Elite Polarization in European Parliamentary Speeches: a Novel Measurement Approach Using Large Language Models
Pith reviewed 2026-05-19 05:28 UTC · model grok-4.3
The pith
Large language models extract a directed negativity score from parliamentary speeches to measure elite polarization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
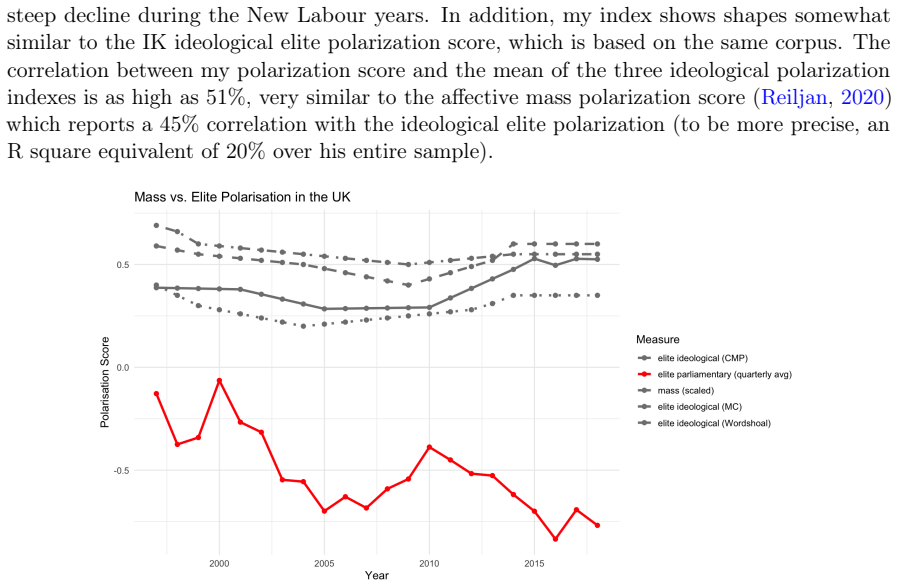
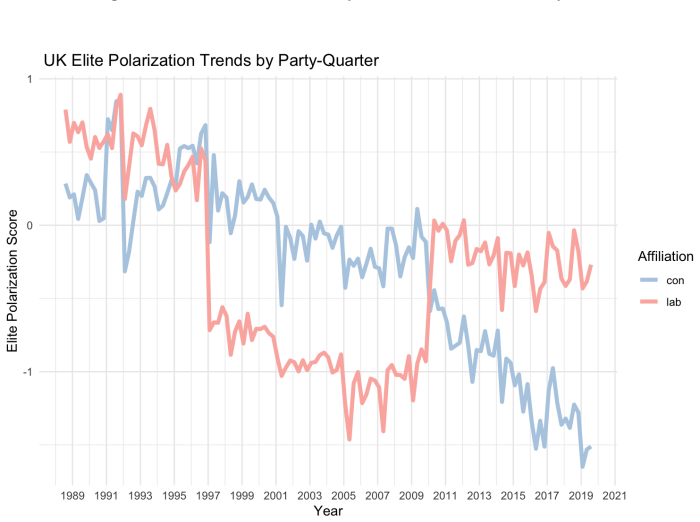
The Elite Polarization Score measures out-party evaluations in parliamentary speech by using large language models to identify political actors mentioned in debates, recover speaker-target pairs, estimate the sentiment directed at each actor, standardize heterogeneous references into party dyads, and aggregate these evaluations into party- and parliament-level measures of mutual out-party negativity. The resulting measure is conceptually distinct from mass affective polarization, elite ideological polarization, incivility, negative campaigning, and general sentiment. Evidence from the UK case study shows that it is also empirically distinct from mass affective polarization, elite ideological
What carries the argument
The Elite Polarization Score, which aggregates standardized directed negativity from speaker-target pairs identified by LLMs in parliamentary debates into party- and parliament-level measures of mutual out-party negativity.
If this is right
- The measure can track changes in elite negativity by party and quarter over multiple decades without retraining.
- Extreme negative evaluations can identify pernicious polarization rhetoric in ongoing debates.
- Multilingual application across countries enables systematic cross-national comparison of elite polarization levels.
- Quarterly aggregation supports analysis of short-term fluctuations linked to events or coalitions.
Where Pith is reading between the lines
- The same extraction pipeline could be applied to legislative texts in additional countries to test whether elite negativity correlates with policy gridlock.
- Linking the score to mass survey data over time would allow testing whether elite hostility precedes or follows shifts in public polarization.
- If the score predicts democratic backsliding in longitudinal data, targeted monitoring of parliamentary rhetoric could inform early-warning systems.
Load-bearing premise
LLM-based sentiment estimates on political speech accurately recover directed negativity without systematic bias from training data, prompt wording, or cross-lingual performance differences.
What would settle it
A new validation study on parliamentary speeches from a fourth country in which human coders rate a sample of speaker-target pairs and the LLM scores show correlations below 0.7 or average error exceeding 10 percent of the scale range.
Figures
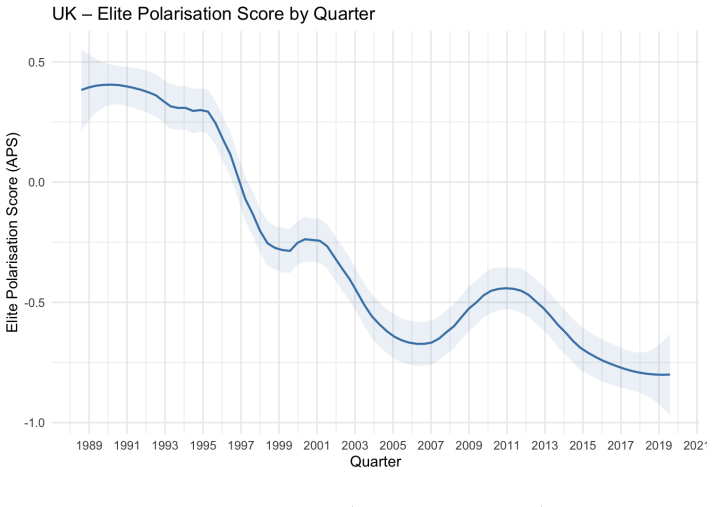
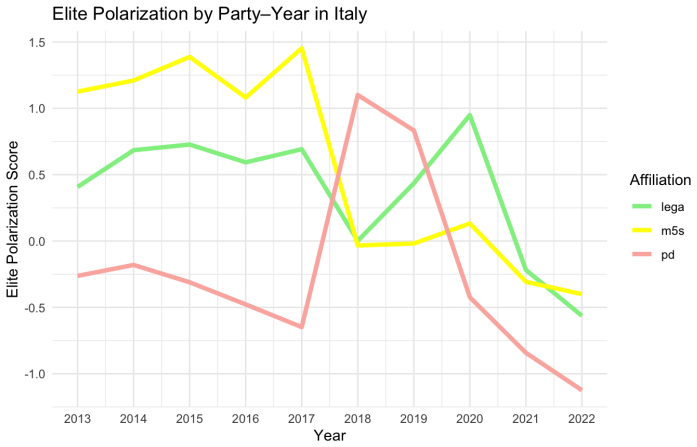
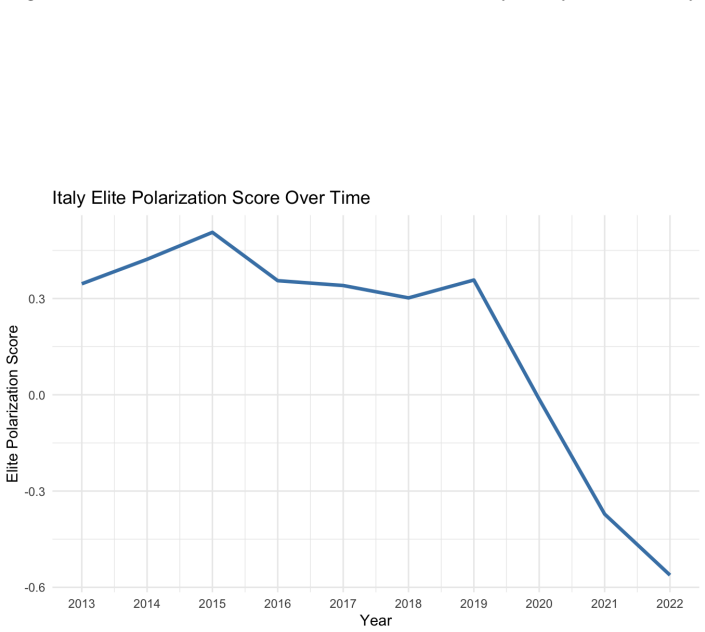
read the original abstract
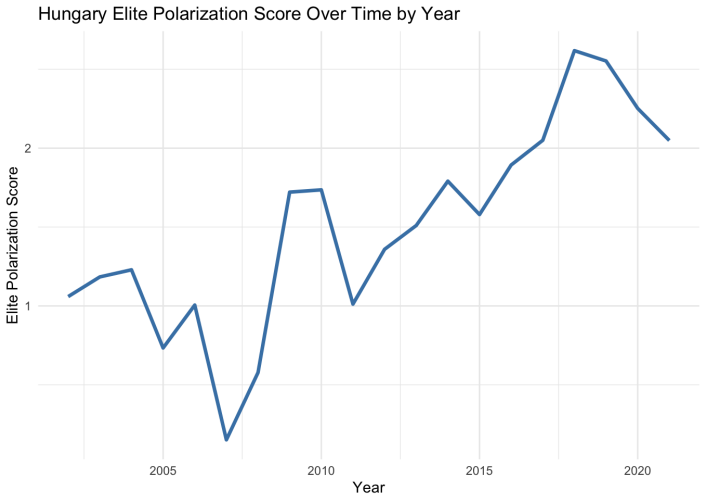
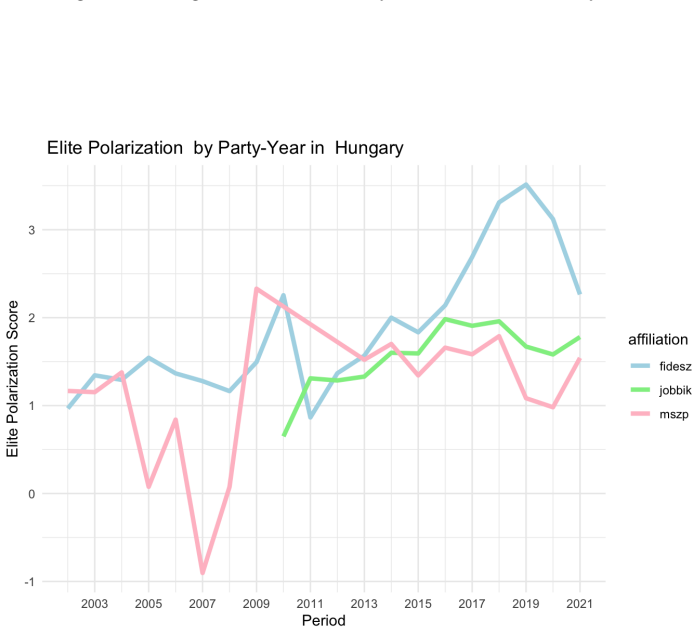
Theories of democratic stability, populism, and party-system crisis often point to a form of polarization that comparative research rarely measures directly: hostile relations among political elites. Existing comparative measures capture adjacent phenomena, including mass affective polarization, or elite ideological distance, but not directed mutual elite evaluation. This paper introduces the Elite Polarization Score, a measurement of out-party evaluations in parliamentary speech. Large Language Models identify political actors mentioned in parliamentary debates, recover speaker-target pairs, estimate the sentiment directed at each actor, standardize heterogeneous references into party dyads, and aggregate these evaluations into party- and parliament-level measures of mutual out-party negativity. The validity of the approach is demonstrated on parliamentary corpora from the United Kingdom, Hungary, and Italy, covering up to four decades of debate. The resulting measure is conceptually distinct from mass affective polarization, elite ideological polarization, incivility, negative campaigning, and general sentiment. Evidence from the UK case study shows that it is also empirically distinct from mass affective polarization, elite ideological polarization, and incivility. Extreme negative evaluations can also be used to locate pernicious polarization rhetoric. Validation across three countries finds no false discoveries, sentiment estimates accurate to roughly 10 percent of the scale range, and AI sensitivity that meets or exceeds that of human coders in two of three settings. Because the algorithm is multilingual, requires no task-specific training, and can be aggregated by party and quarter, it provides a scalable basis for future cross-national research on what produces elite polarization and what elite polarization itself produces
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Elite Polarization Score, a measure of directed out-party negativity extracted from parliamentary speeches via LLMs. The pipeline identifies mentioned political actors, recovers speaker-target pairs, assigns sentiment scores, standardizes references to party dyads, and aggregates to party- and parliament-level scores. Validity is shown on UK, Hungarian, and Italian corpora spanning up to four decades, with claims of conceptual distinctness from mass affective polarization, elite ideological polarization, incivility, negative campaigning, and general sentiment, plus empirical distinctness in the UK case. Validation reports no false discoveries, sentiment accuracy to roughly 10 percent of the scale range, and AI sensitivity meeting or exceeding human coders in two of three settings. The method is multilingual and requires no task-specific training.
Significance. If the central assumption holds, the work supplies a scalable, multilingual, parameter-free approach to measuring elite-level directed hostility that is conceptually and empirically separable from adjacent constructs. This directly addresses gaps in theories of democratic stability, populism, and party-system crisis. Credit is due for the cross-country validation showing no false discoveries, the use of raw speech data without outcome-fitting, the demonstration that AI sensitivity meets or exceeds human coders in two settings, and the potential for quarter-level aggregation in future comparative research.
major comments (1)
- [§5] §5 (Validation across three countries): The reported checks establish no false discoveries and sentiment accuracy within 10 percent of the scale range, with AI performance meeting or exceeding human coders in two settings. However, the section provides limited detail on prompt engineering, exact model version, or robustness checks against systematic directional biases arising from training data or prompt wording. Because the distinctness claims (both conceptual and empirical) rest on the LLM recovering directed negativity without bias that correlates with ideology or affect, this gap is load-bearing for the central argument.
minor comments (1)
- [Abstract] The abstract states coverage of 'up to four decades of debate' but does not list the precise start and end years for each national corpus; adding these dates would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our paper. Their comments highlight important areas for improving the transparency and robustness of our LLM-based measurement approach. We address the major comment in detail below and have made revisions to the manuscript to incorporate additional details and checks as suggested.
read point-by-point responses
-
Referee: [§5] §5 (Validation across three countries): The reported checks establish no false discoveries and sentiment accuracy within 10 percent of the scale range, with AI performance meeting or exceeding human coders in two settings. However, the section provides limited detail on prompt engineering, exact model version, or robustness checks against systematic directional biases arising from training data or prompt wording. Because the distinctness claims (both conceptual and empirical) rest on the LLM recovering directed negativity without bias that correlates with ideology or affect, this gap is load-bearing for the central argument.
Authors: We appreciate the referee highlighting the importance of transparency in our LLM validation procedures. To address this, we will revise §5 to include the complete set of prompts used for each step of the pipeline: actor identification, speaker-target pair recovery, sentiment assignment, and standardization to party dyads. We will also explicitly state the model version utilized (a single consistent model across the UK, Hungarian, and Italian corpora). Additionally, we will incorporate new robustness checks, such as re-running analyses with alternative prompt phrasings and testing for directional biases by stratifying results by speaker ideology and target party. These enhancements will bolster confidence that our measure captures directed negativity without systematic ideological or affective biases, thereby supporting the distinctness claims. We agree this information is essential for the paper's central argument. revision: yes
Circularity Check
No circularity: direct LLM pipeline on raw speeches yields the score without fitting or self-referential reduction
full rationale
The paper constructs the Elite Polarization Score via an explicit sequence of operations on the input parliamentary corpora: LLM identification of mentioned actors, recovery of speaker-target pairs, sentiment estimation for each directed evaluation, standardization of references into party dyads, and aggregation to party- and parliament-level negativity measures. These steps are computational transformations of the raw text data rather than a model whose parameters are chosen or fitted to reproduce the target polarization construct. No equations are shown that equate the final score to an input by construction, and the provided text contains no self-citations used to justify uniqueness or to smuggle in an ansatz. Separate validation (accuracy to ~10% of scale range, no false discoveries, AI sensitivity meeting or exceeding human coders) functions as external benchmarking rather than circular justification. The derivation chain therefore remains self-contained against the raw speech inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM sentiment estimates on parliamentary text recover true directed negativity with error bounded by roughly 10 percent of the scale range
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The EPS can be calculated at various levels... EP_Sn = sum_m≠n [-Like_m · Ref.share_m / (1 - Ref.share_n)] ... parliament-level EP score... weighted out-party sentiment on a 10-point scale.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LLMs identify political actors... recover speaker-target pairs, estimate the sentiment directed at each actor, standardize heterogeneous references into party dyads, and aggregate these evaluations into party- and parliament-level measures of mutual out-party negativity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Struggle Over Borders: Cosmopolitanism and Communitarianism
“The Struggle Over Borders: Cosmopolitanism and Communitarianism.”Cambridge University Press. https://doi.org/10.1017/9781108673311 DiMaggio, Paul, John Evans and Bethany Bryson. 1996. “Have American’s Social Attitudes Become More Polarized?”American Journal of Sociology102(3):690–755. https://www.journals.uchicago.edu/doi/10.1086/230995 Druckman, James N...
-
[2]
“The Origins and Consequences of Affective Polarization in the United States.”Annual Review of Political Science22(1):129–146. https://www.annualreviews.org/doi/10.1146/annurev-polisci-051117-073034 Jurafsky, Daniel and James H. Martin. 2024.Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Spee...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.