SafeTrans: LLM-assisted Transpilation from C to Rust
Pith reviewed 2026-05-22 14:09 UTC · model grok-4.3
The pith
LLMs can transpile C code to Rust at 80 percent success when an iterative repair loop supplies error-specific context and example fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
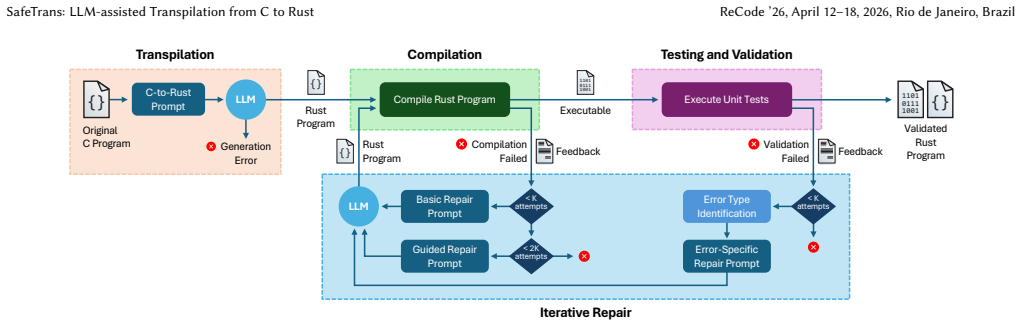
SafeTrans demonstrates that an LLM-based transpiler equipped with a few-shot guided repair loop can convert C programs into compilable and runnable Rust in the majority of cases. The loop works by feeding the model contextual error information and one or more concrete code examples that illustrate the correct resolution for each error type, allowing successive corrections without unbounded iteration. On 2,653 C programs the best model reaches 80 percent successful translations after repair, up from 54 percent without it, and the same pattern holds for two larger real-world C projects. The study additionally reports that common C vulnerability patterns, such as buffer issues, continue to be,
What carries the argument
The few-shot guided repair technique, which augments each repair prompt with error-type context plus example code snippets that show the proper fix for that specific error category.
If this is right
- Iterative repair produces large gains in successful translations for the strongest models but smaller gains for weaker ones.
- Certain C vulnerabilities such as buffer overflows translate directly into the generated Rust code.
- The framework succeeds on both synthetic test suites and actual open-source C projects.
- Different LLMs exhibit distinct baseline translation quality and different improvement curves under repair.
- The same error-guided prompting pattern can be reused with any code-generating LLM.
Where Pith is reading between the lines
- If the repair examples can be generated automatically from error logs rather than hand-written, the whole process could scale to millions of lines of legacy code without manual curation.
- The survival of vulnerabilities indicates that a post-translation static analysis or security-focused prompt stage would be a natural next addition.
- The technique may transfer to other language pairs where compiler errors provide reliable, structured feedback for iterative correction.
- Measuring not only compilation success but also runtime behavior equivalence on larger benchmarks would clarify how much functional fidelity is preserved.
Load-bearing premise
Supplying contextual information and a few example code snippets for each error type will reliably steer the LLM to correct, non-regressive fixes without introducing new errors or requiring unbounded iterations.
What would settle it
Apply the identical repair loop and example set to an independent collection of several thousand fresh C programs and measure whether the final success rate stays near 80 percent or falls sharply while tracking whether the same vulnerability classes persist.
Figures
read the original abstract
Rust is a strong contender for a memory-safe alternative to C as a "systems" language, but porting the vast amount of existing C code to Rust remains daunting. In this paper, we evaluate the potential of large language models (LLMs) to automate the transpilation of C code to idiomatic Rust. We present SafeTrans, a generic framework that leverages LLMs to i) transpile C code into Rust, and ii) iteratively repair compilation and runtime errors. A key novelty of our approach is a few-shot guided repair technique for translation errors, which provides contextual information and example code snippets for specific error types, guiding the LLM toward the correct solution. Another novel aspect of our work is the evaluation of the security implications of the transpilation process, showing how some vulnerability classes in C persist in the translated Rust code. SafeTrans was evaluated with six leading LLMs on 2,653 C programs and two real-world C projects. Our results show that iterative repair improves the rate of successful translations from 54% to 80% for the best-performing LLM (gpt-4o).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SafeTrans, a framework that uses LLMs to transpile C programs to Rust and then applies iterative repair of compilation and runtime errors via few-shot prompts supplying error-specific context and code examples. It evaluates the approach on 2,653 C programs plus two real-world projects using six LLMs, reports that iterative repair raises successful translation rates from 54% to 80% for gpt-4o, and examines how certain C vulnerability classes can persist after translation.
Significance. If the empirical results hold, the work provides concrete evidence that LLM-based iterative repair can meaningfully improve automated C-to-Rust transpilation at scale. The large program corpus, multi-LLM comparison, use of standard compilation/runtime oracles, and security analysis together offer a useful data point on both the promise and the limitations of LLM-assisted migration to memory-safe languages.
major comments (1)
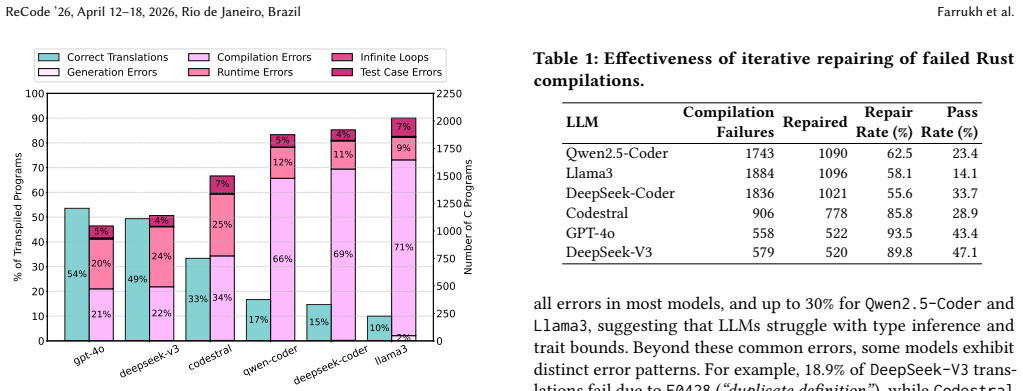
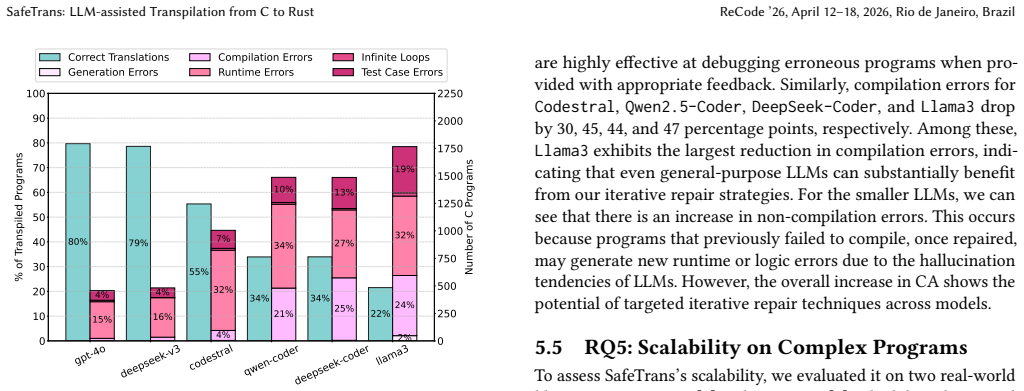
- [Evaluation / Results] The headline result (54% → 80% for gpt-4o) rests on the iterative repair loop. The manuscript reports only final success rates and does not quantify average or maximum iterations per program, convergence behavior, or the frequency of regressions in which a repair introduces a new error type outside the supplied few-shot examples. This information is needed to evaluate whether the repair process remains practical under realistic iteration caps.
minor comments (2)
- [Evaluation] Clarify whether the 2,653 programs include only synthetic benchmarks or also subsets of the two real-world projects, and ensure table captions and text use identical program counts.
- [Security Analysis] The security section would benefit from a short table enumerating the vulnerability classes examined and the fraction that remained after translation for each LLM.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of our work. We address the major comment below and will incorporate additional analysis of the iterative repair process in the revised manuscript.
read point-by-point responses
-
Referee: [Evaluation / Results] The headline result (54% → 80% for gpt-4o) rests on the iterative repair loop. The manuscript reports only final success rates and does not quantify average or maximum iterations per program, convergence behavior, or the frequency of regressions in which a repair introduces a new error type outside the supplied few-shot examples. This information is needed to evaluate whether the repair process remains practical under realistic iteration caps.
Authors: We agree that quantifying the behavior of the iterative repair loop would provide a more complete evaluation of practicality. In the revised manuscript we will add a dedicated subsection (and associated figures/tables) reporting the average and maximum number of repair iterations required for successful translations across the full corpus for each of the six LLMs. We will also present cumulative success-rate curves to illustrate convergence behavior. For regressions, we will analyze our experimental logs to report the frequency with which a repair step introduces a new error category outside the supplied few-shot examples and discuss how the error-specific prompting strategy limits such regressions. These additions will be based on data already collected during our experiments. revision: yes
Circularity Check
No circularity: empirical success rates measured against external oracles
full rationale
The paper reports empirical measurements of transpilation success rates (54% to 80% with iterative repair) obtained by running SafeTrans on 2,653 C programs and two real-world projects using external LLMs (gpt-4o and others) and standard compilation/runtime oracles. No mathematical derivations, equations, or first-principles claims exist that could reduce to self-definitions or fitted inputs. The few-shot repair technique is described as a prompting strategy evaluated directly against observable error fixes, with no self-citation chains or uniqueness theorems invoked to justify core results. The evaluation is self-contained and independently falsifiable via the same external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be guided to produce correct code repairs when given targeted examples and context for specific error categories
Forward citations
Cited by 4 Pith papers
-
ORBIT: Guided Agentic Orchestration for Autonomous C-to-Rust Transpilation
ORBIT achieves 100% compilation success and 91.7% test success on 24 mostly large programs from CRUST-Bench by using dependency-aware orchestration and iterative verification, outperforming prior static and baseline tools.
-
ENCRUST: Encapsulated Substitution and Agentic Refinement on a Live Scaffold for Safe C-to-Rust Translation
ENCRUST decouples C-to-Rust translation via ABI wrappers and agentic refinement to reduce unsafe constructs across 15 real programs while preserving full test correctness.
-
Project-Level C-to-Rust Translation via Pointer Knowledge Graphs
PtrTrans builds a Pointer Knowledge Graph with points-to flows, struct abstractions, and Rust annotations to guide LLMs toward project-level C-to-Rust translations that cut unsafe code by 99.9% and raise functional co...
-
Search-Based Multi-Trajectory Refinement for Safe C-to-Rust Translation with Large Language Models
LAC2R uses MCTS to systematically explore multiple LLM refinement trajectories for C-to-Rust translation and reports superior safety and correctness on small-scale benchmarks.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. An AVL Tree Implementation In C. https://github.com/xieqing/avl- tree/tree/master
-
[2]
[n. d.]. url.h. https://github.com/jwerle/url.h/tree/master
-
[3]
Artisan-Lab. 2025. RAPx: Rust Analysis Platform. https://github.com/Artisan- Lab/RAPx. https://github.com/Artisan-Lab/RAPx Accessed: 2025-05-13
work page 2025
-
[4]
Yechan Bae, Youngsuk Kim, Ammar Askar, Jungwon Lim, and Taesoo Kim. 2021. Rudra: finding memory safety bugs in Rust at the ecosystem scale. InProceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles. 84–99
work page 2021
- [5]
-
[6]
Efe Bozkir, Süleyman Özdel, Ka Hei Carrie Lau, Mengdi Wang, Hong Gao, and Enkelejda Kasneci. 2024. Embedding large language models into extended re- ality: Opportunities and challenges for inclusion, engagement, and privacy. In Proceedings of the 6th ACM Conference on Conversational User Interfaces. 1–7
work page 2024
- [7]
-
[8]
Mehmet Emre, Ryan Schroeder, Kyle Dewey, and Ben Hardekopf. 2021. Trans- lating C to Safer Rust.Proc. ACM Program. Lang.5, OOPSLA, Article 121 (oct 2021)
work page 2021
- [9]
-
[10]
Mikhail R Gadelha, Felipe R Monteiro, Jeremy Morse, Lucas C Cordeiro, Bernd Fischer, and Denis A Nicole. 2018. ESBMC 5.0: an industrial-strength C model checker. InProceedings of the 33rd ACM/IEEE International Conference on Auto- mated Software Engineering. 888–891
work page 2018
-
[11]
Jaemin Hong. 2023. Improving Automatic C-to-Rust Translation with Static Analysis. InProceedings of the 45th IEEE/ACM International Conference on Software Engineering (ICSE). 273–277
work page 2023
-
[12]
Jaemin Hong and Sukyoung Ryu. 2023. Concrat: An automatic C-to-Rust lock API translator for concurrent programs. In2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). IEEE, 716–728
work page 2023
-
[13]
Jaemin Hong and Sukyoung Ryu. 2024. Don’t Write, but Return: Replacing Output Parameters with Algebraic Data Types in C-to-Rust Translation.Proceedings of the ACM on Programming Languages8, PLDI (2024), 716–740
work page 2024
-
[14]
Jaemin Hong and Sukyoung Ryu. 2024. To Tag, or Not to Tag: Translating C’s Unions to Rust’s Tagged Unions. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 40–52
work page 2024
-
[15]
Rasha Ahmad Husein, Hala Aburajouh, and Cagatay Catal. 2025. Large language models for code completion: A systematic literature review.Computer Standards & Interfaces92 (2025), 103917. doi:10.1016/j.csi.2024.103917
-
[16]
Ali Reza Ibrahimzada, Kaiyao Ke, Mrigank Pawagi, Muhammad Salman Abid, Rangeet Pan, Saurabh Sinha, and Reyhaneh Jabbarvand. 2025. AlphaTrans: A Neuro-Symbolic Compositional Approach for Repository-Level Code Translation and Validation.Proceedings of the ACM on Software Engineering2, FSE (2025), 2454–2476
work page 2025
-
[17]
Ali Reza Ibrahimzada, Brandon Paulsen, Reyhaneh Jabbarvand, Joey Dodds, and Daniel Kroening. 2025. MatchFixAgent: Language-Agnostic Autonomous Repository-Level Code Translation Validation and Repair.arXiv preprint arXiv:2509.16187(2025)
work page internal anchor Pith review arXiv 2025
-
[18]
Immunant. 2022. C2Rust. https://github.com/immunant/c2rust
work page 2022
- [19]
-
[20]
Yoonsang Kim, Zainab Aamir, Mithilesh Singh, Saeed Boorboor, Klaus Mueller, and Arie E. Kaufman. 2025. Explainable XR: Understanding User Behaviors of XR Environments using LLM-assisted Analytics Framework.IEEE Transactions on Visualization and Computer Graphics(2025)
work page 2025
- [21]
-
[22]
Tianyu Li, Ruishi Li, Bo Wang, Brandon Paulsen, Umang Mathur, and Prateek Saxena. 2025. Adversarial Agent Collaboration for C to Rust Translation.arXiv preprint arXiv:2510.03879(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [23]
-
[24]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics12 (02 2024), 157–
work page 2024
-
[25]
doi:10.1162/tacl_a_00638 arXiv:https://direct.mit.edu/tacl/article- pdf/doi/10.1162/tacl_a_00638/2336043/tacl_a_00638.pdf
-
[26]
Muhammad Muzammil, Abisheka Pitumpe, Xigao Li, Amir Rahmati, and Nick Nikiforakis. 2025. The Poorest Man in Babylon: A Longitudinal Study of Cryp- tocurrency Investment Scams. InProceedings of The Web Conference (WWW)
work page 2025
- [27]
- [28]
- [29]
-
[30]
Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lam- bert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2024. Lost in translation: A study of bugs introduced by large language models while translating code. InProceedings of the IEEE/ACM 46th International Conference on Software Enginee...
work page 2024
-
[31]
Ruchir Puri, David S Kung, Geert Janssen, Wei Zhang, Giacomo Domeniconi, Vladimir Zolotov, Julian Dolby, Jie Chen, Mihir Choudhury, Lindsey Decker, et al
- [32]
-
[33]
Baptiste Roziere, Marie-Anne Lachaux, Lowik Chanussot, and Guillaume Lample
-
[34]
InAdvances in Neural Information Processing Systems (NeurIPS), Vol
Unsupervised Translation of Programming Languages. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 33. 20601–20611
-
[35]
Ranjan Sapkota, Shaina Raza, Maged Shoman, Achyut Paudel, and Manoj Karkee
- [36]
-
[37]
Scott Olson. [n. d.]. Miri: an Interpreter for Rust’s Mid-level Intermediate Repre- sentation. https://github.com/rust-lang/miri
-
[38]
Manish Shetty, Naman Jain, Adwait Godbole, Sanjit A Seshia, and Koushik Sen
- [39]
- [40]
-
[41]
HoHyun Sim, Hyeonjoong Cho, Yeonghyeon Go, Zhoulai Fu, Ali Shokri, and Binoy Ravindran. 2025. Large Language Model-Powered Agent for C to Rust Code Translation. arXiv:2505.15858 [cs.PL] https://arxiv.org/abs/2505.15858
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [42]
-
[43]
Norbert Tihanyi, Tamas Bisztray, Ridhi Jain, Mohamed Amine Ferrag, Lucas C Cordeiro, and Vasileios Mavroeidis. 2023. The FormAI dataset: Generative AI in software security through the lens of formal verification. InProceedings of the 19th International Conference on Predictive Models and Data Analytics in Software Engineering. 33–43
work page 2023
- [44]
- [45]
- [46]
-
[47]
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, and Ge Li. 2024. Exploring and unleashing the power of large language models in automated code translation.Proceedings of the ACM on Software Engineering1, FSE (2024), 1585–1608
work page 2024
- [48]
-
[49]
Hanliang Zhang, Cristina David, Yijun Yu, and Meng Wang. 2023. Ownership guided C to Rust translation. InInternational Conference on Computer Aided Verification. Springer, 459–482
work page 2023
-
[50]
Tianyang Zhou, Haowen Lin, Somesh Jha, Mihai Christodorescu, Kirill Levchenko, and Varun Chandrasekaran. 2025. LLM-Driven Multi-step Translation from C to Rust using Static Analysis.arXiv preprint arXiv:2503.12511(2025). ReCode ’26, April 12–18, 2026, Rio de Janeiro, Brazil Farrukh et al. A Appendix A.1 Comparison with Prior C-to-Rust Translation Tools Ta...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.