Explainable Machine Learning Framework for Cardiovascular Disease Diagnosis and Prognosis
Pith reviewed 2026-05-19 04:04 UTC · model grok-4.3
The pith
Random Forest reaches 97 percent accuracy detecting heart disease and linear regression reaches 0.99 R-squared forecasting risks after SMOTE balancing and explainable AI interpretation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
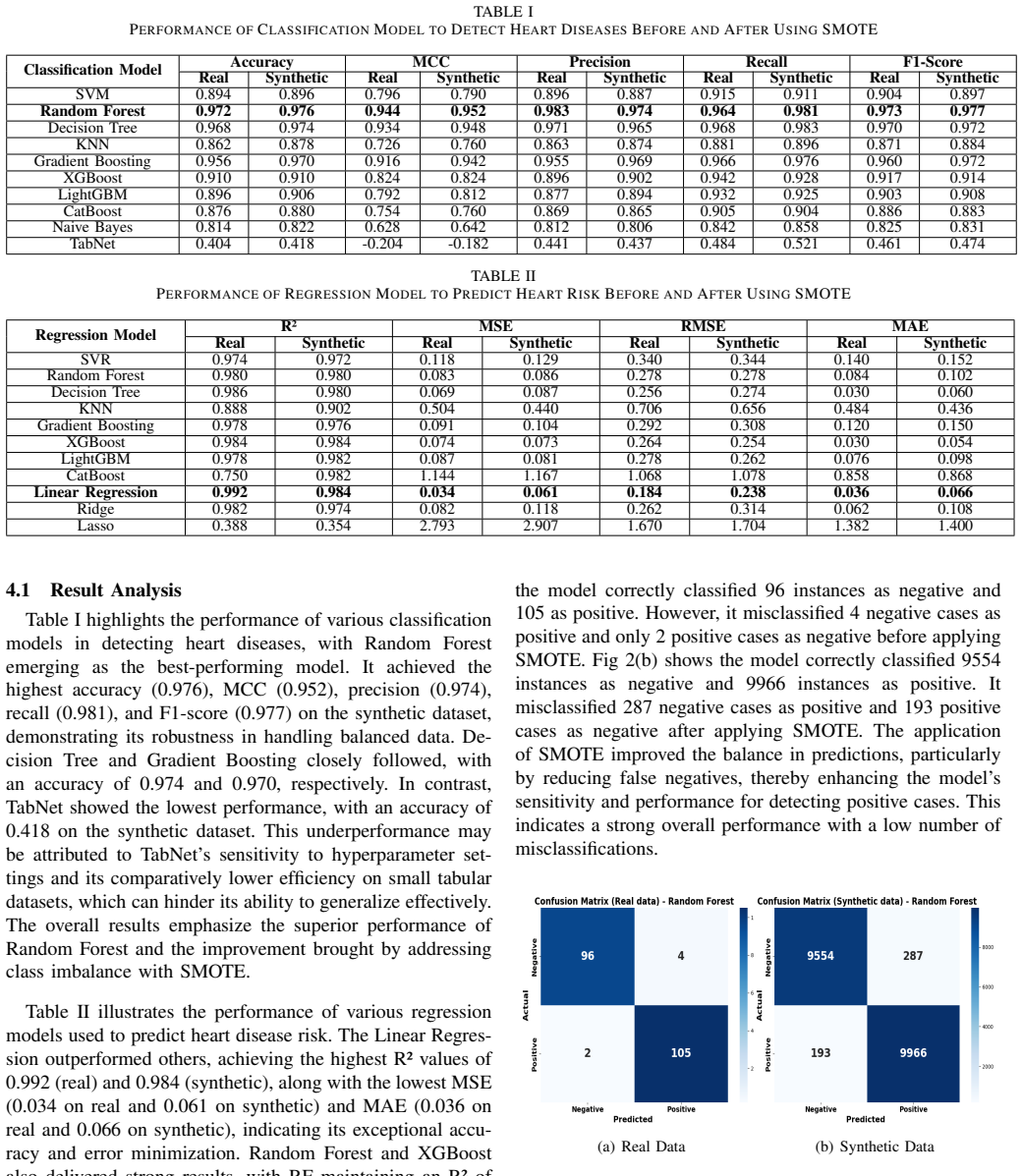
The research introduces a unified machine learning approach that performs classification to detect heart disease and regression to predict associated risks on the Heart Disease dataset of 1035 instances. SMOTE generates 100000 synthetic samples to address data imbalance. Random Forest achieves the highest classification accuracy of 0.972 on real data and 0.976 on synthetic data, while linear regression yields the best R-squared values of 0.992 on synthetic and 0.984 on real samples along with lowest MAE, RMSE, and MSE. Explainable AI techniques are applied to make the model decisions interpretable, supporting the claim that such methods can improve diagnosis and prognosis in clinical use.
What carries the argument
SMOTE oversampling to create balanced synthetic samples combined with Random Forest classification, linear regression prediction, and post-hoc Explainable AI interpretation of feature contributions.
If this is right
- Doctors gain higher precision tools for identifying cardiovascular disease cases where conventional methods fall short.
- Risk forecasts become more reliable, enabling earlier interventions that reduce unfavorable patient outcomes.
- Explainable outputs increase trust and adoption in clinical workflows.
- The framework demonstrates a repeatable process for handling imbalanced medical data in diagnosis and prognosis tasks.
Where Pith is reading between the lines
- Similar pipelines could be tested on other medical conditions that suffer from small or unbalanced patient records.
- High performance on synthetic data opens the possibility of using such augmentation when privacy rules limit sharing of real health records.
- Deployment inside remote monitoring systems could extend timely cardiovascular screening to areas lacking on-site specialists.
Load-bearing premise
The synthetic samples produced by SMOTE keep the same statistical relationships as real patient records and do not create artificial patterns that artificially raise accuracy and R-squared scores on both training and test data.
What would settle it
Apply the final Random Forest and linear regression models to an independent set of real patient records collected from a different hospital or region and check whether accuracy falls below 0.90 or R-squared falls below 0.90.
Figures




read the original abstract
Heart disease continues to pose a critical worldwide health issue, more specifically in areas with insufficient access to healthcare infrastructure and diagnostic systems. Conventional diagnostic approaches often fall short in accurately detecting and managing heart disease risks, resulting in unfavorable outcomes. Machine learning presents a powerful means to boost the precision and reliability of cardiovascular disease prognosis and diagnosis. In this research, we introduced a unified approach incorporating classification techniques for detecting heart disease and regression techniques for forecasting associated risks. The analysis utilized the dataset, named Heart Disease, containing 1,035 instances. To mitigate the problem of data disproportion, the SMOTE was implemented, producing 100,000 additional synthetic samples. Evaluation metrics such as F1-score, recall, precision, accuracy, MAE, RMSE, MSE, and R2 were adopted to evaluate the performance of the models. Among the classification algorithms, Random Forest delivered the most notable results, attaining an accuracy of 0.972 on actual data and 0.976 on artificially generated data. For prediction modeling, for both synthetic and real samples, linear regression produced the best R2 values of 0.992 and 0.984, respectively, along with the least amount of measurement errors. Furthermore, Explainable AI methods were utilized to improve the comprehensibility of the model outcomes. This paper emphasizes the transformative capabilities of machine learning for diagnosing cardiovascular disease and estimating risk levels, thereby supporting timely interventions and enhancing clinical settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an explainable ML framework combining classification for heart disease diagnosis and regression for risk prognosis on the Heart Disease dataset (1035 real instances). SMOTE generates 100000 synthetic samples to address imbalance; Random Forest reports 0.972 accuracy on real data and 0.976 on synthetic data, while linear regression reports R² of 0.992 (synthetic) and 0.984 (real). XAI techniques are applied to enhance interpretability of the outcomes.
Significance. If the evaluation protocol is sound and free of leakage, the framework could aid diagnostic support in low-resource settings by combining high reported accuracy with interpretability; however, the heavy dependence on SMOTE-augmented data from a modest real cohort limits immediate translational value without independent real-world validation.
major comments (3)
- [Methods (data preprocessing)] Methods section on data augmentation: the application of SMOTE to produce 100000 synthetic samples from only 1035 real instances does not state whether oversampling occurred before or after any train/test split. If performed on the full dataset, this introduces a direct risk of leakage that would inflate both the real-data and synthetic-data metrics (RF accuracy 0.972/0.976 and LR R² 0.992/0.984), which are central to the paper's performance claims.
- [Results (model performance)] Results and evaluation: the reported metrics lack any description of cross-validation procedure, hyperparameter optimization, feature scaling or selection steps, or confirmation that the 'actual data' test set consists solely of held-out real instances never seen during SMOTE or model training. Without these details the headline numbers cannot be interpreted as evidence of generalization.
- [Discussion] Discussion: the assertion that the models enable 'timely interventions and enhancing clinical settings' rests on internal metrics alone; no external validation on an independent real-patient cohort or analysis of distribution shift between the original 1035 instances and the SMOTE-generated samples is provided.
minor comments (2)
- [Abstract] Abstract and results tables: clarify whether the synthetic test set was drawn from the same SMOTE run as the training data or generated independently after the split.
- [Evaluation metrics] Notation: define precisely how MAE, RMSE, and MSE are computed for the regression task (e.g., on which target variable) to support reproducibility.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas for improvement in our manuscript. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Methods (data preprocessing)] Methods section on data augmentation: the application of SMOTE to produce 100000 synthetic samples from only 1035 real instances does not state whether oversampling occurred before or after any train/test split. If performed on the full dataset, this introduces a direct risk of leakage that would inflate both the real-data and synthetic-data metrics (RF accuracy 0.972/0.976 and LR R² 0.992/0.984), which are central to the paper's performance claims.
Authors: We thank the referee for pointing out this critical detail regarding the data preprocessing pipeline. Upon reviewing our implementation, SMOTE was indeed applied exclusively to the training set after performing the train-test split on the original 1035 real instances. This ensures no leakage from the test set into the synthetic data generation. We regret that this important step was not clearly articulated in the Methods section. In the revised manuscript, we will explicitly describe the data splitting procedure, the application of SMOTE only on training data, and include a figure illustrating the workflow to prevent any misinterpretation of our results. revision: yes
-
Referee: [Results (model performance)] Results and evaluation: the reported metrics lack any description of cross-validation procedure, hyperparameter optimization, feature scaling or selection steps, or confirmation that the 'actual data' test set consists solely of held-out real instances never seen during SMOTE or model training. Without these details the headline numbers cannot be interpreted as evidence of generalization.
Authors: We appreciate the referee's emphasis on the need for comprehensive evaluation protocols. Our study employed an 80/20 train-test split on the real data, with model training and hyperparameter tuning (via grid search and 5-fold cross-validation) conducted solely on the training portion. Feature scaling was performed using parameters derived from the training data only. The test set for 'actual data' metrics consisted exclusively of held-out real instances. We will expand the Results section to include these methodological details, along with the specific hyperparameter values and cross-validation scores, to better substantiate the reported performance metrics. revision: yes
-
Referee: [Discussion] Discussion: the assertion that the models enable 'timely interventions and enhancing clinical settings' rests on internal metrics alone; no external validation on an independent real-patient cohort or analysis of distribution shift between the original 1035 instances and the SMOTE-generated samples is provided.
Authors: The referee correctly notes that our claims regarding clinical impact are based on internal validation. While we do not have access to an independent external cohort at this time, we will revise the Discussion section to more cautiously frame the potential for 'timely interventions,' highlighting the preliminary nature of the findings and the importance of future real-world validation. Furthermore, we will add a comparison of the distributions between the original and SMOTE-generated samples to address concerns about distribution shift. revision: partial
Circularity Check
No circularity: empirical ML metrics are direct evaluation outputs, not derived by construction
full rationale
The paper applies standard classification (Random Forest) and regression (linear regression) algorithms to a fixed Heart Disease dataset of 1035 instances, augments it via SMOTE to 100k samples, and reports accuracy/R2 values on real vs. synthetic splits. These are straightforward empirical performance numbers obtained by fitting and testing models; no equations, first-principles derivations, or predictions are claimed that reduce to the inputs by definition. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The methodology is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- SMOTE oversampling target
- Random Forest hyperparameters
axioms (2)
- domain assumption SMOTE synthetic samples are statistically exchangeable with real patient records for the purpose of training and evaluation.
- domain assumption The Heart Disease dataset of 1,035 instances is representative of the target clinical population.
Reference graph
Works this paper leans on
-
[1]
Work stress and coronary heart disease: what are the mechanisms?,
T. Chandola, A. Britton, E. Brunner, H. Hemingway, M. Malik, M. Kumari, E. Badrick, M. Kivimaki, and M. Marmot, “Work stress and coronary heart disease: what are the mechanisms?,”European heart journal, vol. 29, no. 5, pp. 640–648, 2008
work page 2008
-
[2]
The global burden of congenital heart disease,
J. I. Hoffman, “The global burden of congenital heart disease,” Car- diovascular journal of Africa , vol. 24, no. 4, pp. 141–145, 2013
work page 2013
-
[3]
Experts: One in four adults in bangladesh suffer from hypertension
T. Desk, “Experts: One in four adults in bangladesh suffer from hypertension.” Dhaka Tribune, 2024. Available at: https://www.dhakatribune.com/bangladesh/health/360195/experts- one-in-four-adults-in-bangladesh-suffer
work page 2024
-
[4]
F. L. Mondesir, T. M. Brown, P. Muntner, R. W. Durant, A. P. Carson, M. M. Safford, and E. B. Levitan, “Diabetes, diabetes severity, and coronary heart disease risk equivalence: Reasons for geographic and racial differences in stroke (regards),”American heart journal, vol. 181, pp. 43–51, 2016
work page 2016
-
[5]
Challenges on the management of congenital heart disease in developing countries,
A. O. Mocumbi, E. Lameira, A. Yaksh, L. Paul, M. B. Ferreira, and D. Sidi, “Challenges on the management of congenital heart disease in developing countries,” International journal of cardiology, vol. 148, no. 3, pp. 285–288, 2011
work page 2011
-
[6]
M. S. Hossen, P. Shaha, and M. Saiduzzaman, “A hybrid machine learning approach utilizing cnn feature extraction with traditional classifier to identify strawberry leaf diseases,” in 4th International Conference on Electrical, Computer and Communication Engineering (ECCE), IEEE, 2025
work page 2025
-
[7]
Effective diagnosis and monitoring of heart disease,
A. F. Otoom, E. E. Abdallah, Y . Kilani, A. Kefaye, and M. Ashour, “Effective diagnosis and monitoring of heart disease,” International Journal of Software Engineering and Its Applications , vol. 9, no. 1, pp. 143–156, 2015
work page 2015
-
[8]
An artificial intelligence model for heart disease detection using machine learning algorithms,
V . Chang, V . R. Bhavani, A. Q. Xu, and M. Hossain, “An artificial intelligence model for heart disease detection using machine learning algorithms,” Healthcare Analytics, vol. 2, p. 100016, 2022
work page 2022
-
[9]
An integrated machine learning approach for congestive heart failure prediction,
M. S. Singh, K. Thongam, P. Choudhary, and P. Bhagat, “An integrated machine learning approach for congestive heart failure prediction,” Diagnostics, vol. 14, no. 7, p. 736, 2024
work page 2024
-
[10]
Enhancing heart disease prediction accuracy through machine learning techniques and optimiza- tion,
N. Chandrasekhar and S. Peddakrishna, “Enhancing heart disease prediction accuracy through machine learning techniques and optimiza- tion,” Processes, vol. 11, no. 4, p. 1210, 2023
work page 2023
-
[11]
Optimized ensemble learning approach with explainable ai for improved heart disease prediction,
I. D. Mienye and N. Jere, “Optimized ensemble learning approach with explainable ai for improved heart disease prediction,”Information, vol. 15, no. 7, p. 394, 2024
work page 2024
-
[12]
A. Husnain, A. Saeed, A. Hussain, A. Ahmad, and M. Gondal, “Harnessing ai for early detection of cardiovascular diseases: Insights from predictive models using patient data,” International Journal for Multidisciplinary Research, vol. 6, no. 5, 2024
work page 2024
-
[13]
A technical comparative heart disease prediction framework using boosting ensemble techniques,
N. Nissa, S. Jamwal, and M. Neshat, “A technical comparative heart disease prediction framework using boosting ensemble techniques,” Computation, vol. 12, no. 1, p. 15, 2024
work page 2024
-
[14]
Effective heart disease prediction using machine learning techniques,
C. M. Bhatt, P. Patel, T. Ghetia, and P. L. Mazzeo, “Effective heart disease prediction using machine learning techniques,” Algorithms, vol. 16, no. 2, p. 88, 2023
work page 2023
-
[15]
B. Abuhaija, A. Alloubani, M. Almatari, G. M. Jaradat, B. A. Hemn, A. M. Abualkishik, and M. K. Alsmadi, “A comprehensive study of machine learning for predicting cardiovascular disease using weka and spss tools,” International Journal of Electrical and Computer Engineering, vol. 13, no. 2, p. 1891, 2023
work page 2023
-
[16]
S. Mahsa, “Heart disease dataset.” Kaggle, Available at: https://www.kaggle.com/datasets/snmahsa/heart-disease, 2020
work page 2020
-
[17]
An explainable ai driven machine learning approach for maternal health risk analysis,
M. S. Hossen, P. Shaha, M. Saiduzzaman, M. Shovon, A. K. Akhi, and M. S. Iqbal, “An explainable ai driven machine learning approach for maternal health risk analysis,” in 27th International Conference on Computer and Information Technology (ICCIT) , IEEE, 2024
work page 2024
-
[18]
Explainable ai (xai): Core ideas, techniques, and solutions,
R. Dwivedi, D. Dave, H. Naik, S. Singhal, R. Omer, P. Patel, B. Qian, Z. Wen, T. Shah, G. Morgan, et al., “Explainable ai (xai): Core ideas, techniques, and solutions,” ACM Computing Surveys , vol. 55, no. 9, pp. 1–33, 2023
work page 2023
-
[19]
M. S. Hossen, M. Saiduzzaman, and P. Shaha, “Social media sentiments analysis on the july revolution in bangladesh: A hybrid transformer based machine learning approach,” in Proceedings of the 17th Interna- tional Conference on Electronics, Computers and Artificial Intelligence (ECAI), IEEE, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.