SPaCe: Unlocking Sample-Efficient Large Language Models Training With Self-Pace Curriculum Learning
Pith reviewed 2026-05-19 00:16 UTC · model grok-4.3
The pith
SPaCe trains large language models for reasoning with up to 100 times fewer samples than standard methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPaCe first applies cluster-based data reduction to partition training examples by semantics and difficulty and extract a compact yet diverse subset. It then runs a multi-armed bandit that treats clusters as arms and allocates samples according to the model's solve rates on each cluster plus measured learning progress within the cluster. This self-paced selection produces training curricula that deliver comparable or superior accuracy to state-of-the-art baselines on multiple reasoning benchmarks while using up to 100 times fewer samples.
What carries the argument
Cluster-based data reduction followed by multi-armed bandit allocation that selects training samples according to the current model's solve rates and cluster-level learning progress.
If this is right
- LLMs reach comparable reasoning accuracy on standard benchmarks with far smaller training sets.
- Adaptive allocation driven by model performance outperforms uniform sampling across epochs.
- Semantic and difficulty clustering can shrink data volume without erasing essential reasoning patterns.
- Both the reduction step and the bandit step are required for the observed efficiency gains.
Where Pith is reading between the lines
- The same clustering-plus-bandit pattern could be tested on non-reasoning tasks such as code generation or instruction following to see if sample savings transfer.
- If clustering introduces hidden selection bias, an alternative progress signal that avoids explicit clusters might be needed for robustness.
- Lower sample counts would directly reduce the compute and energy cost of producing capable reasoning models.
Load-bearing premise
Solve rates on the current model plus cluster-level progress give an unbiased signal for which future samples will deliver the most learning value.
What would settle it
Re-run the reported benchmarks with the clustering step removed or the bandit replaced by uniform sampling and check whether the 100-fold sample reduction and accuracy parity both disappear.
Figures



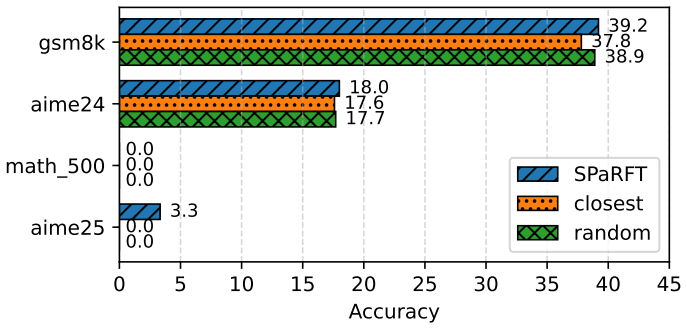

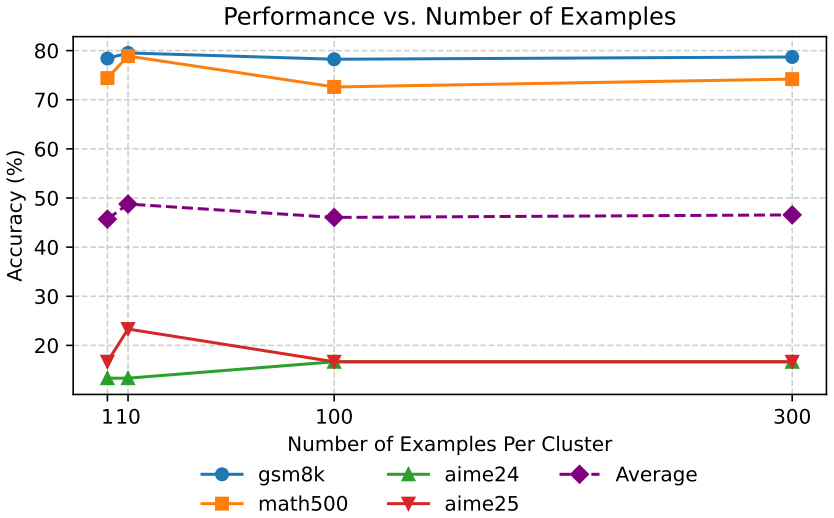



read the original abstract
Large language models (LLMs) have shown strong reasoning capabilities when fine-tuned with reinforcement learning (RL). However, such methods require extensive data and compute, making them impractical under many realistic training budgets. Many existing pipelines sample training examples uniformly across steps or epochs, ignoring differences in difficulty, redundancy, and learning value, which slows learning and wastes computation. We propose \textbf{SPaCe}, a self-paced learning framework that enables efficient learning based on the capability of the model being trained through optimizing which data to use and when. First, we apply \emph{cluster-based data reduction} to partition training data by semantics and difficulty, extracting a compact yet diverse subset that reduces redundancy. Then, a \textit{multi-armed bandit} treats data clusters as arms, allocating training samples based on the model's solve rates and learning progress. Experiments across multiple reasoning benchmarks show that SPaCe achieves comparable or better accuracy than state-of-the-art baselines while using up to \(100\times\) fewer samples. Ablation studies and analyses further highlight the importance of both data clustering and adaptive selection. Our results demonstrate that carefully curated, performance-driven training curricula can unlock strong reasoning abilities in LLMs with minimal resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPaCe, a self-paced curriculum learning framework for efficient fine-tuning of LLMs on reasoning tasks. It first performs cluster-based data reduction to partition training examples by semantics and difficulty and extract a compact diverse subset, then employs a multi-armed bandit that treats clusters as arms and allocates samples according to the current model's solve rates and cluster-level learning progress. The central empirical claim is that SPaCe matches or exceeds state-of-the-art baselines on multiple reasoning benchmarks while using up to 100× fewer training samples.
Significance. If the reported gains prove robust, the work would meaningfully advance sample-efficient LLM training by demonstrating that a combination of semantic/difficulty clustering and performance-driven adaptive allocation can preserve accuracy under severe data budgets. Such a result would be of immediate practical value for resource-constrained fine-tuning pipelines.
major comments (2)
- [Ablation studies] Ablation studies: the reported ablations isolate the contributions of clustering and adaptive selection but omit a uniform-allocation control trained on the same reduced cluster subset. Without this baseline it remains possible that the observed sample-efficiency gains are largely attributable to the initial cluster-based reduction rather than the bandit mechanism.
- [Experiments] Experiments section: the performance claims (comparable or better accuracy with up to 100× fewer samples) are presented without details on baseline implementations, number of independent runs, statistical significance tests, or variance across random seeds. These omissions make it impossible to judge whether the central efficiency claim is supported by the evidence.
minor comments (1)
- [Abstract] The abstract refers to “multiple reasoning benchmarks” without naming them; listing the concrete datasets (e.g., GSM8K, MATH) would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: Ablation studies: the reported ablations isolate the contributions of clustering and adaptive selection but omit a uniform-allocation control trained on the same reduced cluster subset. Without this baseline it remains possible that the observed sample-efficiency gains are largely attributable to the initial cluster-based reduction rather than the bandit mechanism.
Authors: We agree that this control is necessary to isolate the bandit's contribution. In the revised manuscript we will add an ablation that applies uniform sampling over the identical reduced cluster subset produced by the cluster-based data reduction step. This will allow direct comparison with the adaptive bandit allocation and clarify whether the efficiency gains stem primarily from clustering or from the performance-driven selection. revision: yes
-
Referee: Experiments section: the performance claims (comparable or better accuracy with up to 100× fewer samples) are presented without details on baseline implementations, number of independent runs, statistical significance tests, or variance across random seeds. These omissions make it impossible to judge whether the central efficiency claim is supported by the evidence.
Authors: We acknowledge these omissions. In the revision we will expand the Experiments section with: (i) precise implementation details and hyper-parameters for all baselines, (ii) results averaged over at least five independent runs using different random seeds, (iii) statistical significance tests (e.g., paired t-tests) comparing SPaCe against baselines, and (iv) standard deviations or error bars to report variance. These additions will provide the necessary rigor to support the sample-efficiency claims. revision: yes
Circularity Check
No significant circularity in SPaCe derivation or claims
full rationale
The paper describes a two-stage method of first applying cluster-based data reduction on semantics and difficulty to obtain a compact subset, followed by a multi-armed bandit that allocates samples using observed solve rates and learning progress signals from the model under training. These steps rely on standard unsupervised clustering and bandit algorithms driven by empirical performance metrics rather than any fitted parameter that is then renamed as a prediction of the same metric. No equations are presented that define the target accuracy or sample-efficiency gains in terms of the clustering or bandit outputs by construction. Ablations are cited to isolate the contributions of clustering versus adaptive selection, and the headline results are framed as experimental outcomes on external reasoning benchmarks rather than internal consistency checks. The derivation chain remains self-contained against external benchmarks with no load-bearing self-citations or uniqueness theorems imported from prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cluster-based partitioning by semantics and difficulty produces a compact yet diverse subset without losing critical learning signals.
- domain assumption Model solve rates on clusters provide a reliable, non-circular signal for allocating future training samples.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
cluster-based data reduction to partition training data by semantics and difficulty... multi-armed bandit treats data clusters as arms, allocating training samples based on the model's solve rates and learning progress
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 1... Thompson Sampling scheduler in SPaRFT satisfies sublinear reward variation VT = O(log T)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
A Survey of Reinforcement Learning for Large Reasoning Models
A survey compiling RL methods, challenges, data resources, and applications for enhancing reasoning in large language models and large reasoning models since DeepSeek-R1.
Reference graph
Works this paper leans on
-
[1]
Richard Bellman. Dynamic programming. Science, 153(3731):34–37, 1966
work page 1966
-
[2]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, page 41–48, New York, NY , USA, 2009. Association for Computing Machinery
work page 2009
-
[3]
Stochastic multi-armed-bandit problem with non-stationary rewards
Omar Besbes, Yonatan Gur, and Assaf Zeevi. Stochastic multi-armed-bandit problem with non-stationary rewards. Advances in neural information processing systems, 27, 2014
work page 2014
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
work page 2025
-
[6]
RAFT: Reward ranked finetuning for generative foundation model alignment
Hanze Dong, Wei Xiong, Deepanshu Goyal, Yihan Zhang, Winnie Chow, Rui Pan, Shizhe Diao, Jipeng Zhang, KaShun SHUM, and Tong Zhang. RAFT: Reward ranked finetuning for generative foundation model alignment. Transactions on Machine Learning Research, 2023
work page 2023
-
[7]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org
work page 2016
-
[8]
Introducing gemini 2.0: Our new ai model for the agentic era, 2024
Google. Introducing gemini 2.0: Our new ai model for the agentic era, 2024. Accessed: 2025-03-05
work page 2024
-
[9]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page 2024
-
[10]
Lighteval: A lightweight framework for llm evaluation, 2023
Nathan Habib, Clémentine Fourrier, Hynek Kydlí ˇcek, Thomas Wolf, and Lewis Tunstall. Lighteval: A lightweight framework for llm evaluation, 2023
work page 2023
-
[11]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021
work page 2021
-
[12]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
SPAM: Spike-aware adam with momentum reset for stable LLM training
Tianjin Huang, Ziquan Zhu, Gaojie Jin, Lu Liu, Zhangyang Wang, and Shiwei Liu. SPAM: Spike-aware adam with momentum reset for stable LLM training. In The Thirteenth Interna- tional Conference on Learning Representations, 2025
work page 2025
-
[14]
Open r1: A fully open reproduction of deepseek-r1, January 2025
Hugging Face. Open r1: A fully open reproduction of deepseek-r1, January 2025
work page 2025
-
[15]
Llm post-training: A deep dive into reasoning large language models
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip HS Torr, Salman Khan, and Fahad Shahbaz Khan. Llm post-training: A deep dive into reasoning large language models. arXiv preprint arXiv:2502.21321, 2025
-
[16]
Episodic policy gradient training
Hung Le, Majid Abdolshah, Thommen K George, Kien Do, Dung Nguyen, and Svetha Venkatesh. Episodic policy gradient training. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 7317–7325, 2022
work page 2022
-
[17]
Reasoning under 1 billion: Memory- augmented reinforcement learning for large language models
Hung Le, Dai Do, Dung Nguyen, and Svetha Venkatesh. Reasoning under 1 billion: Memory- augmented reinforcement learning for large language models. arXiv preprint arXiv:2504.02273, 2025
-
[18]
Limr: Less is more for rl scaling, 2025
Xuefeng Li, Haoyang Zou, and Pengfei Liu. Limr: Less is more for rl scaling, 2025
work page 2025
-
[19]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y . Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl. https://pretty-radio-b75.notion.site/ DeepScaleR-Surpassing-O1-Preview-with-a-1-5B-Model-by-Scaling-RL-19681902c1468005bed8ca303013a4e2 ,
- [21]
-
[22]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022. 14
work page 2022
-
[23]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page 2025
-
[24]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 11 2019
work page 2019
-
[25]
Principles of Mathematical Analysis
Walter Rudin. Principles of Mathematical Analysis. McGraw-Hill, 3rd edition, 1976
work page 1976
-
[26]
A tutorial on thompson sampling, 2020
Daniel Russo, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, and Zheng Wen. A tutorial on thompson sampling, 2020
work page 2020
-
[27]
Proximal policy optimization algorithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017
work page 2017
-
[28]
Efficient reinforcement finetuning via adaptive curriculum learning, 2025
Taiwei Shi, Yiyang Wu, Linxin Song, Tianyi Zhou, and Jieyu Zhao. Efficient reinforcement finetuning via adaptive curriculum learning, 2025
work page 2025
-
[29]
Mingyang Song, Mao Zheng, Zheng Li, Wenjie Yang, Xuan Luo, Yue Pan, and Feng Zhang. Fastcurl: Curriculum reinforcement learning with stage-wise context scaling for efficient training r1-like reasoning models, 2025
work page 2025
-
[30]
Reinforcement learning: An introduction, volume 1
Richard S Sutton, Andrew G Barto, et al. Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
work page 1998
- [31]
-
[32]
Adagc: Improving training stability for large language model pretraining, 2025
Guoxia Wang, Shuai Li, Congliang Chen, Jinle Zeng, Jiabin Yang, Tao Sun, Yanjun Ma, Dianhai Yu, and Li Shen. Adagc: Improving training stability for large language model pretraining, 2025
work page 2025
-
[33]
Rui Wang, Joel Lehman, Jeff Clune, and Kenneth O. Stanley. Paired open-ended trailblazer (poet): Endlessly generating increasingly complex and diverse learning environments and their solutions, 2019
work page 2019
-
[34]
Reinforcement learning for reasoning in large language models with one training example, 2025
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. Reinforcement learning for reasoning in large language models with one training example, 2025
work page 2025
-
[35]
Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond, 2025
Liang Wen, Yunke Cai, Fenrui Xiao, Xin He, Qi An, Zhenyu Duan, Yimin Du, Junchen Liu, Lifu Tang, Xiaowei Lv, Haosheng Zou, Yongchao Deng, Shousheng Jia, and Xiangzheng Zhang. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond, 2025
work page 2025
-
[36]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page 2025
-
[37]
Wojciech Zaremba and Ilya Sutskever. Learning to execute. arXiv preprint arXiv:1410.4615, 2014. 15 A Appendix A.1 Algorithm for SPaRFT In this section, we provide the pseudo-code for SPaRFT in Algorithm 1. A.2 Convergence of the Thompson Sampling Scheduler We analyze the convergence of the Thompson Sampling scheduler used in SPaRFT. Each data cluster is t...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[38]
First, let’s computef ( √ 2): f ( √
-
[39]
= a( √ 2)2 − √ 2 = a(2) − √ 2 = 2 a − √ 2 Now, we need to compute f (f ( √ 2)): f (f ( √ 2)) = f (2a − √
-
[40]
= a(2a − √ 2)2 − √ 2 Let’s expand the square term: (2a − √ 2)2 = (2a)2 − 2(2a)( √
-
[41]
+ ( √ 2)2 = 4a2 − 4a √ 2 + 2 . . . So the discriminant is zero, which means there is a repeated root: a = 2 √ 2 4 = √ 2 2 Therefore, the value of a is √ 2 2 . Let me double-check the calculations to ensure there are no errors. Starting from the beginning:
-
[42]
= a(2) − √ 2 = 2 a − √ 2
-
[43]
Then f (f ( √ 2)) = f (2a − √
-
[44]
= a(2a − √ 2)2 − √ 2
-
[45]
Expanding (2a − √ 2)2 gives 4a2 − 4a √ 2 + 2
-
[46]
Multiplying by a and subtracting √ 2 gives 4a3 − 4a2√ 2 + 2a − √ 2
-
[47]
Setting equal to − √ 2 leads to the equation 4a3 − 4a2√ 2 + 2a = 0
-
[48]
Factoring gives 2a(2a2 − 2a √ 2 + 1) = 0 , leading to the quadratic with discriminant zero. Yes, the steps seem correct. The discriminant being zero implies a repeated root, which gives a = √ 2 2 . Therefore, the answer is √ 2 2 . **Final Answer** √ 2 2 22 Table 11: Qwen3-0.6B fine-tuned with SPaRFT responses. Question A set S of points in the xy-plane is...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.