ACE: A Security Architecture for LLM-Integrated App Systems
Pith reviewed 2026-05-22 17:59 UTC · model grok-4.3
The pith
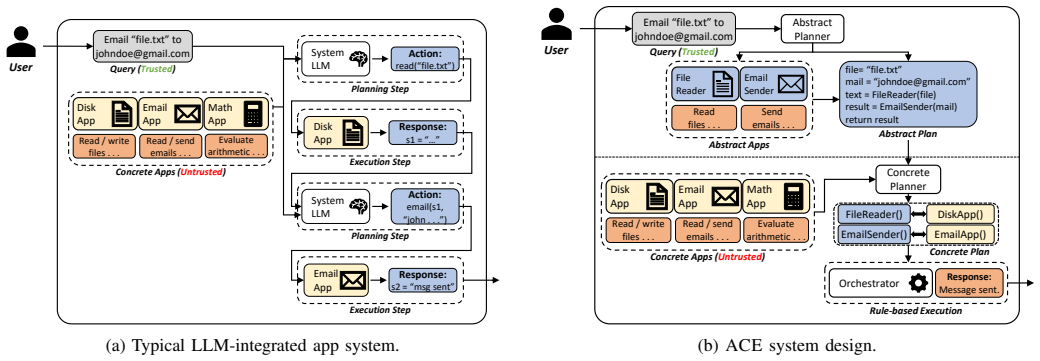
ACE secures LLM-integrated app systems by creating a trusted abstract plan first, verifying it statically, then mapping to concrete apps with enforced barriers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ACE provides security guarantees for system planning and execution by decoupling planning into abstract and concrete phases, verifying plans via static analysis on structured output, and enforcing data and capability barriers during execution according to the trusted abstract plan.
What carries the argument
Decoupling planning into an abstract phase that uses only trusted information and a concrete phase that maps to installed apps, followed by static analysis on the structured plan and runtime enforcement of the abstract plan through data and capability barriers.
If this is right
- LLM-integrated systems resist indirect prompt injection attacks from the InjecAgent and Agent Security Bench benchmarks plus the paper's new attacks.
- User-specified secure information flow constraints are checked automatically on every plan before execution begins.
- Execution integrity and availability are preserved even when individual third-party apps are malicious.
- Privacy is maintained because data access is limited to what the verified abstract plan explicitly permits.
Where Pith is reading between the lines
- The same abstract-to-concrete split could be tested in non-app LLM agents that call external APIs or databases.
- Combining this with capability-based operating systems might further limit what concrete steps an app can actually perform.
- Developers could measure how often the static analysis rejects plans in everyday use to quantify the overhead of the added checks.
Load-bearing premise
An abstract plan created from trusted information can be mapped to a concrete plan using installed apps without introducing new integrity or privacy violations that the subsequent static analysis would miss.
What would settle it
An experiment in which a malicious app alters the concrete plan to perform an unauthorized action that still passes static analysis and executes without violating the abstract plan's recorded constraints.
Figures










read the original abstract
LLM-integrated app systems extend the utility of Large Language Models (LLMs) with third-party apps that are invoked by a system LLM using interleaved planning and execution phases to answer user queries. These systems introduce new attack vectors where malicious apps can cause integrity violation of planning or execution, availability breakdown, or privacy compromise during execution. In this work, we identify new attacks impacting the integrity of planning, as well as the integrity and availability of execution in LLM-integrated apps, and demonstrate them against IsolateGPT, a recent solution designed to mitigate attacks from malicious apps. We propose Abstract-Concrete-Execute (ACE), a new secure architecture for LLM-integrated app systems that provides security guarantees for system planning and execution. Specifically, ACE decouples planning into two phases by first creating an abstract execution plan using only trusted information, and then mapping the abstract plan to a concrete plan using installed system apps. We verify that the plans generated by our system satisfy user-specified secure information flow constraints via static analysis on the structured plan output. During execution, ACE enforces data and capability barriers between apps, and ensures that the execution is conducted according to the trusted abstract plan. We show experimentally that ACE is secure against attacks from the InjecAgent and Agent Security Bench benchmarks for indirect prompt injection, and our newly introduced attacks. We also evaluate the utility of ACE in realistic environments, using the Tool Usage suite from the LangChain benchmark. Our architecture represents a significant advancement towards hardening LLM-based systems using system security principles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies new attacks on LLM-integrated app systems (including against IsolateGPT) that compromise planning integrity, execution integrity/availability, and privacy. It proposes the ACE architecture, which decouples planning into an abstract phase (using only trusted information to produce a structured plan) followed by a concrete mapping phase (binding to installed apps), verifies the resulting plan against user-specified information-flow constraints via static analysis, and enforces data/capability barriers at runtime to ensure execution follows the trusted abstract plan. Experiments are claimed to show security against InjecAgent, Agent Security Bench, and new attacks, plus maintained utility on the LangChain Tool Usage benchmark.
Significance. If the central claims hold, the work would be a meaningful step toward applying established system-security techniques (trusted abstract plans, static verification of structured outputs, and runtime barriers) to LLM-app ecosystems. It directly addresses prompt-injection and malicious-app vectors that current LLM-integrated systems struggle with, and the identification of new attacks plus the concrete architecture could serve as a reference design for future hardened systems.
major comments (2)
- [§4] §4 (Abstract-to-concrete mapping): The central security argument assumes that mapping a trusted abstract plan to a concrete plan via installed apps cannot introduce new integrity or privacy violations that evade the subsequent static analysis on the structured plan representation. Because the mapping step selects and wires real apps (which may be malicious or exhibit side-channel behavior) and static analysis operates only on the final structured output, any data-flow or capability escalation introduced exactly during binding would bypass both the trusted abstract phase and the verifier. The manuscript provides no separate soundness argument, formal model, or invariant showing how app metadata and concrete bindings are represented and checked inside the analysis.
- [§5] §5 (Experimental evaluation): The abstract states that experiments demonstrate security against InjecAgent, Agent Security Bench, and newly introduced attacks plus utility on LangChain Tool Usage, yet the manuscript supplies no quantitative results, success/failure rates, error analysis, or implementation details for the static analyzer or runtime enforcer. Without these data it is impossible to evaluate whether the claimed security properties actually hold or whether the utility overhead is acceptable.
minor comments (2)
- The abstract claims experimental results but contains no numeric metrics; adding a sentence with key security and utility numbers would improve readability.
- [§3] Notation for the abstract plan representation and the information-flow constraints is introduced without a compact formal definition; a small table or grammar would help readers follow the static-analysis claims.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address each of the major comments below and describe the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Abstract-to-concrete mapping): The central security argument assumes that mapping a trusted abstract plan to a concrete plan via installed apps cannot introduce new integrity or privacy violations that evade the subsequent static analysis on the structured plan representation. Because the mapping step selects and wires real apps (which may be malicious or exhibit side-channel behavior) and static analysis operates only on the final structured output, any data-flow or capability escalation introduced exactly during binding would bypass both the trusted abstract phase and the verifier. The manuscript provides no separate soundness argument, formal model, or invariant showing how app metadata and concrete bindings are represented and checked inside the analysis.
Authors: We appreciate the referee highlighting this aspect of our security argument. The ACE architecture performs static analysis on the structured representation of the concrete plan, which incorporates the app selections and bindings from the mapping phase. The abstract plan is generated using only trusted information, and the mapping step is designed to instantiate it without introducing unauthorized flows. However, we acknowledge that the manuscript would benefit from a more explicit soundness argument. In the revised version, we will add a dedicated subsection in §4 that provides a formal invariant: the concrete plan preserves the information-flow properties of the abstract plan, with app metadata checked against declared capabilities. This will include a description of how the plan representation encodes bindings and how the verifier ensures no escalation occurs. revision: yes
-
Referee: [§5] §5 (Experimental evaluation): The abstract states that experiments demonstrate security against InjecAgent, Agent Security Bench, and newly introduced attacks plus utility on LangChain Tool Usage, yet the manuscript supplies no quantitative results, success/failure rates, error analysis, or implementation details for the static analyzer or runtime enforcer. Without these data it is impossible to evaluate whether the claimed security properties actually hold or whether the utility overhead is acceptable.
Authors: We agree that the experimental section requires more detailed quantitative data to support the claims. In the current draft, we present high-level results, but we will substantially revise §5 to include specific metrics such as attack prevention rates (e.g., 0% success for prompt injection attacks under ACE), utility scores on the LangChain benchmark with overhead percentages, error analysis for any false positives in the static analyzer, and implementation details including the static analysis tool used and runtime enforcement mechanisms. We will add tables summarizing these results and discuss any limitations observed. revision: yes
Circularity Check
No circularity: architecture design with external verification
full rationale
The paper proposes ACE as a new security architecture that decouples planning into abstract (trusted) and concrete phases, applies static analysis to the structured plan output for information-flow constraints, and enforces runtime barriers. Security claims rest on this design plus experimental evaluation against InjecAgent, Agent Security Bench, and LangChain Tool Usage benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation of the central guarantees. The architecture is self-contained against external benchmarks and static-analysis checks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Malicious third-party apps can be installed and can attempt integrity, availability, or privacy violations during planning or execution phases.
- domain assumption Static analysis performed on the structured output of the abstract plan can verify user-specified secure information flow constraints.
invented entities (1)
-
Abstract execution plan
no independent evidence
Forward citations
Cited by 8 Pith papers
-
ClawGuard: Out-of-Band Detection of LLM Agent Workflow Hijacking via EM Side Channel
ClawGuard detects LLM agent workflow hijacking by capturing and classifying electromagnetic emanations from hardware with 0.9945 AUC, 100% true-positive rate, and 1.16% false-positive rate on a 7.82 TB RF dataset.
-
ARGUS: Defending LLM Agents Against Context-Aware Prompt Injection
ARGUS defends LLM agents from context-aware prompt injections by tracking information provenance and verifying decisions against trustworthy evidence, reducing attack success to 3.8% while retaining 87.5% task utility.
-
An AI Agent Execution Environment to Safeguard User Data
GAAP guarantees confidentiality of private user data for AI agents by enforcing user-specified permissions deterministically through persistent information flow tracking, without trusting the agent or requiring attack...
-
Parallax: Why AI Agents That Think Must Never Act
Parallax enforces structural separation between AI thinking and acting via independent multi-tier validation, information flow control, and state rollback, blocking 98.9% of 280 adversarial attacks with zero false pos...
-
Security Considerations for Multi-agent Systems
No existing AI security framework covers a majority of the 193 identified multi-agent system threats in any category, with OWASP Agentic Security Initiative achieving the highest overall coverage at 65.3%.
-
Engineering Robustness into Personal Agents with the AI Workflow Store
AI agents should shift from on-the-fly plan synthesis to invoking pre-engineered, tested, and reusable workflows stored in an AI Workflow Store to gain reliability and security.
-
ClawLess: A Security Model of AI Agents
ClawLess introduces a formal fine-grained security model for AI agents with runtime-adaptive policies enforced via user-space kernel and BPF syscall interception.
-
Engineering Robustness into Personal Agents with the AI Workflow Store
AI agents require pre-engineered reusable workflows stored in a central repository rather than generating plans on the fly to achieve production-grade reliability and security.
Reference graph
Works this paper leans on
-
[1]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” 2019
work page 2019
-
[2]
LLaMA: Open and efficient foundation language models,
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” 2023
work page 2023
-
[3]
Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality,
W.-L. Chiang, Z. Li, Z. Lin, Y . Sheng, Z. Wu, H. Zhang, L. Zheng, S. Zhuang, Y . Zhuang, J. E. Gonzalez, I. Stoica, and E. P. Xing, “Vicuna: An open-source chatbot impressing GPT-4 with 90%* ChatGPT quality,” March 2023. [Online]. Available: https://lmsys.org/blog/2023-03-30-vicuna/
work page 2023
-
[4]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023
work page 2023
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, Y . Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth et al., “Gemini: a family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805 , 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Anthropic launches a new ai model that ’thinks’ as long as you want,
M. Zeff, “Anthropic launches a new ai model that ’thinks’ as long as you want,” February 2025
work page 2025
-
[7]
Applications that can reason. powered by LangChain
LangChain, “Applications that can reason. powered by LangChain.” https://www.langchain.com/
-
[8]
Microsoft, “Semantic Kernel documentation. learn to build robust, future-proof AI solutions that evolve with technological advancements.” https://learn.microsoft.com/en-us/semantic-kernel/
-
[9]
AutoGen, an open-source programming framework for agentic AI,
——, “AutoGen, an open-source programming framework for agentic AI,” https://microsoft.github.io/autogen/
-
[10]
InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec @ CCS 2023)
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real- world LLM-integrated applications with indirect prompt injection,” in Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security , ser. AISec ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 79–...
-
[11]
LLM platform security: Applying a systematic evaluation framework to OpenAI’s ChatGPT plugins,
U. Iqbal, T. Kohno, and F. Roesner, “LLM platform security: Applying a systematic evaluation framework to OpenAI’s ChatGPT plugins,” https: //arxiv.org/abs/2309.10254, 2024
-
[12]
F. Wu, E. Cecchetti, and C. Xiao, “System-level defense against indirect prompt injection attacks: An information flow control perspective,”
-
[13]
[Online]. Available: https://arxiv .org/abs/2409.19091
-
[14]
IsolateGPT: An execution isolation architecture for LLM-based agentic systems,
Y . Wu, F. Roesner, T. Kohno, N. Zhang, and U. Iqbal, “IsolateGPT: An execution isolation architecture for LLM-based agentic systems,” in Proceedings of the Network and Distributed System Security Symposium (NDSS). San Diego, California: Internet Society, February 2025
work page 2025
-
[15]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” in Findings of the Association for Computational Linguistics: ACL 2024 , L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 10 471–10 506. [Onl...
work page 2024
-
[16]
Agent security bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents,
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (ASB): Formalizing and benchmarking attacks and defenses in LLM-based agents,” in The Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=V4y0CpX4hK
work page 2025
-
[17]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in The Eleventh International Conference on Learning Representations , 2023. [Online]. Available: https://openreview.net/forum?id=WE vluYUL-X
work page 2023
-
[18]
OpenAI, “Openai embeddings api,” 2024. [Online]. Available: https: //platform.openai.com/docs/guides/embeddings
work page 2024
-
[19]
A lattice model of secure information flow,
D. E. Denning, “A lattice model of secure information flow,” Commun. ACM, vol. 19, no. 5, p. 236–243, May 1976. [Online]. Available: https://doi.org/10.1145/360051.360056
-
[20]
Struq: Defending against prompt injection with structured queries
S. Chen, J. Piet, C. Sitawarin, and D. Wagner, “StruQ: Defend- ing against prompt injection with structured queries,” arXiv preprint arXiv:2402.06363, 2024
-
[21]
LangChain AI, “Langchain benchmarks,” https://langchain-ai .lang.chat/ langchain-benchmarks/, LangChain AI, 2025, accessed: 2025-07-25
work page 2025
-
[22]
Mind the Style of Text! Adversarial and Backdoor Attacks Based on Text Style Transfer,
F. Qi, Y . Chen, X. Zhang, M. Li, Z. Liu, and M. Sun, “Mind the Style of Text! Adversarial and Backdoor Attacks Based on Text Style Transfer,” Oct. 2021, arXiv:2110.07139 [cs]. [Online]. Available: http://arxiv.org/abs/2110.07139
-
[23]
Universal Jailbreak Backdoors from Poisoned Human Feedback,
J. Rando and F. Tram `er, “Universal Jailbreak Backdoors from Poisoned Human Feedback,” Nov. 2023, arXiv:2311.14455 [cs]. [Online]. Available: http://arxiv.org/abs/2311.14455
-
[24]
Catastrophic Jailbreak of Open-source LLMs via Exploiting Generation
Y . Huang, S. Gupta, M. Xia, K. Li, and D. Chen, “Catastrophic jailbreak of open-source LLMs via exploiting generation,”arXiv preprint arXiv:2310.06987, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “Do Anything Now: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” 2024, to appear in ACM CCS 2024. [Online]. Available: https://arxiv.org/abs/2308.03825
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Jailbreaking Black Box Large Language Models in Twenty Queries
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” 2024. [Online]. Available: https://arxiv .org/abs/2310.08419
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Neu- ral exec: Learning (and learning from) execution triggers for prompt injection attacks,
D. Pasquini, M. Strohmeier, and C. Troncoso, “Neural Exec: Learning (and learning from) execution triggers for prompt injection attacks,” arXiv preprint arXiv:2403.03792 , 2024
-
[28]
Prompt injection attack against LLM- integrated applications,
Y . Liu, G. Deng, Y . Li, K. Wang, Z. Wang, X. Wang, T. Zhang, Y . Liu, H. Wang, Y . Zheng, and Y . Liu, “Prompt injection attack against LLM- integrated applications,” 2024
work page 2024
-
[29]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
E. Wallace, K. Xiao, R. Leike, L. Weng, J. Heidecke, and A. Beutel, “The instruction hierarchy: Training LLMs to prioritize privileged instructions,” 2024. [Online]. Available: https://arxiv.org/abs/ 2404.13208
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Secalign: Defending against prompt injection with preference optimization,
S. Chen, A. Zharmagambetov, S. Mahloujifar, K. Chaudhuri, D. Wagner, and C. Guo, “SecAlign: Defending against prompt injection with preference optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2410.05451
-
[31]
A critical evaluation of defenses against prompt injection attacks,
Y . Jia, Z. Shao, Y . Liu, J. Jia, D. Song, and N. Z. Gong, “A critical evaluation of defenses against prompt injection attacks,” 2025. [Online]. Available: https://arxiv.org/abs/2505.18333
-
[32]
Defeating Prompt Injections by Design
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tram `er, “Defeating prompt injections by design,” arXiv preprint arXiv:2503.18813 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
LeanDojo: Theorem proving with retrieval-augmented language models,
K. Yang, A. Swope, A. Gu, R. Chalamala, P. Song, S. Yu, S. Godil, R. Prenger, and A. Anandkumar, “LeanDojo: Theorem proving with retrieval-augmented language models,” in Neural Information Process- ing Systems (NeurIPS) , 2023
work page 2023
-
[34]
Lean copilot: Large language models as copilots for theorem proving in lean,
P. Song, K. Yang, and A. Anandkumar, “Lean copilot: Large language models as copilots for theorem proving in lean,” 2025. [Online]. Available: https://arxiv.org/abs/2404.12534
-
[35]
VeriPlan: Integrating formal verification and LLMs into end-user planning,
C. Lee, D. J. Porfirio, X. J. Wang, K. Zhao, and B. Mutlu, “VeriPlan: Integrating formal verification and LLMs into end-user planning,” ArXiv, vol. abs/2502.17898, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:276581025
-
[36]
Y . Liu, Y . Xue, D. Wu, Y . Sun, Y . Li, M. Shi, and Y . Liu, “PropertyGPT: LLM-driven formal verification of smart contracts through retrieval-augmented property generation,” in 32nd Annual Network and Distributed System Security Symposium, NDSS 2025, San Diego, California, USA, February 24-28, 2025 . The Internet Society,
work page 2025
-
[37]
[Online]. Available: https://www .ndss-symposium.org/ndss- paper/propertygpt-llm-driven-formal-verification-of-smart-contracts- through-retrieval-augmented-property-generation/
-
[38]
Testing and understanding erroneous planning in LLM agents through synthesized user inputs,
Z. Ji, D. Wu, P. Ma, Z. Li, and S. Wang, “Testing and understanding erroneous planning in LLM agents through synthesized user inputs,”
-
[39]
Available: https://arxiv .org/abs/2404.17833
[Online]. Available: https://arxiv .org/abs/2404.17833
-
[40]
A theorem on boolean matrices,
S. Warshall, “A theorem on boolean matrices,” Journal of the ACM (JACM), vol. 9, no. 1, pp. 11–12, 1962. APPENDIX A ADDITIONAL DETAILS ON INFORMATION FLOW CONTROL In this appendix, we give additional details on the informa- tion flow system in ACE. 14 Lattice example. A lattice is a mathematical structure that defines a partial ordering of security levels...
work page 1962
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.