RExBench: Can coding agents autonomously implement AI research extensions?
Pith reviewed 2026-05-19 07:31 UTC · model grok-4.3
The pith
LLM coding agents autonomously implement only about a third of realistic AI research extensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
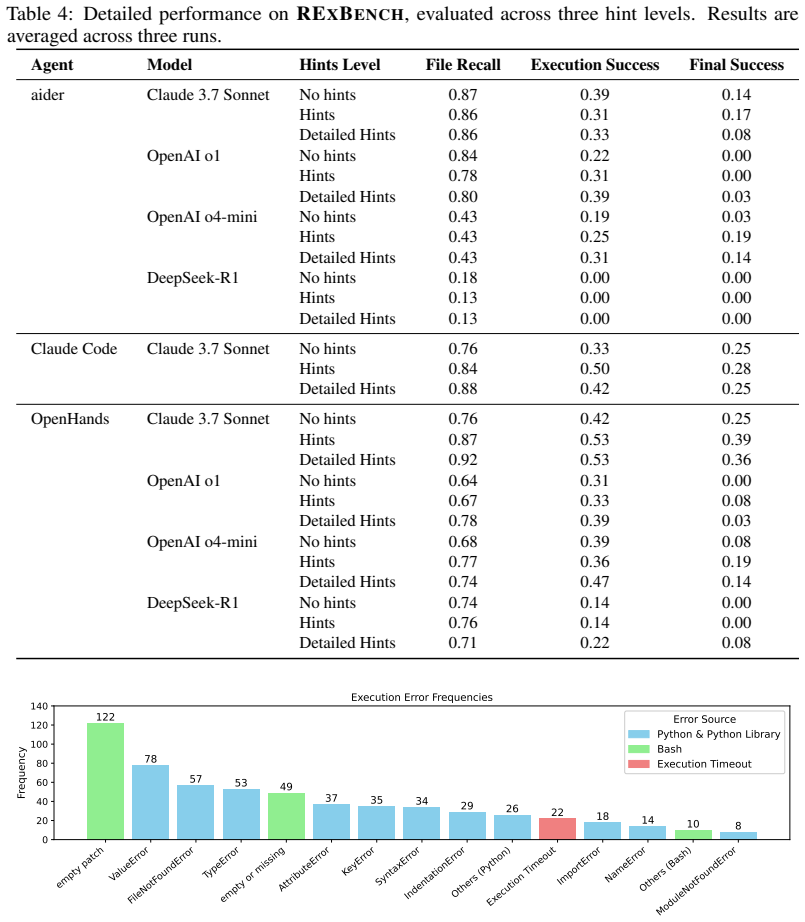
RExBench consists of realistic extensions of 12 research papers that investigate novel hypotheses, each accompanied by domain-expert instructions and an automatic evaluation infrastructure that executes agent outputs to verify success criteria. All evaluated agents fail to autonomously implement the majority of these extensions, with the strongest agent reaching around a 33 percent success rate. Success improves when human-written hints are supplied, yet the best performance in that setting remains below 44 percent. The results indicate that current agents remain short of handling realistic research-extension tasks without substantial human guidance.
What carries the argument
RExBench benchmark of 12 paper extensions with expert instructions and automatic execution-based success evaluation.
Load-bearing premise
The 12 selected extensions and their success criteria represent genuine research-extension difficulty without systematic bias.
What would settle it
A new agent that autonomously completes more than half of the twelve RExBench extensions without hints would challenge the reported performance gap.
Figures





read the original abstract
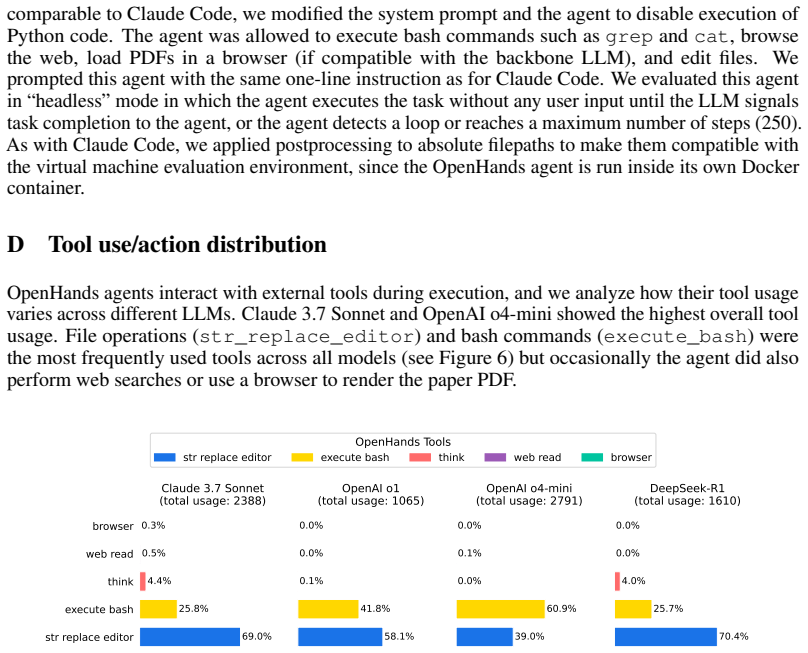
Agents based on Large Language Models (LLMs) have shown promise for performing sophisticated software engineering tasks autonomously. In addition, there has been progress towards developing agents that can perform parts of the research pipeline in machine learning and the natural sciences. We argue that research extension and its implementation is a critical capability for such systems, and introduce RExBench to support the evaluation of this capability. RExBench is a benchmark consisting of realistic extensions of 12 research papers that aim to investigate novel research hypotheses. Each task is set up as an extension to an existing research paper and codebase, accompanied by domain expert-written instructions. RExBench is robust to data contamination and supports an automatic evaluation infrastructure that executes agent outputs to determine whether the success criteria are met. We use this benchmark to evaluate 12 LLM agents implemented using two different frameworks, aider and OpenHands. We find that all agents fail to autonomously implement the majority of the extensions, with the best agent achieving around a 33% success rate. Although the success rate improves with additional human-written hints, the best performance under this setting remains below 44%. This indicates that current agents are still short of being able to handle realistic research extension tasks without substantial human guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RExBench, a benchmark consisting of 12 realistic extensions to existing AI research papers and their codebases, each accompanied by domain-expert instructions and automatic success criteria. It evaluates 12 LLM-based coding agents implemented in the aider and OpenHands frameworks, reporting that the best agent achieves approximately 33% success rate autonomously and below 44% even with additional human-written hints, concluding that current agents cannot handle realistic research-extension tasks without substantial human guidance.
Significance. If the 12 tasks prove representative, the benchmark fills a gap between standard coding benchmarks and full research automation by providing contamination-robust, automatically executable tasks. The automatic evaluation infrastructure and direct execution-based metrics are positive features that could enable reproducible comparisons of future agents on research-like implementation work.
major comments (3)
- [§3] §3 (Task Construction): The manuscript does not describe systematic selection criteria, diversity metrics, or controls for the 12 source papers and extensions. Because the central claim (best agent ~33% success) depends on these tasks fairly sampling realistic research-extension difficulty, the absence of such justification leaves open the possibility that the low rates reflect selection bias rather than a general limitation of current agents.
- [§4.2] §4.2 (Evaluation Protocol): Exact success criteria and their automatic implementations are described only at a high level. Without per-task details on what constitutes a passing execution (e.g., quantitative thresholds, test cases, or handling of partial implementations), it is difficult to assess whether the criteria are free of systematic bias or overly lenient/strict for certain failure modes.
- [Results] Table 1 / Results section: The reported success rates lack error bars, multiple-run statistics, or significance tests. Given that agent performance can vary with temperature and prompt stochasticity, single-run percentages make it hard to determine whether the gap between 33% and 44% (with hints) is reliable.
minor comments (2)
- [Abstract] Abstract: The number of agents (12) and the two frameworks (aider, OpenHands) should be stated explicitly for immediate clarity.
- [§5] §5 (Discussion): Adding even one or two concrete failure-case examples (e.g., a specific extension where agents consistently produce incorrect API calls) would help readers understand the nature of the remaining difficulties.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Task Construction): The manuscript does not describe systematic selection criteria, diversity metrics, or controls for the 12 source papers and extensions. Because the central claim (best agent ~33% success) depends on these tasks fairly sampling realistic research-extension difficulty, the absence of such justification leaves open the possibility that the low rates reflect selection bias rather than a general limitation of current agents.
Authors: We agree that explicit documentation of selection criteria would better support the claim that the 12 tasks are representative. In the revised manuscript we will add a dedicated subsection to §3 that describes the selection process: papers were required to have publicly available codebases, to be published within the last three years, and to span distinct AI sub-areas (NLP, vision, RL, etc.). We will also report simple diversity statistics (e.g., distribution across sub-fields and average code-base size) and acknowledge that the set remains a curated starting point rather than a statistically sampled population. revision: yes
-
Referee: [§4.2] §4.2 (Evaluation Protocol): Exact success criteria and their automatic implementations are described only at a high level. Without per-task details on what constitutes a passing execution (e.g., quantitative thresholds, test cases, or handling of partial implementations), it is difficult to assess whether the criteria are free of systematic bias or overly lenient/strict for certain failure modes.
Authors: We accept that the current high-level description limits reproducibility and scrutiny. We will expand §4.2 with a table or appendix that lists, for each task, the precise success criterion (including any quantitative thresholds or test scripts), how partial implementations are scored, and the exact command used by the automatic evaluator. This will allow readers to judge potential leniency or bias on a per-task basis. revision: yes
-
Referee: [Results] Table 1 / Results section: The reported success rates lack error bars, multiple-run statistics, or significance tests. Given that agent performance can vary with temperature and prompt stochasticity, single-run percentages make it hard to determine whether the gap between 33% and 44% (with hints) is reliable.
Authors: We acknowledge that single-run reporting leaves the results vulnerable to stochastic effects. Because of the substantial compute required to run each agent on the full suite of tasks, we initially reported single executions. In the revision we will re-run the two strongest agents (with and without hints) across three random seeds, report mean success rates together with standard deviations, and add a short discussion of observed variability. We will also note that the 33 %–44 % gap should be interpreted with this variability in mind. revision: partial
Circularity Check
No circularity: purely empirical benchmark with direct execution evaluation
full rationale
The paper introduces RExBench as an empirical benchmark consisting of 12 research extensions, expert-written instructions, and automatic success criteria evaluated via agent execution. No derivations, equations, fitted parameters, or predictions appear in the provided abstract or description. Central claims rest on observed success rates (33% best agent, <44% with hints) obtained through direct testing rather than any self-referential construction or self-citation chain. The evaluation infrastructure is falsifiable externally via reproduction on the released tasks. Selection of the 12 papers and criterion validity are potential external-validity concerns but do not constitute circularity under the defined patterns, as no step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
REXBENCH is a benchmark consisting of 12 realistic research experiment implementation tasks... automatic evaluation infrastructure that executes agent outputs to determine whether the success criteria are met.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
What Makes AI Research Replicable? Executable Knowledge Graphs as Scientific Knowledge Representations
xKG is a paper-centric knowledge base that extracts code and insights to improve LLM agent performance on AI research replication by 10.9% on PaperBench.
-
AblateCell: A Reproduce-then-Ablate Agent for Virtual Cell Repositories
AblateCell reproduces baselines in three single-cell perturbation repositories with 88.9% success and recovers ground-truth critical components with 93.3% accuracy via closed-loop ablation.
Reference graph
Works this paper leans on
-
[1]
Aider AI. 2023. Aider: AI pair programming in your terminal. https://github.com/ Aider-AI/aider. Accessed: 2025-05-12
work page 2023
-
[2]
Anthropic. 2024. Claude 3.7 Sonnet System Card. https://assets.anthropic.com/ m/785e231869ea8b3b/original/claude-3-7-sonnet-system-card.pdf . Accessed: 2025-05-14
work page 2024
-
[3]
Ben Bogin, Kejuan Yang, Shashank Gupta, Kyle Richardson, Erin Bransom, Peter Clark, Ashish Sabharwal, and Tushar Khot. 2024. SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research Repositories. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 12622–12645, Miami, Florida, USA. Association for...
work page 2024
-
[4]
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. 2023. Autonomous chemical research with large language models. Nature, 624(7992):570–578
work page 2023
- [5]
-
[6]
Jonathan H. Choi. 2024. How to use large language models for empirical legal research.Journal of Institutional and Theoretical Economics (JITE) , 180(2):214–233
work page 2024
-
[7]
Róbert Csordás, Kazuki Irie, and Juergen Schmidhuber. 2021. The Devil is in the Detail: Simple Tricks Improve Systematic Generalization of Transformers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages 619–634, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics. 10
work page 2021
-
[8]
Singularity Developers. 2021. Singularity
work page 2021
-
[9]
Jiangshu Du, Yibo Wang, Wenting Zhao, Zhongfen Deng, Shuaiqi Liu, Renze Lou, Henry Peng Zou, Pranav Narayanan Venkit, Nan Zhang, Mukund Srinath, Haoran Ranran Zhang, Vipul Gupta, Yinghui Li, Tao Li, Fei Wang, Qin Liu, Tianlin Liu, Pengzhi Gao, Congying Xia, Chen Xing, Cheng Jiayang, Zhaowei Wang, Ying Su, Raj Sanjay Shah, Ruohao Guo, Jing Gu, Haoran Li, K...
work page 2024
-
[10]
Cole, Fangyu Liu, and William W
Julian Martin Eisenschlos, Jeremy R. Cole, Fangyu Liu, and William W. Cohen. 2023. WinoDict: Probing language models for in-context word acquisition. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages 94–102, Dubrovnik, Croatia. Association for Computational Linguistics
work page 2023
- [11]
-
[12]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, et al. 2025. Towards an AI co-scientist. arXiv:2502.18864
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Zhang, Lanyi Zhu, Mike A Merrill, Jeffrey Heer, and Tim Althoff
Ken Gu, Ruoxi Shang, Ruien Jiang, Keying Kuang, Richard-John Lin, Donghe Lyu, Yue Mao, Youran Pan, Teng Wu, Jiaqian Yu, Yikun Zhang, Tianmai M. Zhang, Lanyi Zhu, Mike A Merrill, Jeffrey Heer, and Tim Althoff. 2024. BLADE: Benchmarking Language Model Agents for Data-Driven Science. In Findings of the Association for Computational Linguistics: EMNLP 2024, p...
work page 2024
-
[14]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Liu, Percy Liang, and Christopher D
John Hewitt, Nelson F. Liu, Percy Liang, and Christopher D. Manning. 2024. Instruction following without instruction tuning. arXiv:2409.14254
-
[16]
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. 2024. MLAgentBench: evaluating language agents on machine learning experimentation. In Proceedings of the 41st International Conference on Machine Learning, pages 20271–20309
work page 2024
-
[17]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. 2024. OpenAI o1 system card. arXiv:2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Peter Jansen, Oyvind Tafjord, Marissa Radensky, Pao Siangliulue, Tom Hope, Bhavana Dalvi Mishra, Bodhisattwa Prasad Majumder, Daniel S. Weld, and Peter Clark. 2025. CodeSci- entist: End-to-End Semi-Automated Scientific Discovery with Code-based Experimentation. arXiv:2503.22708
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues? In The Twelfth International Conference on Learning Representations
work page 2024
- [20]
-
[21]
Julie Kallini, Isabel Papadimitriou, Richard Futrell, Kyle Mahowald, and Christopher Potts
-
[22]
Mission: Impossible Language Models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 14691–14714, Bangkok, Thailand. Association for Computational Linguistics. 11
-
[23]
Najoung Kim and Tal Linzen. 2020. COGS: A Compositional Generalization Challenge Based on Semantic Interpretation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 9087–9105, Online. Association for Computational Linguistics
work page 2020
- [24]
-
[25]
Hiroaki Kitano. 2021. Nobel Turing Challenge: creating the engine for scientific discovery. NPJ systems biology and applications , 7(1):29
work page 2021
- [26]
-
[27]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
Jon M. Laurent, Joseph D. Janizek, Michael Ruzo, Michaela M. Hinks, Michael J. Hammerling, Siddharth Narayanan, Manvitha Ponnapati, Andrew D. White, and Samuel G. Rodriques. 2024. Lab-bench: Measuring capabilities of language models for biology research. arXiv:2407.10362
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Yukyung Lee, Joonghoon Kim, Jaehee Kim, Hyowon Cho, Pilsung Kang, and Najoung Kim
-
[29]
Checkeval: A reliable LLM-as-a-judge framework for evaluating text generation using checklists. arXiv:2403.18771
-
[30]
Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg
Kenneth Li, Aspen K. Hopkins, David Bau, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023. Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task. In The Eleventh International Conference on Learning Representations
work page 2023
-
[31]
Sihang Li, Jin Huang, Jiaxi Zhuang, Yaorui Shi, Xiaochen Cai, Mingjun Xu, Xiang Wang, Linfeng Zhang, Guolin Ke, and Hengxing Cai. 2025. SciLitLLM: How to Adapt LLMs for Scientific Literature Understanding. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[32]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv:2408.06292
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [33]
-
[34]
Neel Nanda, Andrew Lee, and Martin Wattenberg. 2023. Emergent Linear Representations in World Models of Self-Supervised Sequence Models. In Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages 16–30, Singapore. Association for Computational Linguistics
work page 2023
- [35]
- [36]
-
[37]
Chan Jun Shern, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, et al. 2024. MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering. arXiv:2410.07095
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [38]
-
[39]
Zachary S Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan
-
[40]
Transactions on Machine Learning Research
CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark. Transactions on Machine Learning Research
-
[41]
Michael D. Skarlinski, Sam Cox, Jon M Laurent, James D. Braza, Michaela Hinks, Michael J. Hammerling, Manvitha Ponnapati, Samuel G. Rodriques, and Andrew D. White. 2024. Lan- guage agents achieve superhuman synthesis of scientific knowledge. arXiv:2409.13740. 12
-
[42]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, et al. 2025. PaperBench: Evaluating AI’s Ability to Replicate AI Research. arXiv:2504.01848
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Zilu Tang, Mayank Agarwal, Alexander Shypula, Bailin Wang, Derry Wijaya, Jie Chen, and Yoon Kim. 2023. Explain-then-translate: an analysis on improving program translation with self-generated explanations. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 1741–1788, Singapore. Association for Computational Linguistics
work page 2023
-
[44]
Minyang Tian, Luyu Gao, Dylan Zhang, Xinan Chen, Cunwei Fan, Xuefei Guo, Roland Haas, Pan Ji, Kittithat Krongchon, Yao Li, Shengyan Liu, Di Luo, Yutao Ma, HAO TONG, Kha Trinh, Chenyu Tian, Zihan Wang, Bohao Wu, Shengzhu Yin, Minhui Zhu, Kilian Lieret, Yanxin Lu, Genglin Liu, Yufeng Du, Tianhua Tao, Ofir Press, Jamie Callan, Eliu A Huerta, and Hao Peng
-
[45]
SciCode: A Research Coding Benchmark Curated by Scientists. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
-
[46]
Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Yinxu Pan, Yesai Wu, Hui Haotian, Liu Weichuan, Zhiyuan Liu, and Maosong Sun. 2024. DebugBench: Evaluating Debugging Capability of Large Language Models. In Findings of the Association for Computational Linguistics: ACL 2024 , pages 4173–4198, Bangkok, Thailand. Association for Computational Linguistics
work page 2024
-
[47]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2025. OpenHands: An Open Platform for A...
work page 2025
-
[48]
Leon Weber-Genzel, Siyao Peng, Marie-Catherine De Marneffe, and Barbara Plank. 2024. VariErr NLI: Separating Annotation Error from Human Label Variation. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 2256–2269, Bangkok, Thailand. Association for Computational Linguistics
work page 2024
-
[49]
Zhaofeng Wu, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. 2024. Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: ...
work page 2024
- [50]
-
[51]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Z. Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Maben, Raj Mehta, Wayne Chi, Lawrence Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. 2024. TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Xiaohan Xu, Chongyang Tao, Tao Shen, Can Xu, Hongbo Xu, Guodong Long, Jian-Guang Lou, and Shuai Ma. 2024. Re-Reading Improves Reasoning in Large Language Models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages 15549–15575, Miami, Florida, USA. Association for Computational Linguistics
work page 2024
-
[53]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In Advances in Neural Information Processing Systems, volume 36, pages 11809–11822. Curran Associates, Inc. 13
work page 2023
- [54]
-
[55]
Caleb Ziems, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Yang. 2024. Can Large Language Models Transform Computational Social Science? Computational Linguistics, 50(1):237–291. 14 A An Example Task Instruction (Extension of WinoDict) WinoDict Task Instruction Problem Description Background The paperWinoDict: Probing language models for i...
work page 2024
-
[56]
Top Group: • Verbs, Nouns, Adverbs: Select the top 20% most frequent words • Adjectives: Select the top 35% most frequent adjectives (to match the sample set size)
-
[57]
Bottom Group: • Verbs, Nouns, Adverbs: Select the bottom 20% least frequent words • Adjectives: Select the bottom 35% least frequent adjectives
-
[58]
Read the instructions in instructions.md and carry out the specified task
All Group: • Verbs, Nouns, Adjectives, Adverbs: Include all words, no frequency-based filtering Assume that the frequency information will be provided in a form of four files corre- sponding to each POS, named 1_all_rank_noun.txt, 2_all_rank_verb.txt, 3_all_rank_adjective.txt, 4_all_rank_adverb.txt, under the directory./words/. Each file lists words in de...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.