Model Internal Sleuthing: Finding Lexical Identity and Inflectional Features in Modern Language Models
Pith reviewed 2026-05-19 10:53 UTC · model grok-4.3
The pith
Language models preserve grammatical inflection features across all layers but lose specific word identities as they deepen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
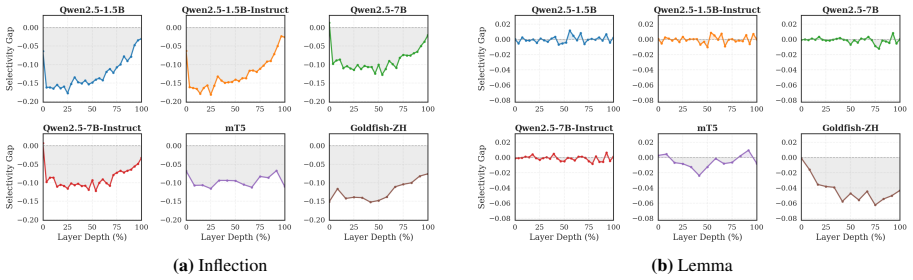
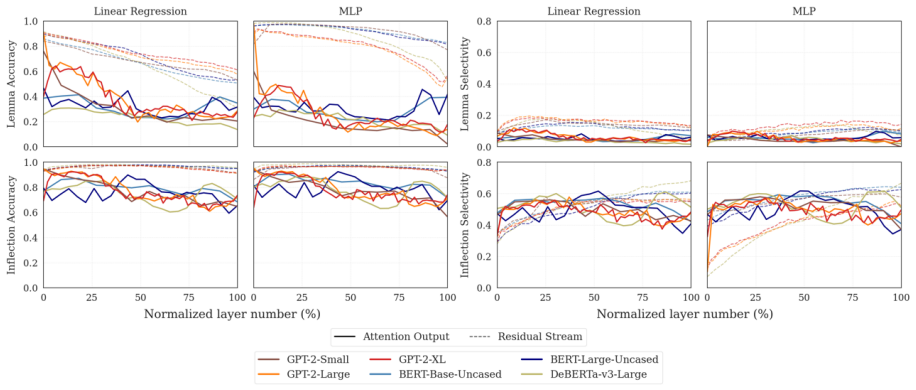
Transformers maintain inflectional features across layers, while trading off lexical identity for compact, predictive representations. Inflectional features are linearly decodable throughout the model, while lexical identity is prominent early but increasingly weakens with depth. Further analysis of the representation geometry reveals that models with aggressive mid-layer dimensionality compression show reduced steering effectiveness in those layers, despite probe accuracy remaining high. Pretraining analysis shows that inflectional structure stabilizes early while lexical identity representations continue evolving.
What carries the argument
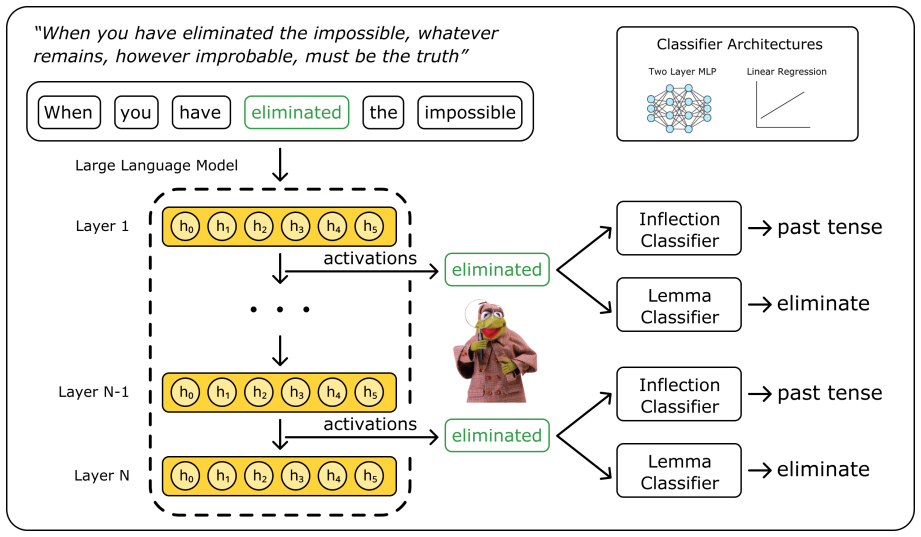
Linear probes on hidden states that measure decodability of lexical identity versus inflectional features at each layer.
If this is right
- Inflectional features remain steerable at any layer depth.
- Lexical identity becomes harder to steer or edit in deeper layers.
- Aggressive mid-layer dimensionality compression reduces steering effectiveness for lexical features.
- Inflectional structure forms early in pretraining and stays stable while lexical representations keep evolving.
Where Pith is reading between the lines
- This compression pattern may help explain how models generalize to new word forms by focusing on abstract features.
- Layer-specific editing tools could apply grammatical changes at any depth and lexical changes only early on.
- The same trade-off might appear when probing other properties such as semantic roles.
- Measuring exact word recall on tasks after mid-layer interventions would test the claimed weakening of lexical identity.
Load-bearing premise
That high accuracy from linear probes means the model is actually using those features for its predictions rather than merely correlating with them.
What would settle it
A model or layer in which lexical identity stays strongly decodable in deep layers while inflectional features lose decodability, or where high probe accuracy fails to predict steering success.
Figures


























read the original abstract
Large transformer-based language models dominate modern NLP, yet our understanding of how they encode linguistic information relies primarily on studies of early models like BERT and GPT-2. We systematically probe 25 models from BERT Base to Qwen2.5-7B focusing on two linguistic properties: lexical identity and inflectional features across 6 diverse languages. We find a consistent pattern: inflectional features are linearly decodable throughout the model, while lexical identity is prominent early but increasingly weakens with depth. Further analysis of the representation geometry reveals that models with aggressive mid-layer dimensionality compression show reduced steering effectiveness in those layers, despite probe accuracy remaining high. Pretraining analysis shows that inflectional structure stabilizes early while lexical identity representations continue evolving. Taken together, our findings suggest that transformers maintain inflectional features across layers, while trading off lexical identity for compact, predictive representations. Our code is available at https://github.com/ml5885/model_internal_sleuthing
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically probes 25 transformer LMs (BERT Base to Qwen2.5-7B) across 6 languages for lexical identity and inflectional features. It reports that inflectional features remain linearly decodable throughout all layers while lexical identity is strong early but progressively weakens with depth. Geometry analysis finds that models with aggressive mid-layer dimensionality compression exhibit reduced steering effectiveness despite sustained high probe accuracy. Pretraining dynamics show inflectional structure stabilizing early while lexical representations continue to evolve. The authors conclude that transformers maintain inflectional features across layers while trading off lexical identity for compact, predictive representations. Code is released at the provided GitHub link.
Significance. If the findings hold after addressing the noted issues, the work provides a systematic, multi-model, multi-language extension of probing studies beyond early models such as BERT and GPT-2. The explicit reporting of a dissociation between linear decodability and steering effectiveness in compressed layers is a useful contribution to the interpretability literature. Public code availability supports reproducibility and is a clear strength.
major comments (1)
- [Abstract and geometry analysis] Abstract and geometry analysis section: The central claim that models 'maintain inflectional features across layers' is grounded in consistent linear decodability, yet the manuscript itself reports reduced steering effectiveness in mid-layers with aggressive dimensionality compression despite high probe accuracy. This dissociation directly challenges the inference from probe success to actual maintenance and usage of the features for predictions, which is load-bearing for the trade-off interpretation.
minor comments (2)
- [Abstract] The abstract states 'consistent pattern' and 'high probe accuracy' but provides no numerical values, confidence intervals, or statistical tests; adding these (or directing readers to the relevant table/figure) would improve clarity without altering the claims.
- [Abstract] The languages studied are described only as '6 diverse languages'; listing them explicitly would aid readers in assessing generalizability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comment on the abstract and geometry analysis raises an important point about the interpretation of our results, which we address below by clarifying the distinction between linear decodability and steering while preserving the empirical claims of the manuscript.
read point-by-point responses
-
Referee: [Abstract and geometry analysis] Abstract and geometry analysis section: The central claim that models 'maintain inflectional features across layers' is grounded in consistent linear decodability, yet the manuscript itself reports reduced steering effectiveness in mid-layers with aggressive dimensionality compression despite high probe accuracy. This dissociation directly challenges the inference from probe success to actual maintenance and usage of the features for predictions, which is load-bearing for the trade-off interpretation.
Authors: We appreciate the referee highlighting this nuance. The manuscript reports both high probe accuracy and reduced steering effectiveness specifically to document their dissociation in layers undergoing aggressive dimensionality compression. We interpret 'maintain' as the continued linear decodability of inflectional features, which remains high across all layers and models; this is distinct from claiming that the features are used identically in every forward pass. The steering results are presented as evidence of geometric reorganization that favors compact representations, consistent with the overall trade-off between lexical identity (which weakens in decodability) and inflectional structure (which does not). We do not equate probe success with direct causal usage in all cases. To address the concern, we have revised the abstract to foreground 'remain linearly decodable' and added a short clarifying paragraph in the geometry analysis section that explicitly discusses the probe-steering dissociation and its implications for the maintenance claim. These changes strengthen the precision of the interpretation without altering the reported findings or conclusions. revision: yes
Circularity Check
No circularity: empirical observations from probes and geometry
full rationale
The manuscript reports direct empirical measurements of linear probe accuracy for lexical identity and inflectional features across layers in 25 models, plus geometry analysis and steering experiments. These are observational results from applying standard probing techniques to model activations; no equations, fitted parameters, or derivations are presented that reduce the reported patterns to quantities defined by the paper's own inputs. Pretraining dynamics and cross-layer comparisons are independent measurements, and the interpretive summary follows from the observed dissociation between probe accuracy and steering effectiveness without self-referential reduction or load-bearing self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Linear probes on hidden states faithfully indicate whether a linguistic feature is represented and used by the model
Forward citations
Cited by 4 Pith papers
-
Inference-Time Machine Unlearning via Gated Activation Redirection
GUARD-IT performs machine unlearning in LLMs via inference-time gated activation redirection, matching or exceeding gradient-based baselines on TOFU and MUSE while preserving utility and working under quantization.
-
Gradients with Respect to Semantics Preserving Embeddings Tell the Uncertainty of Large Language Models
SemGrad is a gradient-based uncertainty quantification technique for free-form LLM generation that operates in semantic space using a Semantic Preservation Score to select stable embeddings.
-
Defragmenting Language Models: An Interpretability-based Approach for Vocabulary Expansion
Interpretability-based selection of vocabulary items plus FragMend initialization reduces token over-fragmentation and improves performance for non-Latin script languages by roughly 20 points over baselines.
-
Inference-Time Machine Unlearning via Gated Activation Redirection
GUARD-IT performs machine unlearning in LLMs via input-dependent activation steering at inference time, matching or exceeding gradient-based baselines on TOFU and MUSE while preserving utility and working under quantization.
Reference graph
Works this paper leans on
-
[1]
Yossi Adi, Einat Kermany, Yonatan Belinkov, Ofer Lavi, and Yoav Goldberg. 2017. https://openreview.net/forum?id=BJh6Ztuxl Fine-grained analysis of sentence embeddings using auxiliary prediction tasks . In 5th International Conference on Learning Representations (Conference Track)
work page 2017
-
[2]
Guillaume Alain and Yoshua Bengio. 2017. https://openreview.net/forum?id=ryF7rTqgl Understanding intermediate layers using linear classifier probes . In 5th International Conference on Learning Representations (Workshop Track)
work page 2017
-
[3]
Yonatan Belinkov and James Glass. 2019. https://doi.org/10.1162/tacl_a_00254 Analysis methods in neural language processing: A survey . Transactions of the Association for Computational Linguistics, 7:49--72
-
[4]
Leo Breiman. 2001. https://doi.org/10.1023/A:1010933404324 Random forests . Mach. Learn., 45(1):5–32
-
[5]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, and 6 others. 2023. Towards monosemanticity: Decomposing language models with d...
work page 2023
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, and 12 others. 2020. https://arxiv.org/abs/2005.14165 Lan...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[7]
Chang, Catherine Arnett, Zhuowen Tu, and Benjamin K
Tyler A. Chang, Catherine Arnett, Zhuowen Tu, and Benjamin K. Bergen. 2024. https://arxiv.org/abs/2408.10441 Goldfish: Monolingual language models for 350 languages . Preprint, arXiv:2408.10441
work page internal anchor Pith review arXiv 2024
-
[8]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2023. https://arxiv.org/abs/2309.08600 Sparse autoencoders find highly interpretable features in language models . Preprint, arXiv:2309.08600
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://doi.org/10.18653/v1/N19-1423 BERT : Pre-training of deep bidirectional transformers for language understanding . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long a...
-
[10]
Yanai Elazar, Shauli Ravfogel, Alon Jacovi, and Yoav Goldberg. 2021. https://doi.org/10.1162/tacl_a_00359 Amnesic Probing: Behavioral Explanation with Amnesic Counterfactuals . Transactions of the Association for Computational Linguistics, 9:160--175
-
[11]
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, and 6 others. 2021. A mathematical framework for transformer circuits. Transformer C...
work page 2021
-
[12]
Kawin Ethayarajh. 2019. https://doi.org/10.18653/v1/D19-1006 How contextual are contextualized word representations? C omparing the geometry of BERT , ELM o, and GPT -2 embeddings . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCN...
-
[13]
Atticus Geiger, Hanson Lu, Thomas F Icard, and Christopher Potts. 2021. https://openreview.net/forum?id=RmuXDtjDhG Causal abstractions of neural networks . In Advances in Neural Information Processing Systems
work page 2021
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, and 24 others. 2024. https://doi.org/10.18653/v1/2024.acl-long.841 OLM o: Acceleratin...
-
[16]
Trevor Hastie, Robert Tibshirani, and Jerome Friedman. 2009. https://web.stanford.edu/ hastie/ElemStatLearn/ The Elements of Statistical Learning: Data Mining, Inference, and Prediction , 2 edition. Springer, New York, NY, USA
work page 2009
-
[17]
John Hewitt and Percy Liang. 2019. https://doi.org/10.18653/v1/D19-1275 Designing and interpreting probes with control tasks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2733--2743, Hong Kong, China. Association fo...
-
[18]
Kurt Hornik, Maxwell Stinchcombe, and Halbert White. 1989. https://doi.org/10.1016/0893-6080(89)90020-8 Multilayer feedforward networks are universal approximators . Neural Networks, 2(5):359--366
-
[19]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, and 1 others. 2024. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. 2023. https://openreview.net/forum?id=6t0Kwf8-jrj Editing models with task arithmetic . In The Eleventh International Conference on Learning Representations
work page 2023
-
[21]
Ganesh Jawahar, Beno \^i t Sagot, and Djam \'e Seddah. 2019. https://doi.org/10.18653/v1/P19-1356 What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651--3657, Florence, Italy. Association for Computational Linguistics
-
[22]
Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, and 4 others. 2025. https://arxiv.org/abs/2411.15124 Tulu 3: Pushing...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Kenneth Li, Oam Patel, Fernanda Vi \'e gas, Hanspeter Pfister, and Martin Wattenberg. 2023. https://openreview.net/forum?id=aLLuYpn83y Inference-time intervention: Eliciting truthful answers from a language model . In Thirty-seventh Conference on Neural Information Processing Systems
work page 2023
-
[25]
and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. 2019. https://doi.org/10.18653/v1/N19-1112 Linguistic knowledge and transferability of contextual representations . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1...
-
[26]
Kevin Meng, David Bau, Alex J Andonian, and Yonatan Belinkov. 2022. https://openreview.net/forum?id=-h6WAS6eE4 Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems
work page 2022
-
[27]
nostalgebraist. 2020. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens interpreting gpt: the logit lens
work page 2020
-
[28]
Nina Panickssery, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. 2024. https://arxiv.org/abs/2312.06681 Steering llama 2 via contrastive activation addition . Preprint, arXiv:2312.06681
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine learning in P ython. Journal of Machine Learning Research, 12:2825--2830
work page 2011
-
[30]
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9
work page 2019
-
[31]
Anna Rogers, Olga Kovaleva, and Anna Rumshisky. 2020. https://doi.org/10.1162/tacl_a_00349 A primer in BERT ology: What we know about how BERT works . Transactions of the Association for Computational Linguistics, 8:842--866
-
[32]
Frank Rosenblatt. 1958. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review, 65(6):386
work page 1958
-
[33]
Nishant Subramani, Jason Eisner, Justin Svegliato, Benjamin Van Durme, Yu Su, and Sam Thomson. 2025. https://aclanthology.org/2025.naacl-long.615/ MICE for CAT s: Model-internal confidence estimation for calibrating agents with tools . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
work page 2025
-
[34]
Nishant Subramani, Nivedita Suresh, and Matthew Peters. 2022. https://doi.org/10.18653/v1/2022.findings-acl.48 Extracting latent steering vectors from pretrained language models . In Findings of the Association for Computational Linguistics: ACL 2022, pages 566--581, Dublin, Ireland. Association for Computational Linguistics
-
[35]
Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019. https://doi.org/10.18653/v1/P19-1452 BERT rediscovers the classical NLP pipeline . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593--4601, Florence, Italy. Association for Computational Linguistics
-
[36]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/92650b2e92217715fe312e6fa7b90d82-Paper.pdf Investigating gender bias in language models using causal mediation analysis . In Advances in Neural Information Processing Systems, volume ...
work page 2020
-
[37]
Elena Voita and Ivan Titov. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.14 Information-theoretic probing with minimum description length . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 183--196, Online. Association for Computational Linguistics
-
[38]
Ivan Vuli \'c , Edoardo Maria Ponti, Robert Litschko, Goran Glava s , and Anna Korhonen. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.586 Probing pretrained language models for lexical semantics . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7222--7240, Online. Association for Computational ...
-
[39]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
-
[40]
BigScience Workshop. 2023. https://arxiv.org/abs/2211.05100 Bloom: A 176b-parameter open-access multilingual language model . Preprint, arXiv:2211.05100
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Amir Zeldes. 2017. https://doi.org/http://dx.doi.org/10.1007/s10579-016-9343-x The GUM corpus: Creating multilayer resources in the classroom . Language Resources and Evaluation, 51(3):581--612
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.