Online Covariance Matrix Estimation in Sketched Newton Methods
Pith reviewed 2026-05-23 03:10 UTC · model grok-4.3
The pith
A covariance estimator built solely from sketched Newton iterates enables consistent online statistical inference without data batches or matrix factorizations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
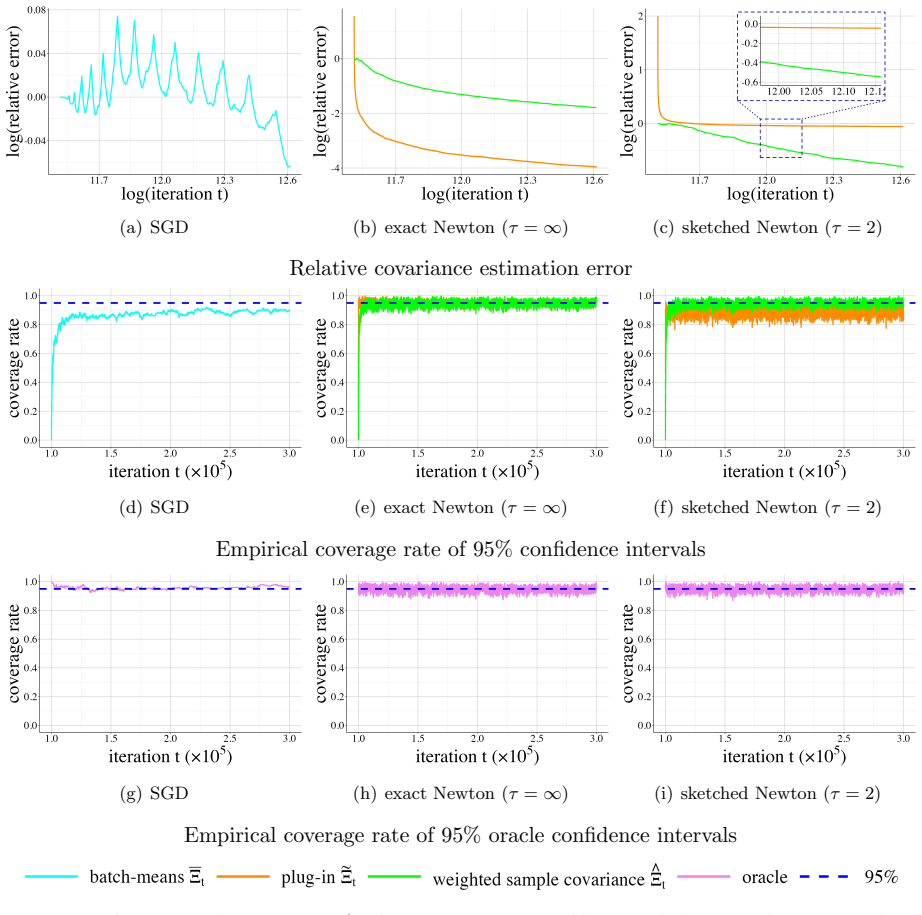
The paper introduces a fully online covariance matrix estimator constructed entirely from the Newton iterates of a sketched Newton method. This estimator requires no matrix factorization and operates without retaining data batches. Consistency and a convergence rate are established for the estimator. Paired with prior asymptotic normality results for the iterates, the estimator supports online statistical inference for model parameters. The approach extends to constrained optimization and shows strong empirical performance on regression tasks and CUTEst benchmarks.
What carries the argument
Fully online covariance matrix estimator assembled from sketched Newton iterates without factorization or batch retention.
If this is right
- The estimator achieves consistency and a stated convergence rate when built from the iterates alone.
- Asymptotic normality of the sketched Newton iterates can be paired with the estimator to produce online confidence intervals and hypothesis tests for parameters.
- The same construction applies to constrained problems by suitable modification of the iterate sequence.
- Empirical tests on regression problems and the CUTEst collection show better performance than existing alternatives.
Where Pith is reading between the lines
- The batch-free property may allow second-order online methods to be used for real-time uncertainty quantification on very large or non-stationary streams where storing data is impossible.
- The construction could be combined with adaptive sketching strategies that change dimension over time without restarting the covariance estimate.
- If the iterates converge to a stationary point, the estimator may also supply online estimates of the Hessian or information matrix for use in model selection criteria.
Load-bearing premise
The sequence of sketched Newton iterates by itself carries enough information to produce a consistent estimator of the limiting covariance matrix.
What would settle it
Generate streaming data from a known quadratic model, run the sketched Newton method, apply the proposed estimator, and check whether the estimated covariance converges in norm to the true limiting covariance as the number of iterates grows.
Figures

read the original abstract
Given the ubiquity of streaming data, online algorithms have been widely used for parameter estimation, with second-order methods particularly standing out for their efficiency and robustness. In this paper, we study an online sketched Newton method that leverages a randomized sketching technique to perform an approximate Newton step in each iteration, thereby eliminating the computational bottleneck of second-order methods. While existing studies have established the asymptotic normality of sketched Newton methods, a consistent estimator of the limiting covariance matrix remains an open problem. We propose a fully online covariance matrix estimator that is constructed entirely from the Newton iterates and requires no matrix factorization. Compared to covariance estimators for first-order online methods, our estimator for second-order methods is batch-free. We establish the consistency and convergence rate of our estimator, and coupled with asymptotic normality results, we can then perform online statistical inference for the model parameters based on sketched Newton methods. We also discuss the extension of our estimator to constrained problems, and demonstrate its superior performance on regression problems as well as benchmark problems in the CUTEst set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a fully online covariance matrix estimator for sketched Newton methods, constructed solely from the sequence of Newton iterates without data batches or matrix factorizations. It claims to prove consistency and a convergence rate for this estimator, which when combined with existing asymptotic normality results enables online statistical inference for model parameters. The work also extends the estimator to constrained problems and reports superior empirical performance on regression tasks and CUTEst benchmark problems.
Significance. If the central claims hold, the result fills a noted gap in online second-order methods by delivering a batch-free covariance estimator that supports inference in streaming settings. This is a meaningful practical advance over first-order online covariance estimators, as it leverages the structure of sketched Newton iterates directly. The combination of consistency, rate results, and empirical demonstrations on standard benchmarks strengthens the contribution for large-scale optimization and statistical applications.
minor comments (3)
- The abstract and introduction reference the consistency proof and convergence rate but do not cite the specific theorem or section numbers where these results appear, making it harder for readers to locate the key derivations.
- Notation for the sketched Newton iterates and the covariance estimator could be introduced with a short table or explicit list of symbols in §2 to improve readability before the main theorems.
- The empirical section would benefit from reporting the number of independent runs and standard errors for the performance metrics on the CUTEst problems to allow clearer assessment of variability.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the paper's focus on a batch-free online covariance estimator for sketched Newton methods, its consistency proof, and empirical results on regression and CUTEst problems.
Circularity Check
No significant circularity detected
full rationale
The paper proposes an estimator built directly from the sequence of sketched Newton iterates and separately establishes its consistency and convergence rate. Asymptotic normality is invoked from existing external studies rather than derived internally. No self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or argument structure. The central claim remains independent of its own outputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sketched Newton methods exhibit asymptotic normality with a well-defined limiting covariance matrix.
Forward citations
Cited by 2 Pith papers
-
Higher-Order Equilibrium Tracking for EM-Compressible Online Estimation
Higher-order equilibrium tracking lets online EM estimators inherit batch central limit theorems and risk constants under EM-compressibility conditions.
-
Refining Covariance Matrix Estimation in Stochastic Gradient Descent Through Bias Reduction
A novel bias-reduced online covariance estimator for SGD achieves convergence rate n to the power (α-1)/2 times square root of log n without second-order derivatives.
Reference graph
Works this paper leans on
-
[1]
H. Chen, W. Lu, and R. Song. Statistical inference for online decision making via stochastic gradient descent. Journal of the American Statistical Association , 116(534):708–719, 2020a. X. Chen, J. D. Lee, X. T. Tong, and Y. Zhang. Statistical inference for model parameters in stochastic gradient descent. The Annals of Statistics , 48(1):251 – 273, 2020b....
work page 1923
-
[2]
P. C´ enac, A. Godichon-Baggioni, and B. Portier. An efficient averaged stochastic gauss-newton algo- rithm for estimating parameters of non linear regressions models. arXiv preprint arXiv:2006.12920,
-
[3]
D. Kovalev, K. Mishchenko, and P. Richt´ arik. Stochastic newton and cubic newton methods with simple local linear-quadratic rates. arXiv preprint arXiv:1912.01597 ,
- [4]
- [5]
-
[6]
R. Liu, X. Chen, and Z. Shang. Statistical inference with stochastic gradient methods under ϕ-mixing data. arXiv preprint arXiv:2302.12717 , 2023a. W. Liu, J. Tu, Y. Zhang, and X. Chen. Online estimation and inference for robust policy evaluation in reinforcement learning. arXiv preprint arXiv:2310.02581 , 2023b. L. Ljung. Analysis of recursive stochastic...
- [7]
- [8]
- [9]
- [10]
-
[11]
Online Bootstrap Inference with Noncon- vex Stochastic Gradient Descent Estimator
Y. Zhong, T. Kuffner, and S. Lahiri. Online bootstrap inference with nonconvex stochastic gradient descent estimator. arXiv preprint arXiv:2306.02205 ,
- [12]
- [13]
-
[14]
A Online Update of bΞ−1 t We introduce how to online updatebΞ−1 t for constructing the confidence region in Corollary 4.4. By the definition of bΞt in (21), we have bΞt+1 (21) = 1 t + 1 t+1X i=1 1 φi−1 (xi − ¯xt+1)(xi − ¯xt+1)T = 1 t + 1 tX i=1 1 φi−1 (xi − ¯xt+1)(xi − ¯xt+1)T + 1/φt t + 1(xt+1 − ¯xt+1)(xt+1 − ¯xt+1)T = t t + 1 1 t tX i=1 1 φi−1 (xi − ¯xt...
work page 2022
-
[15]
For any l ≥ 1, ifPl k=1 σk/2+ ϕ/eφ > 0, then we have tY i=0 lY k=1 |1 − ηiσk| + tX i=0 tY j=i+1 lY k=1 |1 − ηjσk|φiϕi ≲ 1Pl k=1 σk/2 + ϕ/eφ · ϕt. 1In fact, ϕ < 0 is only required by Lemma B.3(b) in Na and Mahoney (2022), and the statements in Lemma B.3(a) hold for any constant ϕ. 23 Lemma B.5. For the t-th iteration, let us define two sketching matrices e...
work page 2022
-
[16]
(C.1) We first calculate the rate of the term in the curly bracket in II
Thus, Lemma B.2 holds and its proof (Na and Mahoney, 2022, (C.1)) suggests the following decomposition 1 ϕt tX i=0 tY j=i+1 lY k=1 (1 − φjσk) φiϕi − 1Pl k=1 σk = 1 ϕt tY j=1 lY k=1 (1 − φjσk) · ϕ0 φ0 − 1Pl k=1 σk + 1 ϕt tX i=1 tY j=i+1 lY k=1 (1 − φjσk)ϕi φi − 1Pl k=1 σk 1 − ϕi−1 ϕi lY k=1 (1 − φiσk) =: I + II. (C.1) We first calculate the rate of the ter...
work page 2022
-
[17]
≥ β, there exists a fixed integer t0 such that 2C1/4 g,1 γ2 H χt + 8ΥH C1/2 g,1 γ4 H η2 t ≤ 1 4ΥH βt for all t ≥ t0. Thus, for t ≥ t0, we have E[Ft+1 − F ⋆ | F t−1] ≤ Ft − F ⋆ − 1 4ΥH βt∥∇Ft∥2 + 4ΥH C1/2 g,2 γ2 H χ2 t βt + η2 t . Note thatP∞ t=t0 χ2 t /βt < ∞ andP∞ t=t0 η2 t ≲P∞ t=t0 β2 t +P∞ t=t0 χ2 t < ∞. Thus, we apply the Robbins- Siegmund Theorem (Du...
work page 2013
-
[18]
Again, we apply (D.6) and obtain lim t→∞ xt = x⋆ almost surely. This completes the proof. D.2 Proof of Theorem 3.6 The proof of asymptotic normality is almost identical to the proof of Theorem 5.6 in Na and Mahoney (2022). Since χ > 1.5β ⇒ χ > 0.5(β + 1), we have xt → x⋆ almost surely, as proved in Theorem 3.5. Therefore, we only have to note that our gro...
work page 2022
-
[19]
This suggests that (B.1) also holds. Now, we apply Lemma B.4 and obtain E ∥xt − x⋆∥4 (D.6) ≲ 1 γ2 H E (Ft − F ⋆)2 ≲ 1 γ2 H · ΥH γH Υ5 H Cg,2 γ7 H · χ4 t β4 t + Υ3 H Cg,2 γ5 H · η3 t βt (E.7) ≲ Υ4 H Cg,2 γ8 H β2 t + Υ6 H Cg,2 γ10 H · χ4 t β4 t = O β2 t + χ4 t β4 t . Part 2: Bound of E[∥Bt − B⋆∥4]. By the construction of Bt in (7), we have E ∥Bt − B⋆∥4 ≲ E ...
work page 2008
-
[20]
Thus, we combine the above two displays and have 1 t2 Υ4 H Cg,2CH,1 γ8 H 1 t t−1X i=0 βi 2 + Υ6 H Cg,2CH,1 γ10 H 1 t t−1X i=0 χ2 i β2 i 2 = o 1 t2 and E 1 t t−1X i=0 ( ¯Hi − ∇2Fi) 4 ≲ CH,2 t2 . (E.10) 31 For the second term on the right hand side in (E.8), the Υ L-Lipschitz continuity of ∇2F (x) leads to E 1 t t−1X i=0 (∇2Fi − ∇2F ⋆) 4 ≤ E 1 t t−1X i=0 ∥∇...
work page 2022
-
[21]
Therefore, we conclude that |I4| ≲ ∥Λ∥2 F (1 − ρτ)3 · 1 tβt
The analysis of I4 is almost identical to I3, only with the expectation term being replaced by X p,q E h U Teθk1eθkT 1 U p,q U Teθk2eθkT 2 U p,q i = X p,q Γ2 p,q = ∥Γ∥2 F = ∥Λ∥2 F when k1 ̸= k2. Therefore, we conclude that |I4| ≲ ∥Λ∥2 F (1 − ρτ)3 · 1 tβt . Combining the analyses of four terms, we obtain |I| ≤ 4X i=1 |Ii| ≲ max(∥Λ∥2 F , Cg,2/γ4 H) (1 − ρτ)...
work page 2022
-
[22]
Then, we have E 1 t tX i=1 1 φi−1 (¯xt − x⋆)(¯xt − x⋆)T ≤ 1 t t−1X i=0 1 φi−1 E ∥¯xt − x⋆∥2 ≲ ( βt + χ2 t /β3 t , β ∈ (0, 0.5], 1/tβt + χ2 t /β3 t , β ∈ (0.5, 1). By the decomposition (E.44), we follow the derivations in (E.25) and (E.26) and obtain E ∥bΞt − Ξ⋆∥ ≤ E 1 t tX i=1 1 φi−1 (xi − x⋆)(xi − x⋆)T − Ξ⋆ + E 1 t tX i=1 1 φi−1 (¯xt − x⋆)(¯xt − x⋆)T + 2...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.