MixProLAP: Mixture-Induced Uncertainty Modeling for Probabilistic Language-Audio Pretraining
Pith reviewed 2026-06-26 15:40 UTC · model grok-4.3
The pith
Representing audio and text as distributions via mixture-induced overlaps models many-to-many alignment ambiguity more effectively than deterministic point embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mixing audio-text pairs to induce uncertainty from overlapping sounds and introducing a multi-level inclusion loss, the framework learns distribution representations that capture the many-to-many correspondences in audio-language data, outperforming deterministic contrastive methods on retrieval tasks.
What carries the argument
Mixture-induced uncertainty modeling, which creates overlapping audio from mixed pairs to simulate real scenes and semantic inclusions, combined with probabilistic cross-modal alignment.
If this is right
- Outperforms deterministic baselines on audio-text retrieval benchmarks.
- Captures semantic inclusion relations among sound events through the inclusion loss.
- Models many-to-many correspondence ambiguity in audio-text alignment.
- Provides uncertainty-aware representations for each modality.
Where Pith is reading between the lines
- This approach might generalize to other multimodal pretraining where ambiguity arises from real-world mixtures.
- Testing on datasets with explicitly labeled overlapping events could further validate the mixture simulation.
- The method suggests potential improvements in downstream tasks like audio captioning or event detection in noisy settings.
Load-bearing premise
Mixing audio-text pairs creates overlapping sounds that accurately reflect real acoustic mixtures and capture semantic inclusion relations among sound events.
What would settle it
A controlled experiment where models using masking-based simulation achieve comparable or better retrieval performance on real-world overlapping audio datasets would challenge the superiority of the mixture approach.
Figures

read the original abstract
Acoustic environments often contain multiple overlapping sound events, and the same acoustic scene can be described using diverse textual expressions, making audio-text alignment inherently ambiguous. This paper proposes a probabilistic audio-language pretraining framework to model many-to-many correspondence ambiguity in audio-text alignment. Unlike conventional contrastive methods that learn deterministic point embeddings, our approach represents each modality as a distribution and learns uncertainty-aware cross-modal alignment. Rather than relying on masking-based uncertainty simulation, we mix audio-text pairs to create overlapping sounds that better reflect real acoustic mixtures and capture semantic inclusion relations among sound events. We further introduce a multi-level inclusion loss to enforce representations consistent with these relations. Experiments on audio-text retrieval benchmarks show that the proposed method outperforms deterministic baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MixProLAP, a probabilistic audio-language pretraining framework to model many-to-many correspondence ambiguity in audio-text alignment. Unlike deterministic contrastive methods that learn point embeddings, it represents each modality as a distribution and learns uncertainty-aware cross-modal alignment. It uses mixing of audio-text pairs (rather than masking) to create overlapping sounds that reflect real acoustic mixtures and capture semantic inclusion relations, and introduces a multi-level inclusion loss to enforce consistency with these relations. The central claim is that this outperforms deterministic baselines on audio-text retrieval benchmarks.
Significance. If the results hold and are reproducible, the work could advance multimodal pretraining by offering a modeling choice (mixing-induced uncertainty) that more closely approximates real-world acoustic overlap and semantic inclusion than standard masking simulations. This has potential implications for applications requiring robust handling of ambiguous audio-text correspondences.
major comments (1)
- The manuscript consists solely of the abstract; no method derivations, loss function definitions, experimental setups, benchmark details, quantitative results, tables, figures, or error bars are provided. This prevents any assessment of whether the reported outperformance supports the central claim.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address the major comment below.
read point-by-point responses
-
Referee: The manuscript consists solely of the abstract; no method derivations, loss function definitions, experimental setups, benchmark details, quantitative results, tables, figures, or error bars are provided. This prevents any assessment of whether the reported outperformance supports the central claim.
Authors: We agree that the manuscript text provided consists solely of the abstract and lacks method derivations, loss function definitions (such as the multi-level inclusion loss), experimental setups, benchmark details, quantitative results, tables, figures, or error bars. This observation is accurate and prevents a full assessment of the claims. We will revise the manuscript to incorporate all of these elements in detail. revision: yes
- Specific definitions and derivations of the mixture-induced uncertainty modeling and multi-level inclusion loss, as well as the exact experimental setups, benchmarks, results, tables, figures, and error bars, since these are not present in the provided manuscript text.
Circularity Check
No significant circularity
full rationale
The provided abstract and description outline a probabilistic pretraining method with mixture-based uncertainty modeling and a multi-level inclusion loss. The central claim is empirical outperformance on audio-text retrieval benchmarks versus deterministic baselines. No equations, derivations, or self-citations are shown that reduce predictions to fitted inputs by construction, import uniqueness from prior self-work, or smuggle ansatzes. The mixing-vs-masking choice is presented as an explicit modeling decision whose validity is tested externally via benchmarks, making the framework self-contained against independent evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Acoustic environments often contain multiple overlapping sound events, and the same acoustic scene can be described using diverse textual expressions, making audio-text alignment inherently ambiguous.
Reference graph
Works this paper leans on
-
[1]
heavy rain
Introduction Humans naturally describe complex acoustic environments us- ing language. Learning to align audio signals with textual de- scriptions has therefore become an important problem in multi- modal representation learning. Recent progress in cross-modal learning has been driven by contrastive pretraining approaches that learn joint embeddings from ...
-
[2]
Probabilistic Representation Learning Most contrastive multi-modal learning frameworks represent each modality using deterministic point embeddings, which do not explicitly model uncertainty in cross-modal relationships. To address this limitation, probabilistic representations have been proposed. PCME [11] and PCME++ [12] model each in- put as a Gaussian...
Pith/arXiv arXiv 2026
-
[3]
A, and B
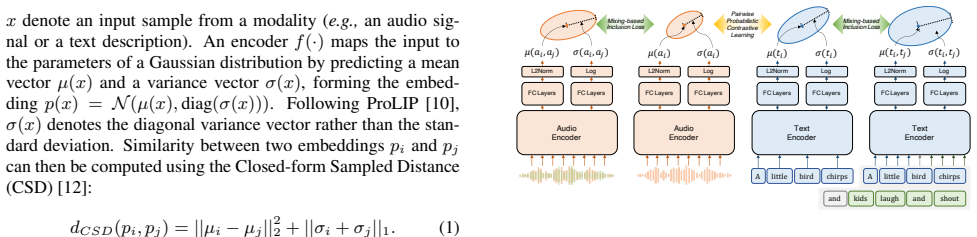
Proposed Method: MixProLAP In this section, we introduce MixProLAP, a probabilistic frame- work that models uncertainty through audio mixing. Our key contribution is replacing masking-based uncertainty with addi- tive uncertainty through waveform mixing, enabling more ap- propriate hierarchical structure learning for audio signals. An overview of the arch...
-
[4]
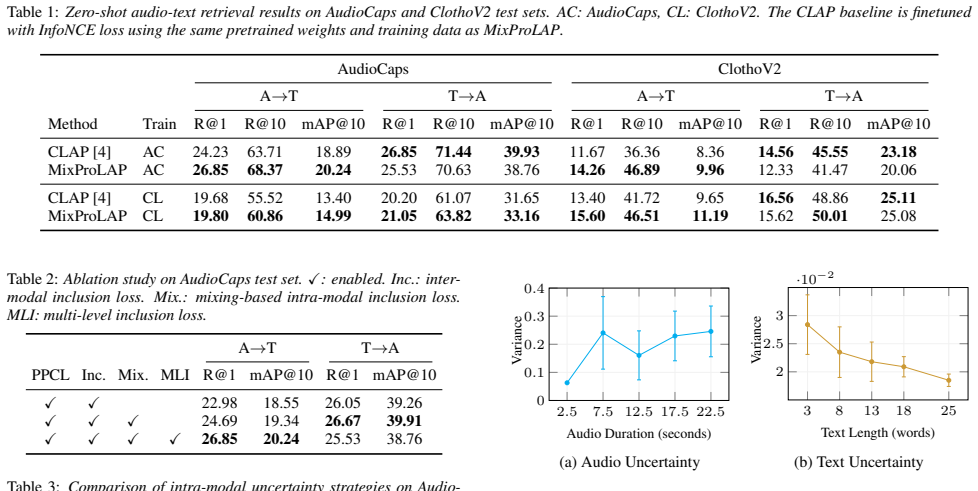
Experiments 4.1. Experimental Settings Dataset and metrics.We used AudioCaps [20] and ClothoV2 [21] datasets for both training and evaluation. Au- dioCaps consists of approximately 51k audio clips from Au- dioSet [22] with human written captions, while ClothoV2 con- tains nearly 6k audio samples with five captions each. All au- dio samples were processed ...
arXiv 1915
-
[5]
Conclusion We propose MixProLAP, a probabilistic audio-language pre- training framework that replaces masking-based uncertainty with additive uncertainty through audio mixing. Unlike mask- ing, which destroys semantic content for transient sounds or fails to create hierarchy for ambient sounds, mixing constructs a semantic superset that naturally satisfie...
-
[6]
The authors are solely re- sponsible for all scientific content, including the methodology, experiments, analysis, and conclusions
Generative AI Use Disclosure The use of generative AI in this paper was limited strictly to text refinement and clarity improvements. The authors are solely re- sponsible for all scientific content, including the methodology, experiments, analysis, and conclusions
-
[7]
Seeing voices and hearing faces: Cross-modal biometric matching,
A. Nagrani, S. Albanie, and A. Zisserman, “Seeing voices and hearing faces: Cross-modal biometric matching,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[8]
Perfect match: Improved cross-modal embeddings for audio-visual synchronisa- tion,
S.-W. Chung, J. S. Chung, and H.-G. Kang, “Perfect match: Improved cross-modal embeddings for audio-visual synchronisa- tion,” inProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2019
2019
-
[9]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agar- wal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” in Proceedings of the International Conference on Machine Learn- ing, 2021
2021
-
[10]
CLAP: learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “CLAP: learning audio concepts from natural language supervision,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2023
2023
-
[11]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdul- mohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa et al., “Siglip 2: Multilingual vision-language encoders with im- proved semantic understanding, localization, and dense features,” arXiv preprint arXiv:2502.14786, 2025
Pith/arXiv arXiv 2025
-
[12]
AudioCLIP: Ex- tending CLIP to image, text and audio,
A. Guzhov, F. Raue, J. Hees, and A. Dengel, “AudioCLIP: Ex- tending CLIP to image, text and audio,” inProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2022
2022
-
[13]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2023
2023
-
[14]
Natural language super- vision for general-purpose audio representations,
B. Elizalde, S. Deshmukh, and H. Wang, “Natural language super- vision for general-purpose audio representations,” inProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2024
2024
-
[15]
ProbVLM: Probabilistic adapter for frozen vison-language models,
U. Upadhyay, S. Karthik, M. Mancini, and Z. Akata, “ProbVLM: Probabilistic adapter for frozen vison-language models,” inPro- ceedings of the International Conference on Computer Vision, 2023
2023
-
[16]
Probabilistic language- image pre-training,
S. Chun, W. Kim, S. Park, and S. Yun, “Probabilistic language- image pre-training,” inProceedings of the International Confer- ence on Learning Representations, 2025
2025
-
[17]
Probabilistic embeddings for cross-modal retrieval,
S. Chun, S. J. Oh, R. S. De Rezende, Y . Kalantidis, and D. Lar- lus, “Probabilistic embeddings for cross-modal retrieval,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[18]
Improved probabilistic image-text representations,
S. Chun, “Improved probabilistic image-text representations,” in Proceedings of the International Conference on Learning Repre- sentations, 2024
2024
-
[19]
LongProLIP: A probabilistic vision- language model with long context text,
S. Chun and S. Yun, “LongProLIP: A probabilistic vision- language model with long context text,” inICLR Workshop on Quantify Uncertainty and Hallucination in Foundation Models, 2025
2025
-
[20]
Position: Multiplicity is an in- evitable and inherent challenge in multimodal learning,
S. Chun and O. Russakovsky, “Position: Multiplicity is an in- evitable and inherent challenge in multimodal learning,” inPro- ceedings of the International Conference on Machine Learning, 2026
2026
-
[21]
Pro- LAP: Probabilistic language-audio pre-training,
T. Manabe, Y . Ishikawa, H. Munakata, and T. Komatsu, “Pro- LAP: Probabilistic language-audio pre-training,”arXiv preprint arXiv:2510.18423, 2025
arXiv 2025
-
[22]
HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dub- nov, “HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,” inProceedings of the IEEE International Conference on Acoustics, Speech, and Signal Pro- cessing, 2022
2022
-
[23]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the International Conference on Computer Vision, 2021
2021
-
[24]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[25]
Deep varia- tional information bottleneck,
A. A. Alemi, I. Fischer, J. V . Dillon, and K. Murphy, “Deep varia- tional information bottleneck,” inProceedings of the International Conference on Learning Representations, 2017
2017
-
[26]
AudioCaps: Generat- ing captions for audios in the wild,
C. D. Kim, B. Kim, H. Lee, and G. Kim, “AudioCaps: Generat- ing captions for audios in the wild,” inProceedings of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, 2019
2019
-
[27]
Clotho: An audio cap- tioning dataset,
K. Drossos, S. Lipping, and T. Virtanen, “Clotho: An audio cap- tioning dataset,” inProceedings of the IEEE International Con- ference on Acoustics, Speech, and Signal Processing, 2020
2020
-
[28]
Audio Set: An ontology and human-labeled dataset for audio events,
J. F. Gemmeke, D. P. W. Ellis, D. Freedman, A. Jansen, W. Lawrence, R. C. Moore, M. Plakal, and M. Ritter, “Audio Set: An ontology and human-labeled dataset for audio events,” in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2017
2017
-
[29]
Estimated audio–caption correspondences improve language-based audio retrieval,
P. Primus, F. Schmid, and G. Widmer, “Estimated audio–caption correspondences improve language-based audio retrieval,” inPro- ceedings of the Detection and Classification of Acoustic Scenes and Events 2024 Workshop (DCASE2024), 2024
2024
-
[30]
Representation learning with contrastive predictive coding,
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
Pith/arXiv arXiv 2018
-
[31]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProceedings of the International Conference on Learning Representations, 2019
2019
-
[32]
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,” inINTERSPEECH, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.