What Prompts Don't Say: Understanding and Managing Underspecification in LLM Prompts
Pith reviewed 2026-05-22 13:58 UTC · model grok-4.3
The pith
Under-specified prompts make LLMs twice as likely to regress across model or prompt changes, yet requirements-aware optimization lifts results by 4.8 percent on average.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLMs often infer unspecified requirements in prompts by default in 41.1 percent of cases, but this behavior is fragile because under-specified prompts are twice as likely to regress across model or prompt changes, with accuracy drops exceeding 20 percent in some instances. Simply specifying all requirements does not consistently improve outcomes due to limited instruction-following abilities and potential conflicts. Standard prompt optimizers offer little help, whereas the proposed requirements-aware prompt optimization mechanisms achieve an average performance improvement of 4.8 percent over baselines.
What carries the argument
Requirements-aware prompt optimization mechanisms that perform proactive requirements discovery, evaluation, and ongoing monitoring to reduce the effects of underspecification.
If this is right
- Under-specified prompts are twice as likely to regress when models or prompts change.
- Accuracy drops exceeding 20 percent can occur from this instability.
- Explicitly stating every requirement does not reliably improve performance due to inconsistent instruction following and requirement conflicts.
- Standard prompt optimization techniques deliver little benefit against underspecification.
- Requirements-aware optimization mechanisms improve average performance by 4.8 percent.
Where Pith is reading between the lines
- Developers could add routine audits for missing requirements during prompt creation to reduce later regressions.
- Automated tools that flag and suggest missing requirements might become practical for production systems.
- Ongoing performance monitoring in deployed applications could catch instability before it affects users.
- Similar fragility patterns may appear in multi-turn or agent-based LLM setups and warrant separate checks.
Load-bearing premise
The evaluation tasks and metrics used accurately capture the real effects of underspecification in typical LLM application scenarios.
What would settle it
A replication on a wider range of practical tasks showing that under-specified prompts do not regress at twice the rate or that the new optimization methods lose their reported gains.
Figures









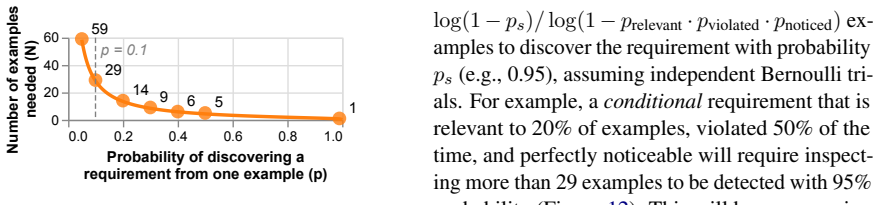






read the original abstract
Prompt underspecification is a common challenge when interacting with LLMs. In this paper, we present an in-depth analysis of this problem, showing that while LLMs can often infer unspecified requirements by default (41.1%), such behavior is fragile: Under-specified prompts are 2x as likely to regress across model or prompt changes, sometimes with accuracy drops exceeding 20%. This instability makes it difficult to reliably build LLM applications. Moreover, simply specifying all requirements does not consistently help, as models have limited instruction-following ability and requirements can conflict. Standard prompt optimizers likewise provide little benefit. To address these issues, we propose requirements-aware prompt optimization mechanisms that improve performance by 4.8% on average over baselines. We further advocate for a systematic process of proactive requirements discovery, evaluation, and monitoring to better manage prompt underspecification in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes prompt underspecification in LLMs, reporting that models default-infer unspecified requirements in 41.1% of cases. It finds that underspecified prompts are 2x as likely to regress across model or prompt changes (with accuracy drops sometimes exceeding 20%), that fully specifying requirements does not consistently help due to limited instruction-following and conflicts, and that standard prompt optimizers provide little benefit. The authors propose requirements-aware prompt optimization mechanisms yielding 4.8% average improvement over baselines and advocate a systematic process of proactive requirements discovery, evaluation, and monitoring.
Significance. If the quantitative results on regression likelihood and optimization gains hold under scrutiny, the work would be significant for highlighting a practical fragility in LLM prompting and for offering concrete mitigation strategies. The empirical focus on observable behaviors rather than self-referential derivations is a strength, as is the proposal of requirements-aware mechanisms that could inform more reliable LLM application design.
major comments (2)
- [Methods] Methods section: The headline claims of 2x regression likelihood and 4.8% optimization gains rest on specific task collections and a particular definition of regression across model/prompt changes. The paper must demonstrate that these tasks are representative of real-world scenarios and that the regression metric is robust to reasonable variations in threshold or baseline; otherwise the factor-of-two and reported gains risk being artifacts of experimental design rather than general properties of underspecification.
- [§4] §4 (Evaluation): The abstract reports concrete figures (41.1% default inference, >20% drops, 4.8% gain) but the evaluation must include explicit controls, statistical tests, and ablation on whether the chosen metrics isolate underspecification effects versus other prompt sensitivities; without these the central stability claims remain difficult to verify.
minor comments (2)
- [§5] Clarify the exact operational definition of 'requirements-aware prompt optimization' and how it differs from standard optimizers in the proposed mechanisms.
- [Discussion] Add discussion of potential conflicts between requirements and how the systematic process handles them in practice.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below, outlining how we will strengthen the paper through targeted revisions.
read point-by-point responses
-
Referee: [Methods] Methods section: The headline claims of 2x regression likelihood and 4.8% optimization gains rest on specific task collections and a particular definition of regression across model/prompt changes. The paper must demonstrate that these tasks are representative of real-world scenarios and that the regression metric is robust to reasonable variations in threshold or baseline; otherwise the factor-of-two and reported gains risk being artifacts of experimental design rather than general properties of underspecification.
Authors: Our task collection draws from established benchmarks spanning classification, generation, and reasoning to capture typical LLM application patterns. We agree that explicit robustness checks are valuable and have added sensitivity analyses in the revised Methods section: varying the regression threshold by ±5% and using alternative baselines such as mean performance across models. These confirm the approximately 2x regression likelihood holds. We have also expanded the task selection rationale with a limitations discussion on representativeness, noting that while our set reflects common prompt-engineering scenarios, broader real-world coverage would require future multi-domain studies. revision: yes
-
Referee: [§4] §4 (Evaluation): The abstract reports concrete figures (41.1% default inference, >20% drops, 4.8% gain) but the evaluation must include explicit controls, statistical tests, and ablation on whether the chosen metrics isolate underspecification effects versus other prompt sensitivities; without these the central stability claims remain difficult to verify.
Authors: We concur that stronger statistical grounding and isolation of effects will improve verifiability. The revised §4 now includes paired t-tests and bootstrap confidence intervals for the reported figures (41.1% default inference, accuracy drops, and 4.8% gain). We added control experiments contrasting underspecification with other prompt perturbations (e.g., lexical noise) and an ablation removing individual components of the requirements-aware optimizer. These results, with full tables in the appendix, support that the stability claims are attributable to underspecification rather than generic prompt sensitivity. revision: yes
Circularity Check
No circularity detected in empirical LLM prompt analysis
full rationale
The paper reports direct experimental measurements of LLM behavior under underspecified prompts, including observed rates (41.1% default inference) and comparative statistics (2x regression likelihood, 4.8% optimization gains). These quantities are computed from task evaluations rather than derived via equations, fitted parameters renamed as predictions, or self-referential definitions. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the abstract or described methods. The work is self-contained as an empirical investigation against external benchmarks, with results tied to observable model outputs instead of reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can infer unspecified requirements from prompts in measurable ways
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under-specified prompts are 2x as likely to regress across model or prompt changes... requirements-aware prompt optimization mechanisms that improve performance by 4.8%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 7 Pith papers
-
Instruction Complexity Induces Positional Collapse in Adversarial LLM Evaluation
Complex adversarial instructions induce positional collapse in LLMs, with extreme cases showing 99.9% concentration on a single response position and zero content sensitivity.
-
When Prompt Under-Specification Improves Code Correctness: An Exploratory Study of Prompt Wording and Structure Effects on LLM-Based Code Generation
Structurally rich task descriptions make LLMs robust to prompt under-specification, and under-specification can enhance code correctness by disrupting misleading lexical or structural cues.
-
Compass vs Railway Tracks: Unpacking User Mental Models for Communicating Long-Horizon Work to Humans vs. AI
Users treat human delegation for long tasks as a flexible compass but AI delegation as rigid railway tracks due to perceived AI limitations in inference and judgment.
-
Intent Lenses: Inferring Capture-Time Intent to Transform Opportunistic Photo Captures into Structured Visual Notes
Intent Lenses infer capture-time user intent from photos via LLMs to create dynamic, reusable interactive objects that generate and organize structured visual notes for later sensemaking.
-
Consistency as a Testable Property: Statistical Methods to Evaluate AI Agent Reliability
A framework with U-statistics and kernel-based metrics quantifies AI agent consistency and robustness, showing trajectory metrics outperform pass@1 rates in diagnosing failures.
-
Quantifying the Utility of User Simulators for Building Collaborative LLM Assistants
Fine-tuned simulators grounded in real human data produce LLM assistants that win more often against real users than those trained against role-playing simulators.
-
Symbolic Guardrails for Domain-Specific Agents: Stronger Safety and Security Guarantees Without Sacrificing Utility
Symbolic guardrails enforce 74% of specified safety policies in agent benchmarks and boost safety without hurting utility.
Reference graph
Works this paper leans on
-
[1]
Octopack: Instruction tuning code large language models,
(why) is my prompt getting worse? rethink- ing regression testing for evolving llm apis. InPro- ceedings of the IEEE/ACM 3rd International Confer- ence on AI Engineering-Software Engineering for AI, pages 166–171. Steve McConnell. 1998.Software project survival guide. Pearson Education. Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui...
-
[2]
Shopping queries dataset: A large-scale ESCI benchmark for improving product search.arXiv preprint arXiv:2206.06588. Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, and 1 others. 2021. Multitask prompted training en- ables zero-shot task generalization.a...
-
[3]
Prompting in the wild: An empirical study of prompt evolution in software repositories.arXiv preprint arXiv:2412.17298. Axel Van Lamsweerde. 2009.Requirements engineer- ing: From system goals to UML models to software, volume 10. Chichester, UK: John Wiley & Sons. Sanidhya Vijayvargiya, Xuhui Zhou, Akhila Yerukola, Maarten Sap, and Graham Neubig. 2025. In...
-
[4]
arXiv preprint arXiv:2502.02533 , year=
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Pro- cessing Systems, 36:46595–46623. Han Zhou, Xingchen Wan, Ruoxi Sun, Hamid Palangi, Shariq Iqbal, Ivan Vuli´c, Anna Korhonen, and Ser- can Ö Arık. 2025. Multi-agent design: Optimizing agents with better prompts and topologies.arXiv preprint arXiv:2502.02533. Jeffrey ...
-
[5]
If there are no key classes, this requirement is not applicable
Identify the key classes in the given code snippet by examining the code structure and class definitions. If there are no key classes, this requirement is not applicable
-
[6]
Check that the explanation clearly highlights which classes are considered "key" for this snippet (for example,anyclasses that define core functionality or are central to the code's purpose)
-
[7]
Verify that the explanation includes concrete examples showing how to instantiate the identified key classes
-
[8]
accurate numerical values in summaries
Finally, assess whether the explanation meets the requirement by providing sufficient instantiation and usage examples that a user could follow. You are a reviewer who is evaluating whether a model output satisfies the given requirement. Given a task description, examples, and requirement, write a Python function to evaluate the requirement. The Python fu...
work page 2024
-
[9]
**Overview**: Begin with a high-level summary that sets the context for the code’s purpose and functionality
-
[10]
**Purpose and Benefits**: Clearly explain the code’s main objective and highlight scenarios where its features are particularly beneficial or efficient
-
[11]
**Analogies and Examples**: Use relatable analogies and examples to enhance understanding, especially for complex concepts
-
[12]
**Code Breakdown**: Decompose the code into its fundamental components, explaining the role and function of each part
-
[13]
**Step-by-Step Execution**: Offer a precise, sequential walkthrough of how the code executes, ensuring clarity on the process
-
[14]
**State Changes and Side Effects**: Identify any potential side effects or state changes that occur during execution
-
[15]
**Variable and Data Structure Explanation**: Define and explain any variables or data structures used, ensuring comprehension for those with minimal coding knowledge
-
[16]
**Technical Jargon**: Simplify or clarify any technical terms to make the explanation accessible
-
[17]
**Setup Verification**: Include information on verifying the setup or configuration before running the code, if relevant
-
[18]
**Error Handling**: Describe any error handling mechanisms, detailing how they manage potential errors and edge cases
-
[19]
**Dependencies**: Identify any libraries or dependencies required by the code
-
[20]
**Applications and Implications**: Discuss potential applications and implications of the algorithm or functionality provided by the code
-
[21]
**Function Usage Example**: Provide an example of how at least one function, class, or constant from the code can be utilized
-
[22]
**Conciseness**: Ensure the explanation does not exceed 500 words, maintaining focus and clarity. Figure 16: COPRO-optimized prompts (acc=86.7%). We found COPRO-optimized prompts tend to reorder requirements in a more logical structure, merge related requirements together, and sometimes drop requirements. D Additional tasks setups and results Tasks and da...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.