A Fusion-Aware Two-Stage Framework for Mispronunciation Detection and Diagnosis in Low-Resource Modern Standard Arabic
Pith reviewed 2026-06-25 23:14 UTC · model grok-4.3
The pith
A two-stage framework learns general phonetic mappings from synthetic Arabic data then adapts them to scarce real learner recordings, reaching 0.7201 F1-score on QuranMB.v2.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a hierarchical two-stage end-to-end framework, which first learns general mappings from native and synthetic corpora and then adapts them to scarce real learner data, combined with a pre-trained encoder, causal dilated temporal convolutional networks, and multi-checkpoint ensemble inference with N-gram rescoring, produces an F1-score of 0.7201 on the QuranMB.v2 test set and thereby sets a new state-of-the-art for low-resource MSA mispronunciation detection and diagnosis.
What carries the argument
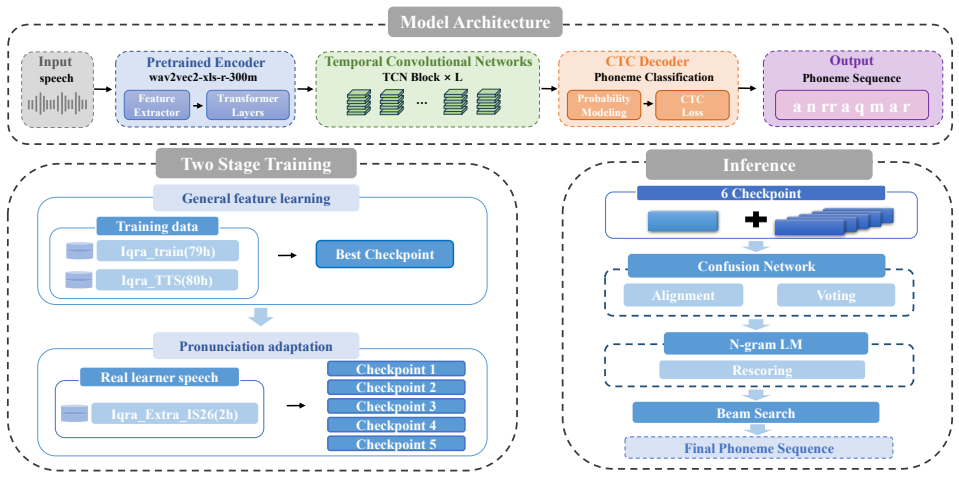
The fusion-aware two-stage framework: a pre-trained encoder paired with causal dilated temporal convolutional networks, followed by hierarchical adaptation from synthetic to real data and multi-checkpoint ensemble rescoring.
If this is right
- The same two-stage schedule reduces domain shift in other low-resource speech tasks that mix synthetic and real recordings.
- Ensemble inference with N-gram rescoring raises prediction stability once the two-stage training has produced candidate checkpoints.
- Causal dilated temporal convolutional networks preserve the fine-grained phonetic timing needed for phoneme-level diagnosis.
- The approach yields a concrete ranking at the top of the IqraEval.2 Challenge leaderboard.
Where Pith is reading between the lines
- The same staged training pattern could be tested on other morphologically rich low-resource languages that also suffer from synthetic-to-real gaps.
- If the first-stage synthetic corpus were enlarged, the second-stage adaptation might require even less real learner data while preserving the same F1 gain.
- The reported F1 improvement could be re-measured on a held-out dialectal Arabic set to check whether the MSA-specific adaptation generalizes.
Load-bearing premise
The second-stage adaptation on scarce real learner data can refine the first-stage mappings without introducing over-correction.
What would settle it
Running the identical QuranMB.v2 test set through the released model and obtaining an F1-score no higher than the reported baseline of 0.4414 would falsify the performance claim.
Figures
read the original abstract
Accurate phoneme recognition is pivotal for mispronunciation detection and diagnosis (MDD) in modern standard Arabic (MSA), yet remains constrained by data scarcity and the synthetic-real domain gap. This work proposes a two-stage end-to-end framework. It integrates a pre-trained encoder with causal dilated temporal convolutional networks to preserve fine-grained phonetic variations. A hierarchical two-stage strategy first learns general mappings from native/synthetic corpora, then adapts to scarce real learner data to mitigate domain shift without over-correction. Prediction stability is further enhanced via multi-checkpoint ensemble inference with N-gram rescoring. Evaluated on the QuranMB.v2 test set, our system achieves an F1-score of $0.7201$, a $63.1$\% relative improvement over baseline ($0.4414$). This performance ranks at the top of the IqraEval.2 Challenge, establishing a new state-of-the-art for low-resource MSA in MDD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a fusion-aware two-stage framework for mispronunciation detection and diagnosis (MDD) in low-resource Modern Standard Arabic (MSA). It integrates a pre-trained encoder with causal dilated temporal convolutional networks (TCNs) to preserve phonetic variations. A hierarchical strategy pre-trains on native/synthetic corpora then adapts to scarce real learner data to mitigate domain shift. Multi-checkpoint ensemble inference with N-gram rescoring is added for stability. On the QuranMB.v2 test set the system reports F1=0.7201 (63.1% relative gain over baseline 0.4414) and first place on the IqraEval.2 Challenge leaderboard.
Significance. If the reported gains can be traced to the hierarchical adaptation stage, the work would provide a concrete, reproducible recipe for leveraging synthetic data in low-resource MDD and could generalize to other Arabic dialects or low-resource languages. The explicit use of an external challenge benchmark supplies a falsifiable performance anchor.
major comments (3)
- Abstract: the 63.1% relative F1 improvement and SOTA claim rest on the assertion that the second-stage adaptation mitigates domain shift without over-correction, yet no ablation that removes the adaptation stage, no domain-discrepancy metric (e.g., MMD or adversarial discriminator), and no analysis of over-correction risk are referenced, so the performance numbers cannot be attributed to the claimed mechanism.
- Abstract: the baseline F1 of 0.4414 is stated without description of its architecture, training data, or hyper-parameters, and no error bars, number of runs, or statistical significance test accompany the 0.7201 result, leaving the central numeric claim without visible controls or variance estimates.
- Abstract: the data-split protocol for QuranMB.v2 (train/dev/test sizes, speaker overlap, synthetic vs. real proportions) is not reported, which is load-bearing for assessing whether the adaptation stage truly operates on scarce real learner data as described.
minor comments (1)
- Title uses 'Fusion-Aware' but the abstract does not define the fusion operation; clarify whether fusion refers to the ensemble, encoder-TCN combination, or another component.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: Abstract: the 63.1% relative F1 improvement and SOTA claim rest on the assertion that the second-stage adaptation mitigates domain shift without over-correction, yet no ablation that removes the adaptation stage, no domain-discrepancy metric (e.g., MMD or adversarial discriminator), and no analysis of over-correction risk are referenced, so the performance numbers cannot be attributed to the claimed mechanism.
Authors: We agree the abstract does not reference an explicit ablation removing the adaptation stage or quantitative domain-discrepancy metrics. The full manuscript (Section 3.2) describes the hierarchical pre-training then adaptation procedure and reports the final F1, but does not include a dedicated ablation table or MMD analysis. To directly support attribution of the 63.1% gain to the adaptation stage, we will add a one-sentence summary of the ablation results and a brief note on over-correction checks to the revised abstract, plus the corresponding table in the main text. revision: yes
-
Referee: Abstract: the baseline F1 of 0.4414 is stated without description of its architecture, training data, or hyper-parameters, and no error bars, number of runs, or statistical significance test accompany the 0.7201 result, leaving the central numeric claim without visible controls or variance estimates.
Authors: The baseline is a standard CTC-based phoneme recognizer trained on the same pre-training corpora; its architecture and hyper-parameters are detailed in Section 4.1. The reported 0.7201 is the single-run result on the fixed IqraEval.2 test set. We will revise the abstract to include a concise baseline description and will add error bars (standard deviation across three random seeds) together with a significance test to the main results table in the revision. revision: yes
-
Referee: Abstract: the data-split protocol for QuranMB.v2 (train/dev/test sizes, speaker overlap, synthetic vs. real proportions) is not reported, which is load-bearing for assessing whether the adaptation stage truly operates on scarce real learner data as described.
Authors: We will revise the abstract to state the split explicitly: QuranMB.v2 uses a speaker-disjoint partition (approximately 70% train, 15% dev, 15% test) with the adaptation stage performed only on the real-learner subset after pre-training on the combined native/synthetic data. Full utterance counts and synthetic-to-real ratios appear in Section 2; these details will be summarized in the abstract as well. revision: yes
Circularity Check
No circularity: empirical results on external test set and challenge leaderboard
full rationale
The paper reports measured F1-scores (0.7201) and relative gains on the held-out QuranMB.v2 test set and IqraEval.2 Challenge, which are external benchmarks rather than quantities algebraically derived from fitted parameters or self-citations within the paper. The two-stage framework is presented as an engineering description without equations that reduce by construction to their inputs, without self-definitional mappings, and without load-bearing self-citations that substitute for independent evidence. The derivation chain consists of standard pre-training plus adaptation steps whose outputs are validated externally, making the performance claims self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Computer-aided pronunciation training (CAPT) has become an essential tool for second language acquisition. Mispronunci- ation detection and diagnosis (MDD) [1, 2, 3, 4, 5, 6] serves as a critical component of CAPT systems, and its effectiveness hinges on a specific capability: for fine-grained diagnosis, the ability to distinguish canonical f...
Pith/arXiv arXiv 2026
-
[2]
Proposed Method As illustrated in Figure 1, our approach comprises three core components: (1) a hybrid model architecture integrating a large-scale multilingual pre-trained encoder with causal dilated TCNs; (2) a hierarchical two-stage training strategy that first learns general acoustic-phonetic representations from native and synthetic data, then adapts...
-
[3]
Rel. Imp
Experiments 3.1. Experimental Setup Datasets.We utilize the multi-source corpus from the IqraEval challenge 2, partitioned for our two-stage strategy: (1) Training: Stage 1 uses∼79h of native MSA (Iqra train 3) and∼80h of synthetic error-injected speech (Iqra TTS 4). Stage 2 adapts on ∼2h of real learner recordings (Iqra Extra IS26 5) to capture natural d...
-
[4]
Eval- uated on the blind QuranMB.v2 test set, our system achieved an F1-score of0.7201(+63.1%over baseline), ranking at the top of the IqraEval.2 Challenge
Conclusion We presented a robust end-to-end framework for modern stan- dard Arabic MDD, addressing data scarcity and domain shift via three innovations: causal dilated TCNs for fine-grained feature preservation, a hierarchical two-stage training strategy to bridge synthetic-real gaps, and ensemble inference for stability. Eval- uated on the blind QuranMB....
-
[5]
The authors would like to thank the Supercomputing Center of Wuhan Uni- versity for providing the computational resources
Acknowledgments This work was supported by the National Natural Science Foun- dation (NSFC) of China under Grant 62471340. The authors would like to thank the Supercomputing Center of Wuhan Uni- versity for providing the computational resources
-
[6]
No generative AI tool was used to produce a significant part of the manuscript, and no AI tool is listed as a co-author
Generative AI Use Disclosure The authors declare that generative AI tools were used solely for editing, polishing, and improving the grammar and readability of the manuscript. No generative AI tool was used to produce a significant part of the manuscript, and no AI tool is listed as a co-author
-
[7]
Mispronunciation detection and diagnosis in l2 english speech using multidistribution deep neu- ral networks,
K. Li, X. Qian, and H. Meng, “Mispronunciation detection and diagnosis in l2 english speech using multidistribution deep neu- ral networks,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25, no. 1, pp. 193–207, 2017
2017
-
[8]
Improving end-to-end mod- eling for mispronunciation detection with effective augmenta- tion mechanisms,
T.-H. Lo, Y .-T. Sung, and B. Chen, “Improving end-to-end mod- eling for mispronunciation detection with effective augmenta- tion mechanisms,” in2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2021, pp. 1049–1055
2021
-
[9]
Cnn-rnn-ctc based end- to-end mispronunciation detection and diagnosis,
W.-K. Leung, X. Liu, and H. Meng, “Cnn-rnn-ctc based end- to-end mispronunciation detection and diagnosis,” inProc. IEEE ICASSP, 2019, pp. 8132–8136
2019
-
[10]
Empirical study on mispronunciation detection for tajweed rules during quran recitation,
Y . S. Alsahafi and M. Asad, “Empirical study on mispronunciation detection for tajweed rules during quran recitation,” in2024 6th ICCI, 2024, pp. 39–45
2024
-
[11]
Applying multitask learning to acoustic-phonemic model for mispronuncia- tion detection and diagnosis in l2 english speech,
S. Mao, Z. Wu, R. Li, X. Li, H. Meng, and L. Cai, “Applying multitask learning to acoustic-phonemic model for mispronuncia- tion detection and diagnosis in l2 english speech,” inProc. IEEE ICASSP, 2018, pp. 6254–6258
2018
-
[12]
Unsuper- vised discovery of an extended phoneme set in l2 english speech for mispronunciation detection and diagnosis,
S. Mao, X. Li, K. Li, Z. Wu, X. Liu, and H. Meng, “Unsuper- vised discovery of an extended phoneme set in l2 english speech for mispronunciation detection and diagnosis,” inProc. IEEE ICASSP, 2018, pp. 6244–6248
2018
-
[13]
Towards a unified benchmark for arabic pronunciation assessment: Quranic recitation as case study,
Y . E. Kheir, O. Ibrahim, A. Meghanani, N. Almarwani, H. O. Toyin, S. Alharbi, M. Alfadly, L. Alkanhal, I. Selim, S. Elbatal, S. Mdhaffar, T. Hain, Y . Hifny, M. Shahin, and A. Ali, “Towards a unified benchmark for arabic pronunciation assessment: Quranic recitation as case study,”ArXiv, vol. abs/2506.07722, 2025
arXiv 2025
-
[14]
Sampled connectionist temporal classification,
E. Variani, T. Bagby, K. Lahouel, E. McDermott, and M. Bac- chiani, “Sampled connectionist temporal classification,” inProc. IEEE ICASSP, 2018, pp. 4959–4963
2018
-
[15]
Reinterpreting ctc training as iterative fit- ting,
H. Li and W. Wang, “Reinterpreting ctc training as iterative fit- ting,”Pattern Recognition, vol. 105, p. 107392, 2020
2020
-
[16]
Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” inProceedings of the 23rd International Conference on Machine Learning, ser. ICML ’06. New York, NY , USA: Association for Computing Machin- ery, 2006, p. 369–376
2006
-
[17]
Building competitive direct acoustics-to-word mod- els for english conversational speech recognition,
K. Audhkhasi, B. Kingsbury, B. Ramabhadran, G. Saon, and M. Picheny, “Building competitive direct acoustics-to-word mod- els for english conversational speech recognition,” inProc. IEEE ICASSP, 2018, pp. 4759–4763
2018
-
[18]
Fast and accurate recurrent neural network acoustic models for speech recognition,
H. Sak, A. Senior, K. Rao, and F. Beaufays, “Fast and accurate recurrent neural network acoustic models for speech recognition,” inInterspeech 2015, 2015, pp. 1468–1472
2015
-
[19]
Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 29, pp. 3451–3460, 2021
2021
-
[20]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 12 449–12 460
2020
-
[21]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[22]
An End-to-End Mispronunciation Detection System for L2 English Speech Lever- aging Novel Anti-Phone Modeling,
B.-C. Yan, M.-C. Wu, H.-T. Hung, and B. Chen, “An End-to-End Mispronunciation Detection System for L2 English Speech Lever- aging Novel Anti-Phone Modeling,” inInterspeech 2020, 2020, pp. 3032–3036
2020
-
[23]
Improving mis- pronunciation detection and diagnosis for non-native learners of the Arabic language,
N. Alrashoudi, H. Al-Khalifa, and Y . Alotaibi, “Improving mis- pronunciation detection and diagnosis for non-native learners of the Arabic language,”Discover Computing, vol. 28, no. 1, p. 1, Jan. 2025
2025
-
[24]
Transformer Based End-to-End Mispronunciation Detection and Diagnosis,
M. Wu, K. Li, W.-K. Leung, and H. Meng, “Transformer Based End-to-End Mispronunciation Detection and Diagnosis,” inInter- speech 2021, 2021, pp. 3954–3958
2021
-
[25]
An end-to- end transformer-based automatic speech recognition for qur’an re- citers,
S. A.-H. Mohammed Hadwan, Hamzah A. Alsayadi, “An end-to- end transformer-based automatic speech recognition for qur’an re- citers,”Computers, Materials & Continua, vol. 74, no. 2, pp. 3471–3487, 2023
2023
-
[26]
Tem- poral convolutional networks for speech and music detection,
F.-R. St ¨oter, S. Chakrabarty, B. Edler, and E. A. P. Habets, “Tem- poral convolutional networks for speech and music detection,” in Proceedings of the 20th International Society for Music Informa- tion Retrieval Conference (ISMIR 2019). Delft, Netherlands: International Society for Music Information Retrieval (ISMIR), 2019, pp. 458–465
2019
-
[27]
Audio-linguistic embeddings for spoken sentences,
A. Haque, M. Guo, P. Verma, and L. Fei-Fei, “Audio-linguistic embeddings for spoken sentences,”Proc. IEEE ICASSP, pp. 7355–7359, 2019
2019
-
[28]
Improved backing-off for m-gram lan- guage modeling,
R. Kneser and H. Ney, “Improved backing-off for m-gram lan- guage modeling,” in1995 International Conference on Acoustics, Speech, and Signal Processing, vol. 1, 1995, pp. 181–184 vol.1
1995
-
[29]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, Eds., vol. 30. Curran Asso- ciates, Inc., 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.