ServeGen: Workload Characterization and Generation of Large Language Model Serving in Production
Pith reviewed 2026-05-22 15:37 UTC · model grok-4.3
The pith
ServeGen generates realistic LLM serving workloads by composing per-client patterns observed in production traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
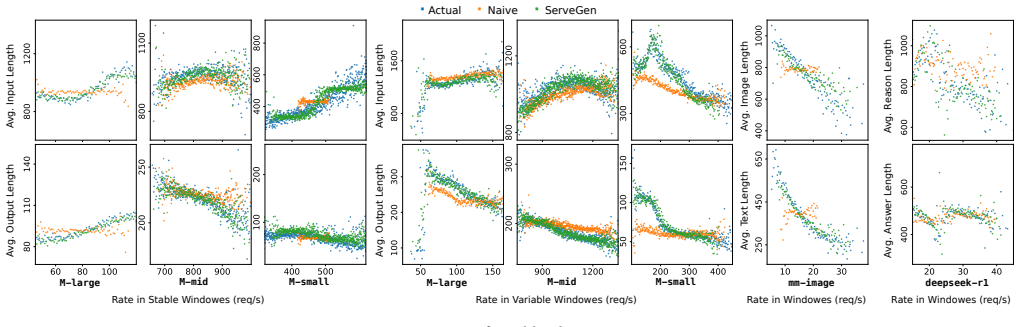
The paper characterizes LLM serving workloads at scale from a cloud inference service and proposes ServeGen, a framework that generates realistic workloads through per-client composition based on observed patterns. This is validated in production where it avoids 50% under-provisioning compared to naive generation.
What carries the argument
ServeGen's per-client composition mechanism that builds overall workloads by modeling and combining the request patterns of individual clients from real traces.
If this is right
- Per-client composition allows more accurate replication of complex workload characteristics than previous methods.
- Generated workloads from ServeGen enable better performance benchmarking of LLM serving systems.
- The approach covers a range of model types including multimodal and reasoning models.
- Real-world use demonstrates reduced under-provisioning in resource allocation for serving.
Where Pith is reading between the lines
- ServeGen might be adapted for other cloud environments if the core client patterns prove similar across providers.
- Future extensions could incorporate evolving client behaviors as models and usage patterns change over time.
- Similar composition strategies may improve workload modeling in adjacent areas such as general cloud service benchmarking.
Load-bearing premise
The traces from one cloud provider capture the essential patterns of LLM serving workloads that apply more broadly to other settings and newer model types.
What would settle it
Running ServeGen on traces from a separate cloud provider and finding that the generated workloads still cause significant under-provisioning in production tests would challenge the generalizability of the approach.
Figures














read the original abstract
With the widespread adoption of Large Language Models (LLMs), serving LLM inference requests has become an increasingly important task, attracting active research advancements. Practical workloads play an essential role in this process: they are critical for motivating and benchmarking serving techniques and systems. However, the existing understanding of real-world LLM serving workloads is limited due to the lack of a comprehensive workload characterization. Prior analyses remain insufficient in scale and scope, thus failing to fully capture intricate workload characteristics. In this paper, we fill the gap with an in-depth characterization of LLM serving workloads collected from our worldwide cloud inference serving service, covering not only language models but also emerging multimodal and reasoning models, and unveiling important new findings in each case. Moreover, based on our findings, we propose ServeGen, a principled framework for generating realistic LLM serving workloads by composing them on a per-client basis. A practical use case in production validates that ServeGen avoids 50% under-provisioning compared to naive workload generation, demonstrating ServeGen's advantage in performance benchmarking. ServeGen is available at https://github.com/alibaba/ServeGen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides an in-depth characterization of production LLM serving workloads from a worldwide cloud inference service, covering language, multimodal, and reasoning models and identifying new patterns in each. It introduces ServeGen, a workload generation framework that composes realistic request streams on a per-client basis using these observed patterns. A production use case is presented in which ServeGen-generated workloads avoid 50% under-provisioning relative to naive generation methods, illustrating the framework's value for performance benchmarking of LLM serving systems.
Significance. If the characterization holds and the per-client generation method transfers beyond the source traces, ServeGen could become a useful open tool for creating more realistic benchmarks in the LLM serving community. The open-sourcing at https://github.com/alibaba/ServeGen supports reproducibility and further evaluation by others.
major comments (2)
- [Practical use case / evaluation section] The central validation claim (avoiding 50% under-provisioning) is load-bearing for the paper's demonstration of ServeGen's advantage, yet the abstract and evaluation section provide no details on measurement methodology, statistical significance testing, workload scale, model versions, or controls for confounding factors. Without these, the result cannot be properly assessed or reproduced.
- [ServeGen framework and validation] ServeGen's per-client composition is derived directly from traces collected at a single cloud provider (Alibaba). The manuscript does not present external benchmarks, cross-provider validation, or sensitivity analysis showing that the observed arrival processes, model-type mixtures, and client behaviors remain representative when applied to other environments or future model releases; this directly affects the generalizability of the reported provisioning improvement.
minor comments (2)
- [Introduction / Related Work] Clarify early in the paper how 'per-client composition' differs from existing trace-replay or statistical workload generators, with a brief comparison table if possible.
- [Characterization sections] Ensure all figures showing workload characteristics (e.g., request rate distributions, model-type breakdowns) include axis labels, units, and sample sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below, indicating the revisions we will make to strengthen the paper while being transparent about its scope and limitations.
read point-by-point responses
-
Referee: [Practical use case / evaluation section] The central validation claim (avoiding 50% under-provisioning) is load-bearing for the paper's demonstration of ServeGen's advantage, yet the abstract and evaluation section provide no details on measurement methodology, statistical significance testing, workload scale, model versions, or controls for confounding factors. Without these, the result cannot be properly assessed or reproduced.
Authors: We agree that the evaluation section would benefit from expanded methodological details to support assessment and reproducibility. In the revised manuscript we will add a new subsection under the practical use case that specifies the workload scale (number of clients and total requests processed), the exact model versions used in the production validation, the statistical significance testing procedures applied to the under-provisioning measurements, and the controls employed for potential confounding factors such as hardware heterogeneity and request distribution variations. revision: yes
-
Referee: [ServeGen framework and validation] ServeGen's per-client composition is derived directly from traces collected at a single cloud provider (Alibaba). The manuscript does not present external benchmarks, cross-provider validation, or sensitivity analysis showing that the observed arrival processes, model-type mixtures, and client behaviors remain representative when applied to other environments or future model releases; this directly affects the generalizability of the reported provisioning improvement.
Authors: The characterization and ServeGen framework are derived from production traces of our Alibaba worldwide cloud inference service. We have performed sensitivity analyses on arrival processes and model-type mixtures within the collected dataset; these will be presented more explicitly in the revised manuscript. Cross-provider validation is not possible with the data available to us. We will add a dedicated limitations paragraph discussing generalizability to other providers and future model releases, while noting that the open-sourced ServeGen repository enables external researchers to test and adapt the framework on their own traces. revision: partial
- Cross-provider validation or external benchmarks of the observed workload patterns and the 50% provisioning improvement, due to the proprietary nature of production traces from other cloud providers.
Circularity Check
No circularity: characterization and generator derived from independent production traces with external-style validation
full rationale
The paper performs standard workload characterization on traces collected from the authors' own Alibaba cloud service, identifies patterns (language/multimodal/reasoning mixtures, per-client behaviors), and builds ServeGen as a composition framework on those observed statistics. The production use-case validation compares ServeGen-generated workloads against naive baselines for provisioning accuracy. No step reduces a claimed prediction or uniqueness result to a fitted parameter or self-citation by construction; the derivation chain remains self-contained against the collected traces without re-using the target metric as input. Generalizability concerns exist but are separate from circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Production traces from the authors' cloud service are representative of broader LLM serving workloads.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ServeGen performs principled modeling of workloads on a per-client basis... to generate realistic workloads
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Finding 1: The short-term arrival of LLM requests is often bursty (CV > 1), exhibiting complex patterns beyond any single stochastic process.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Cornfigurator: Automated Planning for Any-to-Any Multimodal Model Serving
Cornfigurator is the first automated deployment planner for generic any-to-any multimodal models that explores the full range of colocation-to-disaggregation strategies and delivers 1.12x to 6.32x higher goodput than ...
-
Dual-Pool Token-Budget Routing for Cost-Efficient and Reliable LLM Serving
Dual-pool token-budget routing for LLM serving reduces GPU-hours by 31-42% and preemption rates by 5.4x through online-learned request classification without a tokenizer.
-
WarmServe: Enabling One-for-Many GPU Prewarming for Multi-LLM Serving
WarmServe reduces tail TTFT by up to 50.8× versus autoscaling and supports 2.5× higher throughput than GPU-sharing by using one-for-many prewarming, model placement, KV cache reservation, and efficient tensor switching.
-
The Workload-Router-Pool Architecture for LLM Inference Optimization: A Vision Paper from the vLLM Semantic Router Project
The Workload-Router-Pool architecture is a 3D framework for LLM inference optimization that synthesizes prior vLLM work into a 3x3 interaction matrix and proposes 21 research directions at the intersections.
Reference graph
Works this paper leans on
-
[1]
Disaggregated prefilling and KV cache transfer roadmap in vLLM
2024. Disaggregated prefilling and KV cache transfer roadmap in vLLM. https://github.com/vllm-project/vllm/issues/10818. (2024)
work page 2024
-
[2]
2024. Learning to reason with LLMs. https://openai.com/index/ learning-to-reason-with-llms/ . (2024)
work page 2024
-
[3]
DeepSeek-V3/R1 Inference System Overview
2025. DeepSeek-V3/R1 Inference System Overview. https://github.com/deepseek-ai/open-infra-index/blob/main/ 202502OpenSourceWeek/day_6_one_more_thing_deepseekV3R1_ inference_system_overview.md. (2025)
work page 2025
-
[4]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. (2024). arXiv:cs.LG/2403.02310 https://arxiv.org/ abs/2403.02310
-
[5]
George Amvrosiadis, Jun Woo Park, Gregory R. Ganger, Garth A. Gib- son, Elisabeth Baseman, and Nathan DeBardeleben. 2018. On the di- versity of cluster workloads and its impact on research results. In 2018 USENIX Annual Technical Conference (USENIX ATC 18). USENIX As- sociation, Boston, MA, 533–546. https://www.usenix.org/conference/ atc18/presentation/am...
work page 2018
-
[6]
N. Attig, P. Gibbon, and Th. Lippert. 2011. Trends in supercomputing: The European path to exascale. Computer Physics Communications 182, 9 (2011), 2041–2046. https://doi.org/10.1016/j.cpc.2010.11.011 Com- puter Physics Communications Special Edition for Conference on Computational Physics Trondheim, Norway, June 23-26, 2010
-
[7]
Arshdeep Bahga, Vijay Krishna Madisetti, et al. 2011. Synthetic work- load generation for cloud computing applications. Journal of Software Engineering and Applications 4, 07 (2011), 396
work page 2011
-
[8]
Luiz Andr Barroso, Jimmy Clidaras, and Urs Hlzle. 2013. The Data- center as a Computer: An Introduction to the Design of Warehouse-Scale Machines (2nd ed.). Morgan & Claypool Publishers
work page 2013
-
[9]
Shane Bergsma, Timothy Zeyl, Arik Senderovich, and J. Christopher Beck. 2021. Generating Complex, Realistic Cloud Workloads using Recurrent Neural Networks. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21). Association for Computing Machinery, New York, NY, USA, 376–391. https://doi.org/ 10.1145/3477132.3483590
-
[10]
Shiyi Cao, Yichuan Wang, Ziming Mao, Pin-Lun Hsu, Liangsheng Yin, Tian Xia, Dacheng Li, Shu Liu, Yineng Zhang, Yang Zhou, Ying Sheng, Joseph Gonzalez, and Ion Stoica. 2025. Locality-aware Fair Scheduling in LLM Serving. (2025). arXiv:cs.DC/2501.14312 https: //arxiv.org/abs/2501.14312
-
[11]
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. 2025. Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scal- ing. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Eli Cortez, Anand Bonde, Alexandre Muzio, Mark Russinovich, Marcus Fontoura, and Ricardo Bianchini. 2017. Resource Central: Understand- ing and Predicting Workloads for Improved Resource Management in Large Cloud Platforms. In Proceedings of the International Symposium on Operating Systems Principles (SOSP)
work page 2017
-
[13]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. (2025). arXiv:cs.CL/2501.12948 https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weis- senborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. InInternational Conference on Learning Representations. https://...
work page 2021
-
[15]
Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, and Hao Zhang. 2024. MuxServe: flexible spatial-temporal multiplexing for multiple LLM serving. InProceedings of the 41st International Conference on Machine Learning . Article 473, 13 pages
work page 2024
-
[16]
DeepSeek-AI et al. 2025. DeepSeek-V3 Technical Report. (2025). arXiv:cs.CL/2412.19437 https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Gonzalo P. Rodrigo et al. 2018. Towards understanding HPC users and systems: A NERSC case study. J. Parallel and Distrib. Comput. 111 (2018), 206–221. https://doi.org/10.1016/j.jpdc.2017.09.002
- [18]
- [19]
- [20]
-
[21]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low- Latency Serverless Inference for Large Language Models. In 18th USENIX Symposium on Operating Systems Design and Implementa- tion (OSDI 24). USENIX Association, Santa Clara, CA, 135–153. https: //www.usenix.org/conference/osdi24/...
work page 2024
-
[22]
Connor Holmes, Masahiro Tanaka, Michael Wyatt, Ammar Ahmad Awan, Jeff Rasley, Samyam Rajbhandari, Reza Yazdani Aminabadi, Heyang Qin, Arash Bakhtiari, Lev Kurilenko, and Yuxiong He. 2024. DeepSpeed-FastGen: High-throughput Text Generation for LLMs via MII and DeepSpeed-Inference. (2024). arXiv:cs.PF/2401.08671 https: //arxiv.org/abs/2401.08671
-
[23]
Qinghao Hu, Peng Sun, Shengen Yan, Yonggang Wen, and Tianwei Zhang. 2021. Characterization and prediction of deep learning work- loads in large-scale gpu datacenters. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–15
work page 2021
-
[24]
Qinghao Hu, Zhisheng Ye, Zerui Wang, Guoteng Wang, Meng Zhang, Qiaoling Chen, Peng Sun, Dahua Lin, Xiaolin Wang, Yingwei Luo, Yonggang Wen, and Tianwei Zhang. 2024. Characterization of Large Language Model Development in the Datacenter. In 21st USENIX Sym- posium on Networked Systems Design and Implementation (NSDI 24) . USENIX Association, Santa Clara, C...
work page 2024
-
[25]
Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wencong Xiao, and Fan Yang. 2019. Analysis of Large-Scale Multi-Tenant GPU Clusters for DNN Training Workloads. In 2019 USENIX Annual Technical Conference (USENIX ATC 19). USENIX As- sociation, Renton, WA, 947–960. https://www.usenix.org/conference/ atc19/presentation/jeon
work page 2019
-
[26]
Yibo Jin, Tao Wang, Huimin Lin, Mingyang Song, Peiyang Li, Yipeng Ma, Yicheng Shan, Zhengfan Yuan, Cailong Li, Yajing Sun, Tiandeng Wu, Xing Chu, Ruizhi Huan, Li Ma, Xiao You, Wenting Zhou, Yunpeng Ye, Wen Liu, Xiangkun Xu, Yongsheng Zhang, Tiantian Dong, Jiawei Zhu, Zhe Wang, Xijian Ju, Jianxun Song, Haoliang Cheng, Xiaojing Li, Jiandong Ding, Hefei Guo,...
-
[27]
Da-Cheng Juan, Lei Li, Huan-Kai Peng, Diana Marculescu, and Chris- tos Faloutsos. 2014. Beyond poisson: Modeling inter-arrival time of requests in a datacenter. In Advances in Knowledge Discovery and Data Mining: 18th Pacific-Asia Conference, PAKDD 2014, Tainan, Taiwan, May 13-16, 2014. Proceedings, Part II 18 . Springer, 198–209
work page 2014
-
[28]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[29]
In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23)
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). Association for Computing Machinery, New York, NY, USA, 611–626. https://doi.org/10.1145/ 3600006.3613165
-
[30]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23) . USENIX As- sociation, Boston, ...
work page 2023
- [31]
-
[32]
Chengzhi Lu, Kejiang Ye, Guoyao Xu, Cheng-Zhong Xu, and Tongxin Bai. 2017. Imbalance in the cloud: An analysis on Alibaba cluster trace. In 2017 IEEE International Conference on Big Data (Big Data) . 2884–2892. https://doi.org/10.1109/BigData.2017.8258257
-
[33]
OpenAI. 2024. Introducing OpenAI o1. (2024). https://openai.com/o1/
work page 2024
-
[34]
OpenAI. 2024. OpenAI’s GPT-4o model. (2024). https://openai.com/ index/hello-gpt-4o/
work page 2024
-
[35]
Tirthak Patel, Zhengchun Liu, Raj Kettimuthu, Paul Rich, William Allcock, and Devesh Tiwari. 2020. Job characteristics on large-scale systems: long-term analysis, quantification, and implications. In Pro- ceedings of the International Conference for High Performance Comput- ing, Networking, Storage and Analysis (SC ’20). IEEE Press, Article 84, 17 pages
work page 2020
-
[36]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2025. Mooncake: Trading More Storage for Less Computation — A KVCache-centric Ar- chitecture for Serving LLM Chatbot. In 23rd USENIX Conference on File and Storage Technologies (FAST 25). USENIX Association, Santa Clara, CA, 155–170. https://ww...
work page 2025
-
[37]
Qwen Team. 2024. Qwen2.5: A Party of Foundation Models. (Septem- ber 2024). https://qwenlm.github.io/blog/qwen2.5/
work page 2024
-
[38]
Charles Reiss, Alexey Tumanov, Gregory R. Ganger, Randy H. Katz, and Michael A. Kozuch. 2012. Heterogeneity and dynamicity of clouds at scale: Google trace analysis. In Proceedings of the Third ACM Symposium on Cloud Computing (SoCC ’12) . Association for Computing Machinery, New York, NY, USA, Article 7, 13 pages. https://doi.org/10.1145/2391229.2391236
-
[39]
RyokoAI. 2024. ShareGPT-52K. (2024). https://huggingface.co/ datasets/RyokoAI/ShareGPT52K
work page 2024
-
[40]
Mohammad Shahrad, Rodrigo Fonseca, Inigo Goiri, Gohar Chaudhry, Paul Batum, Jason Cooke, Eduardo Laureano, Colby Tresness, Mark Russinovich, and Ricardo Bianchini. 2020. Serverless in the Wild: Char- acterizing and Optimizing the Serverless Workload at a Large Cloud Provider. In2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, 2...
work page 2020
-
[41]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. (2020). arXiv:cs.CL/1909.08053 https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[42]
Abhishek Verma, Madhukar Korupolu, and John Wilkes. 2014. Evalu- ating job packing in warehouse-scale computing. In 2014 IEEE Interna- tional Conference on Cluster Computing (CLUSTER) . IEEE, 48–56
work page 2014
-
[43]
Mengdi Wang, Chen Meng, Guoping Long, Chuan Wu, Jun Yang, Wei Lin, and Yangqing Jia. 2019. Characterizing Deep Learning Training Workloads on Alibaba-PAI . In 2019 IEEE International Symposium on Workload Characterization (IISWC) . IEEE Computer Society, Los Alamitos, CA, USA, 189–202. https://doi.org/10.1109/IISWC47752.2019. 9042047
- [44]
- [45]
-
[46]
Qizhen Weng, Wencong Xiao, Yinghao Yu, Wei Wang, Cheng Wang, Jian He, Yong Li, Liping Zhang, Wei Lin, and Yu Ding. 2022. MLaaS in the Wild: Workload Analysis and Scheduling in Large-Scale Het- erogeneous GPU Clusters. In 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22) . USENIX Association, Renton, WA, 945–960. https://www.us...
work page 2022
- [47]
-
[48]
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. 2024. Fast Distributed Inference Serving for Large Language Models. (2024). 14 arXiv:cs.LG/2305.05920 https://arxiv.org/abs/2305.05920
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Has- san Awadallah, Ryen W White, Doug Burger, and Chi Wang. 2023. Au- toGen: Enabling Next-Gen LLM Applications via Multi-Agent Conver- sation. (2023). arXiv:cs.AI/2308.08155 https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
xAI. 2025. Grok 3 Beta — The Age of Reasoning Agents. (2025). https://x.ai/blog/grok-3/
work page 2025
-
[51]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025. Qwen2.5-Omni Technical Report. arXiv preprint arXiv:2503.20215 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22) . USENIX As- sociation, Carlsbad, CA, 521–538. https://www.usenix.org/conference/ osdi22/presentation/yu
work page 2022
-
[53]
Hong Zhang, Yupeng Tang, Anurag Khandelwal, and Ion Stoica. 2023. SHEPHERD: Serving DNNs in the Wild. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23) . USENIX As- sociation, Boston, MA, 787–808. https://www.usenix.org/conference/ nsdi23/presentation/zhang-hong
work page 2023
-
[54]
Yanqi Zhang, Íñigo Goiri, Gohar Irfan Chaudhry, Rodrigo Fonseca, Sameh Elnikety, Christina Delimitrou, and Ricardo Bianchini. 2021. Faster and Cheaper Serverless Computing on Harvested Resources. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (SOSP ’21). Association for Computing Machinery, New York, NY, USA, 724–739. http...
-
[55]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Efficient Execution of Structured Language Model Programs. (2024). arXiv:cs.AI/2312.07104 https://arxiv.org/abs/2312.07104
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [56]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.