DetailCLIP: Injecting Image Details into CLIP's Feature Space
Pith reviewed 2026-05-24 11:05 UTC · model grok-4.3
The pith
DetailCLIP generates one feature vector from high-resolution images that keeps multi-scale details while staying in CLIP's original semantic space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
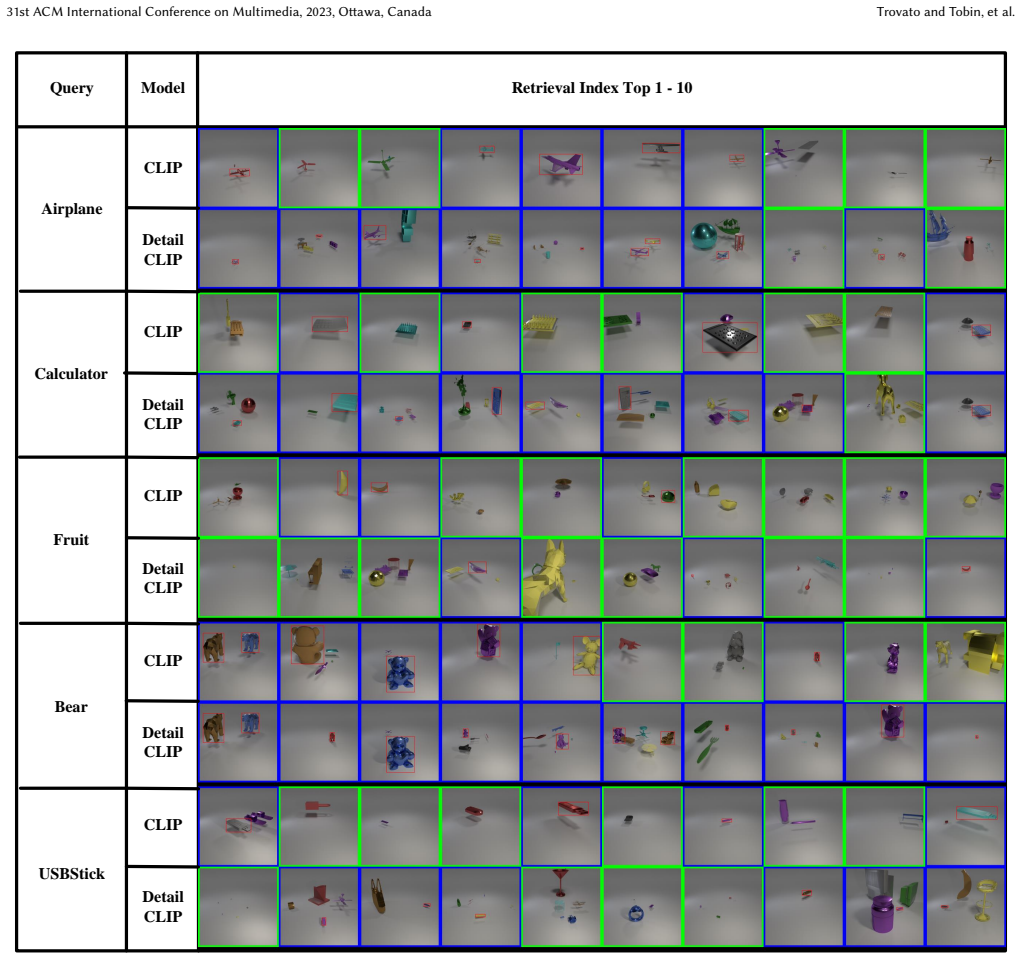
DetailCLIP generates a single feature representation for a high-resolution image that retains image details from different scales while sharing the same semantic space as the original CLIP. This is achieved by a feature fusion model that relies on CLIP features extracted from a carefully designed image patch method, dubbed Complete Cover. This method ensures comprehensive coverage of objects across various scales and is weakly supervised by image-agnostic class prompted queries. The framework is shown to improve retrieval performance on both real-world remote-sensing data and a new controllable synthetic dataset called CLVER-DS.
What carries the argument
The Complete Cover patch method, which tiles the high-resolution image so that objects at every scale are fully covered by at least one patch, paired with a feature fusion model that merges the resulting CLIP vectors into one aligned representation.
If this is right
- Image retrieval based on class prompts improves on both real remote-sensing images and the CLVER-DS synthetic set.
- Small-scale targets such as vehicles and ships become retrievable without changing CLIP's semantic space.
- The same fused vector can be used for any downstream task that already accepts standard CLIP features.
- Controlled scale experiments on CLVER-DS allow direct measurement of how well details at each size are retained.
Where Pith is reading between the lines
- The same patching-plus-fusion pattern could be tried on other vision-language models whose input size is also fixed.
- If the weak supervision works, the method might extend to tasks that need fine detail but lack dense labels, such as medical or aerial image search.
- One could test whether the fused vector still supports zero-shot classification on categories never seen during the fusion training.
Load-bearing premise
The fusion model can combine the patch features so that both fine details and CLIP semantics are preserved when the only training signal is class text prompts.
What would settle it
If retrieval accuracy for tiny objects on the CLVER-DS dataset shows no improvement when the fused high-resolution features are used instead of standard CLIP on downsampled images, the central claim does not hold.
Figures











read the original abstract
Although CLIP-like Visual Language Models provide a functional joint feature space for image and text, due to the limitation of the CILP-like model's image input size (e.g., 224), subtle details are lost in the feature representation if we input high-resolution images (e.g., 2240). Our proposed framework addresses this issue by generating a single feature representation for a high-resolution image that retains image details from different scales while sharing the same semantic space as the original CLIP. An application scenario is remote sensing text-image retrieval, where targets (e.g., vehicles and ships) often appear at tiny scales. To achieve this, we develop a feature fusion model that relies on CLIP features extracted from a carefully designed image patch method, dubbed Complete Cover. This method ensures comprehensive coverage of objects across various scales and is weakly supervised by image-agnostic class prompted queries. We evaluate our framework's performance using real-world and synthetic datasets, demonstrating significant improvements in image retrieval tasks based on class prompted queries. To further showcase our framework's capability in detail retrieval, we introduce a CLEVR-like synthetic dataset, named CLVER-DS. This fully annotated dataset offers a controllable object scale, allowing for a more thorough examination of our approach's effectiveness.Our code is publicly available at https://github.com/zilunzhang/DetailCLIP
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DetailCLIP to produce a single CLIP-compatible feature vector from high-resolution images that retains fine details across scales. It extracts patch features via a Complete Cover method, fuses them with a learned model, and trains under weak supervision from image-agnostic class text prompts. The framework targets remote-sensing retrieval of small objects and is evaluated on real-world data plus a new controllable-scale synthetic dataset (CLVER-DS); code is released publicly.
Significance. If the central claim holds, the work would allow detail-preserving retrieval inside the original CLIP space without retraining the vision encoder, which is practically useful for high-resolution remote-sensing tasks. Public code and the introduction of CLVER-DS are concrete strengths that aid reproducibility.
major comments (3)
- [Method / training procedure] The training objective (described in the method section) uses only image-agnostic class prompts as supervision. Because the prompt is identical for every patch and every scale, the loss supplies no explicit signal that distinguishes fine-grained or scale-specific content; the fusion network can therefore satisfy the class-level retrieval metric while discarding the very details the paper claims to retain.
- [Experiments / CLVER-DS evaluation] Evaluation relies on class-prompted retrieval metrics. To support the claim that scale-specific details are preserved, the experiments must demonstrate gains on queries or annotations that require fine-grained information (e.g., object size, count, or spatial relations) rather than class identity alone; the current protocol does not isolate this property.
- [Abstract and §4] No quantitative numbers (recall@K, mAP, etc.) or baseline comparisons appear in the abstract, and the strength of the reported improvements cannot be assessed without the specific tables or figures that would allow effect-size evaluation.
minor comments (2)
- [Abstract] Abstract contains the typo 'CILP' (should be 'CLIP').
- [Abstract and dataset description] Dataset name alternates between 'CLEVR-like' and 'CLVER-DS'; consistent nomenclature would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where the manuscript will be revised.
read point-by-point responses
-
Referee: [Method / training procedure] The training objective (described in the method section) uses only image-agnostic class prompts as supervision. Because the prompt is identical for every patch and every scale, the loss supplies no explicit signal that distinguishes fine-grained or scale-specific content; the fusion network can therefore satisfy the class-level retrieval metric while discarding the very details the paper claims to retain.
Authors: We agree that the class-level, image-agnostic supervision provides no explicit per-patch or per-scale signal. The Complete Cover extraction and fusion architecture are intended to ensure that multi-scale patches contribute to the final feature, but the training objective itself does not enforce retention of fine details. We will add a clarifying paragraph in the method section acknowledging this limitation of weak supervision and include an ablation that isolates the contribution of multi-scale fusion versus single-scale inputs on small-object retrieval. revision: partial
-
Referee: [Experiments / CLVER-DS evaluation] Evaluation relies on class-prompted retrieval metrics. To support the claim that scale-specific details are preserved, the experiments must demonstrate gains on queries or annotations that require fine-grained information (e.g., object size, count, or spatial relations) rather than class identity alone; the current protocol does not isolate this property.
Authors: CLVER-DS provides full annotations for object scale, count, and spatial layout, which in principle support fine-grained queries. However, the reported experiments use only class-prompted retrieval. We will extend the evaluation section to include additional metrics and queries that directly test size, count, and spatial relations on CLVER-DS, thereby isolating the preservation of scale-specific details. revision: yes
-
Referee: [Abstract and §4] No quantitative numbers (recall@K, mAP, etc.) or baseline comparisons appear in the abstract, and the strength of the reported improvements cannot be assessed without the specific tables or figures that would allow effect-size evaluation.
Authors: We agree that the abstract should report key quantitative results. We will revise the abstract to include specific recall@K and mAP values together with the main baseline comparisons. revision: yes
Circularity Check
No circularity; derivation is self-contained
full rationale
The paper describes a standard pipeline: extract CLIP features from Complete Cover patches of high-resolution images, train a fusion model under weak supervision from image-agnostic class prompts, and evaluate retrieval performance. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the text. The central claim rests on empirical training and external CLIP features rather than any definitional reduction or imported uniqueness theorem. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, et al
-
[2]
Flamingo: a Visual Language Model for Few-Shot Learning
Flamingo: a Visual Language Model for Few-Shot Learning. arXiv preprint arXiv:2204.14198 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [3]
-
[4]
ShapeNet: An Information-Rich 3D Model Repository
Angel X. Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, Jianx- iong Xiao, Li Yi, and Fisher Yu. 2015. ShapeNet: An Information-Rich 3D Model Repository. Technical Report arXiv:1512.03012 [cs.GR]. Stanford University — Princeton University — Toyota Technological Institute...
work page internal anchor Pith review Pith/arXiv arXiv 2015
- [5]
-
[6]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. CoRR abs/2010.11929 (2020). arXiv:2010.11929 https://arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Gabriel Goh, Nick Cammarata †, Chelsea Voss †, Shan Carter, Michael Petrov, Ludwig Schubert, Alec Radford, and Chris Olah. 2021. Multimodal Neurons in Artificial Neural Networks. Distill (2021). https://doi.org/10.23915/distill.00030 https://distill.pub/2021/multimodal-neurons
-
[8]
Agrim Gupta, Piotr Dollar, and Ross Girshick. 2019. LVIS: A dataset for large vocabulary instance segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 5356–5364
work page 2019
-
[9]
Le, Yunhsuan Sung, Zhen Li, and Tom Duerig
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, and Tom Duerig. [n. d.]. Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. ([n. d.]). arXiv:2102.05918 http://arxiv.org/abs/2102.05918
-
[10]
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. 2017. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. In Proceedings of the IEEE conference on computer vision and pattern recognition . 2901–2910
work page 2017
- [11]
- [12]
-
[13]
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al
-
[14]
International journal of computer vision 123, 1 (2017), 32–73
Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision 123, 1 (2017), 32–73
work page 2017
-
[15]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: Boot- strapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models. arXiv:2301.12597 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. [n. d.]. VisualBERT: A Simple and Performant Baseline for Vision and Language. ([n. d.]). arXiv:1908.03557 http://arxiv.org/abs/1908.03557
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[17]
Liunian Harold Li*, Pengchuan Zhang*, Haotian Zhang*, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. 2022. Grounded Language-Image Pre-training. In CVPR
work page 2022
- [18]
-
[19]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. In European conference on computer vision . Springer, 740–755
work page 2014
-
[20]
Norman Mu, Alexander Kirillov, David A. Wagner, and Saining Xie. 2021. SLIP: Self-supervision meets Language-Image Pre-training.CoRR abs/2112.12750 (2021). arXiv:2112.12750 https://arxiv.org/abs/2112.12750
-
[21]
Michal Nazarczuk and Krystian Mikolajczyk. 2020. SHOP-VRB: A Visual Reason- ing Benchmark for Object Perception. International Conference on Robotics and Automation (ICRA) (2020)
work page 2020
-
[22]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. [n. d.]. Learning Transferable Visual Models From Natural Language Supervision. ([n. d.]). arXiv:2103.00020 http: //arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Rad- ford, Mark Chen, and Ilya Sutskever. [n. d.]. Zero-Shot Text-to-Image Generation. ([n. d.]). arXiv:2102.12092 http://arxiv.org/abs/2102.12092
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
ImageNet Large Scale Visual Recognition Challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael S. Bernstein, Alexander C. Berg, and Li Fei-Fei. 2014. ImageNet Large Scale Visual Recognition Challenge. CoRR abs/1409.0575 (2014). arXiv:1409.0575 http://arxiv.org/abs/1409. 0575
work page internal anchor Pith review Pith/arXiv arXiv 2014
- [25]
-
[26]
vijishmadhavan. 2022. Crop-CLIP. https://github.com/vijishmadhavan/Crop- CLIP#Simple-App
work page 2022
- [27]
- [28]
- [29]
-
[30]
Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, Ce Liu, Mengchen Liu, Zicheng Liu, Yumao Lu, Yu Shi, Lijuan Wang, Jianfeng Wang, Bin Xiao, Zhen Xiao, Jianwei Yang, Michael Zeng, Luowei Zhou, and Pengchuan Zhang. [n. d.]. Flo- rence: A New Foundation Model for Computer Vision. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liu- nian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, and Jianfeng Gao. 2021. RegionCLIP: Region-based Language-Image Pretraining. CoRR abs/2112.09106 (2021). arXiv:2112.09106 https://arxiv.org/abs/2112.09106
-
[32]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. 2021. Learning to prompt for vision-language models. arXiv preprint arXiv:2109.01134 (2021). DetailCLIP: Injecting Image Details into CLIP’s Feature Space 31st ACM International Conference on Multimedia, 2023, Ottawa, Canada A APPENDIX A.1 The Effectiveness of Complete Cover Let us explore the c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.