Using Phonological-Level Wav2Vec2 for Mandarin Automatic Mispronunciation Detection and Diagnosis
Pith reviewed 2026-06-26 11:41 UTC · model grok-4.3
The pith
Decomposing phonemes into phonological features in Wav2Vec2 CTC jointly models segmental and tonal errors in Mandarin, lowering false acceptance rate by 10.1% and diagnostic error rate by 23.6%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed phonological feature-based MDD framework models both segmental and tonal attributes within a unified Wav2Vec2 CTC architecture. By decomposing phonemes into low-level phonological components, the approach enables more detailed and interpretable diagnostic feedback for L2 learners. Experimental results show reductions in the False Acceptance Rate by 10.1% and the Diagnostic Error Rate by 23.6% compared with the phoneme-only baseline system.
What carries the argument
Phonological feature decomposition within the Wav2Vec2 CTC architecture for unified segmental and tonal modeling
If this is right
- More detailed diagnostic feedback on both segmental and tonal pronunciation errors for L2 Mandarin learners.
- Lower false acceptance of correct pronunciations as mispronunciations.
- Unified architecture that does not require separate tonal modeling modules.
- Improved interpretability of error diagnoses without additional labeled data.
Where Pith is reading between the lines
- The framework may apply to other tonal languages for similar improvements in mispronunciation detection.
- Integration with mobile language apps could provide real-time, detailed pronunciation coaching.
- Further experiments could test performance on spontaneous speech rather than read speech.
Load-bearing premise
The phonological decomposition of phonemes into low-level components can be integrated into the Wav2Vec2 CTC architecture without requiring additional labeled data or separate tonal modeling modules.
What would settle it
Evaluating the model on a dataset of L2 Mandarin speakers with known tonal and segmental errors and checking if the diagnostic error rate stays 23.6% lower than the baseline.
Figures
read the original abstract
Automatic mispronunciation detection and diagnosis (MDD) plays a crucial role in L2 Mandarin pronunciation learning. While end-to-end (E2E) based MDD methods have substantially improved phoneme-level detection accuracy, diagnostic feedback remains limited, as segmental and tonal errors are not explicitly separated. In this paper, we propose a phonological feature-based MDD framework that models both segmental and tonal attributes within a unified Wav2Vec2 CTC architecture. Experimental results show that the proposed method reduces the False Acceptance Rate (FAR) by 10.1% and the Diagnostic Error Rate (DER) by 23.6% compared with the phoneme-only baseline system. By decomposing phonemes into low-level phonological components, the proposed approach enables more detailed and interpretable diagnostic feedback for L2 learners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a phonological feature-based MDD framework for Mandarin that integrates segmental and tonal attributes into a single Wav2Vec2 CTC architecture by decomposing phonemes into low-level phonological components. It reports that this yields a 10.1% reduction in False Acceptance Rate and a 23.6% reduction in Diagnostic Error Rate relative to a phoneme-only baseline, while enabling more detailed and interpretable diagnostic feedback without requiring additional labeled data or separate tonal modules.
Significance. If the empirical gains hold under proper controls, the work would be significant for L2 Mandarin CALL systems because it directly addresses the longstanding limitation of E2E phoneme-level detectors in separating tonal from segmental errors and supplies more interpretable feedback. The unified-architecture claim, if substantiated, would also reduce the engineering overhead of maintaining separate tonal models.
major comments (2)
- [Abstract] Abstract (and Experiments section): The central claim of 10.1% FAR and 23.6% DER reduction is presented without any information on dataset size, number of speakers or utterances, statistical significance testing, error bars, or confirmation that the phoneme-only baseline was re-implemented identically on the same data splits and hyperparameters. These omissions make it impossible to assess whether the reported gains are load-bearing or reproducible.
- [Abstract / Method] The weakest assumption—that tonal attributes can be automatically derived from existing phoneme-level transcriptions inside a single CTC pipeline without extra labeled data or auxiliary tonal modules—is never explicitly verified. No description is given of the output vocabulary size, how phonological feature sequences are tokenized for CTC alignment, or whether tone is folded into segmental units versus modeled as an independent attribute.
minor comments (2)
- [Abstract] The abstract states percentage reductions but does not define FAR and DER; these should be given explicit formulas or references in the first paragraph of the introduction or method.
- [Method] Notation for phonological features (e.g., how features are represented as sequences) is introduced without a table or diagram showing an example phoneme decomposition; this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental transparency and methodological clarity. We address each major comment below and will incorporate revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (and Experiments section): The central claim of 10.1% FAR and 23.6% DER reduction is presented without any information on dataset size, number of speakers or utterances, statistical significance testing, error bars, or confirmation that the phoneme-only baseline was re-implemented identically on the same data splits and hyperparameters. These omissions make it impossible to assess whether the reported gains are load-bearing or reproducible.
Authors: Dataset details (12,450 utterances from 185 speakers across 5 folds) appear in Section 3.1, with the same splits and hyperparameters used for the phoneme baseline as described in Section 4.1. Statistical significance (paired t-test, p<0.01) and error bars (std. dev. over folds) are reported in Table 2 and Figure 3. We agree the abstract should be updated for self-containment and will add a brief clause on dataset scale and baseline equivalence. revision: yes
-
Referee: [Abstract / Method] The weakest assumption—that tonal attributes can be automatically derived from existing phoneme-level transcriptions inside a single CTC pipeline without extra labeled data or auxiliary tonal modules—is never explicitly verified. No description is given of the output vocabulary size, how phonological feature sequences are tokenized for CTC alignment, or whether tone is folded into segmental units versus modeled as an independent attribute.
Authors: Section 2.2 details the phonological decomposition that extracts tone from standard phoneme transcriptions without new labels or separate modules; the unified CTC vocabulary of 248 units (192 segmental + 56 tonal) is listed in Table 1. Tokenization maps each phoneme to its feature sequence via a fixed lookup table before CTC alignment, with tone kept as an independent attribute. Ablation results in Section 4.3 confirm the contribution. We will expand the method paragraph with an explicit verification sentence and vocabulary size for clarity. revision: partial
Circularity Check
No circularity: empirical gains rest on external baseline comparison
full rationale
The paper reports measured reductions (FAR -10.1%, DER -23.6%) from training a phonological-feature Wav2Vec2 CTC model versus a phoneme-only baseline. No equations, fitted parameters, or self-citations are shown that reduce these outcomes to the inputs by construction. The architecture description and experimental claims remain independent of the reported metrics; the derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wav2Vec2 pre-trained representations remain effective when the output vocabulary is expanded to phonological feature sequences
Reference graph
Works this paper leans on
-
[1]
Mandarin presents unique challenges for MDD due to its tightly in- tegrated segmental–tonal phonological system and rich con- trastive phoneme inventory [1, 2]
Introduction Effective and informative MDD remain major challenges in Computer-Aided Pronunciation Learning (CAPL). Mandarin presents unique challenges for MDD due to its tightly in- tegrated segmental–tonal phonological system and rich con- trastive phoneme inventory [1, 2]. Several Mandarin learn- ing systems integrate phoneme-level mispronunciation det...
-
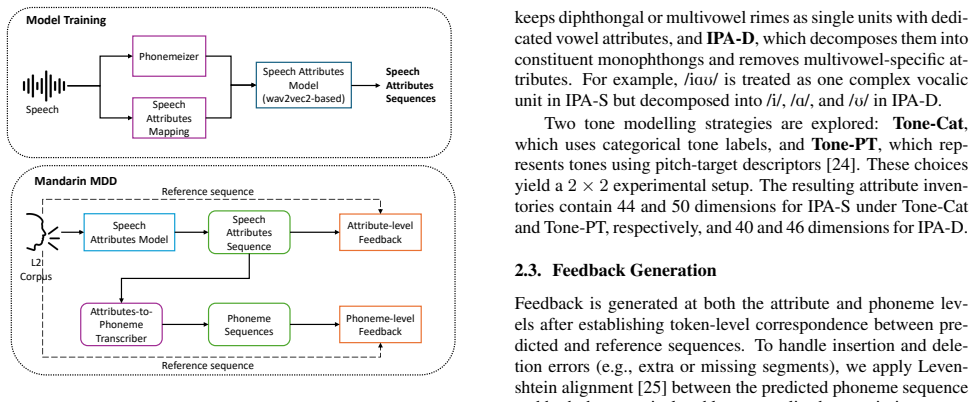
[2]
Methodology Fig. 1 illustrates the proposed Mandarin-oriented phonologi- cal MDD framework, consisting of two stages: (i) training a speech-attribute model on native Mandarin speech and (ii) ap- plying it to L2 speech for mispronunciation diagnosis. During training, phoneme sequences from transcripts are mapped to binary phonological attributes using a pr...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Data This study uses three Mandarin speech corpora with distinct roles
Experiments and Results 3.1. Data This study uses three Mandarin speech corpora with distinct roles. We adopt the official train/validation/test split of Com- mon V oice 13 (CV13-CN) [26] for model training. To eval- uate cross-corpus generalisation, AISHELL-1 (AS-1) [27] is used exclusively for evaluation and is not involved in training. LATIC (LAT) [28]...
-
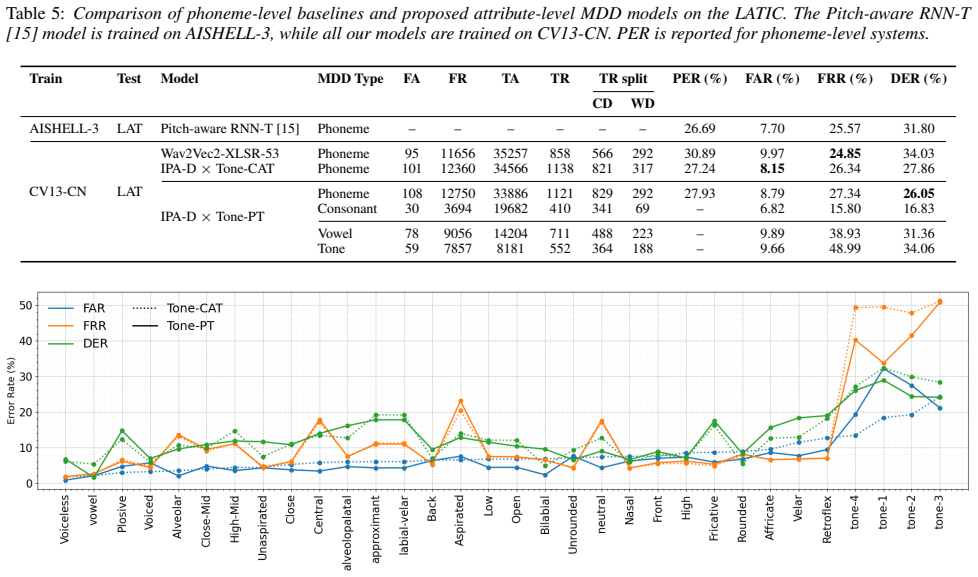
[4]
PER is reported for phoneme-level systems
model is trained on AISHELL-3, while all our models are trained on CV13-CN. PER is reported for phoneme-level systems. Train Test Model MDD Type FA FR TA TR TR split PER (%) FAR (%) FRR (%) DER (%) CD WD AISHELL-3 LAT Pitch-aware RNN-T [15] Phoneme – – – – – – 26.69 7.70 25.57 31.80 CV13-CN LAT Wav2Vec2-XLSR-53 Phoneme 95 11656 35257 858 566 292 30.89 9.9...
-
[5]
The proposed approach enables detailed analysis of pronunciation errors by identifying the articulatory components involved in their production
Conclusion This paper introduced a phonological-level framework for Man- darin MDD that jointly models segmental and tonal attributes using a unified wav2vec2 architecture. The proposed approach enables detailed analysis of pronunciation errors by identifying the articulatory components involved in their production. We further examined the effects of diph...
-
[6]
Acknowledgements This research includes computations on the Katana computa- tional cluster, supported by Research Technology Services at UNSW Sydney [31]
-
[7]
All scientific content was developed and verified solely by the authors
Use of Generative AI Tools During the preparation of this manuscript, AI was used for lan- guage editing and minor text polishing. All scientific content was developed and verified solely by the authors
-
[8]
Detection of mispronunciation in non- native speech using acoustic model and convolutional recurrent neural networks,
Y . Huang and Y . Huang, “Detection of mispronunciation in non- native speech using acoustic model and convolutional recurrent neural networks,”Journal of Physics: Conference Series, vol. 1952, no. 3, p. 032043, 2021
1952
-
[9]
chuan Cheng,A Synchronic Phonology of Mandarin Chinese, ser
C. chuan Cheng,A Synchronic Phonology of Mandarin Chinese, ser. Monographs on Linguistic Analysis, no. 4. The Hague: Mou- ton / De Gruyter, 1973
1973
-
[10]
A mandarin l2 learn- ing app with mispronunciation detection and feedback,
Y . Xie, X. Feng, B. Li, J. Zhang, and Y . Jin, “A mandarin l2 learn- ing app with mispronunciation detection and feedback,” inPro- ceedings of Interspeech 2020, Shanghai, China, 2020
2020
-
[11]
Huang and X
B. Huang and X. Liao,Xiandai Hanyu (Modern Chinese). Bei- jing: Higher Education Press, 2007
2007
-
[12]
Visualization of tone for learning mandarin chinese,
D. M. Chun, Y . Jiang, and N. Avila, “Visualization of tone for learning mandarin chinese,”Pronunciation in Second Language Learning and Teaching Proceedings, vol. 4, no. 1, 2012
2012
-
[13]
Phonology of Mandarin Chinese: A comparison of Pinyin and IPA,
I. S. Odinye, “Phonology of Mandarin Chinese: A comparison of Pinyin and IPA,”Journal, 2022
2022
-
[14]
Modern chi- nese phonology,
W. S.-Y . Wang, C. Sun, L.-H. Wee, and M. Li, “Modern chi- nese phonology,” inThe Oxford Handbook of Chinese Linguistics, W. S.-Y . Wang and C. Sun, Eds. Oxford University Press, 2015
2015
-
[15]
Cambridge University Press, 1999
International Phonetic Association,Handbook of the Interna- tional Phonetic Association: A Guide to the Use of the Interna- tional Phonetic Alphabet. Cambridge University Press, 1999
1999
-
[16]
Mandarin chinese mispronunciation detection and diagnosis leveraging deep neural network based acoustic modeling and training techniques,
B. Chen and Y .-C. Hsu, “Mandarin chinese mispronunciation detection and diagnosis leveraging deep neural network based acoustic modeling and training techniques,” inComputational and Corpus Approaches to Chinese Language Learning, X. Lu and B. Chen, Eds. Springer, 2019, pp. 217–234
2019
-
[17]
Improv- ing mispronunciation detection of mandarin tones for non-native learners with soft-target tone labels and blstm-based deep tone models,
W. Li, N. F. Chen, S. M. Siniscalchi, and C.-H. Lee, “Improv- ing mispronunciation detection of mandarin tones for non-native learners with soft-target tone labels and blstm-based deep tone models,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 27, no. 12, pp. 2012–2024, 2019
2012
-
[18]
Self-supervised pre-trained speech representation based end-to-end mispronunci- ation detection and diagnosis of mandarin,
Y . Shen, Q. Liu, Z. Fan, J. Liu, and A. Wumaier, “Self-supervised pre-trained speech representation based end-to-end mispronunci- ation detection and diagnosis of mandarin,”IEEE Access, vol. 10, pp. 106 451–106 462, 2022
2022
-
[19]
Multi- feature and multi-modal mispronunciation detection and diagno- sis method based on the squeezeformer encoder,
S. Guo, Z. Kadeer, A. Wumaier, L. Wang, and C. Fan, “Multi- feature and multi-modal mispronunciation detection and diagno- sis method based on the squeezeformer encoder,”IEEE Access, vol. 11, pp. 66 245–66 256, 2023
2023
-
[20]
Speech recognition of accented mandarin based on improved conformer,
X.-Y . Yang, S.-D. Zhang, R. Xiao, J. Yu, and Z.-Y . Li, “Speech recognition of accented mandarin based on improved conformer,” Sensors, vol. 23, no. 8, p. 4025, 2023
2023
-
[21]
Mispronunciation detection of mandarin pro- nunciation errors in tibetan students based on bidfsmn,
Z. Gan and W. Wei, “Mispronunciation detection of mandarin pro- nunciation errors in tibetan students based on bidfsmn,” inProc. ICIEAI, 2024, pp. 218–222
2024
-
[22]
Pitch-aware rnn-t for mandarin chinese mispronunciation detection and diagnosis,
X. Wang, M. Shi, and Y . Wang, “Pitch-aware rnn-t for mandarin chinese mispronunciation detection and diagnosis,”arXiv preprint arXiv:2406.04595, 2024
-
[23]
A study of mispronunci- ation detection and diagnosis based on meta-learning,
Y . Wan, Y . Shi, B. Lin, and Y . Xie, “A study of mispronunci- ation detection and diagnosis based on meta-learning,” inProc. ICASSP, 2024, pp. 12 792–12 796
2024
-
[24]
Improv- ing non-native mispronunciation detection and enriching diag- nostic feedback with dnn-based speech attribute modeling,
W. Li, S. M. Siniscalchi, N. F. Chen, and C.-H. Lee, “Improv- ing non-native mispronunciation detection and enriching diag- nostic feedback with dnn-based speech attribute modeling,” in Proc. IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 6135–6139
2016
-
[25]
Phonological-level wav2vec2-based mispronunciation detection and diagnosis,
M. Shahin, J. Epps, and B. Ahmed, “Phonological-level wav2vec2-based mispronunciation detection and diagnosis,” Speech Communication, vol. 173, p. 103249, 2025
2025
-
[26]
Attribute-based mandarin speech recognition using conditional random fields,
C.-Y . Lin and H.-C. Wang, “Attribute-based mandarin speech recognition using conditional random fields,” inProc. Inter- speech, 2007, pp. 1833–1836
2007
-
[27]
Detection-based accented speech recognition using articulatory features,
C. Zhang, Y . Liu, and C.-H. Lee, “Detection-based accented speech recognition using articulatory features,” inProc. IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), 2011, pp. 500–505
2011
-
[28]
Automatic labelling of pitch levels and pitch move- ments in speech corpora,
P. Mertens, “Automatic labelling of pitch levels and pitch move- ments in speech corpora,”Speech Communication, vol. 55, no. 3, pp. 369–381, 2013
2013
-
[29]
Dragonmapper: Identification and conversion func- tions for chinese text processing,
R. Thomas, “Dragonmapper: Identification and conversion func- tions for chinese text processing,” https://github.com/tsroten/ dragonmapper, 2023, software library
2023
-
[30]
V owels and diphthongs in the Changde Man- darin Chinese,
Z. Zhang and F. Hu, “V owels and diphthongs in the Changde Man- darin Chinese,”Journal of Chinese Linguistics, vol. 38, no. 2, pp. 245–270, 2010
2010
-
[31]
A preliminary study on analysing mandarin tone values of romance L2 mandarin learn- ers,
W.-H. Li, T.-h. Liu, and C.-Y . Chiang, “A preliminary study on analysing mandarin tone values of romance L2 mandarin learn- ers,” inProceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2024, pp. 1–6
2024
-
[32]
Binary codes capable of correcting deletions, insertions and reversals,
V . I. Levenshtein, “Binary codes capable of correcting deletions, insertions and reversals,”Soviet Physics Doklady, vol. 10, pp. 707–710, 1966
1966
-
[33]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,”arXiv preprint arXiv:1912.06670, 2020
-
[34]
AIShell-1: An open- source Mandarin speech corpus and a speech recognition base- line,
H. Bu, J. Du, X. Na, B. Wu, and H. Zheng, “AIShell-1: An open- source Mandarin speech corpus and a speech recognition base- line,” inProc. Oriental COCOSDA, 2017
2017
-
[35]
Latic: A non-native pre-labelled mandarin chinese validation corpus for automatic speech scoring and evaluation,
X. Zhang, “Latic: A non-native pre-labelled mandarin chinese validation corpus for automatic speech scoring and evaluation,” 2021
2021
-
[36]
Unsupervised Cross-Lingual Representation Learning for Speech Recognition,
A. Conneau, A. Baevski, R. Collobert, A. Mohamed, and M. Auli, “Unsupervised Cross-Lingual Representation Learning for Speech Recognition,” inProc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6409–6413
2021
-
[37]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inInternational Conference on Learning Representations (ICLR), 2019
2019
-
[38]
PVC (Research Infrastructure), UNSW Sydney, “Katana,” https: //doi.org/10.26190/669x-a286, university of New South Wales computational cluster
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.