In-depth Analysis of Graph-based RAG in a Unified Framework
Pith reviewed 2026-05-23 01:33 UTC · model grok-4.3
The pith
A single framework unifies graph-based RAG methods and shows that simple recombinations of their parts beat prior leaders on both concrete and abstract QA tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By embedding all graph-based RAG methods in one shared framework the authors run controlled experiments across QA datasets that move from specific to abstract questions; the results identify new variants obtained simply by recombining existing techniques, and these variants outperform the prior state-of-the-art on the specific-question tasks and on the abstract-question tasks respectively.
What carries the argument
The unified high-level framework that incorporates every graph-based RAG method under a common structure for direct comparison.
If this is right
- Direct head-to-head testing reveals which graph components help most on concrete versus abstract questions.
- New variants formed by recombining existing techniques set higher performance marks on specific QA tasks.
- New variants formed by recombining existing techniques set higher performance marks on abstract QA tasks.
- The analysis points to concrete directions for future work on graph-based knowledge integration with LLMs.
Where Pith is reading between the lines
- The same framework could be used to test whether the same recombinations improve performance on tasks beyond QA, such as summarization or dialogue.
- Practitioners could adopt the top-performing variants immediately while waiting for entirely new architectures.
- The framework makes it easier to diagnose why one method succeeds where another fails by swapping individual modules.
Load-bearing premise
The chosen representative methods and QA datasets inside the unified framework produce a comparison that fairly represents the broader space of graph-based RAG approaches.
What would settle it
A follow-up experiment on a fresh collection of QA datasets or additional graph RAG methods in which none of the identified new variants exceeds the previous best scores.
Figures













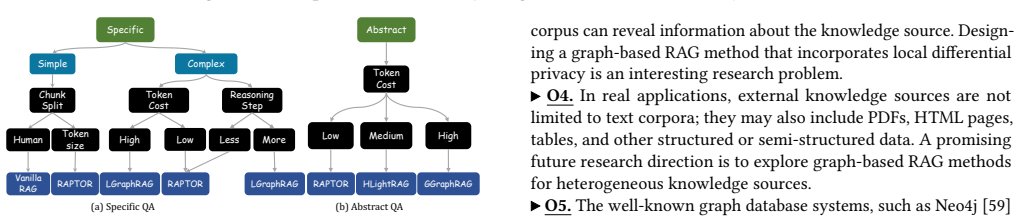
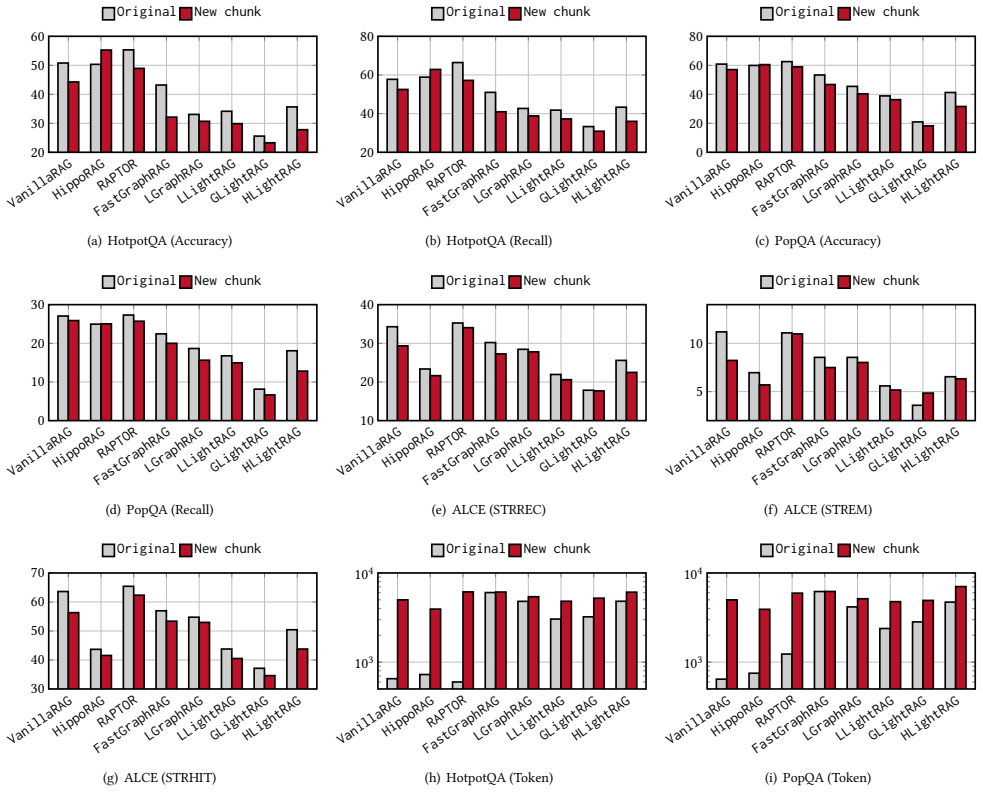




read the original abstract
Graph-based Retrieval-Augmented Generation (RAG) has proven effective in integrating external knowledge into large language models (LLMs), improving their factual accuracy, adaptability, interpretability, and trustworthiness. A number of graph-based RAG methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework to incorporate all graph-based RAG methods from a high-level perspective. We then extensively compare representative graph-based RAG methods over a range of questing-answering (QA) datasets -- from specific questions to abstract questions -- and examine the effectiveness of all methods, providing a thorough analysis of graph-based RAG approaches. As a byproduct of our experimental analysis, we are also able to identify new variants of the graph-based RAG methods over specific QA and abstract QA tasks respectively, by combining existing techniques, which outperform the state-of-the-art methods. Finally, based on these findings, we offer promising research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide new valuable insights for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified high-level framework that encompasses existing graph-based RAG methods. It performs extensive empirical comparisons of representative methods across QA datasets spanning specific to abstract questions, analyzes their effectiveness, identifies new variants obtained by combining existing techniques that outperform prior SOTA on specific and abstract QA tasks respectively, and outlines promising research directions based on the findings.
Significance. A sound unified framework and controlled comparison could help standardize evaluation practices in graph-based RAG and surface practically useful combinations. The byproduct identification of outperforming variants would be a concrete contribution if the selection process is shown to be systematic rather than selective.
major comments (2)
- [Experimental analysis] Experimental analysis section: the claim that new variants 'outperform the state-of-the-art' on specific and abstract QA tasks is load-bearing for the central contribution, yet the manuscript provides no description of the total search space size, whether the combination search was pre-specified, the number of combinations evaluated, or any correction for multiple testing. The 'byproduct' phrasing increases the risk that only successful combinations are highlighted.
- [Unified framework] Unified framework section: it is unclear whether the framework definition introduces any implicit bias in how representative methods are instantiated or whether all methods are placed on equal footing with respect to hyper-parameter tuning budgets and retrieval settings; this directly affects the fairness of the reported outperformance.
minor comments (2)
- [Abstract] The abstract states that 'extensive comparisons were performed' without referencing dataset splits, statistical significance tests, or variance across runs; these details belong in the main experimental protocol.
- [Notation] Notation for graph construction and retrieval operators should be made consistent between the framework description and the experimental tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to enhance transparency and rigor.
read point-by-point responses
-
Referee: [Experimental analysis] Experimental analysis section: the claim that new variants 'outperform the state-of-the-art' on specific and abstract QA tasks is load-bearing for the central contribution, yet the manuscript provides no description of the total search space size, whether the combination search was pre-specified, the number of combinations evaluated, or any correction for multiple testing. The 'byproduct' phrasing increases the risk that only successful combinations are highlighted.
Authors: We agree that the current description lacks sufficient detail on the combination process. The variants were not the result of an exhaustive or pre-specified combinatorial search but were instead derived from targeted, hypothesis-driven recombinations of components identified during our comparative analysis of the unified framework. We will revise the experimental analysis section to explicitly state the rationale, approximate number of combinations explored (approximately two dozen component swaps across the main methods), and the absence of multiple-testing corrections, as the process was exploratory rather than statistical. We will also replace the 'byproduct' phrasing with language that better reflects the systematic, insight-guided nature of the exploration. revision: yes
-
Referee: [Unified framework] Unified framework section: it is unclear whether the framework definition introduces any implicit bias in how representative methods are instantiated or whether all methods are placed on equal footing with respect to hyper-parameter tuning budgets and retrieval settings; this directly affects the fairness of the reported outperformance.
Authors: The framework is intentionally high-level and component-based to avoid favoring any particular method. All representative methods were instantiated using the same retrieval pipeline (identical embedding model, vector index, and top-k setting) and the same LLM backbone. Hyper-parameters for each method were tuned independently on a held-out validation split to their best achievable performance under a uniform computational budget. We will add a dedicated paragraph in the unified framework and experimental setup sections to document this protocol and confirm that no implicit bias was introduced by the framework definition. revision: yes
Circularity Check
No circularity: purely empirical benchmarking and combination search
full rationale
The paper summarizes an existing unified framework for graph-based RAG methods, performs extensive empirical comparisons across QA datasets, and reports new variants found by combining techniques that outperform baselines on the tested tasks. No derivations, first-principles predictions, fitted parameters renamed as predictions, or load-bearing self-citations are present. The outperformance claim rests on experimental results rather than any reduction to inputs by construction. This matches the default case of a self-contained empirical study with score 0.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 4 Pith papers
-
H-Mem: A Novel Memory Mechanism for Evolving and Retrieving Agent Memory via a Hybrid Structure
H-Mem introduces a hybrid tree-plus-graph memory mechanism that evolves short-term agent memories into long-term summaries and enables efficient retrieval, reporting state-of-the-art QA results on three benchmarks.
-
ASTRA-QA: A Benchmark for Abstract Question Answering over Documents
ASTRA-QA is a benchmark for abstract document question answering that uses explicit topic sets, unsupported content annotations, and evidence alignments to enable direct scoring of coverage and hallucination.
-
SkillRAE: Agent Skill-Based Context Compilation for Retrieval-Augmented Execution
SkillRAE organizes skills into a graph and compiles compact, grounded contexts for LLM agents, yielding 11.7% gains on SkillsBench over prior RAE methods.
-
EvoRAG: Making Knowledge Graph-based RAG Automatically Evolve through Feedback-driven Backpropagation
EvoRAG adds a feedback-driven backpropagation step that attributes response quality to individual knowledge-graph triplets and updates the graph to raise reasoning accuracy by 7.34 percent over prior KG-RAG methods.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi
-
[4]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Self-rag: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [5]
- [6]
-
[7]
Sibei Chen, Yeye He, Weiwei Cui, Ju Fan, Song Ge, Haidong Zhang, Dongmei Zhang, and Surajit Chaudhuri. 2024. Auto-Formula: Recommend Formulas in Spreadsheets using Contrastive Learning for Table Representations. Proceedings of the ACM on Management of Data 2, 3 (2024), 1–27
work page 2024
-
[8]
Sibei Chen, Nan Tang, Ju Fan, Xuemi Yan, Chengliang Chai, Guoliang Li, and Xi- aoyong Du. 2023. Haipipe: Combining human-generated and machine-generated pipelines for data preparation. Proceedings of the ACM on Management of Data 1, 1 (2023), 1–26
work page 2023
-
[9]
Zui Chen, Lei Cao, Sam Madden, Tim Kraska, Zeyuan Shang, Ju Fan, Nan Tang, Zihui Gu, Chunwei Liu, and Michael Cafarella. 2023. SEED: Domain-Specific Data Curation With Large Language Models. arXiv e-prints (2023), arXiv–2310
work page 2023
-
[10]
Jacob Devlin. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Tianyu Liu, et al. 2022. A survey on in-context learning. arXiv preprint arXiv:2301.00234 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Ju Fan, Zihui Gu, Songyue Zhang, Yuxin Zhang, Zui Chen, Lei Cao, Guoliang Li, Samuel Madden, Xiaoyong Du, and Nan Tang. 2024. Combining small language models and large language models for zero-shot nl2sql. Proceedings of the VLDB Endowment 17, 11 (2024), 2750–2763
work page 2024
-
[15]
Meihao Fan, Xiaoyue Han, Ju Fan, Chengliang Chai, Nan Tang, Guoliang Li, and Xiaoyong Du. 2024. Cost-effective in-context learning for entity resolution: A design space exploration. In 2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 3696–3709
work page 2024
-
[16]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining . 6491–6501
work page 2024
-
[17]
FastGraphRAG. 2024. FastGraphRAG. https://github.com/circlemind-ai/fast- graphrag
work page 2024
- [18]
-
[19]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [20]
- [21]
-
[22]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2024. LightRAG: Simple and Fast Retrieval-Augmented Generation. arXiv e-prints (2024), arXiv– 2410
work page 2024
-
[23]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[24]
J.; Shu, Y.; Gu, Y.; Yasunaga, M.; and Su, Y
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. arXiv preprint arXiv:2405.14831 (2024)
-
[25]
Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Ma- hantesh Halappanavar, Ryan A Rossi, Subhabrata Mukherjee, Xianfeng Tang, et al. 2024. Retrieval-augmented generation with graphs (graphrag). arXiv preprint arXiv:2501.00309 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Jiawei Han, Jian Pei, and Hanghang Tong. 2022. Data mining: concepts and techniques. Morgan kaufmann
work page 2022
-
[27]
Taher H Haveliwala. 2002. Topic-sensitive pagerank. In Proceedings of the 11th international conference on World Wide Web. 517–526
work page 2002
- [28]
- [29]
-
[30]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Hao- tian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al
-
[31]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Yizheng Huang and Jimmy Huang. 2024. A Survey on Retrieval-Augmented Text Generation for Large Language Models. arXiv preprint arXiv:2404.10981 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [33]
-
[34]
huawei. 2019. Ascend GPU. https://e.huawei.com/ph/products/computing/ ascend
work page 2019
-
[35]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park
-
[36]
Adaptive-rag: Learning to adapt retrieval-augmented large language mod- els through question complexity. arXiv preprint arXiv:2403.14403 (2024)
-
[37]
Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Wayne Xin Zhao, and Ji-Rong Wen. 2023. StructGPT: A General Framework for Large Language Model to Reason over Structured Data. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing . 9237–9251
work page 2023
-
[38]
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. 2023. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Omar Khattab and Matei Zaharia. 2020. Colbert: Efficient and effective passage search via contextualized late interaction over bert. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 39–48
work page 2020
-
[40]
Langchian. 2023. Langchian. https://python.langchain.com/docs/additional_ resources/arxiv_references/
work page 2023
-
[41]
Jiale Lao, Yibo Wang, Yufei Li, Jianping Wang, Yunjia Zhang, Zhiyuan Cheng, Wanghu Chen, Mingjie Tang, and Jianguo Wang. 2024. Gptuner: A manual- reading database tuning system via gpt-guided bayesian optimization. Proceed- ings of the VLDB Endowment 17, 8 (2024), 1939–1952
work page 2024
- [42]
-
[43]
Dawei Li, Shu Yang, Zhen Tan, Jae Young Baik, Sukwon Yun, Joseph Lee, Aaron Chacko, Bojian Hou, Duy Duong-Tran, Ying Ding, et al. 2024. DALK: Dynamic Co-Augmentation of LLMs and KG to answer Alzheimer’s Disease Questions with Scientific Literature. arXiv preprint arXiv:2405.04819 (2024)
- [44]
-
[45]
Yinheng Li, Shaofei Wang, Han Ding, and Hang Chen. 2023. Large language models in finance: A survey. In Proceedings of the fourth ACM international conference on AI in finance . 374–382
work page 2023
- [46]
-
[47]
Zhaodonghui Li, Haitao Yuan, Huiming Wang, Gao Cong, and Lidong Bing. 2025. LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency. Proceedings of the VLDB Endowment 1, 18 (2025), 53–65
work page 2025
- [48]
- [49]
- [50]
-
[51]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baille Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, and Gerardo Vitagliano
-
[52]
arXiv preprint arXiv:2405.14696 (2024)
A Declarative System for Optimizing AI Workloads. arXiv preprint arXiv:2405.14696 (2024). 14
- [53]
- [54]
-
[55]
llamaindex. 2023. llamaindex. https://www.llamaindex.ai/
work page 2023
- [56]
-
[57]
Yu A Malkov and Dmitry A Yashunin. 2018. Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs. IEEE transactions on pattern analysis and machine intelligence 42, 4 (2018), 824–836
work page 2018
-
[58]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2022. When not to trust language models: Investigat- ing effectiveness of parametric and non-parametric memories. arXiv preprint arXiv:2212.10511 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [59]
-
[60]
Multi-Linguality Multi-Functionality Multi-Granularity. 2024. M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. (2024)
work page 2024
-
[61]
Zan Ahmad Naeem, Mohammad Shahmeer Ahmad, Mohamed Eltabakh, Mourad Ouzzani, and Nan Tang. 2024. RetClean: Retrieval-Based Data Cleaning Using LLMs and Data Lakes. Proceedings of the VLDB Endowment 17, 12 (2024), 4421– 4424
work page 2024
-
[62]
Avanika Narayan, Ines Chami, Laurel Orr, and Christopher Ré. 2022. Can Foun- dation Models Wrangle Your Data? Proceedings of the VLDB Endowment 16, 4 (2022), 738–746
work page 2022
-
[63]
nebula. 2010. nebula. https://www.nebula-graph.io/
work page 2010
-
[64]
neo4j. 2006. neo4j. https://neo4j.com/
work page 2006
- [65]
-
[66]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems 35 (2022), 27730–27744
work page 2022
-
[67]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, et al
- [68]
- [69]
- [70]
- [71]
-
[72]
Yichen Qian, Yongyi He, Rong Zhu, Jintao Huang, Zhijian Ma, Haibin Wang, Yaohua Wang, Xiuyu Sun, Defu Lian, Bolin Ding, et al. 2024. UniDM: A Unified Framework for Data Manipulation with Large Language Models. Proceedings of Machine Learning and Systems 6 (2024), 465–482
work page 2024
-
[73]
The Technique Report. 2025. In-depth Analysis of Graph-based RAG in a Unified Framework (technical report). https://github.com/JayLZhou/GraphRAG/blob/ master/VLDB2025_GraphRAG.pdf
work page 2025
-
[74]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. Raptor: Recursive abstractive processing for tree-organized retrieval. arXiv preprint arXiv:2401.18059 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2024. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
-
[76]
Vikramank Singh, Kapil Eknath Vaidya, Vinayshekhar Bannihatti Kumar, Sopan Khosla, Murali Narayanaswamy, Rashmi Gangadharaiah, and Tim Kraska. 2024. Panda: Performance debugging for databases using LLM agents. (2024)
work page 2024
-
[77]
Shamane Siriwardhana, Rivindu Weerasekera, Elliott Wen, Tharindu Kalu- arachchi, Rajib Rana, and Suranga Nanayakkara. 2023. Improving the domain adaptation of retrieval augmented generation (RAG) models for open domain question answering. Transactions of the Association for Computational Linguistics 11 (2023), 1–17
work page 2023
-
[78]
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. 2024. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. In The Twelfth International Conference on Learning Representations
work page 2024
- [79]
-
[80]
Yixuan Tang and Yi Yang. 2024. Multihop-rag: Benchmarking retrieval- augmented generation for multi-hop queries. arXiv preprint arXiv:2401.15391 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.