CAAD: Contrastive Audio-Aware Distillation for Efficient Speech Language Models
Pith reviewed 2026-06-26 07:26 UTC · model grok-4.3
The pith
CAAD distills a teacher's contrastive audio-aware reasoning into student speech language model weights via synchronized teacher-forcing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By anchoring distillation on unified Pseudo-Ground Truths and applying synchronized teacher-forcing, CAAD enables simultaneous full-sequence generation of the teacher's contrastive distributions, allowing the student to absorb the audio-aware signal efficiently and embed it in its weights without token-by-token dual-path overhead.
What carries the argument
Synchronized teacher-forcing strategy anchored by unified Pseudo-Ground Truths that enables simultaneous full-sequence generation of the teacher's contrastive distributions.
If this is right
- CAAD yields an approximately 8 percent relative gain over standard knowledge distillation on Dynamic-SUPERB.
- CAAD reduces linguistic bias as measured on MCR-BENCH.
- The method removes the inference latency increase that accompanies contrastive decoding at runtime.
- Smaller speech language models acquire improved audio grounding through weight-internalized contrastive reasoning.
Where Pith is reading between the lines
- The approach may support deployment of audio-grounded speech models on devices with limited compute.
- Analogous synchronized distillation could be tested on other contrastive reasoning techniques in language models.
- Additional benchmarks that isolate acoustic versus linguistic conflicts would provide further checks on bias reduction.
Load-bearing premise
The synchronized teacher-forcing strategy with unified Pseudo-Ground Truths transfers the teacher's full-sequence contrastive distributions to the student without material loss of the audio-aware signal.
What would settle it
A controlled comparison in which a CAAD-trained student shows no measurable reduction in linguistic bias on MCR-BENCH and no accuracy lift on Dynamic-SUPERB relative to standard knowledge distillation would falsify the central claim.
Figures
read the original abstract
Speech Language Models achieve reasoning capabilities, but are often hindered by massive parameter counts and a tendency to prioritize linguistic priors over acoustic features. While contrastive decoding enhances grounding by contrasting audio-aware and text-only logits, it increases inference latency. We propose Contrastive Audio-Aware Distillation (CAAD), a framework that internalizes the teacher's contrastive reasoning into the student model's weights. To overcome the high computational training overhead in the dual-path token-by-token contrastive distillation process, we introduce a synchronized teacher-forcing strategy. Anchored by unified Pseudo-Ground Truths, this mechanism enables simultaneous full-sequence generation of the teacher's contrastive distributions, allowing student to distill the audio-aware signal efficiently. Overall, CAAD yields a ~8% relative gain over standard knowledge distillation on Dynamic-SUPERB and successfully reduces linguistic bias in MCR-BENCH.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Contrastive Audio-Aware Distillation (CAAD) to internalize a teacher's contrastive reasoning (audio-aware vs. text-only logits) into smaller speech language models. It introduces a synchronized teacher-forcing strategy anchored by unified Pseudo-Ground Truths to enable efficient full-sequence distillation of the teacher's contrastive distributions, avoiding token-by-token overhead. The central claims are an ~8% relative gain over standard knowledge distillation on Dynamic-SUPERB and reduced linguistic bias on MCR-BENCH.
Significance. If the method successfully transfers the per-token audio-aware contrastive signal without material loss, the work could enable more efficient SLMs that better prioritize acoustic features over linguistic priors while avoiding inference-time latency from contrastive decoding. The approach targets two practical bottlenecks (model size and bias) with a training-time distillation technique.
major comments (1)
- [Method] Method section (synchronized teacher-forcing with unified Pseudo-Ground Truths): Unifying ground truths across the full sequence to generate the teacher's contrastive distributions risks collapsing token-specific differences between audio-aware and text-only logits into an averaged target. If this occurs, the student may not internalize the teacher's per-step contrastive reasoning, undermining the claim that the ~8% gain and bias reduction stem from successful audio-aware distillation rather than generic effects or extra compute. The manuscript should include an ablation or analysis (e.g., per-token KL divergence between teacher contrastive distributions and the unified targets) demonstrating preservation of the signal.
minor comments (1)
- [Abstract] Abstract: 'student to distill' should read 'the student to distill'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Method] Method section (synchronized teacher-forcing with unified Pseudo-Ground Truths): Unifying ground truths across the full sequence to generate the teacher's contrastive distributions risks collapsing token-specific differences between audio-aware and text-only logits into an averaged target. If this occurs, the student may not internalize the teacher's per-step contrastive reasoning, undermining the claim that the ~8% gain and bias reduction stem from successful audio-aware distillation rather than generic effects or extra compute. The manuscript should include an ablation or analysis (e.g., per-token KL divergence between teacher contrastive distributions and the unified targets) demonstrating preservation of the signal.
Authors: We appreciate the referee's careful analysis of the synchronized teacher-forcing mechanism. The unified Pseudo-Ground Truths are constructed to align the dual forward passes (audio-aware and text-only) at the sequence level for computational efficiency, but the teacher's contrastive distributions are computed from per-token logit differences prior to unification; the resulting target distributions therefore retain token-specific contrastive information rather than averaging it away. Our controlled experiments already isolate the contribution of this audio-aware signal by comparing against standard knowledge distillation (which uses identical compute but lacks the contrastive component), showing consistent gains on Dynamic-SUPERB and bias reduction on MCR-BENCH. To directly address the concern, we will add in the revised manuscript a quantitative analysis of per-token KL divergence between the original teacher contrastive distributions and the unified targets, confirming signal preservation. revision: yes
Circularity Check
No circularity: empirical gains presented without self-referential derivations or fitted predictions.
full rationale
The manuscript introduces CAAD as a distillation method using synchronized teacher-forcing and unified Pseudo-Ground Truths to transfer contrastive distributions. No equations, parameter-fitting steps, or self-citations are shown that would make the reported ~8% gain on Dynamic-SUPERB or bias reduction on MCR-BENCH equivalent to the inputs by construction. The performance claims are framed as experimental outcomes rather than tautological predictions or renamed known results. The derivation chain is self-contained against external benchmarks with no load-bearing circular steps identified.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
However, the massive parameter count of these foundation models poses significant challenges for low la- tency [10]
Introduction The convergence of large-scale linguistic and acoustic model- ing has catalyzed the development of Speech Language Mod- els (SLMs) [1–10], capable of instruction following and cross- modal reasoning. However, the massive parameter count of these foundation models poses significant challenges for low la- tency [10]. Consequently, some research...
-
[2]
andMCR-BENCH[17], CAAD effectively mitigates linguistic bias. The student model consistently outperforms standard knowledge distillationandcontrastive decoding in test time, while surpassing the greedy decode performance of teacher model in paralinguistic tasks
-
[3]
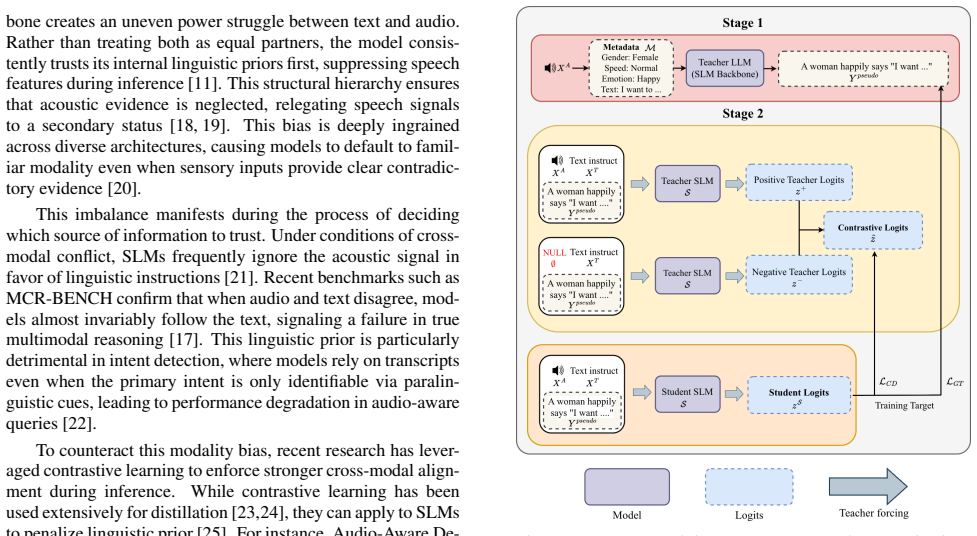
Related Work 2.1. Modality Bias in Speech Language Models A critical bottleneck in Speech Language Models (SLMs) is modality bias, where the model’s powerful linguistic back- 1https://github.com/ChenWils/Contrastive Audio- Aware Distillation.git arXiv:2606.23052v1 [eess.AS] 22 Jun 2026 bone creates an uneven power struggle between text and audio. Rather t...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Methodology A fundamental challenge in distilling multimodal contrastive decoding is the expensive computational overhead of generat- ing dual-path targets autoregressively. Since standard teacher forcing relies on a single shared sequence to accelerate training via full-sequence parallelization, simultaneously computing a teacher’s positive (audio-aware)...
-
[5]
Experiment 4.1. Training Dataset To ensure distillation and robust acoustic generalization, we utilize expressive speech instruction-following dataset estab- lished by the DeSTA2, which consolidates diverse benchmarks including AccentDB [26], DailyTalk [27], IEMOCAP [28], PromptTTS [29], VCTK [30], and V oxCeleb [31]. Beyond the original labels, the corpu...
-
[6]
We propose an optimal hyperparameter config- uration for this approach; and (3)Standard KD (Std
Results To evaluate the impact of our distillation framework, we com- pare our CAAD method against different baselines: (1)Greedy Decoding, representing the model’s vanilla baseline where the model selects the token with the highest probability at each step; (2) Contrastive Decoding (CD), a test-time method that ampli- fies acoustic signals by subtracting...
-
[7]
Conclusion In this work, we presentedContrastive Audio-Aware Distil- lation (CAAD), distillation framework designed to compress Speech Language Models while mitigating linguistic priors. Through the synchronized teacher-forcing strategy anchored by metadata-driven pseudo-ground truths, CAAD effectively bridges the performance gap between student and teach...
-
[8]
When employing a highly optimized student architecture, such as Qwen2.5-Omni 3B as a student model, the potential for further gain through distillation may be marginal
Limitations The efficacy of knowledge distillation often depends on the per- formance gap between the teacher and student models. When employing a highly optimized student architecture, such as Qwen2.5-Omni 3B as a student model, the potential for further gain through distillation may be marginal. Consequently, as our proposed method relies on distillatio...
-
[9]
The authors would like to express their sincere grati- tude to the MOE for its financial assistance, which greatly facil- itated this research
Acknowledgement This work was supported in part by the Ministry of Education (MOE), Taiwan, through the NTU Artificial Intelligence Center of Research Excellence (NTU AI-CoRE) under the framework of the Taiwan Centers of Excellence in Artificial Intelligence project. The authors would like to express their sincere grati- tude to the MOE for its financial ...
-
[10]
Generative AI tools are employed solely for linguistic refinement and polishing of the manuscript
Generative AI Use Disclosure The authors maintain full responsibility for the research design, experimental execution, data analysis, and the final reported re- sults. Generative AI tools are employed solely for linguistic refinement and polishing of the manuscript. These AI tools do not contribute to the substantive scientific content or intellectual fra...
-
[11]
Desta: Enhancing speech language models through descriptive speech-text alignment,
K.-H. Lu, Z. Chen, S.-W. Fu, H. Huang, B. Ginsburg, Y .-C. F. Wang, and H.-y. Lee, “Desta: Enhancing speech language models through descriptive speech-text alignment,” inProc. Interspeech 2024, 2024, pp. 4159–4163
2024
-
[12]
K.-H. Lu, Z. Chen, S.-W. Fu, C.-H. H. Yang, S.-F. Huang, C.- K. Yang, C.-E. Yu, C.-W. Chen, W.-C. Chen, C.-y. Huanget al., “Desta2. 5-audio: Toward general-purpose large audio language model with self-generated cross-modal alignment,”arXiv preprint arXiv:2507.02768, 2025
-
[13]
Developing instruction- following speech language model without speech instruction- tuning data,
K.-H. Lu, Z. Chen, S.-W. Fu, C.-H. H. Yang, J. Balam, B. Gins- burg, Y .-C. F. Wang, and H.-y. Lee, “Developing instruction- following speech language model without speech instruction- tuning data,” inICASSP 2025-2025 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[14]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “Salmonn: Towards generic hearing abilities for large language models,”arXiv preprint arXiv:2310.13289, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,
D. Zhang, S. Li, X. Zhang, J. Zhan, P. Wang, Y . Zhou, and X. Qiu, “Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities,” inFindings of the Associ- ation for Computational Linguistics: EMNLP 2023, 2023, pp. 15 757–15 773
2023
-
[18]
On The Landscape of Spoken Language Models: A Comprehensive Survey
S. Arora, K.-W. Chang, C.-M. Chien, Y . Peng, H. Wu, Y . Adi, E. Dupoux, H.-Y . Lee, K. Livescu, and S. Watanabe, “On the landscape of spoken language models: A comprehensive survey,” arXiv preprint arXiv:2504.08528, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Building a taiwanese mandarin spoken language model: A first attempt,
C.-K. Yang, Y .-K. Fu, C.-A. Li, Y .-C. Lin, Y .-X. Lin, W.-C. Chen, H. L. Chung, C.-Y . Kuan, W.-P. Huang, K.-H. Luet al., “Building a taiwanese mandarin spoken language model: A first attempt,” arXiv preprint arXiv:2411.07111, 2024
-
[20]
Recent advances in speech language models: A sur- vey,
W. Cui, D. Yu, X. Jiao, Z. Meng, G. Zhang, Q. Wang, S. Y . Guo, and I. King, “Recent advances in speech language models: A sur- vey,” inProceedings of the 63rd Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 13 943–13 970
2025
-
[21]
When language over- rules: Revealing text dominance in multimodal large language models,
H. Wu, M. Tang, X. Zheng, and H. Jiang, “When language over- rules: Revealing text dominance in multimodal large language models,”arXiv preprint arXiv:2508.10552, 2025
-
[22]
Efficient interleaved speech modeling through knowledge distillation,
M. Nouriborji and M. Rohanian, “Efficient interleaved speech modeling through knowledge distillation,”arXiv preprint arXiv:2506.23670, 2025
-
[23]
Reducing ob- ject hallucination in large audio-language models via audio-aware decoding,
T.-w. Hsu, K.-H. Lu, C.-H. Chiang, and H.-y. Lee, “Reducing ob- ject hallucination in large audio-language models via audio-aware decoding,”arXiv preprint arXiv:2506.07233, 2025
-
[24]
On-policy distillation of language models: Learning from self-generated mistakes,
R. Agarwal, N. Vieillard, Y . Zhou, P. Stanczyk, S. R. Garea, M. Geist, and O. Bachem, “On-policy distillation of language models: Learning from self-generated mistakes,” inThe twelfth international conference on learning representations, 2024
2024
-
[25]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
S. Zhao, Z. Xie, M. Liu, J. Huang, G. Pang, F. Chen, and A. Grover, “Self-distilled reasoner: On-policy self-distillation for large language models,”arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Dynamic- superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,
C.-y. Huang, K.-H. Lu, S.-H. Wang, C.-Y . Hsiao, C.-Y . Kuan, H. Wu, S. Arora, K.-W. Chang, J. Shi, Y . Penget al., “Dynamic- superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 136–12 140
2024
-
[27]
When au- dio and text disagree: Revealing text bias in large audio-language models,
C. Wang, G. Deng, X. Yang, H. Qiu, and T. Zhang, “When au- dio and text disagree: Revealing text bias in large audio-language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 4878–4888
2025
-
[28]
C.-Y . Kuan, W.-P. Huang, and H.-y. Lee, “Understanding sounds, missing the questions: The challenge of object hallucination in large audio-language models,”arXiv preprint arXiv:2406.08402, 2024
-
[29]
arXiv preprint arXiv:2410.12787 , year=
S. Leng, Y . Xing, Z. Cheng, Y . Zhou, H. Zhang, X. Li, D. Zhao, S. Lu, C. Miao, and L. Bing, “The curse of multi-modalities: Eval- uating hallucinations of large multimodal models across language, visual, and audio,”arXiv preprint arXiv:2410.12787, 2024
-
[30]
Mllms are deeply affected by modality bias,
X. Zheng, C. Liao, Y . Fu, K. Lei, Y . Lyu, L. Jiang, B. Ren, J. Chen, J. Wang, C. Liet al., “Mllms are deeply affected by modality bias,”arXiv preprint arXiv:2505.18657, 2025
-
[31]
When audio-llms don’t listen: A cross-linguistic study of modality arbitration,
J. Billa, “When audio-llms don’t listen: A cross-linguistic study of modality arbitration,”arXiv preprint arXiv:2602.11488, 2026
-
[32]
Text takes over: A study of modality bias in multimodal intent detection,
A. Mullick, S. Sharma, A. Jana, and P. Goyal, “Text takes over: A study of modality bias in multimodal intent detection,” inPro- ceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 24 039–24 069
2025
-
[33]
Colld: Contrastive layer-to-layer distillation for compressing multilingual pre-trained speech encoders,
H.-J. Chang, N. Dong, R. Mavlyutov, S. Popuri, and Y .-A. Chung, “Colld: Contrastive layer-to-layer distillation for compressing multilingual pre-trained speech encoders,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 10 801–10 805
2024
-
[34]
Ckd: Con- trastive knowledge distillation from a sample-wise perspective,
W. Zhu, X. Zhou, P. Zhu, Y . Wang, and Q. Hu, “Ckd: Con- trastive knowledge distillation from a sample-wise perspective,” IEEE Transactions on Image Processing, 2025
2025
-
[35]
How contrastive decoding enhances large audio language models?
T.-Q. Lin, W.-P. Huang, Y .-C. Lin, and H. yi Lee, “How contrastive decoding enhances large audio language models?”
-
[36]
Available: https://arxiv.org/abs/2603.09232
[Online]. Available: https://arxiv.org/abs/2603.09232
-
[37]
Accentdb: A database of non-native english accents to assist neural speech recognition,
A. Ahamad, A. Anand, and P. Bhargava, “Accentdb: A database of non-native english accents to assist neural speech recognition,” inProceedings of the Twelfth Language Resources and Evaluation Conference, 2020, pp. 5351–5358
2020
-
[38]
Dailytalk: Spoken dialogue dataset for conversational text-to-speech,
K. Lee, K. Park, and D. Kim, “Dailytalk: Spoken dialogue dataset for conversational text-to-speech,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[39]
Iemocap: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database,”Language resources and evaluation, vol. 42, no. 4, pp. 335–359, 2008
2008
-
[40]
Prompttts: Control- lable text-to-speech with text descriptions,
Z. Guo, Y . Leng, Y . Wu, S. Zhao, and X. Tan, “Prompttts: Control- lable text-to-speech with text descriptions,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[41]
Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (ver- sion 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (ver- sion 0.92),” 2019
2019
-
[42]
V oxceleb: A large- scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: A large- scale speaker identification dataset,” inInterspeech 2017, 2017, pp. 2616–2620
2017
-
[43]
emotion2vec: Self-supervised pre-training for speech emotion representation,
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion representation,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 15 747–15 760
2024
-
[44]
Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and c50 room acoustics estimation,
M. Lavechin, M. M ´etais, H. Titeux, A. Boissonnet, J. Copet, M. Rivi`ere, E. Bergelson, A. Cristia, E. Dupoux, and H. Bredin, “Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and c50 room acoustics estimation,” in2023 IEEE Automatic Speech Recognition and Understanding Work- shop (ASRU). IEEE, 2023, pp. 1–7
2023
-
[45]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,” inProceedings of the 57th annual meeting of the association for computational linguistics, 2019, pp. 527–536
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.