Relative Entropy Pathwise Policy Optimization
Pith reviewed 2026-05-19 04:15 UTC · model grok-4.3
The pith
REPPO trains Q-values from on-policy trajectories alone to enable stable low-variance pathwise policy updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Relative Entropy Pathwise Policy Optimization (REPPO) is an on-policy algorithm that trains Q-value models purely from on-policy trajectories to unlock pathwise policy updates. It pairs stochastic policies for exploration with relative-entropy constraints on the updates to maintain stability, and it identifies architectural choices that keep value-function learning reliable under these constraints.
What carries the argument
On-policy Q-value training that supports direct differentiation of the policy objective under relative-entropy constraints.
If this is right
- Pathwise updates become available inside fully on-policy loops without increasing memory footprint.
- Sample efficiency improves relative to prior on-policy algorithms on standard continuous-control benchmarks.
- Wall-clock training time decreases because no replay buffer or off-policy corrections are needed.
- Hyperparameter robustness increases while retaining the minimal implementation complexity of on-policy methods.
Where Pith is reading between the lines
- The same on-policy value-learning strategy could be inserted into other actor-critic algorithms to reduce their dependence on replay buffers.
- Architectural stabilizations developed for the Q-function might transfer to value estimation in other on-policy settings.
- If the method scales, it could simplify deployment of low-variance gradient methods on resource-constrained hardware.
Load-bearing premise
Q-value models can be trained accurately enough for pathwise updates using only on-policy trajectories without any replay buffer or off-policy correction.
What would settle it
An experiment in which on-policy Q-value estimates produce policy-gradient variance equal to or higher than standard score-function methods on the same GPU-parallelized benchmarks.
Figures













read the original abstract
Score-function based methods for policy learning, such as REINFORCE and PPO, have delivered strong results in game-playing and robotics, yet their high variance often undermines training stability. Using pathwise policy gradients, i.e. computing a derivative by differentiating the objective function, alleviates the variance issues. However, they require an accurate action-conditioned value function, which is notoriously hard to learn without relying on replay buffers for reusing past off-policy data. We present an on-policy algorithm that trains Q-value models purely from on-policy trajectories, unlocking the possibility of using pathwise policy updates in the context of on-policy learning. We show how to combine stochastic policies for exploration with constrained updates for stable training, and evaluate important architectural components that stabilize value function learning. The result, Relative Entropy Pathwise Policy Optimization (REPPO), is an efficient on-policy algorithm that combines the stability of pathwise policy gradients with the simplicity and minimal memory footprint of standard on-policy learning. Compared to state-of-the-art on two standard GPU-parallelized benchmarks, REPPO provides strong empirical performance at superior sample efficiency, wall-clock time, memory footprint, and hyperparameter robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Relative Entropy Pathwise Policy Optimization (REPPO), an on-policy reinforcement learning algorithm that enables pathwise policy gradient updates by training Q-value models exclusively from on-policy trajectories without replay buffers or off-policy corrections. It incorporates a relative entropy constraint for stable training, combines stochastic policies for exploration, and evaluates architectural stabilizers for value function learning. Empirical comparisons on two standard GPU-parallelized benchmarks claim superior sample efficiency, wall-clock time, memory footprint, and hyperparameter robustness relative to state-of-the-art on-policy methods.
Significance. If the central empirical and algorithmic claims hold, the work would be significant as a practical bridge between low-variance pathwise gradients and the simplicity of on-policy learning, potentially reducing memory overhead while improving stability over score-function methods like PPO. The focus on on-policy Q-training and relative-entropy constraints, together with reported benchmark results, could influence efficient RL implementations if the Q-value accuracy premise is substantiated.
major comments (3)
- [§3] §3: the core premise that a Q-network trained exclusively on on-policy rollouts yields action values accurate enough for low-variance pathwise derivatives lacks any theoretical bound on the distribution shift between the on-policy data and the actions queried by the reparameterized gradient; this is load-bearing for the claim that pathwise updates can be used without replay or importance sampling.
- [Results section] Results section: the asserted empirical superiority over SOTA provides no error bars, data exclusion rules, or ablation isolating Q-error from policy performance, making it impossible to verify that on-policy Q-learning (rather than architectural tuning or the relative entropy term) drives the reported gains in sample efficiency and stability.
- [§3] §3 (relative entropy constraint): the formulation is presented as a stability mechanism, yet no analysis shows that the constraint remains independent of the benchmark data or that it does not implicitly reduce to a fitted quantity defined by the same trajectories used for evaluation.
minor comments (2)
- [Abstract] Abstract: specify the exact two GPU-parallelized benchmarks and the precise metrics (e.g., mean return, steps to threshold) used for the superiority claims.
- [Notation] Notation: ensure the relative entropy term is defined consistently between the algorithm description and any pseudocode or equations.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our paper. We provide point-by-point responses to the major comments below, indicating the revisions we plan to make to address the concerns raised.
read point-by-point responses
-
Referee: [§3] §3: the core premise that a Q-network trained exclusively on on-policy rollouts yields action values accurate enough for low-variance pathwise derivatives lacks any theoretical bound on the distribution shift between the on-policy data and the actions queried by the reparameterized gradient; this is load-bearing for the claim that pathwise updates can be used without replay or importance sampling.
Authors: We thank the referee for highlighting this point. We note that because the Q-network is trained exclusively on on-policy trajectories generated by the current policy, and the reparameterized pathwise gradient also samples actions from the same current policy distribution, there is no distribution shift between the training data and the queried actions. The relevant consideration is the approximation error of the Q-function rather than a distributional mismatch. We will revise §3 to explicitly clarify this distinction and discuss the empirical evidence supporting sufficient Q-accuracy for stable pathwise updates. revision: yes
-
Referee: [Results section] Results section: the asserted empirical superiority over SOTA provides no error bars, data exclusion rules, or ablation isolating Q-error from policy performance, making it impossible to verify that on-policy Q-learning (rather than architectural tuning or the relative entropy term) drives the reported gains in sample efficiency and stability.
Authors: We agree that the results section would benefit from additional statistical rigor. In the revised manuscript, we will include error bars across multiple random seeds, specify any data exclusion criteria used in the experiments, and add an ablation study that isolates the contribution of the on-policy Q-learning component versus the relative entropy constraint and architectural choices. This will help verify the source of the performance gains. revision: yes
-
Referee: [§3] §3 (relative entropy constraint): the formulation is presented as a stability mechanism, yet no analysis shows that the constraint remains independent of the benchmark data or that it does not implicitly reduce to a fitted quantity defined by the same trajectories used for evaluation.
Authors: The relative entropy constraint is formulated as a general regularization term based on the Kullback-Leibler divergence between the current and previous policy parameters, which is independent of any specific benchmark data. It serves to limit policy updates for stability, similar to trust-region methods. We will add analysis in the revised §3 demonstrating that the constraint's effect is consistent across different environments and does not depend on fitting to evaluation trajectories, as it is computed solely from the policy distributions during training. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces REPPO as a new on-policy algorithm that trains Q-value models exclusively from on-policy trajectories and combines them with relative-entropy-constrained pathwise policy updates. The provided abstract and description frame the contribution as an empirical synthesis of pathwise gradients with standard on-policy simplicity, stabilized by architectural choices and a relative-entropy term presented as a constraint. No equations or claims in the visible text reduce a performance prediction or first-principles result to a fitted parameter defined by the same data, nor do they rely on load-bearing self-citations or uniqueness theorems imported from prior author work. The empirical comparisons on GPU-parallelized benchmarks are presented as evaluations rather than derivations that are equivalent to the inputs by construction. This is the most common honest finding for an algorithmic paper whose central claims rest on implementation and benchmarking rather than a closed mathematical reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An accurate action-conditioned value function can be learned purely from on-policy trajectories without replay buffers.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present an on-policy algorithm that trains Q-value models purely from on-policy trajectories... combines stochastic policies for exploration with constrained updates... KL regularization scheme, inspired by the Relative Entropy Policy Search method
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Policy loss: L_π = −Q + e^α log π + e^β D_KL
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Maximum a posteriori policy optimisation
13 Preprint – arXiv 2025 Abbas Abdolmaleki, Jost Tobias Springenberg, Yuval Tassa, Remi Munos, Nicolas Heess, and Mar- tin Riedmiller. Maximum a posteriori policy optimisation. InProceedings of the International Conference on Learning Representations,
work page 2025
-
[2]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization. InArXiv, volume abs/1607.06450,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Soft actor-critic for discrete action settings.arXiv preprint arXiv:1910.07207,
Petros Christodoulou. Soft actor-critic for discrete action settings.arXiv preprint arXiv:1910.07207,
-
[4]
Revisiting fundamentals of experience replay
14 Preprint – arXiv 2025 William Fedus, Prajit Ramachandran, Rishabh Agarwal, Yoshua Bengio, Hugo Larochelle, Mark Rowland, and Will Dabney. Revisiting fundamentals of experience replay. InProceedings of the International Conference on Machine Learning,
work page 2025
-
[5]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, and Sergey Levine. Soft actor-critic algo- rithms and applications.arXiv preprint arXiv:1812.05905,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Evaluating the performance of reinforcement learning algorithms
15 Preprint – arXiv 2025 Scott Jordan, Yash Chandak, Daniel Cohen, Mengxue Zhang, and Philip Thomas. Evaluating the performance of reinforcement learning algorithms. InProceedings of the International Confer- ence on Machine Learning,
work page 2025
-
[7]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Hojoon Lee, Dongyoon Hwang, Donghu Kim, Hyunseung Kim, Jun Jet Tai, Kaushik Subramanian, Peter R. Wurman, Jaegul Choo, Peter Stone, and Takuma Seno. Simba: Simplicity bias for scaling up parameters in deep reinforcement learning. InProceedings of the International Conference on Learning Representations, 2025a. Hojoon Lee, Youngdo Lee, Takuma Seno, Donghu ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
16 Preprint – arXiv 2025 Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Relative entropy policy search
17 Preprint – arXiv 2025 Jan Peters, Katharina M ¨ulling, and Yasemin Alt¨un. Relative entropy policy search. InProceedings of the AAAI Conference on Artificial Intelligence,
work page 2025
-
[11]
Younggyo Seo, Carmelo Sferrazza, Haoran Geng, Michal Nauman, Zhao-Heng Yin, and Pieter Abbeel. Fasttd3: Simple, fast, and capable reinforcement learning for humanoid control.arXiv preprint arXiv:2505.22642,
-
[12]
An emphatic approach to the problem of off-policy temporal-difference learning
18 Preprint – arXiv 2025 Richard S Sutton, A Rupam Mahmood, and Martha White. An emphatic approach to the problem of off-policy temporal-difference learning. InJournal of Machine Learning Research, volume
work page 2025
-
[13]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Niko- lay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open founda- tion and fine-tuned chat models.arXiv preprint arXiv:2307.09288,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
19 Preprint – arXiv 2025 A WALLCLOCKMEASUREMENTCONSIDERATIONS Measuring wall-clock time has become a popular way of highlighting the practical utility of an algorithm as it allows us to quickly deploy new models and iterate on ideas. Rigorous wall-clock time measurement is a difficult topic, as many factors impact the wall-clock time of an algorithm. We c...
work page 2025
-
[15]
and PPO. The main benefit of our approach over PQN is that it is a) a general algorithm that unifies both discrete and continuous action spaces, due to the underlying actor critic 20 Preprint – arXiv 2025 architecture, and b) that the principled entropy and KL objectives stabilize updates and encourages continuing exploration without an epsilon greedy exp...
work page 2025
-
[16]
with only minor changes to the architecture to adapt to the Atari games benchmark. Notably, suitable settings for the KL and entropy target remain consistent even for the discrete action setting. We only find that the value ofλ= 0.65that is also recommended by Gallici et al. (2024) is superior to our default value of0.95, likely due to the higher variance...
work page 2024
-
[17]
We tune the discount factor γand the minimum and maximum values for the HL-Gauss representation automatically for each environment, similar to previous work (Hansen et al., 2024). This makes the hyperparameters, to- gether with the algorithm description, and the source code, acomplete algorithm specificationin the sense of Jordan et al. (2020), as we only...
work page 2024
-
[18]
D.1 DESIGNABLATIONS We run ablation experiments investigating the impact of the design components used in REPPO. In these experiments, we remove the cross-entropy loss via HL-Gauss, layer normalization, the auxiliary self-predictive loss, or the KL regularization of the policy updates. To understand the importance of each component for on-policy learning ...
work page 2025
-
[19]
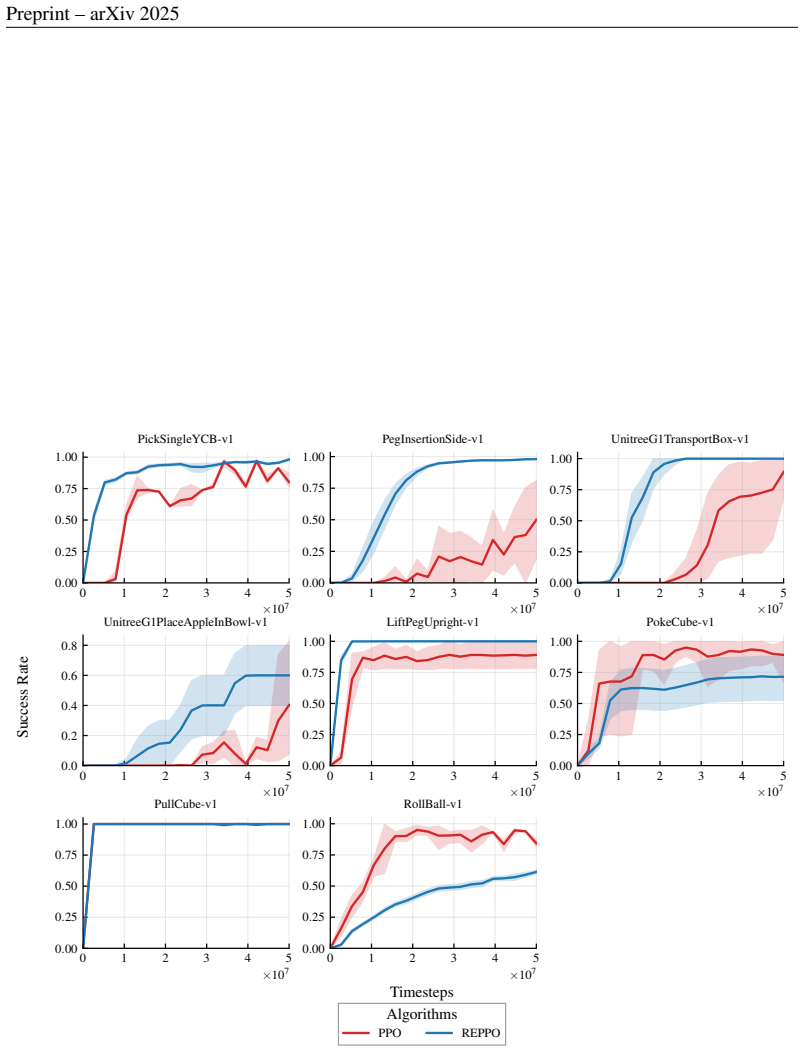
24 Preprint – arXiv 2025 0 1 2 3 4 5 ×107 0.00 0.25 0.50 0.75 1.00 PickSingleYCB-v1 0 1 2 3 4 5 ×107 0.00 0.25 0.50 0.75 1.00 PegInsertionSide-v1 0 1 2 3 4 5 ×107 0.00 0.25 0.50 0.75 1.00 UnitreeG1TransportBox-v1 0 1 2 3 4 5 ×107 0.0 0.2 0.4 0.6 0.8 UnitreeG1PlaceAppleInBowl-v1 0 1 2 3 4 5 ×107 0.00 0.25 0.50 0.75 1.00 LiftPegUpright-v1 0 1 2 3 4 5 ×107 0...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.