BEVal: A Cross-dataset Evaluation Study of BEV Segmentation Models for Autonomous Driving
Pith reviewed 2026-05-23 21:23 UTC · model grok-4.3
The pith
BEV segmentation models generalize better when trained on multiple datasets rather than one.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
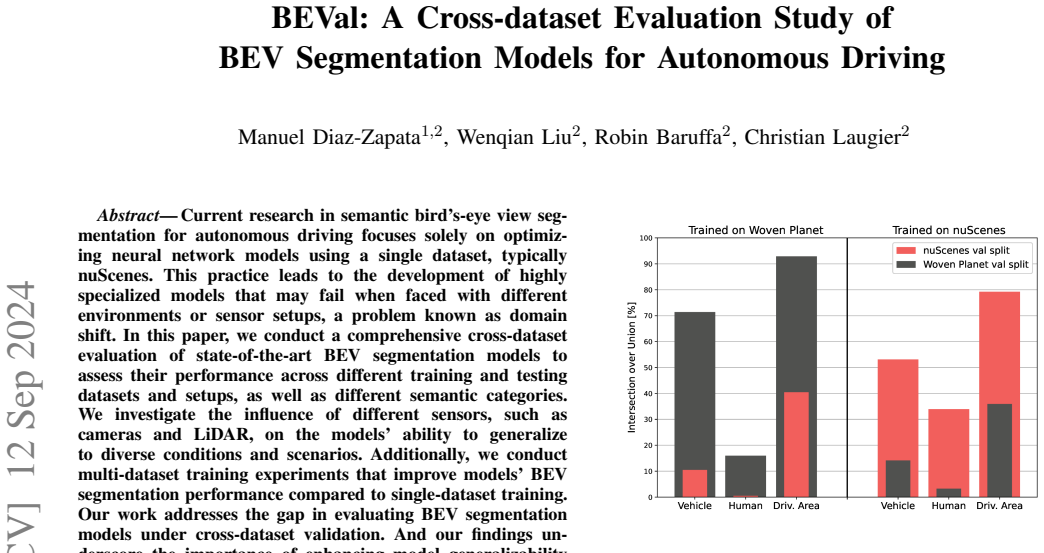
State-of-the-art BEV segmentation models exhibit reduced performance under cross-dataset validation due to domain shift from varying environments and sensors, but multi-dataset training experiments demonstrate improved segmentation accuracy compared to single-dataset training.
What carries the argument
Cross-dataset training and testing protocols that vary datasets, sensor inputs such as cameras and LiDAR, and semantic categories to measure generalization.
If this is right
- Models show better results on test datasets when trained on data from multiple sources.
- Performance differences appear based on whether models use camera, LiDAR, or both.
- Some semantic classes are more affected by dataset changes than others.
- Generalization to new setups becomes essential for practical use in autonomous driving.
Where Pith is reading between the lines
- Autonomous driving systems may require ongoing dataset updates to maintain performance in new areas.
- Evaluation protocols for these models should routinely include tests on unseen datasets.
- Combining datasets could reduce the need for frequent retraining in deployment scenarios.
Load-bearing premise
The datasets used represent the range of variations autonomous driving systems encounter in real deployment.
What would settle it
An experiment showing that models trained on multiple datasets do not outperform single-dataset models on cross-dataset tests.
Figures





read the original abstract
Current research in semantic bird's-eye view segmentation for autonomous driving focuses solely on optimizing neural network models using a single dataset, typically nuScenes. This practice leads to the development of highly specialized models that may fail when faced with different environments or sensor setups, a problem known as domain shift. In this paper, we conduct a comprehensive cross-dataset evaluation of state-of-the-art BEV segmentation models to assess their performance across different training and testing datasets and setups, as well as different semantic categories. We investigate the influence of different sensors, such as cameras and LiDAR, on the models' ability to generalize to diverse conditions and scenarios. Additionally, we conduct multi-dataset training experiments that improve models' BEV segmentation performance compared to single-dataset training. Our work addresses the gap in evaluating BEV segmentation models under cross-dataset validation. And our findings underscore the importance of enhancing model generalizability and adaptability to ensure more robust and reliable BEV segmentation approaches for autonomous driving applications. The code for this paper available at https://github.com/manueldiaz96/beval .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a comprehensive cross-dataset evaluation of state-of-the-art BEV segmentation models for autonomous driving. It assesses performance across multiple training and test datasets, varying sensor configurations (cameras and LiDAR), and semantic categories, while also reporting that multi-dataset training improves segmentation performance relative to single-dataset baselines. The work includes a public code release.
Significance. If the empirical results hold, the study is significant because it directly addresses the domain-shift problem in BEV segmentation, an area that has been dominated by single-dataset (primarily nuScenes) optimization. The demonstration that multi-dataset training yields measurable gains, together with the released code, supplies concrete, reproducible evidence that can guide the development of more robust models for real-world autonomous driving.
minor comments (2)
- [Abstract] Abstract: the sentence beginning 'And our findings' is grammatically awkward; rephrasing to 'Our findings underscore...' would improve readability.
- [§3 (Datasets and Evaluation Protocol)] The manuscript would benefit from an explicit statement of the label taxonomy alignment procedure used when merging semantic categories across datasets.
Simulated Author's Rebuttal
We thank the referee for the thorough review and positive recommendation to accept the manuscript. The summary accurately captures the contributions of our cross-dataset evaluation of BEV segmentation models.
Circularity Check
No significant circularity identified
full rationale
The paper reports empirical cross-dataset evaluations and multi-dataset training experiments on BEV segmentation models, with results compared directly to single-dataset baselines. No derivations, equations, fitted predictions, uniqueness theorems, or ansatzes are invoked; claims rest on experimental measurements and released code. The work is self-contained against external benchmarks with no load-bearing self-citation chains or self-definitional reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard supervised training and evaluation protocols for semantic segmentation (cross-entropy loss, IoU metrics) apply without modification to BEV tasks.
Reference graph
Works this paper leans on
-
[1]
B. Siciliano, O. Khatib, and T. Kr ¨oger, Springer handbook of robotics . Springer, 2008, vol. 200
work page 2008
-
[2]
Using occupancy grids for mobile robot perception and navigation,
A. Elfes, “Using occupancy grids for mobile robot perception and navigation,” Computer, vol. 22, no. 6, pp. 46–57, 1989
work page 1989
-
[3]
M. Diaz-Zapata, D. Sierra-Gonzalez, ¨O. Erkent, C. Laugier, and J. Dibangoye, “Laptnet-fpn: Multi-scale lidar-aided projective trans- form network for real time semantic grid prediction,” in 2023 IEEE International Conference on Robotics and Automation (ICRA) . IEEE, 2023, pp. 712–718
work page 2023
-
[4]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” in European Conference on Computer Vision . Springer, 2020, pp. 194–210
work page 2020
-
[5]
Bird’s-eye-view panoptic segmentation using monocular frontal view images,
N. Gosala and A. Valada, “Bird’s-eye-view panoptic segmentation using monocular frontal view images,” IEEE Robotics and Automation Letters, 2022
work page 2022
-
[6]
Trans- lating images into maps,
A. Saha, O. Mendez Maldonado, C. Russell, and R. Bowden, “Trans- lating images into maps,” 2022 IEEE International Conference on Robotics and Automation (ICRA) , 2022
work page 2022
-
[7]
Pillarsegnet: Pillar-based semantic grid map estimation using sparse lidar data,
J. Fei, K. Peng, P. Heidenreich, F. Bieder, and C. Stiller, “Pillarsegnet: Pillar-based semantic grid map estimation using sparse lidar data,” in 2021 IEEE Intelligent V ehicles Symposium (IV) . IEEE, 2021, pp. 838–844
work page 2021
-
[8]
A simple baseline for bev perception without lidar,
A. W. Harley, Z. Fang, J. Li, R. Ambrus, and K. Fragkiadaki, “A simple baseline for bev perception without lidar,” arXiv preprint arXiv:2206.07959, 2022
-
[9]
Transfusegrid: Transformer-based lidar-rgb fusion for semantic grid prediction,
G. Salazar-Gomez, D. S. Gonz ´alez, M. A. Diaz-Zapata, A. Paigwar, W. Liu, ¨O. Erkent, and C. Laugier, “Transfusegrid: Transformer-based lidar-rgb fusion for semantic grid prediction,” in ICARCV 2022-17th International Conference on Control, Automation, Robotics and Vision, 2022
work page 2022
-
[10]
Deep tracking in the wild: End-to-end tracking using recurrent neu- ral networks,
J. Dequaire, P. Ondr ´uˇska, D. Rao, D. Wang, and I. Posner, “Deep tracking in the wild: End-to-end tracking using recurrent neu- ral networks,” The International Journal of Robotics Research , p. 0278364917710543, 2017
work page 2017
-
[11]
Learning 2d to 3d lifting for object detection in 3d for autonomous vehicles,
S. Srivastava, F. Jurie, and G. Sharma, “Learning 2d to 3d lifting for object detection in 3d for autonomous vehicles,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . IEEE, 2019, pp. 4504–4511
work page 2019
-
[12]
Predicting semantic map representations from images using pyramid occupancy networks,
T. Roddick and R. Cipolla, “Predicting semantic map representations from images using pyramid occupancy networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2020, pp. 11 138–11 147
work page 2020
-
[13]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , 2020, pp. 11 621–11 631
work page 2020
-
[14]
Woven planet perception dataset 2020,
R. Kesten, M. Usman, J. Houston, T. Pandya, K. Nadhamuni, A. Fer- reira, M. Yuan, B. Low, A. Jain, P. Ondruska, S. Omari, S. Shah, A. Kulkarni, A. Kazakova, C. Tao, L. Platinsky, W. Jiang, and V . Shet, “Woven planet perception dataset 2020,” https://woven.toyota/ en/perception-dataset, 2019
work page 2020
-
[15]
Fiery: Future instance prediction in bird’s- eye view from surround monocular cameras,
A. Hu, Z. Murez, N. Mohan, S. Dudas, J. Hawke, V . Badrinarayanan, R. Cipolla, and A. Kendall, “Fiery: Future instance prediction in bird’s- eye view from surround monocular cameras,” in Proceedings of the IEEE/CVF International Conference on Computer Vision , 2021, pp. 15 273–15 282
work page 2021
-
[16]
Cross-view transformers for real-time map-view semantic segmentation,
B. Zhou and P. Kr ¨ahenb¨uhl, “Cross-view transformers for real-time map-view semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 13 760–13 769
work page 2022
-
[17]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” arXiv preprint arXiv:2203.17270, 2022
-
[18]
Uncertainty estimation for cross-dataset performance in trajectory prediction,
T. Gilles, S. Sabatini, D. Tsishkou, B. Stanciulescu, and F. Moutarde, “Uncertainty estimation for cross-dataset performance in trajectory prediction,” CoRR, vol. abs/2205.07310, 2022. [Online]. Available: https://doi.org/10.48550/arXiv.2205.07310
-
[19]
Assess- ing cross-dataset generalization of pedestrian crossing predictors,
J. Gesnouin, S. Pechberti, B. Stanciulescu, and F. Moutarde, “Assess- ing cross-dataset generalization of pedestrian crossing predictors,” in 2022 IEEE Intelligent V ehicles Symposium (IV) . IEEE, 2022, pp. 419–426
work page 2022
-
[20]
Cross-dataset experimental study of radar-camera fusion in bird’s-eye view,
L. St ¨acker, P. Heidenreich, J. Rambach, and D. Stricker, “Cross-dataset experimental study of radar-camera fusion in bird’s-eye view,” in2023 31st European Signal Processing Conference (EUSIPCO) . IEEE, 2023, pp. 810–814
work page 2023
-
[21]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition . Ieee, 2009, pp. 248–255
work page 2009
-
[22]
Lara: Latents and rays for multi-camera bird’s-eye- view semantic segmentation,
F. Bartoccioni, E. Zablocki, A. Bursuc, P. Perez, M. Cord, and K. Alahari, “Lara: Latents and rays for multi-camera bird’s-eye- view semantic segmentation,” in 6th Annual Conference on Robot Learning, 2022. [Online]. Available: https://openreview.net/forum?id= abd D-iVjk0
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.