bound on the surrogate is presented as translating to decision quality, yet the reweighting induced by the measure transformation can alter the relative frequency of cost vectors near decision boundaries; without an additional condition on the cost distribution or a regret-transfer lemma, the bound does not guarantee low original regret.
Authors: The referee is correct that reweighting can change the mass near decision boundaries and that the current excess-risk bound on the surrogate therefore does not automatically imply a bound on original regret. We will revise the theoretical section to state an explicit condition on the cost distribution (or prove the bound holds without it) and insert the regret-transfer lemma mentioned above. The revised manuscript will therefore contain both the additional condition (if needed) and the lemma that converts surrogate excess risk into original regret. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The provided abstract and context describe a measure transformation principle yielding a solver-free surrogate loss, with asserted Fisher consistency and excess risk bounds. No equations, self-citations, or derivations are visible that reduce any prediction or result to fitted inputs by construction, self-definition, or load-bearing self-citation chains. The central claim rests on an independently stated principle rather than renaming known results or smuggling ansatzes via prior author work. This matches the reader's assessment that no visible reductions exist, making the derivation self-contained against external benchmarks. No load-bearing steps qualify under the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Measure transformation principle can be applied to produce a Fisher-consistent surrogate for decision regret in linear optimization
invented entities (1)
-
Measure-transformation-based surrogate loss
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Decision-Focused Learning: When and Why Traditional Prediction Models Fail
A tutorial reviewing why traditional prediction models often fail to improve decision quality in stochastic optimization and summarizing key properties and tools of decision-focused learning.
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Optnet: Differentiable optimization as a layer in neural networks , author=. International conference on machine learning , pages=. 2017 , organization=
2017
-
[2]
Mathematics of Operations Research , volume=
Generalization bounds in the predict-then-optimize framework , author=. Mathematics of Operations Research , volume=
-
[3]
Operations Research , volume=
The big data newsvendor: Practical insights from machine learning , author=. Operations Research , volume=. 2019 , publisher=
2019
-
[4]
Management Science , volume=
Personalized dynamic pricing with machine learning: High-dimensional features and heterogeneous elasticity , author=. Management Science , volume=. 2021 , publisher=
2021
-
[5]
Advances in neural information processing systems , volume=
Learning with differentiable pertubed optimizers , author=. Advances in neural information processing systems , volume=
-
[6]
Management Science , volume=
From predictive to prescriptive analytics , author=. Management Science , volume=. 2020 , publisher=
2020
-
[7]
Blondel, Mathieu and Martins, André F. T. and Niculae, Vlad , date =. Learning with. 1901.02324 , eprinttype =
arXiv 1901
-
[8]
Implicit
Domke, Justin , date =. Implicit. Advances in
-
[9]
Advances in neural information processing systems , volume=
Task-based end-to-end model learning in stochastic optimization , author=. Advances in neural information processing systems , volume=
-
[10]
International Conference on Artificial Intelligence and Statistics , pages=
Dissecting the Impact of Model Misspecification in Data-Driven Optimization , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2025 , organization=
2025
-
[12]
and Lam, Henry and Zhang, Haofeng and Zhao, Yunfan , date =
Elmachtoub, Adam N. and Lam, Henry and Zhang, Haofeng and Zhao, Yunfan , date =. Estimate-. 2304.06833 , eprinttype =
-
[13]
predict, then optimize
Smart “predict, then optimize” , author=. Management Science , volume=. 2022 , publisher=
2022
-
[14]
Proceedings of the AAAI conference on artificial intelligence , volume=
Mipaal: Mixed integer program as a layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Decision-focused learning with directional gradients , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
He, Long and Mak, Ho-Yin , date =. Prescriptive. Proceedings of the 29th. 2306.02223 , eprinttype =
-
[17]
Hu, Xinyi and Lee, Jasper C. H. and Lee, Jimmy H. M. , date =. Branch &. Integration of
-
[18]
Management Science , volume=
Fast rates for contextual linear optimization , author=. Management Science , volume=. 2022 , publisher=
2022
-
[19]
Hu, Xinyi and Lee, Jasper C. H. and Lee, Jimmy H. M. , date =. Predict+. 2209.03668 , eprinttype =
-
[20]
and Lee, Jimmy H.M
Hu, Xinyi and Lee, Jasper C.H. and Lee, Jimmy H.M. , date =. Predict+. Proceedings of the
-
[21]
Hu, Xinyi and Lee, Jasper C. H. and Lee, Jimmy H. M. , date =. Two-. 2311.08022 , eprinttype =
-
[22]
Im, Hyungki and Benslimane, Wyame and Grigas, Paul , date =. Smart. 2505.22881 , eprinttype =
-
[23]
Advances in Neural Information Processing Systems , volume=
The bias-variance tradeoff in data-driven optimization: A local misspecification perspective , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Risk bounds and calibration for a smart predict-then-optimize method , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Decision-
Mandi, Jayanta and Kotary, James and Berden, Senne and Mulamba, Maxime and Bucarey, Victor and Guns, Tias and Fioretto, Ferdinando , date =. Decision-
-
[26]
Decision-
Mandi, Jayanta and Bucarey, Vı́ctor and Tchomba, Maxime Mulamba Ke and Guns, Tias , date =. Decision-. Proceedings of the 39th
-
[27]
Mandi, Jayanta and Defresne, Marianne and Berden, Senne and Guns, Tias , date =. Feasibility-. 2510.04951 , eprinttype =
-
[28]
Advances in Neural Information Processing Systems , volume=
Interior point solving for lp-based prediction+ optimisation , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Proceedings of the AAAI conference on artificial intelligence , volume=
Smart predict-and-optimize for hard combinatorial optimization problems , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[30]
Qi, Meng and Grigas, Paul and Shen, Zuo-Jun Max , date =. Integrated. 2110.12351 , eprinttype =
-
[31]
A Survey of Contextual Optimization Methods for Decision-Making under Uncertainty , author =
-
[32]
Mathematical Programming Computation , volume=
PyEPO: a PyTorch-based end-to-end predict-then-optimize library for linear and integer programming , author=. Mathematical Programming Computation , volume=. 2024 , publisher=
2024
-
[33]
International Conference on Learning Representations , year=
Differentiation of blackbox combinatorial solvers , author=. International Conference on Learning Representations , year=
-
[34]
Wang, Prince Zizhuang and Liang, Jinhao and Chen, Shuyi and Fioretto, Ferdinando and Zhu, Shixiang , date =. Gen-. 2502.05468 , eprinttype =
- [35]
-
[36]
End to End Learning and Optimization on Graphs , booktitle =
Wilder, Bryan and Ewing, Eric and Dilkina, Bistra and Tambe, Milind , date =. End to End Learning and Optimization on Graphs , booktitle =
-
[37]
Proceedings of the AAAI conference on artificial intelligence , volume=
Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[38]
2009 , publisher=
Directional statistics , author=. 2009 , publisher=
2009
-
[39]
Biometrika , volume=
Spherical regression , author=. Biometrika , volume=. 2003 , publisher=
2003
-
[40]
1998 , publisher=
Applied regression analysis , author=. 1998 , publisher=
1998
-
[41]
arXiv preprint arXiv:2505.11360 , year=
Efficient End-to-End Learning for Decision-Making: A Meta-Optimization Approach , author=. arXiv preprint arXiv:2505.11360 , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Decision-focused learning without decision-making: Learning locally optimized decision losses , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Landscape surrogate: Learning decision losses for mathematical optimization under partial information , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
International Conference on Machine Learning , pages=
Satnet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver , author=. International Conference on Machine Learning , pages=. 2019 , organization=
2019
-
[45]
Advances in neural information processing systems , volume=
Differentiable convex optimization layers , author=. Advances in neural information processing systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Automatically learning compact quality-aware surrogates for optimization problems , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
1999 , publisher=
Integer and combinatorial optimization , author=. 1999 , publisher=
1999
-
[48]
Management Science , volume=
Risk guarantees for end-to-end prediction and optimization processes , author=. Management Science , volume=. 2022 , publisher=
2022
-
[49]
arXiv preprint arXiv:2305.06584 , year=
Active learning in the predict-then-optimize framework: A margin-based approach , author=. arXiv preprint arXiv:2305.06584 , year=
-
[50]
arXiv preprint arXiv:2602.05340 , year=
Decision-Focused Sequential Experimental Design: A Directional Uncertainty-Guided Approach , author=. arXiv preprint arXiv:2602.05340 , year=
-
[51]
arXiv preprint arXiv:2602.02800 , year=
Decision-Focused Optimal Transport , author=. arXiv preprint arXiv:2602.02800 , year=
-
[52]
arXiv preprint arXiv:2512.15726 , year=
Decision-focused bias correction for fluid approximation , author=. arXiv preprint arXiv:2512.15726 , year=
-
[53]
Management Science , volume=
Small-data, large-scale linear optimization with uncertain objectives , author=. Management Science , volume=. 2021 , publisher=
2021
-
[54]
Operations Research , volume=
Debiasing in-sample policy performance for small-data, large-scale optimization , author=. Operations Research , volume=. 2024 , publisher=
2024
-
[55]
Journal of Artificial Intelligence Research , volume=
Decision-focused learning: Foundations, state of the art, benchmark and future opportunities , author=. Journal of Artificial Intelligence Research , volume=
-
[56]
European Journal of Operational Research , volume=
A survey of contextual optimization methods for decision-making under uncertainty , author=. European Journal of Operational Research , volume=. 2025 , publisher=
2025
-
[57]
International Conference on the Integration of Constraint Programming, Artificial Intelligence, and Operations Research , pages=
Cave: A cone-aligned approach for fast predict-then-optimize with binary linear programs , author=. International Conference on the Integration of Constraint Programming, Artificial Intelligence, and Operations Research , pages=. 2024 , organization=
2024
-
[58]
Advances in Neural Information Processing Systems , volume=
Solver-free decision-focused learning for linear optimization problems , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
From Inverse Optimization to Feasibility to
Mishra, Saurabh Kumar and Raj, Anant and Vaswani, Sharan , booktitle =. From Inverse Optimization to Feasibility to. 2024 , editor =
2024
-
[60]
Journal of Machine Learning Research , year =
Fast Rates in Statistical and Online Learning , author =. Journal of Machine Learning Research , year =
-
[61]
2016 , eprint =
Fast rates with high probability in exp-concave statistical learning , author =. 2016 , eprint =
2016
-
[62]
Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) , series =
Fast rates with high probability in exp-concave statistical learning , author =. Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS) , series =. 2017 , editor =
2017
-
[63]
Sphere packing numbers for subsets of the Boolean n -cube with bounded
Haussler, David , journal =. Sphere packing numbers for subsets of the Boolean n -cube with bounded. 1995 , volume =
1995
-
[64]
Available at SSRN 4487888 , year=
Value of one data point: Active label acquisition in assortment optimization , author=. Available at SSRN 4487888 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.