Bayesian Parameter Shift Rule in Variational Quantum Eigensolvers
Pith reviewed 2026-05-23 03:34 UTC · model grok-4.3
The pith
Bayesian parameter shift rule estimates VQE gradients from arbitrary past observations with uncertainty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
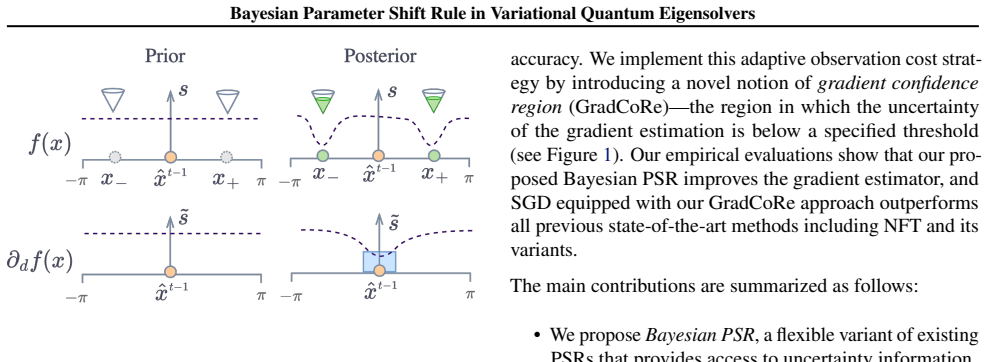
The Bayesian PSR estimates the gradient of the VQE objective using Gaussian process regression, offering estimates from observations at arbitrary locations along with uncertainty quantification. It reduces to the generalized PSR in special cases. In SGD, this flexibility permits reusing observations from prior steps to accelerate optimization, and the posterior uncertainty combined with the gradient confident region concept allows minimizing observation costs per step.
What carries the argument
Bayesian parameter shift rule implemented via Gaussian process regression with appropriate kernels on the VQE objective function
If this is right
- Past observations can be reused across SGD steps without requiring new circuit evaluations at every iteration.
- Posterior uncertainty combined with GradCoRe reduces the number of new observations needed while preserving gradient reliability.
- The method reduces exactly to the generalized parameter shift rule when observations coincide with the required shift locations.
- Numerical experiments show faster convergence than sequential minimal optimization on the tested VQE instances.
Where Pith is reading between the lines
- The reuse mechanism could be combined with adaptive step-size rules that scale with reported uncertainty.
- Kernel choice may need adjustment when the objective exhibits sharp features or noise not captured by the current stationarity assumption.
- The same Gaussian-process construction might apply to gradient estimation in other variational quantum algorithms that rely on parameter shifts.
Load-bearing premise
The VQE objective function is sufficiently smooth and stationary that Gaussian processes with chosen kernels can produce reliable gradient estimates and uncertainty quantification from arbitrary past observation points.
What would settle it
If VQE runs that reuse past observations under Bayesian PSR require the same or greater total evaluations to reach target energies compared with standard PSR, or if gradient estimates from distant points show large systematic deviation from shift-rule values on the same circuit.
Figures







read the original abstract
Parameter shift rules (PSRs) are key techniques for efficient gradient estimation in variational quantum eigensolvers (VQEs). In this paper, we propose its Bayesian variant, where Gaussian processes with appropriate kernels are used to estimate the gradient of the VQE objective. Our Bayesian PSR offers flexible gradient estimation from observations at arbitrary locations with uncertainty information and reduces to the generalized PSR in special cases. In stochastic gradient descent (SGD), the flexibility of Bayesian PSR allows the reuse of observations in previous steps, which accelerates the optimization process. Furthermore, the accessibility to the posterior uncertainty, along with our proposed notion of gradient confident region (GradCoRe), enables us to minimize the observation costs in each SGD step. Our numerical experiments show that the VQE optimization with Bayesian PSR and GradCoRe significantly accelerates SGD and outperforms the state-of-the-art methods, including sequential minimal optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bayesian variant of the parameter shift rule (PSR) for gradient estimation in variational quantum eigensolvers (VQEs). Gaussian processes with chosen kernels are used to estimate gradients from observations at arbitrary locations, providing uncertainty information. The method is claimed to reduce to the generalized PSR in special cases, enable reuse of prior SGD observations to accelerate optimization, and support a gradient confident region (GradCoRe) concept to reduce per-step observation costs. Numerical experiments indicate that the approach accelerates SGD and outperforms state-of-the-art methods including sequential minimal optimization.
Significance. If the GP-based gradient estimates and uncertainty quantification prove reliable for VQE objectives, the approach could meaningfully lower the number of circuit evaluations required during variational optimization by reusing historical data and adaptively controlling new measurements via GradCoRe. The explicit reduction to existing PSR methods and the uncertainty-aware stopping criterion represent potentially useful extensions of classical shift-rule techniques into a Bayesian setting.
major comments (3)
- [§3] The central claim that the Bayesian PSR reduces to the generalized PSR in special cases (abstract and §3) depends on the GP posterior mean recovering the exact shift-rule expression. The manuscript must specify the kernel family, noise model, and limiting procedure under which this equivalence holds exactly; without an explicit derivation or theorem showing the posterior mean matches the finite-difference form of the generalized PSR, the reduction remains unverified.
- [§4 and §5] VQE objective functions are trigonometric polynomials whose frequencies are determined by the circuit and Hamiltonian. The assumption that standard stationary kernels yield accurate gradients and calibrated posterior variances from arbitrarily spaced (including past SGD) observation points is load-bearing for both the reuse claim and GradCoRe. The paper should include a dedicated analysis or diagnostic (e.g., posterior predictive checks or gradient error vs. distance from current θ) demonstrating that kernel misspecification does not produce biased gradients or miscalibrated uncertainties on representative VQE landscapes.
- [§5] Table 2 and Figure 4 report speedups over SMO and standard PSR, but the experiments lack error bars on iteration counts or wall-clock time, details on the number of independent random seeds, and explicit reporting of the total number of circuit evaluations (including those used for GP hyperparameter fitting). Without these, it is impossible to determine whether the reported acceleration is statistically robust or specific to the chosen problem instances.
minor comments (2)
- [§3] Notation for the GP posterior mean and variance should be introduced with explicit dependence on the observation set D_t at each SGD step to clarify how reuse is implemented.
- [§4] The definition of GradCoRe (threshold on posterior variance) is introduced without a sensitivity analysis; a brief ablation on the threshold value would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and will revise the manuscript to strengthen the presentation and add the requested clarifications and diagnostics.
read point-by-point responses
-
Referee: [§3] The central claim that the Bayesian PSR reduces to the generalized PSR in special cases (abstract and §3) depends on the GP posterior mean recovering the exact shift-rule expression. The manuscript must specify the kernel family, noise model, and limiting procedure under which this equivalence holds exactly; without an explicit derivation or theorem showing the posterior mean matches the finite-difference form of the generalized PSR, the reduction remains unverified.
Authors: We agree that an explicit derivation is required. In the revised manuscript we will insert a new theorem in §3 that states the precise conditions: a periodic kernel whose period matches the known frequencies of the VQE objective, homoscedastic Gaussian noise, and the limiting case in which observation locations coincide with the standard shift-rule points while the length-scale parameters are set to the exact frequency values. Under these conditions the GP posterior mean recovers the generalized PSR finite-difference expression exactly; the proof follows by direct substitution of the kernel into the GP mean formula and algebraic simplification to the shift-rule coefficients. revision: yes
-
Referee: [§4 and §5] VQE objective functions are trigonometric polynomials whose frequencies are determined by the circuit and Hamiltonian. The assumption that standard stationary kernels yield accurate gradients and calibrated posterior variances from arbitrarily spaced (including past SGD) observation points is load-bearing for both the reuse claim and GradCoRe. The paper should include a dedicated analysis or diagnostic (e.g., posterior predictive checks or gradient error vs. distance from current θ) demonstrating that kernel misspecification does not produce biased gradients or miscalibrated uncertainties on representative VQE landscapes.
Authors: We accept that a dedicated diagnostic is necessary. The revised §4 will contain a new subsection presenting (i) posterior predictive checks on the VQE landscapes used in the experiments and (ii) plots of gradient error versus Euclidean distance from the current θ, using both newly sampled points and historical SGD observations. These diagnostics will quantify any bias or miscalibration introduced by the chosen kernels on representative trigonometric objectives. revision: yes
-
Referee: [§5] Table 2 and Figure 4 report speedups over SMO and standard PSR, but the experiments lack error bars on iteration counts or wall-clock time, details on the number of independent random seeds, and explicit reporting of the total number of circuit evaluations (including those used for GP hyperparameter fitting). Without these, it is impossible to determine whether the reported acceleration is statistically robust or specific to the chosen problem instances.
Authors: We agree that the experimental reporting must be strengthened. In the revised version we will augment Table 2 and Figure 4 with error bars (standard deviation over runs), state that all metrics are averaged over 20 independent random seeds, and add a supplementary table that breaks down the total circuit evaluations into those used for GP hyperparameter fitting, initial observations, and the SGD steps themselves. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces Bayesian PSR via Gaussian processes for VQE gradients, with the explicit claim that it reduces to generalized PSR in special cases serving as a consistency property rather than a definitional loop. No equations or steps in the provided text show a prediction reducing to a fitted input by construction, no self-citation chains are load-bearing for the central claims, and the reuse/GradCoRe features follow directly from standard GP posterior mechanics applied to the VQE setting. The smoothness/stationarity assumption is stated openly as a modeling choice, not smuggled in. Numerical experiments are presented as external validation. This matches the default expectation of a non-circular proposal grounded in prior PSR literature without self-referential reduction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Bias Analysis and Regularization of Sequential Minimal Optimization in Variational Quantum Eigensolvers
Bias in SMO-VQE can be estimated without extra measurements; a regularization method that mimics error accumulation while preserving unbiased estimates improves performance across system sizes and Hamiltonians.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Abraham, H. et al. Q iskit: A n open-source framework for quantum computing. Zenodo, 2019. doi:10.5281/zenodo.2562111
-
[3]
Acharya, R., Abanin, D. A., et al. Quantum error correction below the surface code threshold. Nature, 2024. doi:10.1038/s41586-024-08449-y
-
[4]
Anders, C. J., Nicoli, K., Wu, B., Elosegui, N., Pedrielli, S., Funcke, L., Jansen, K., Kuhn, S., and Nakajima, S. Adaptive observation cost control for variational quantum eigensolvers. In Proceedings of 41st International Conference on Machine Learning (ICML2024), 2024. doi:10.5555/3692070.3692133
-
[5]
Bluvstein, D., Evered, S. J., Geim, A. A., Li, S. H., Zhou, H., Manovitz, T., Ebadi, S., Cain, M., Kalinowski, M., Hangleiter, D., et al. Logical quantum processor based on reconfigurable atom arrays. Nature, pp.\ 1--3, 2023. doi:10.1038/s41586-023-06927-3
-
[6]
Cai, Z., Babbush, R., Benjamin, S. C., Endo, S., Huggins, W. J., Li, Y., McClean, J. R., and O'Brien, T. E. Quantum error mitigation. Rev. Mod. Phys., 95: 0 045005, Dec 2023. doi:10.1103/RevModPhys.95.045005
-
[7]
Debnath, S., Linke, N. M., Figgatt, C., Landsman, K. A., Wright, K., and Monroe, C. Demonstration of a small programmable quantum computer with atomic qubits. Nature, 536 0 (7614): 0 63--66, 2016. doi:10.1038/nature18648
-
[8]
A Tutorial on Bayesian Optimization
Frazier, P. A tutorial on B ayesian optimization. ArXiv e-prints, 2018. doi:10.48550/arXiv.1807.02811
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1807.02811 2018
-
[9]
Iannelli, G. and Jansen, K. Noisy B ayesian optimization for variational quantum eigensolvers. ArXiv e-prints, 2021. doi:10.48550/arXiv.2112.00426
-
[10]
S., Christiansen, O., Yao, Y.-X., and Lanat\`a, N
Jiang, T., Rogers, J., Frank, M. S., Christiansen, O., Yao, Y.-X., and Lanat\`a, N. Error mitigation in variational quantum eigensolvers using tailored probabilistic machine learning. Phys. Rev. Res., 6: 0 033069, Jul 2024. doi:10.1103/PhysRevResearch.6.033069
-
[11]
Kielpinski, D., Monroe, C., and Wineland, D. J. Architecture for a large-scale ion-trap quantum computer. Nature, 417 0 (6890): 0 709--711, 2002. doi:10.1038/nature00784
-
[12]
S., Sitdikov, I., Salcedo, C., Seif, A., and Minev, Z
Liao, H., Wang, D. S., Sitdikov, I., Salcedo, C., Seif, A., and Minev, Z. K. Machine learning for practical quantum error mitigation. Nature Machine Intelligence, 6 0 (12): 0 1478–1486, November 2024. ISSN 2522-5839. doi:10.1038/s42256-024-00927-2. URL http://dx.doi.org/10.1038/s42256-024-00927-2
-
[13]
R., Romero, J., Babbush, R., et al
McClean, J. R., Romero, J., Babbush, R., et al. The theory of variational hybrid quantum-classical algorithms. New Journal of Physics, 18 0 (2): 0 023023, 2016. doi:10.1088/1367-2630/18/2/023023
-
[14]
Mitarai, K., Negoro, M., Kitagawa, M., et al. Quantum circuit learning. Phys. Rev. A, 98: 0 032309, 2018. doi:10.1103/PhysRevA.98.032309
-
[15]
Nakanishi, K. M., Fujii, K., and Todo, S. Sequential minimal optimization for quantum-classical hybrid algorithms. Phys. Rev. Res., 2: 0 043158, 2020. doi:10.1103/PhysRevResearch.2.043158
-
[16]
Nicoli, K. A., Anders, C. J., Funcke, L., Hartung, T., Jansen, K., Kuhn, S., M \"u ller, K.-R., Stornati, P., Kessel, P., and Nakajima, S. Physics-informed B ayesian optimization of variational quantum circuits. In Advances in Neural Information Processing Systems (NeurIPS2023), 2023 a
work page 2023
-
[17]
Nicoli, K. A., Anders, C. J., et al. EMICoRe : E xpected maximum improvement over confident regions. https://github.com/emicore/emicore, 2023 b
work page 2023
-
[18]
Nicoli, K. A., Wagner, L., and Funcke, L. Machine-learning-enhanced optimization of noise-resilient variational quantum eigensolvers. ArXiv e-prints, 2025. doi:10.48550/arXiv.2501.17689
-
[19]
A variational eigenvalue solver on a photonic quantum processor
Peruzzo, A., McClean, J., Shadbolt, P., et al. A variational eigenvalue solver on a photonic quantum processor. Nature Communications, 5 0 (1): 0 4213, 2014. doi:10.1038/ncomms5213
-
[20]
Sequential minimal optimization : A fast algorithm for training support vector machines
Platt, J. Sequential minimal optimization : A fast algorithm for training support vector machines. Microsoft Research Technical Report, 1998
work page 1998
-
[21]
Quantum computing in the NISQ era and beyond
Preskill, J. Quantum computing in the NISQ era and beyond. Quantum , 2: 0 79, August 2018. doi:10.22331/q-2018-08-06-79
work page internal anchor Pith review doi:10.22331/q-2018-08-06-79 2018
-
[22]
Rasmussen, C. E. and Williams, C. K. I. G aussian Processes for Machine Learning . MIT Press, Cambridge, MA, USA, 2006. doi:10.7551/mitpress/3206.001.0001
-
[23]
Quantum error correction: A n introductory guide
Roffe, J. Quantum error correction: A n introductory guide. Contemporary Physics, 60 0 (3): 0 226--245, 2019. doi:10.1080/00107514.2019.1667078
-
[24]
Principles of Mathematical Analysis
Rudin, W. Principles of Mathematical Analysis. McGraw-Hill, 1964. doi:10.1017/S0013091500008889
-
[25]
Tamiya, S. and Yamasaki, H. Stochastic gradient line B ayesian optimization for efficient noise-robust optimization of parameterized quantum circuits. npj Quantum Information, 8 0 (1): 0 90, 2022. doi:10.1038/s41534-022-00592-6
-
[26]
The variational quantum eigensolver: A review of methods and best practices
Tilly, J., Chen, H., Cao, S., et al. The variational quantum eigensolver: A review of methods and best practices. Physics Reports, 986: 0 1--128, 2022. doi:https://doi.org/10.1016/j.physrep.2022.08.003
-
[27]
Wierichs, D., Izaac, J., Wang, C., and Lin, C. Y.-Y. General parameter-shift rules for quantum gradients. Quantum , 6: 0 677, March 2022. ISSN 2521-327X. doi:10.22331/q-2022-03-30-677
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.