Are Decoder-Only Large Language Models the Silver Bullet for Code Search?
Pith reviewed 2026-05-23 18:37 UTC · model grok-4.3
The pith
Fine-tuned decoder-only LLMs like CodeGemma outperform encoder-only models by 40.4% MAP on CoSQA+ for code search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuned decoder-only models, particularly CodeGemma, significantly outperform encoder-only models like UniXcoder, achieving a 40.4% higher Mean Average Precision (MAP) on the CoSQA+ benchmark. The relationship between model size and performance is non-monotonic, with mid-sized models often outperforming larger variants; the composition of the training data is critical, as a multilingual dataset enhances generalization while a small amount of data from a specific language can act as noise and interfere with model effectiveness.
What carries the argument
Systematic zero-shot and fine-tuned evaluation of eleven decoder-only LLMs on code search benchmarks, with explicit controls for model size and training-data language mix.
If this is right
- Fine-tuned decoder-only models should replace encoder-only models as the default choice for code search.
- Mid-sized decoder-only models can be selected over larger ones without sacrificing accuracy.
- Multilingual training data should be used to improve generalization across programming languages.
- Small quantities of data from one language should be avoided during training to prevent interference.
Where Pith is reading between the lines
- Code search tools could be rebuilt around fine-tuned decoder-only models to reach higher retrieval accuracy in practice.
- Similar size and data-composition effects may appear when the same models are applied to other retrieval tasks in software engineering.
- Optimal model choice for a given deployment may require testing a range of sizes rather than defaulting to the largest available variant.
Load-bearing premise
The chosen benchmarks and fine-tuning protocols provide a fair and generalizable measure of real-world code search performance without hidden selection effects or domain mismatch.
What would settle it
Running the same models on an independently collected code search benchmark where the MAP advantage of the fine-tuned decoder-only models disappears or reverses.
Figures







read the original abstract
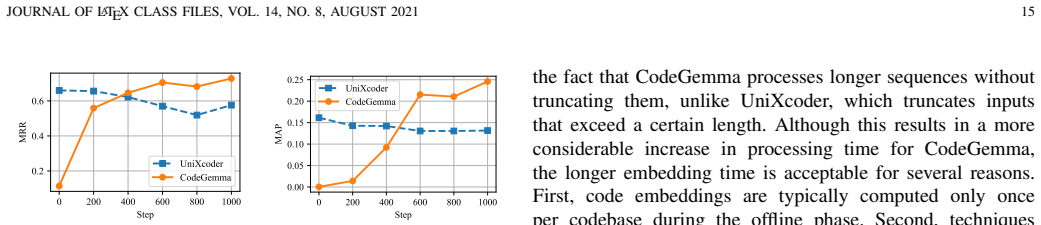
Code search is essential for code reuse, allowing developers to efficiently locate relevant code snippets. The advent of powerful decoder-only Large Language Models (LLMs) has revolutionized many code intelligence tasks. However, their effectiveness for the retrieval-based task of code search, particularly compared to established encoder-based models, remains underexplored. This paper addresses this gap by presenting a large-scale systematic evaluation of eleven decoder-only LLMs, analyzing their performance across zero-shot and fine-tuned settings. Our results show that fine-tuned decoder-only models, particularly CodeGemma, significantly outperform encoder-only models like UniXcoder, achieving a 40.4% higher Mean Average Precision (MAP) on the CoSQA$^+$ benchmark. Our analysis further reveals two crucial nuances for practitioners: first, the relationship between model size and performance is non-monotonic, with mid-sized models often outperforming larger variants; second, the composition of the training data is critical, as a multilingual dataset enhances generalization while a small amount of data from a specific language can act as noise and interfere with model effectiveness. These findings offer a comprehensive guide to selecting and optimizing modern LLMs for code search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale empirical evaluation of eleven decoder-only LLMs for code search in both zero-shot and fine-tuned regimes, comparing them to encoder-only baselines such as UniXcoder. It claims that fine-tuned decoder-only models, particularly CodeGemma, deliver a 40.4% higher MAP on the CoSQA+ benchmark, while also reporting a non-monotonic relationship between model size and performance and the critical role of multilingual versus language-specific training data composition.
Significance. If the decoder-only versus encoder-only comparisons are performed under identical fine-tuning conditions, the results would provide actionable guidance on architecture choice and data curation for code retrieval tasks, potentially shifting preference away from encoder-only models in this domain. The non-monotonic size finding and data-composition nuance are practically useful observations that could be tested in follow-up work.
major comments (2)
- [Methods / Experimental Setup] Methods / Experimental Setup section: The manuscript must explicitly document whether the UniXcoder (and other encoder-only) baseline results were produced by re-fine-tuning the model on the identical dataset, loss, hyperparameters, and train/validation/test splits used for the decoder-only models. The central 40.4% MAP improvement claim on CoSQA+ is load-bearing on this matched-protocol detail; any reliance on previously published numbers without re-implementation would introduce a protocol confound that undermines the architecture comparison.
- [Results] Results section (performance tables): The paper should report the exact fine-tuning data volume and language distribution used for each model family so that readers can verify whether the multilingual advantage is driven by data scale or by the decoder architecture itself.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction should define the precise modifications that distinguish CoSQA+ from the original CoSQA benchmark.
- [Figures / Tables] Figure captions and tables would benefit from explicit mention of the number of random seeds or runs underlying the reported MAP scores.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on clarifying our experimental protocols and data details. These points strengthen the manuscript's transparency. We address each major comment below.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] Methods / Experimental Setup section: The manuscript must explicitly document whether the UniXcoder (and other encoder-only) baseline results were produced by re-fine-tuning the model on the identical dataset, loss, hyperparameters, and train/validation/test splits used for the decoder-only models. The central 40.4% MAP improvement claim on CoSQA+ is load-bearing on this matched-protocol detail; any reliance on previously published numbers without re-implementation would introduce a protocol confound that undermines the architecture comparison.
Authors: All encoder-only baselines including UniXcoder were re-fine-tuned from scratch using the exact same training dataset, loss function, hyperparameters, and train/validation/test splits as the decoder-only models. This matched protocol was followed to ensure a fair architecture comparison, but the manuscript did not explicitly state it. We will revise the Methods section to document this detail clearly, removing any potential ambiguity around the 40.4% MAP claim. revision: yes
-
Referee: [Results] Results section (performance tables): The paper should report the exact fine-tuning data volume and language distribution used for each model family so that readers can verify whether the multilingual advantage is driven by data scale or by the decoder architecture itself.
Authors: We agree that explicit reporting of fine-tuning data volume and language distribution per model family is necessary to isolate architecture effects from data factors. The revised manuscript will include this information, either as an expanded table or dedicated subsection in the Experimental Setup or Results, detailing token counts and language breakdowns for each fine-tuning run. revision: yes
Circularity Check
Pure empirical benchmarking; no derivations or self-referential reductions
full rationale
The paper reports direct experimental results from fine-tuning decoder-only LLMs and comparing MAP scores against published encoder-only baselines on CoSQA+. No equations, fitted parameters renamed as predictions, uniqueness theorems, or ansatzes appear. The central claim is an observed performance delta under stated protocols; it does not reduce to its own inputs by construction. Self-citations, if present, are not load-bearing for any derivation.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
XSearch: Explainable Code Search via Concept-to-Code Alignment
XSearch achieves explainable code search by breaking queries into functional concepts and matching them directly to code statements, delivering large gains on out-of-distribution benchmarks.
Reference graph
Works this paper leans on
- [2]
-
[3]
Chatgpt: Optimizing language models for dialogue,
OpenAI, “Chatgpt: Optimizing language models for dialogue,” 2023. [Online]. Available: https://openai.com/chatgpt
work page 2023
-
[4]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . Li et al. , “Deepseek-coder: When the large language model meets programming–the rise of code intelligence,” arXiv preprint arXiv:2401.14196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” arXiv preprint arXiv:2312.10997 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Le et al. , “Program synthesis with large language models,” arXiv preprint arXiv:2108.07732 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Cocosoda: Effective contrastive learning for code search,
E. Shi, Y . Wang, W. Gu, L. Du, H. Zhang, S. Han, D. Zhang, and H. Sun, “Cocosoda: Effective contrastive learning for code search,” in 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 2023, pp. 2198–2210
work page 2023
-
[8]
GraphCodeBERT: Pre-training Code Representations with Data Flow
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svyatkovskiy, S. Fu et al. , “Graphcodebert: Pre-training code repre- sentations with data flow,” arXiv preprint arXiv:2009.08366 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang et al., “Codebert: A pre-trained model for programming and natural languages,” arXiv preprint arXiv:2002.08155 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[10]
UniXcoder: Unified Cross-Modal Pre-training for Code Representation
D. Guo, S. Lu, N. Duan, Y . Wang, M. Zhou, and J. Yin, “Unixcoder: Unified cross-modal pre-training for code representation,” arXiv preprint arXiv:2203.03850, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
arXiv preprint arXiv:2103.06333 (2021)
W. U. Ahmad, S. Chakraborty, B. Ray, and K.-W. Chang, “Unified pre-training for program understanding and generation,” arXiv preprint arXiv:2103.06333, 2021
-
[12]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
J. W. Rae, S. Borgeaud, T. Cai, K. Millican, J. Hoffmann, F. Song, J. Aslanides, S. Henderson, R. Ring, S. Young et al., “Scaling language models: Methods, analysis & insights from training gopher,” arXiv preprint arXiv:2112.11446, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [14]
- [15]
-
[16]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu et al. , “Deepseek llm: Scaling open-source language models with longtermism,” arXiv preprint arXiv:2401.02954 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Code Llama: Open Foundation Models for Code
B. Rozi `ere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. Tan, Y . Adi, J. Liu, T. Remez, J. Rapin, A. Kozhevnikov, I. Evtimov, J. Bitton, M. P. Bhatt, C. C. Ferrer, A. Grattafiori, W. Xiong, A. D’efossez, J. Copet, F. Azhar, H. Touvron, L. Martin, N. Usunier, T. Scialom, and G. Synnaeve, “Code llama: Open foundation models for code,” ArXiv, vol. abs/2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950 2023
-
[18]
Georgepitt, “Decoderllms-codesearch,” 2024, accessed: 2024- 10-17. [Online]. Available: https://github.com/Georgepitt/ DecoderLLMs-CodeSearch
work page 2024
-
[19]
Sniff: A search engine for java using free-form queries,
S. Chatterjee, S. Juvekar, and K. Sen, “Sniff: A search engine for java using free-form queries,” in Fundamental Approaches to Software Engineering: 12th International Conference, F ASE 2009, Held as Part of the Joint European Conferences on Theory and Practice of Software, ETAPS 2009, York, UK, March 22-29, 2009. Proceedings 12 . Springer, 2009, pp. 385–400
work page 2009
-
[20]
X. Gu, H. Zhang, and S. Kim, “Deep code search,” in Proceedings of the 40th International Conference on Software Engineering , 2018, pp. 933–944
work page 2018
-
[21]
A systematic literature review on the use of deep learning in software engineering research,
C. Watson, N. Cooper, D. N. Palacio, K. Moran, and D. Poshyvanyk, “A systematic literature review on the use of deep learning in software engineering research,” ACM Transactions on Software Engineering and Methodology (TOSEM), vol. 31, no. 2, pp. 1–58, 2022
work page 2022
-
[22]
Leveraging code generation to improve code retrieval and summarization via dual learning,
W. Ye, R. Xie, J. Zhang, T. Hu, X. Wang, and S. Zhang, “Leveraging code generation to improve code retrieval and summarization via dual learning,” in Proceedings of The Web Conference 2020 , 2020, pp. 2309– 2319
work page 2020
-
[23]
Improving code search with co-attentive representation learning,
J. Shuai, L. Xu, C. Liu, M. Yan, X. Xia, and Y . Lei, “Improving code search with co-attentive representation learning,” in Proceedings of the 28th International Conference on Program Comprehension , 2020, pp. 196–207
work page 2020
-
[24]
Learning code-query interaction for enhancing code searches,
W. Li, H. Qin, S. Yan, B. Shen, and Y . Chen, “Learning code-query interaction for enhancing code searches,” in 2020 IEEE International Conference on Software Maintenance and Evolution (ICSME) . IEEE, 2020, pp. 115–126
work page 2020
-
[25]
C. Ling, Z. Lin, Y . Zou, and B. Xie, “Adaptive deep code search,” in Proceedings of the 28th International Conference on Program Compre- hension, 2020, pp. 48–59
work page 2020
-
[26]
Multi- modal attention network learning for semantic source code retrieval,
Y . Wan, J. Shu, Y . Sui, G. Xu, Z. Zhao, J. Wu, and P. Yu, “Multi- modal attention network learning for semantic source code retrieval,” in 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE) . IEEE, 2019, pp. 13–25
work page 2019
-
[27]
Deep graph matching and searching for semantic code retrieval,
X. Ling, L. Wu, S. Wang, G. Pan, T. Ma, F. Xu, A. X. Liu, C. Wu, and S. Ji, “Deep graph matching and searching for semantic code retrieval,” ACM Transactions on Knowledge Discovery from Data (TKDD) , vol. 15, no. 5, pp. 1–21, 2021
work page 2021
-
[28]
Is a single model enough? mucos: A multi-model ensemble learning approach for semantic code search,
L. Du, X. Shi, Y . Wang, E. Shi, S. Han, and D. Zhang, “Is a single model enough? mucos: A multi-model ensemble learning approach for semantic code search,” in Proceedings of the 30th ACM International Conference on Information & Knowledge Management , 2021, pp. 2994– 2998
work page 2021
-
[29]
Ocor: An overlapping-aware code retriever,
Q. Zhu, Z. Sun, X. Liang, Y . Xiong, and L. Zhang, “Ocor: An overlapping-aware code retriever,” inProceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering , 2020, pp. 883–894
work page 2020
-
[30]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
H. Husain, H.-H. Wu, T. Gazit, M. Allamanis, and M. Brockschmidt, “Codesearchnet challenge: Evaluating the state of semantic code search,” arXiv preprint arXiv:1909.09436 , 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[32]
N. D. Bui, Y . Yu, and L. Jiang, “Self-supervised contrastive learning for code retrieval and summarization via semantic-preserving transforma- tions,” in Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , 2021, pp. 511– 521
work page 2021
-
[33]
On the importance of building high-quality training datasets for neural code search,
Z. Sun, L. Li, Y . Liu, X. Du, and L. Li, “On the importance of building high-quality training datasets for neural code search,” in Proceedings of JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 18 the 44th International Conference on Software Engineering , 2022, pp. 1609–1620
work page 2021
-
[34]
Y . Wang, W. Wang, S. Joty, and S. C. Hoi, “Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation,” arXiv preprint arXiv:2109.00859 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
C. Niu, C. Li, V . Ng, D. Chen, J. Ge, and B. Luo, “An empirical comparison of pre-trained models of source code,” in 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023 . IEEE, 2023, pp. 2136–2148. [Online]. Available: https://doi.org/10.1109/ICSE48619.2023.00180
-
[36]
Fine-tuning llama for multi-stage text retrieval,
X. Ma, L. Wang, N. Yang, F. Wei, and J. Lin, “Fine-tuning llama for multi-stage text retrieval,” in Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024, pp. 2421–2425
work page 2024
- [37]
-
[38]
Improving text embeddings with large language models,
L. Wang, N. Yang, X. Huang, L. Yang, R. Majumder, and F. Wei, “Improving text embeddings with large language models,”arXiv preprint arXiv:2401.00368, 2023
-
[39]
Repetition improves language model embeddings,
J. M. Springer, S. Kotha, D. Fried, G. Neubig, and A. Raghunathan, “Repetition improves language model embeddings,” arXiv preprint arXiv:2402.15449, 2024
-
[40]
LLM2Vec: Large language models are secretly powerful text encoders
P. BehnamGhader, V . Adlakha, M. Mosbach, D. Bahdanau, N. Chapados, and S. Reddy, “Llm2vec: Large language models are secretly powerful text encoders,” arXiv preprint arXiv:2404.05961 , 2024
-
[41]
Cosqa+: En- hancing code search dataset with matching code,
J. Gong, Y . Wu, L. Liang, Z. Zheng, and Y . Wang, “Cosqa+: En- hancing code search dataset with matching code,” arXiv preprint arXiv:2406.11589, 2024
-
[42]
Cosqa: 20,000+ web queries for code search and question answering,
J. Huang, D. Tang, L. Shou, M. Gong, K. Xu, D. Jiang, M. Zhou, and N. Duan, “Cosqa: 20,000+ web queries for code search and question answering,” arXiv preprint arXiv:2105.13239 , 2021
-
[43]
Staqc: A systematically mined question-code dataset from stack overflow,
Z. Yao, D. S. Weld, W.-P. Chen, and H. Sun, “Staqc: A systematically mined question-code dataset from stack overflow,” in Proceedings of the 2018 World Wide Web Conference , 2018, pp. 1693–1703
work page 2018
-
[44]
The trec-8 question answering track report
E. M. V oorhees et al. , “The trec-8 question answering track report.” in Trec, vol. 99, 1999, pp. 77–82
work page 1999
-
[45]
Information retrieval: recent advances and beyond,
K. A. Hambarde and H. Proenca, “Information retrieval: recent advances and beyond,” IEEE Access , 2023
work page 2023
-
[46]
Meta, “Meta-llama-3-8b-instruct,” https://huggingface.co/meta-llama/ Meta-Llama-3-8B-Instruct, 2024
work page 2024
-
[47]
(2024) Mistral-7b-instruct-v0.2
Mistral. (2024) Mistral-7b-instruct-v0.2. [Online]. Available: https: //huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
work page 2024
-
[48]
DeepSeek-AI, “Deepseek-llm-7b-chat,” https://huggingface.co/ deepseek-ai/deepseek-llm-7b-chat, 2024
work page 2024
- [49]
-
[50]
Meta, “Llama-2-7b-hf,” https://huggingface.co/meta-llama/ Llama-2-7b-hf, 2024
work page 2024
-
[51]
Qwen Team, “Qwen2.5-coder-7b-instruct,” https://huggingface.co/ Qwen/Qwen2.5-Coder-7B-Instruct, 2025, accessed: 2025-07-04
work page 2025
-
[52]
BigCode Team, “Starcoder2-7b,” https://huggingface.co/bigcode/ starcoder2-7b, 2024, accessed: 2025-07-04
work page 2024
-
[53]
Mistral-7b-instruct-v0.2-code-ft-gguf,
TheBloke, “Mistral-7b-instruct-v0.2-code-ft-gguf,” https://huggingface. co/TheBloke/Mistral-7B-Instruct-v0.2-code-ft-GGUF, 2024
work page 2024
-
[54]
DeepSeek-AI, “Deepseek-coder-6.7b-instruct,” https://huggingface.co/ deepseek-ai/deepseek-coder-6.7b-instruct, 2024
work page 2024
-
[55]
Google, “Codegemma-7b-it,” https://huggingface.co/google/ codegemma-7b-it, 2024
work page 2024
-
[56]
Code Llama: Open Foundation Models for Code
B. Rozi `ere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, T. Remez, J. Rapin et al., “Code llama: Open foundation models for code,” arXiv preprint arXiv:2308.12950 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Microsoft, “Codebert-base,” https://huggingface.co/microsoft/ codebert-base, 2024
work page 2024
-
[58]
——, “Unixcoder-base,” https://huggingface.co/microsoft/ unixcoder-base, 2024
work page 2024
-
[59]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale et al. , “Llama 2: Open foundation and fine-tuned chat models,” arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier et al. , “Mistral 7b,” arXiv preprint arXiv:2310.06825 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [61]
-
[62]
Ajibawa, “Code-290k-sharegpt,” https://huggingface.co/datasets/ ajibawa-2023/Code-290k-ShareGPT, 2024
work page 2023
-
[63]
Gemma: Open Models Based on Gemini Research and Technology
G. Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivi `ere, M. S. Kale, J. Love et al. , “Gemma: Open models based on gemini research and technology,” arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Codegemma: Open code models based on gemma.arXiv preprint arXiv:2406.11409, 2024
C. T. H. Zhao, J. Hui, J. Howland, N. Nguyen, S. Zuo, A. Hu, C. A. Choquette-Choo, J. Shen, J. Kelley, K. Bansal, L. Vilnis, M. Wirth, P. Michel, P. Choy, P. Joshi, R. Kumar, S. Hashmi, S. Agrawal, Z. Gong, J. Fine, T. B. Warkentin, A. J. Hartman, B. Ni, K. Korevec, K. Schaefer, and S. Huffman, “Codegemma: Open code models based on gemma,” ArXiv, vol. abs...
-
[65]
A. Dubey, A. Jauhri, A. Pandey, and et al., “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
StarCoder 2 and The Stack v2: The Next Generation
A. Lozhkov, R. Li, L. B. Allal, F. Cassano, J. Lamy-Poirier, N. Tazi, A. Tang, D. Pykhtar, J. Liu, Y . Wei et al. , “Starcoder 2 and the stack v2: The next generation,” arXiv preprint arXiv:2402.19173 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu et al. , “Qwen2. 5-coder technical report,” arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Survey of code search based on deep learning,
Y . Xie, J. Lin, H. Dong, L. Zhang, and Z. Wu, “Survey of code search based on deep learning,” ACM Transactions on Software Engineering and Methodology , vol. 33, no. 2, pp. 1–42, 2023
work page 2023
-
[69]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” arXiv preprint arXiv:1907.11692 , 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[70]
Codesc: A large code-description parallel dataset,
M. Hasan, T. Muttaqueen, A. A. Ishtiaq, K. S. Mehrab, M. M. A. Haque, T. Hasan, W. U. Ahmad, A. Iqbal, and R. Shahriyar, “Codesc: A large code-description parallel dataset,” arXiv preprint arXiv:2105.14220 , 2021
- [71]
-
[72]
SimCSE: Simple Contrastive Learning of Sentence Embeddings
T. Gao, X. Yao, and D. Chen, “Simcse: Simple contrastive learning of sentence embeddings,” arXiv preprint arXiv:2104.08821 , 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[73]
Sheared-llama-1.3b model card,
P. NLP, “Sheared-llama-1.3b model card,” https://huggingface.co/ princeton-nlp/Sheared-LLaMA-1.3B, 2023, accessed: 2025-08-20
work page 2023
-
[74]
Meta, “Llama-2-13b-hf model card,” https://huggingface.co/meta-llama/ Llama-2-13b-hf, 2023, accessed: 2025-08-20
work page 2023
-
[75]
Qwen2.5-coder-0.5b-instruct model card,
Q. Team, “Qwen2.5-coder-0.5b-instruct model card,” https: //huggingface.co/Qwen/Qwen2.5-Coder-0.5B-Instruct, 2024, accessed: 2025-08-20
work page 2024
-
[76]
Qwen2.5-coder-1.5b-instruct model card,
——, “Qwen2.5-coder-1.5b-instruct model card,” https://huggingface. co/Qwen/Qwen2.5-Coder-1.5B-Instruct, 2024, accessed: 2025-08-20
work page 2024
-
[77]
Qwen2.5-coder-3b-instruct model card,
——, “Qwen2.5-coder-3b-instruct model card,” https://huggingface.co/ Qwen/Qwen2.5-Coder-3B-Instruct, 2024, accessed: 2025-08-20
work page 2024
-
[78]
Qwen2.5-coder-14b-instruct model card,
——, “Qwen2.5-coder-14b-instruct model card,” https://huggingface.co/ Qwen/Qwen2.5-Coder-14B-Instruct, 2024, accessed: 2025-08-20
work page 2024
-
[79]
Language Models are Few-Shot Learners
B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal et al. , “Language models are few-shot learners,” arXiv preprint arXiv:2005.14165 , vol. 1, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.