Importance Estimation for Neural Network Pruning
Pith reviewed 2026-05-25 16:13 UTC · model grok-4.3
The pith
Taylor expansions of the loss rank each filter's contribution to enable effective neural network pruning without layer-specific tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We estimate each filter's contribution to the loss by the first- or second-order Taylor expansion of the loss with respect to that filter's weights and iteratively prune the lowest-scoring filters. The same expansion applies uniformly to any layer without per-layer recalibration and yields a ranking whose correlation with measured true importance exceeds 93 percent on modern ImageNet networks.
What carries the argument
First- and second-order Taylor expansions that approximate the change in loss caused by removing a filter, used as an importance score for iterative pruning.
If this is right
- Pruning guided by these scores produces networks with better accuracy-FLOPs trade-offs than earlier methods.
- The same procedure works on any layer type, including skip connections, without extra per-layer analysis.
- On ResNet-101 a 40 percent FLOPS reduction is achieved by removing 30 percent of parameters while losing only 0.02 percent top-1 accuracy on ImageNet.
- The estimated scores correlate above 93 percent with a direct empirical measure of each filter's true contribution.
Where Pith is reading between the lines
- Because the ranking is derived from the loss surface rather than from layer statistics, the same scores could be recomputed after fine-tuning to decide further rounds of pruning.
- The uniform scaling across layers suggests the method could be applied to networks that mix convolutional, fully-connected, and attention layers without new heuristics.
- If the Taylor approximation remains accurate after quantization, the same importance scores might guide joint pruning and quantization pipelines.
Load-bearing premise
The first- and second-order Taylor expansions give a ranking of filters that stays close enough to their actual effect on loss that removing the lowest-ranked ones produces a good pruned network.
What would settle it
Measure the true loss change after removing each filter individually on a validation set; if the Taylor-based ranking disagrees with that ordering on more than a small fraction of filters, the method's core premise is falsified.
Figures




read the original abstract
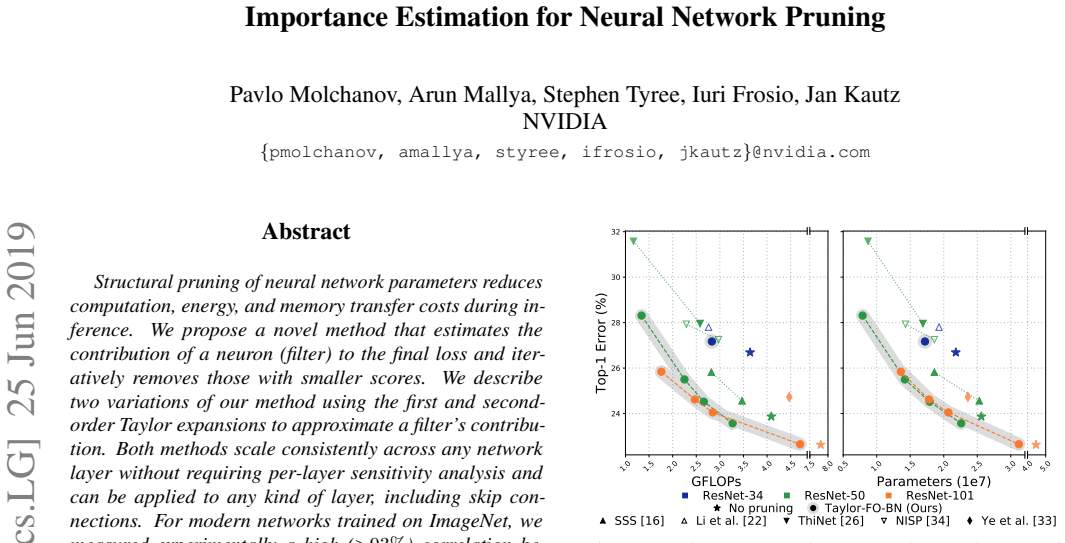
Structural pruning of neural network parameters reduces computation, energy, and memory transfer costs during inference. We propose a novel method that estimates the contribution of a neuron (filter) to the final loss and iteratively removes those with smaller scores. We describe two variations of our method using the first and second-order Taylor expansions to approximate a filter's contribution. Both methods scale consistently across any network layer without requiring per-layer sensitivity analysis and can be applied to any kind of layer, including skip connections. For modern networks trained on ImageNet, we measured experimentally a high (>93%) correlation between the contribution computed by our methods and a reliable estimate of the true importance. Pruning with the proposed methods leads to an improvement over state-of-the-art in terms of accuracy, FLOPs, and parameter reduction. On ResNet-101, we achieve a 40% FLOPS reduction by removing 30% of the parameters, with a loss of 0.02% in the top-1 accuracy on ImageNet. Code is available at https://github.com/NVlabs/Taylor_pruning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes estimating the contribution of filters to the final loss via first- and second-order Taylor expansions and using the resulting scores for iterative structural pruning. The method is claimed to apply uniformly across layer types (including skip connections) without per-layer sensitivity analysis. Experiments on ImageNet-trained networks report >93% correlation between the Taylor scores and an independent estimate of true importance, together with pruning results that improve on prior art (e.g., ResNet-101: 40% FLOPs reduction, 30% parameter removal, 0.02% top-1 accuracy drop). Code is released.
Significance. If the reported correlation and pruning gains hold under standard experimental controls, the work supplies a scalable, layer-agnostic importance estimator whose only free parameters are the usual training hyperparameters. The explicit release of code is a positive contribution to reproducibility.
major comments (2)
- [§4] §4 (Experimental validation): the central claim of >93% correlation is presented without reporting the number of independent runs, random seeds, or variance of the correlation statistic; because this figure is the primary empirical support for the Taylor approximation, the absence of these controls weakens the strength of the evidence.
- [§3.2] §3.2, Eq. (7)–(9): the second-order term is approximated by the diagonal of the Hessian; the manuscript does not quantify the error introduced by this diagonal approximation on modern architectures that contain batch-norm and skip connections, yet the pruning results on ResNet-101 rest on the accuracy of this ranking.
minor comments (3)
- [Table 2] Table 2: the baseline methods are not re-implemented with the same training schedule or data augmentation as the proposed method; a controlled re-run would strengthen the comparison.
- [§4.1] The definition of the 'reliable estimate of true importance' used for the correlation study should be stated explicitly in the main text rather than only in the supplement.
- [Figure 3] Figure 3 caption: the y-axis label 'Importance Score' is ambiguous; clarify whether it is the absolute value of the Taylor term or a normalized quantity.
Simulated Author's Rebuttal
We are grateful to the referee for the positive assessment and recommendation of minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experimental validation): the central claim of >93% correlation is presented without reporting the number of independent runs, random seeds, or variance of the correlation statistic; because this figure is the primary empirical support for the Taylor approximation, the absence of these controls weakens the strength of the evidence.
Authors: We agree that reporting the number of independent runs, random seeds, and variance would strengthen the presentation. The correlation was obtained from 5 independent runs using distinct random seeds; the mean exceeds 93% with standard deviation below 1%. We will revise §4 to include these experimental details and the computation procedure. revision: yes
-
Referee: [§3.2] §3.2, Eq. (7)–(9): the second-order term is approximated by the diagonal of the Hessian; the manuscript does not quantify the error introduced by this diagonal approximation on modern architectures that contain batch-norm and skip connections, yet the pruning results on ResNet-101 rest on the accuracy of this ranking.
Authors: The diagonal approximation is adopted to keep the method computationally feasible. While we do not supply an explicit error bound for networks containing batch-norm and residual connections, the ranking quality is supported by the reported >93% correlation with an independent importance estimate and by the ResNet-101 pruning results themselves. We will add a brief clarifying sentence in §3.2 acknowledging the approximation and its empirical support. revision: partial
Circularity Check
No significant circularity
full rationale
The paper's core derivation applies standard first- and second-order Taylor expansions of the loss to rank filter contributions; these are external mathematical approximations, not defined in terms of the paper's own fitted values or outputs. The reported >93% correlation is measured against an independent reliable estimate of true importance (actual loss change upon removal), which is a separate experimental check rather than a quantity constructed from the same parameters. Pruning results (e.g., ResNet-101) are empirical performance measurements. No self-citation is load-bearing for the central claim, no ansatz is smuggled, and no step reduces by the paper's own equations to a renaming or tautology of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The first- and second-order Taylor expansions of the loss function with respect to filter weights provide a usable approximation to the change in loss caused by removing that filter.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
I^(1)_m(W) = (g_m w_m)^2 ... Var(h_m) = E(h_m^2) - E(h_m)^2 = I^(1)(z) ... J(h) the expected Fisher information matrix
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a new method for estimating ... the contribution of a neuron (filter) to the final loss ... using the first and second-order Taylor expansions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Why Smaller Is Slower? Dimensional Misalignment in Compressed LLMs
Dimensional misalignment slows compressed LLMs on GPUs; GAC uses knapsack optimization to achieve full alignment and up to 1.5x speedup on Llama-3-8B while preserving quality.
Reference graph
Works this paper leans on
-
[1]
Y . Chauvin. A back-propagation algorithm with optimal use of hidden units. In NIPS, 1989
work page 1989
-
[2]
T. M. Cover and J. A. Thomas. Elements of information theory. John Wiley & Sons, 2012
work page 2012
-
[3]
I. Daubechies, M. Defrise, and C. De Mol. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Communications on Pure and Applied Mathematics, 2004
work page 2004
-
[4]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
J. Frankle and M. Carbin. The lottery ticket hypothesis: Train- ing pruned neural networks.arXiv preprint arXiv:1803.03635, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [5]
-
[6]
S. Han, J. Pool, S. Narang, H. Mao, S. Tang, E. Elsen, B. Catanzaro, J. Tran, and W. J. Dally. Dsd: regularizing deep neural networks with dense-sparse-dense training flow. arXiv preprint arXiv:1607.04381, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
S. Han, J. Pool, J. Tran, and W. Dally. Learning both weights and connections for efficient neural network. InNIPS, 2015
work page 2015
-
[8]
S. J. Hanson and L. Y . Pratt. Comparing biases for minimal network construction with back-propagation. In NIPS, 1989
work page 1989
-
[9]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR, 2016
work page 2016
-
[10]
K. He, X. Zhang, S. Ren, and J. Sun. Identity mappings in deep residual networks. In ECCV, 2016
work page 2016
- [11]
- [12]
-
[13]
Y . He, X. Zhang, and J. Sun. Channel pruning for accelerating very deep neural networks. In ICCV, 2017
work page 2017
-
[14]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean. Distilling the knowledge in a neural network. In arXiv preprint arXiv:1503.02531 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [15]
-
[16]
Data-Driven Sparse Structure Selection for Deep Neural Networks
Z. Huang and N. Wang. Data-driven sparse structure selection for deep neural networks. arXiv preprint arXiv:1707.01213, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. Tech Report, 2009
work page 2009
-
[19]
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, pages 1097–1105, 2012
work page 2012
-
[20]
V . Lebedev and V . Lempitsky. Fast convnets using group-wise brain damage. In CVPR, pages 2554–2564, 2016
work page 2016
- [21]
-
[22]
H. Li, A. Kadav, I. Durdanovic, H. Samet, and H. P. Graf. Pruning filters for efficient convnets.ICLR, 2017
work page 2017
-
[23]
Z. Liu, J. Li, Z. Shen, G. Huang, S. Yan, and C. Zhang. Learning efficient convolutional networks through network slimming. In ICCV, 2017
work page 2017
-
[24]
Z. Liu, M. Sun, T. Zhou, G. Huang, and T. Darrell. Re- thinking the value of network pruning. arXiv preprint arXiv:1810.05270, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
Learning Sparse Neural Networks through $L_0$ Regularization
C. Louizos, M. Welling, and D. P. Kingma. Learning sparse neural networks through l 0 regularization. arXiv preprint arXiv:1712.01312, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
J.-H. Luo, J. Wu, and W. Lin. Thinet: A filter level pruning method for deep neural network compression. ICCV, 2017
work page 2017
-
[27]
P. Molchanov, S. Tyree, T. Karras, T. Aila, and J. Kautz. Pruning convolutional neural networks for resource efficient transfer learning. ICLR, 2017
work page 2017
-
[28]
M. C. Mozer and P. Smolensky. Skeletonization: A technique for trimming the fat from a network via relevance assessment. In NIPS, 1989
work page 1989
-
[29]
K. Neklyudov, D. Molchanov, A. Ashukha, and D. P. Vetrov. Structured bayesian pruning via log-normal multiplicative noise. In Advances in Neural Information Processing Systems, pages 6775–6784, 2017
work page 2017
- [30]
-
[31]
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. IJCV, 2015
work page 2015
-
[32]
Faster gaze prediction with dense networks and Fisher pruning
L. Theis, I. Korshunova, A. Tejani, and F. Husz´ar. Faster gaze prediction with dense networks and fisher pruning. arXiv preprint arXiv:1801.05787, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
J. Ye, X. Lu, Z. Lin, and J. Z. Wang. Rethinking the smaller- norm-less-informative assumption in channel pruning of con- volution layers. ICLR, 2018
work page 2018
-
[34]
R. Yu, A. Li, C.-F. Chen, J.-H. Lai, V . I. Morariu, X. Han, M. Gao, C.-Y . Lin, and L. S. Davis. NISP: Pruning networks using neuron importance score propagation. CVPR, 2017
work page 2017
- [35]
-
[36]
Supplementary material In supplementary material we show additional experi- mental results on ResNet20 with CIFAR10, ResNet101 on ImageNet. Additionally, we evaluate inference speed of pruned ResNet101 models. 6.1. ResNet20 on CIFAR10 We experiment on ResNet20 trained on CIFAR10 in order to compare with the work of [33] (referred to as BN-ISTA) and to eva...
-
[37]
Iterative pruning clearly outperforms other settings over all epochs
All settings had the maximum number of neurons to be pruned as 10000 out of 20096, and the Iterative corresponds to TaylorFO-BN-50% in the main paper. Iterative pruning clearly outperforms other settings over all epochs. Finetuning details on ImageNet dataset. When a large number of neurons are removed we found that starting with the larger learning rate ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.